
这些序列化与反序列化的坑你都踩过吗?
共 7725字,需浏览 16分钟
·
2022-03-01 18:08
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
liuchenyang0515.blog.csdn.net
推荐:https://www.xttblog.com/?p=5317
序列化与反序列化的概念
先说说序列化和反序列化的概念
❝序列化:将对象写入到
❞IO流中
反序列化:从IO流中恢复对象
Serializable接口是一个「标记接口」,不用实现任何方法,标记当前类对象是可以序列化的,是给JVM看的。
序列化机制允许将这些实现序列化接口的对象转化为字节序列,这些字节序列可以保证在磁盘上或者网络传输后恢复成原来的对象。序列化就是把对象存储在JVM以外的地方,序列化机制可以让对象脱离程序的运行而独立存在。
序列化在业务代码也许用的不多,但是在框架层面用的是很多的。
相关技术:Session的序列化或者反序列化
先给出序列化的例子,请记住这个People类,后面会根据这个类来改造讲解。
public class People {
private Long id;
public People(Long id) {
this.id = id;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Override
public String toString() {
return "People{" +
"id=" + id +
'}';
}
}
import java.io.*;
// 屏蔽编译器的警告
@SuppressWarnings("all")
public class Main {
/**
* 序列化和反序列化 People 对象
*/
private static void testSerializablePeople() throws Exception {
// 序列化的步骤
// 用于存储序列化的文件,这里的java_下划线仅仅为了说明是java序列化对象,没有任何其他含义
File file = new File("/tmp/people_10.java_");
if (!file.exists()) {
// 1,先得到文件的上级目录,并创建上级目录
file.getParentFile().mkdirs();
try {
// 2,再创建文件
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
People p = new People(10L);
// 创建一个输出流
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream(file)
);
// 输出可序列化对象
oos.writeObject(p);
// 关闭输出流
oos.close();
// 反序列化的步骤
// 创建一个输入流
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream(file)
);
// 得到反序列化的对象,这里可以强转为People类型
Object newPerson = ois.readObject();
// 关闭输入流
ois.close();
System.out.println(newPerson);
}
public static void main(String[] args) throws Exception {
testSerializablePeople();
}
}
运行之后,看到磁盘文件因为序列化而多了一个文件
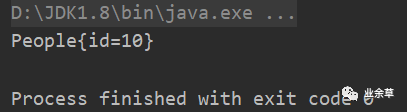
控制台中因反序列化输出的对象信息打印如下:
子类序列化
子类实现Serializable接口,父类没有实现,子类可以序列化吗?
去掉父类People的implements Serializable,让父类不实现序列化接口,子类Worker实现序列化接口
public class Worker extends People implements Serializable {
private String name;
private Integer age;
public Worker(Long id, String name, Integer age) {
super(id);
this.name = name;
this.age = age;
}
}
public static void main(String[] args) throws Exception {
testSerizableWorker();
}
/**
* 子类实现序列化, 父类不实现序列化
* */
private static void testSerizableWorker() throws Exception {
File file = new File("/tmp/worker_10.java_");
