
5300亿参数,SOTA屠榜!最大NLP预训练模型新王登基,微软英伟达联手称霸

新智元报道
新智元报道
来源:Microsoft Nvidia
编辑:好困 小咸鱼
【新智元导读】微软和英伟达联合发布了迄今为止最大、最强的人工智能语言模型:Megatron-Turing自然语言生成模型(MT-NLG)。其包含5300亿个参数,在一系列自然语言任务包括阅读理解、常识推理和自然语言推理中实现了「无与伦比」的准确性。

大!真的大!
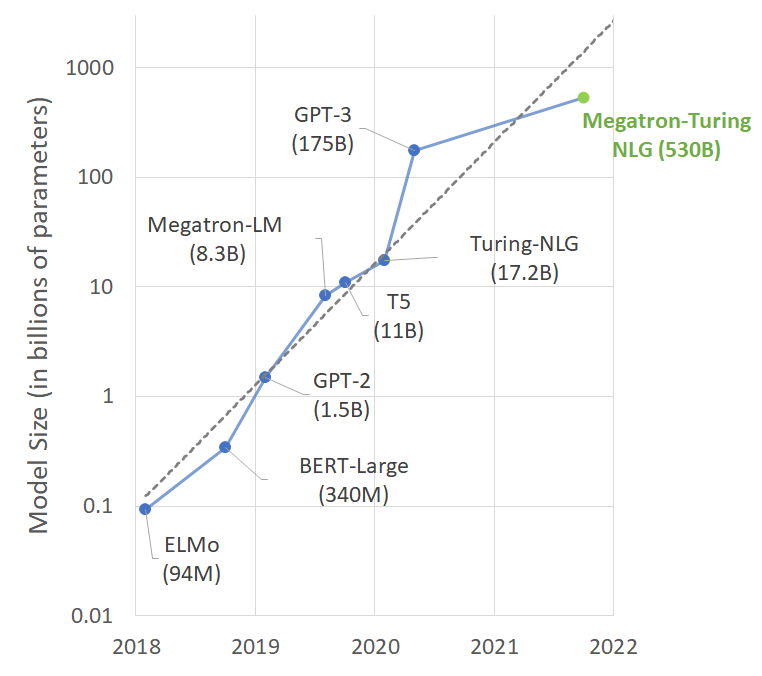

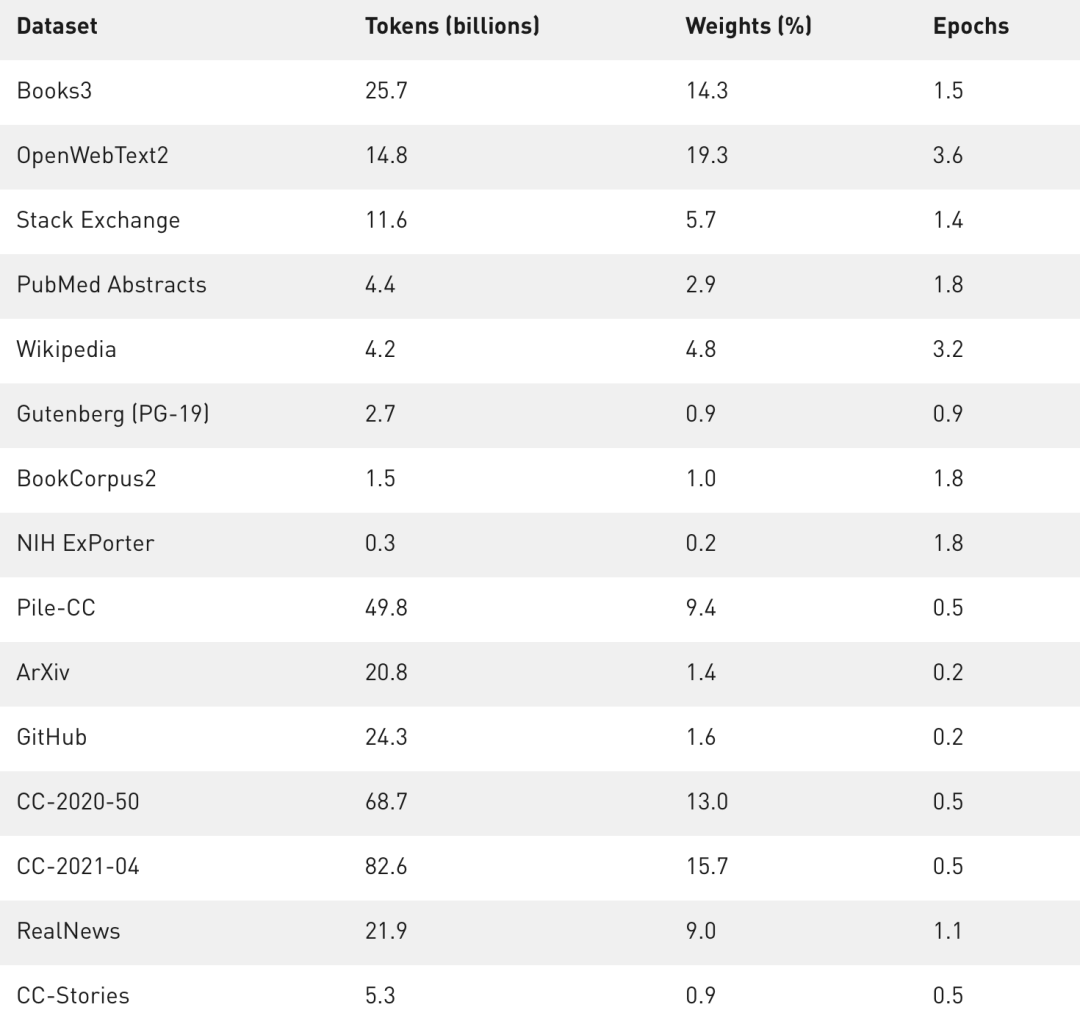
训练使用的数据集
新晋世界第一?拉出来遛遛!
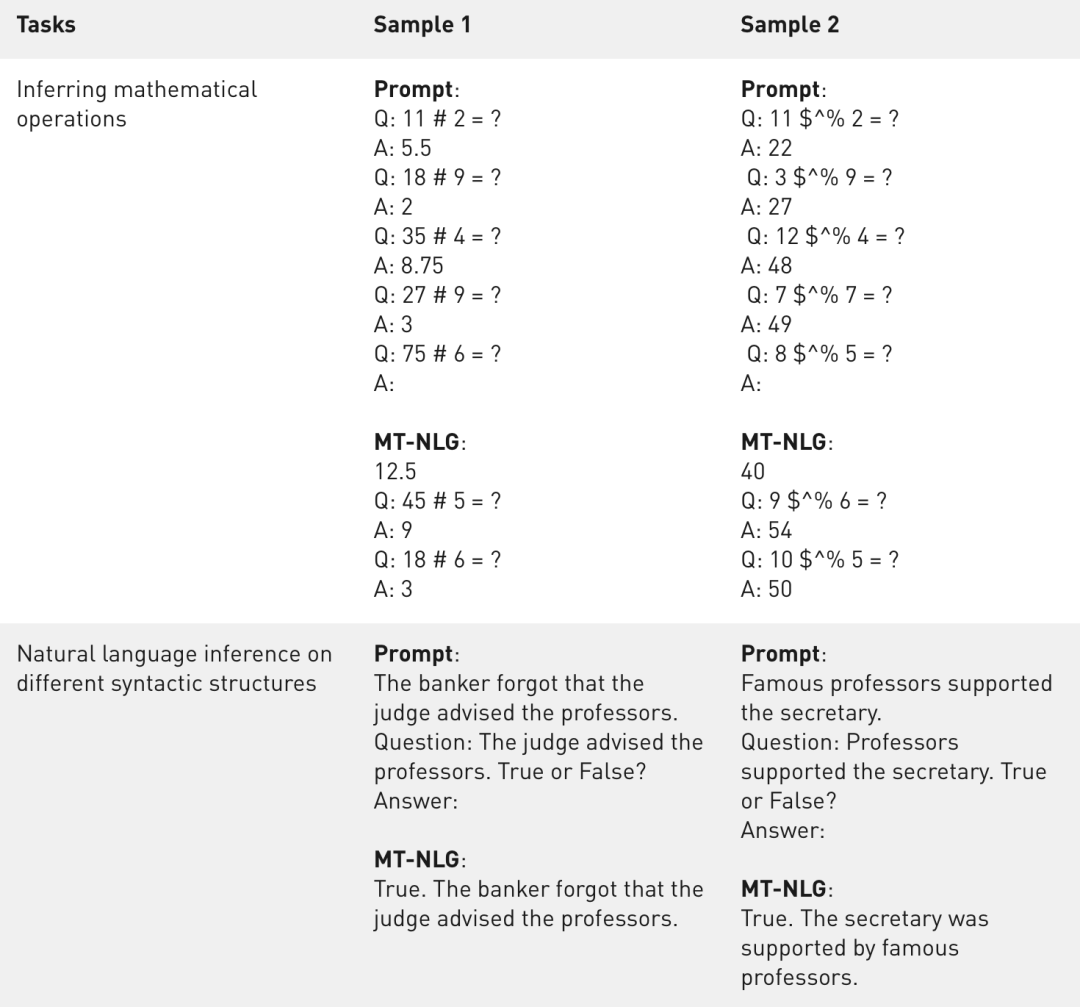
在文本预测任务LAMBADA中,预测给定段落的最后一个词。 在阅读理解任务RACE-h和BoolQ中,根据给定段落生成问题的答案。 在常识推理任务PiQA、HellaSwag和Winogrande中,每个任务都需要用一定程度的「常识」,而不是语言的统计模式来解决。 