
Redis中主、从库宕机如何恢复?


1、什么是哨兵
哨兵是对Redis的系统的运行情况的监控,它是一个独立进程,功能有二个:
监控主数据库和从数据库是否运行正常;
主数据出现故障后自动将从数据库转化为主数据库;
2、原理
单个哨兵的架构:

多个哨兵的架构:
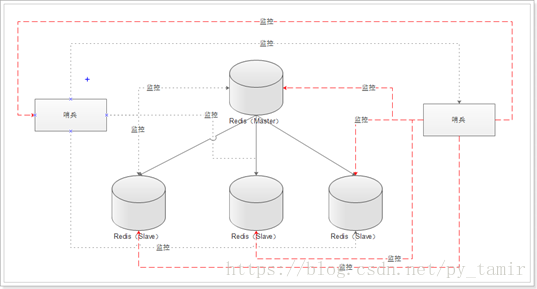
多个哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控。
多个哨兵,防止哨兵单点故障。
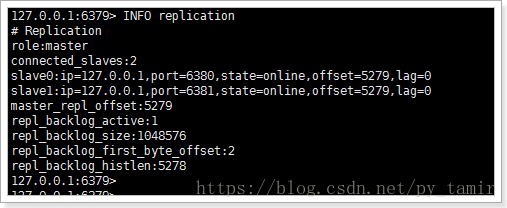
3、环境
当前处于一主多从的环境中:
4、设置哨兵
启动哨兵进程首先需要创建哨兵配置文件:
vim sentinel.conf
输入内容:
sentinel monitor taotaoMaster 127.0.0.1 6379 1
说明:
taotaoMaster:监控主数据的名称,自定义即可,可以使用大小写字母和“.-_”符号
127.0.0.1:监控的主数据库的IP
6379:监控的主数据库的端口
1:最低通过票数
启动哨兵进程:
redis-sentinel ./sentinel.conf
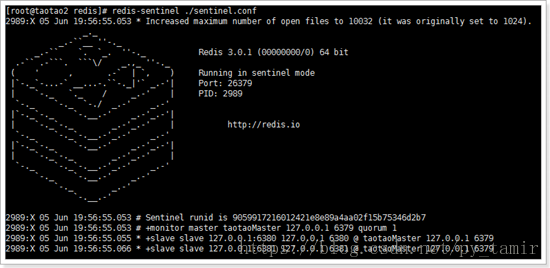
由上图可以看到:
哨兵已经启动,它的id为9059917216012421e8e89a4aa02f15b75346d2b7
为master数据库添加了一个监控
发现了2个slave(由此可以看出,哨兵无需配置slave,只需要指定master,哨兵会自动发现slave)
5、从宕机及恢复
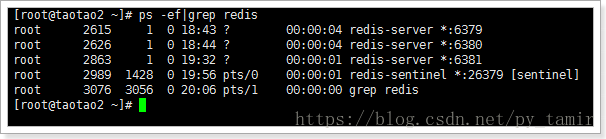
kill掉2826进程后,30秒后哨兵的控制台输出:
2989:X 05 Jun 20:09:33.509 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
说明已经监控到slave宕机了,那么,如果我们将3380端口的redis实例启动后,会自动加入到主从复制吗?
2989:X 05 Jun 20:13:22.716 * +reboot slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 63792989:X 05 Jun 20:13:22.788 # -sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
可以看出,slave从新加入到了主从复制中。-sdown:说明是恢复服务。
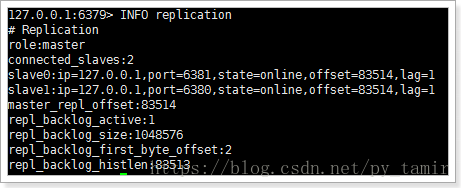
6、主宕机及恢复
哨兵控制台打印出如下信息:
2989:X 05 Jun 20:16:50.300 # +sdown master taotaoMaster 127.0.0.1 6379 说明master服务已经宕机2989:X 05 Jun 20:16:50.300 # +odown master taotaoMaster 127.0.0.1 6379 #quorum 1/12989:X 05 Jun 20:16:50.300 # +new-epoch 12989:X 05 Jun 20:16:50.300 # +try-failover master taotaoMaster 127.0.0.1 6379 开始恢复故障2989:X 05 Jun 20:16:50.304 # +vote-for-leader 9059917216012421e8e89a4aa02f15b75346d2b7 1 投票选举哨兵leader,现在就一个哨兵所以leader就自己2989:X 05 Jun 20:16:50.304 # +elected-leader master taotaoMaster 127.0.0.1 6379 选中leader2989:X 05 Jun 20:16:50.304 # +failover-state-select-slave master taotaoMaster 127.0.0.1 6379 选中其中的一个slave当做master2989:X 05 Jun 20:16:50.357 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 选中63812989:X 05 Jun 20:16:50.357 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 发送slaveof no one命令2989:X 05 Jun 20:16:50.420 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 等待升级master2989:X 05 Jun 20:16:50.515 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 升级6381为master2989:X 05 Jun 20:16:50.515 # +failover-state-reconf-slaves master taotaoMaster 127.0.0.1 63792989:X 05 Jun 20:16:50.566 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 63792989:X 05 Jun 20:16:51.333 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 63792989:X 05 Jun 20:16:52.382 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 63792989:X 05 Jun 20:16:52.438 # +failover-end master taotaoMaster 127.0.0.1 6379 故障恢复完成2989:X 05 Jun 20:16:52.438 # +switch-master taotaoMaster 127.0.0.1 6379 127.0.0.1 6381 主数据库从6379转变为63812989:X 05 Jun 20:16:52.438 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6381 添加6380为6381的从库2989:X 05 Jun 20:16:52.438 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 添加6379为6381的从库2989:X 05 Jun 20:17:22.463 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 发现6379已经宕机,等待6379的恢复
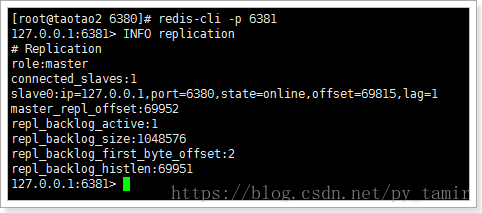
可以看出,目前,6381位master,拥有一个slave为6380.
接下来,我们恢复6379查看状态:
2989:X 05 Jun 20:35:32.172 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 6379已经恢复服务2989:X 05 Jun 20:35:42.137 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 将6379设置为6381的slave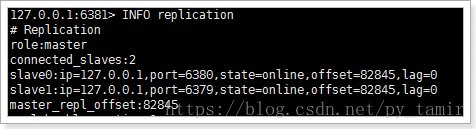
7、配置多个哨兵
vim sentinel.conf
输入内容:
sentinel monitor taotaoMaster1 127.0.0.1 6381 1sentinel monitor taotaoMaster2 127.0.0.1 6381 2

文章转载: 程序员老鬼
(版权归原作者所有,侵删)
![]()

点击下方“阅读原文”查看更多