if (!file.exists()) {
// 1,先得到文件的上级目录,并创建上级目录
file.getParentFile().mkdirs();
try {
// 2,再创建文件
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
Worker p = new Worker(10L, "lcy", 18);
// 创建一个输出流
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream(file)
);
// 输出可序列化对象
oos.writeObject(p);
// 关闭输出流
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object newWorker = ois.readObject(); // 父类没有序列化的时候,需要调用父类的无参数构造方法
ois.close();
System.out.println(newWorker);
}
再次测试运行
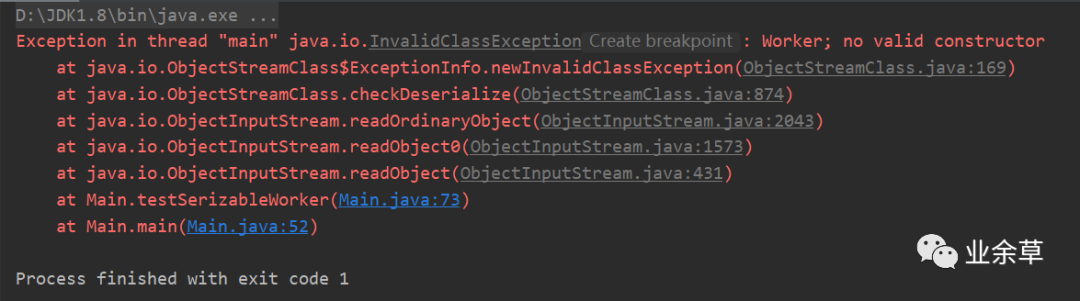
结果显示没有有效地构造器,原来是因为父类没有序列化的时候,Object newWorker = ois.readObject()需要直接调用父类的无参数构造方法,不经过子类的无参构造方法。
我们在父类People中加上空的构造方法之后再次执行
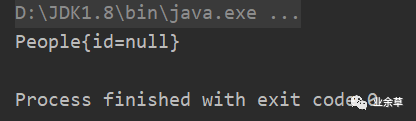
结果却发现打印的不是Worker,而是父类People,因为子类没有实现toString而调用父类的toString,所以打印了People对象,至于父类成员变量id为什么是null,原因如下:
❝一个子类实现了
Serializable接口,它的父类都没有实现Serializable接口,序列化该子类对象。要想反序列化后输出父类定义的某变量的数值,就需要让父类也实现Serializable接口或者父类有默认的无参的构造函数。在父类没有实现
Serializable接口时,虚拟机是不会序列化父对象的,而一个Java对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值,如果在父类无参构造函数中没有对变量赋值,那么父类成员变量值都是默认值,如这里的Long型就是null。根据以上特性,我们可以将不需要被序列化的字段抽取出来放到父类中,子类实现
❞Serializable接口,父类不实现Serializable接口但提供一个空构造方法,则父类的字段数据将不被序列化。
最后加上子类Worker的toString方法,打印结果如下:
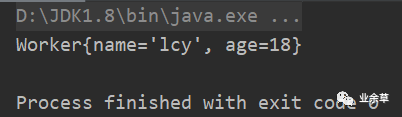
总结:
子类实现 Serializable接口,父类没有实现,子类「可以」序列化!!这种情况父类一定要提供空构造方法,不要忘了子类的 toString方法!
引用对象的序列化
类中存在引用对象,这个类对象在什么情况下可以实现序列化?
来一个组合对象,里面引用People对象,此时People对象「没有」实现Serializable接口,能否序列化呢?代码给出来,大家可以自行复制测试一下。
public class Combo implements Serializable {
private int id;
private People people;
public Combo(int id, People people) {
this.id = id;
this.people = people;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public People getPeople() {
return people;
}
public void setPeople(People people) {
this.people = people;
}
@Override
public String toString() {
return "Combo{" +
"id=" + id +
", people=" + people +
'}';
}
}
public class People {
private Long id;
public People() {
}
public People(Long id) {
this.id = id;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Override
public String toString() {
return "People{" +
"id=" + id +
'}';
}
}
private static void testSerializableCombo() throws Exception {
File file = new File("/tmp/combo_10.java_");