对于自然语言推理,ANLI-R2和HANS针对过去模型的典型失败案例。 词义辨析任务WiC从上下文中评估多义词的理解。
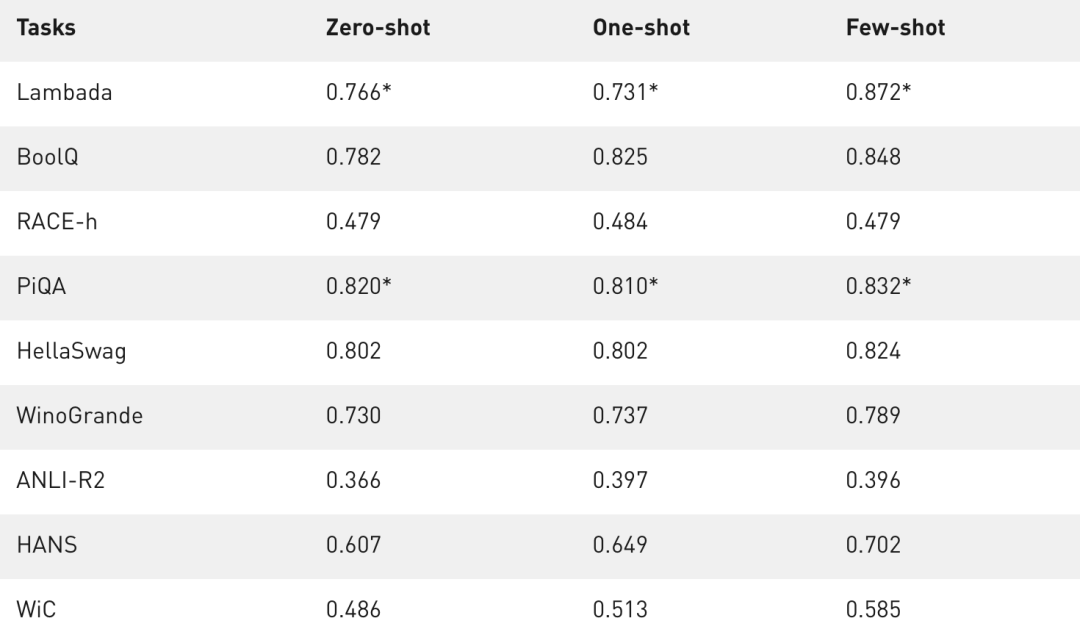
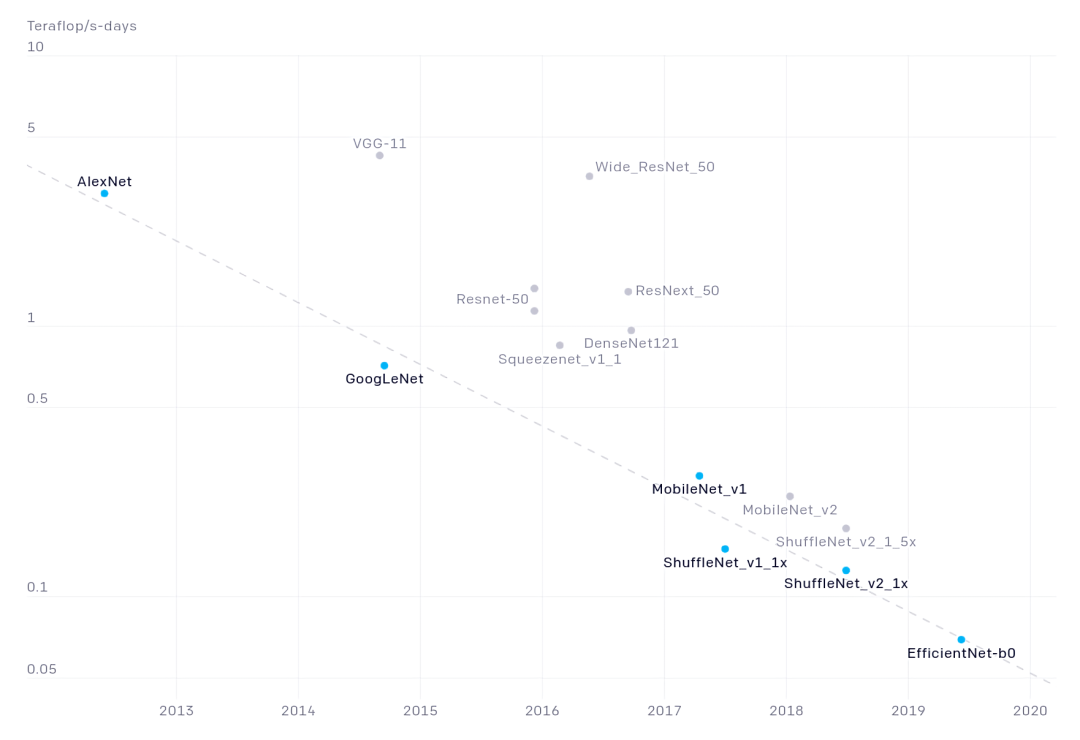
那么,代价是什么呢?


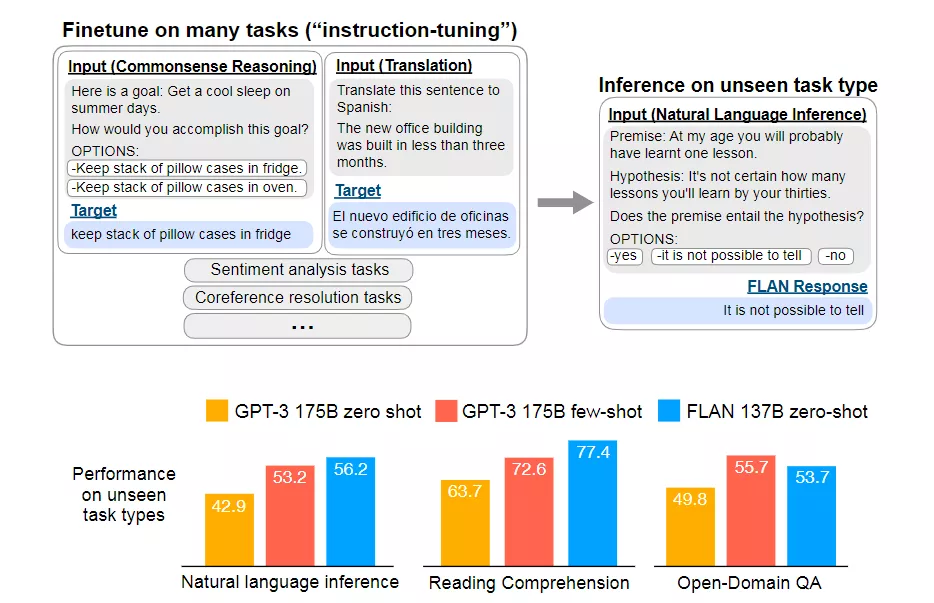
大模型——正确的道路?

参考资料:
https://developer.nvidia.com/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/
https://venturebeat.com/2021/10/11/microsoft-and-nvidia-team-up-to-train-one-of-the-worlds-largest-language-models/https://t.co/md03QzqlxA?amp=1


评论