if (!file.exists()) {
// 1,先得到文件的上级目录,并创建上级目录
file.getParentFile().mkdirs();
try {
// 2,再创建文件
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
Combo p = new Combo(1, new People(10L));
// 创建一个输出流
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream(file)
);
// 输出可序列化对象
oos.writeObject(p);
// 关闭输出流
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object newCombo = ois.readObject();
ois.close();
System.out.println(newCombo);
}
public static void main(String[] args) throws Exception {
testSerializableCombo();
}
运行结果如下
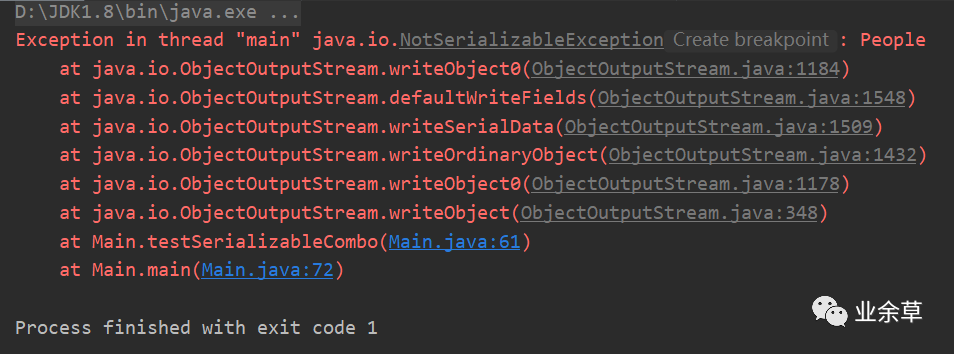
直接爆出异常,说明People类没有序列化。当People加上implements Serializable实现序列化接口后,再次执行如下
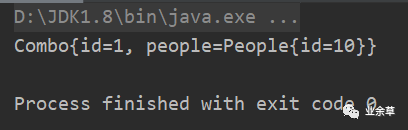
总结:
❝一个类里面所有的属性必须是可序列化的,这个类才能顺利的序列化。比如,类中存在引用对象,那么这个引用对象必须是可序列化的,这个类才能序列化。
❞
同一个对象多次序列化
同一个对象多次序列化之间有属性更新,前后的序列化有什么区别?
下面例子中People是可序列化的,每次序列化之前都会把People的id值修改了,用来观察看看,多次序列化期间,如果对象属性更新,是否会影响序列化,反序列化有什么区别。
/**
* 同一个对象多次序列化的问题, 坑
* */
private static void sameObjectRepeatedSerialization() throws Exception {
File file = new File("/tmp/peopele_more.java_");
if (!file.exists()) {
// 1,先得到文件的上级目录,并创建上级目录
file.getParentFile().mkdirs();
try {
// 2,再创建文件
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
People p = new People(10L);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
// 未序列化,先修改属性
p.setId(11L);
oos.writeObject(p);
// 序列化一次后,再次修改属性
p.setId(15L);
oos.writeObject(p);
// 序列化两次后,再次修改属性
p.setId(20L);
oos.writeObject(p);
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Object people1 = ois.readObject();
Object people2 = ois.readObject();
Object people3 = ois.readObject();
ois.close();
System.out.println(((People) people1).getId());
System.out.println(((People) people2).getId());
System.out.println(((People) people3).getId());
}
public static void main(String[] args) throws Exception {
sameObjectRepeatedSerialization();
}
运行结果如下
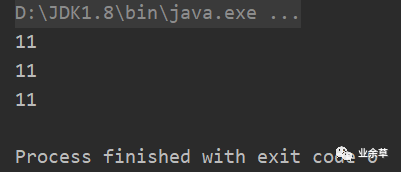
结果发现反序列化读出的值都是一样的。说明当对象第一次序列化成功后,后续这个对象属性即使有修改,也不会对后面的序列化造成成影响。
这其实是序列化算法的原因,所有要序列化的对象都有一个序列化的编码号,当试图序列化一个对象,会检查这个对象是否已经序列化过,若从未序列化过,才会序列化为字节序列去输出。若已经序列化过,则会输出一个编码符号,不会重复序列化一个对象。如下

序列化一次后,后续继续序列化并未重复转换为字节序列,而是输出字符q~
总结:
❝当第一次序列化之后,不管如何修改这个对象的属性,都不会对后续的序列化产生影响,反序列化的结果都和第一次相同。
❞
欢迎一键三连~