
分布式存储 Ceph 的演进
『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。
本文要介绍的是 2019 年 SOSP 期刊中的论文 —— File Systems Unfit as Distributed Storage Backends: Lesson Effis from 10 Years of Ceph Evolution[^1],该论文介绍了分布式存储系统 Ceph 在过去 10 多年演进过程中遇到的一些问题,我们作为文件系统的使用者也能从中可以借鉴到很多经验与教训,在遇到相似问题时避免犯相同的错误。

从 2004 年到今天,Ceph 的存储后端一直都在演变,从最开始基于 B 树的 EBOFS 演变到今天的 BlueStore,存储后端已经变得非常成熟,新的存储系统不仅能够提供良好的性能,还有着优异的兼容性。我们在这篇文章中将要简单介绍分布式存储 Ceph 的架构以及演进过程中遇到的挑战。
Ceph 架构
分布式文件系统能够聚合多个物理机上的存储空间并对外提供具有大带宽、并行 I/O、水平扩展、容错以及强一致性的数据存储系统。不同的分布式系统可能在设计上稍有不同并且使用不同的术语描述物理机上用于管理存储资源的模块,但是存储后端(Storage backend)一般都被定义为直接管理物理机上存储设备的软件模块;而在 Ceph 中这一模块就是对象存储设备(Object Storage Devices、OSDs):
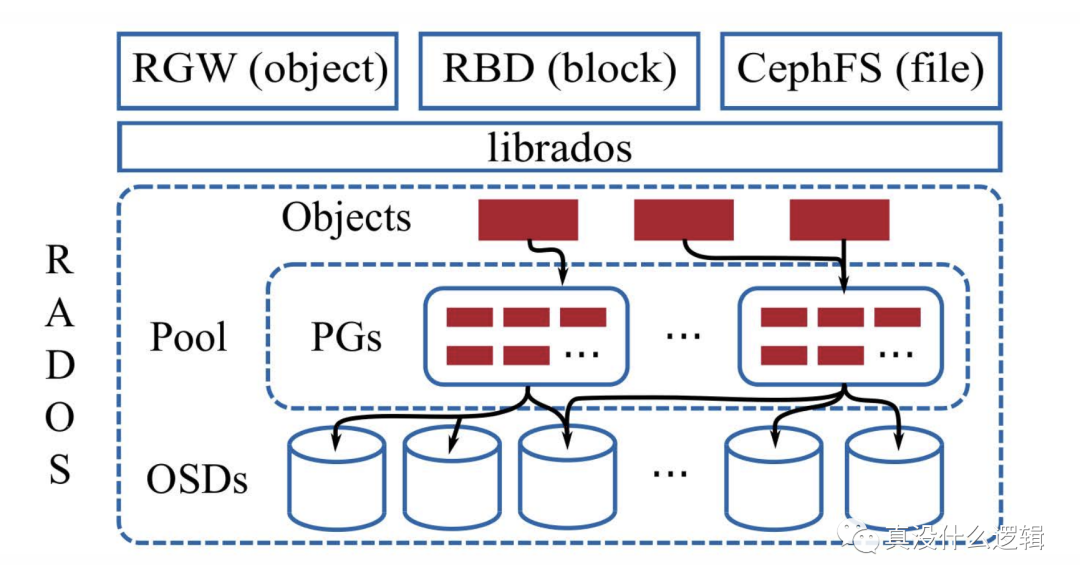
Ceph 使用如上图所示的架构,它的核心是可靠自主分布式对象存储(Reliable Autonomic Distributed Object Store、RADOS),该模块可以水平扩展出成千上万个 OSDs 提供自愈、自管理并且强一致的副本对象存储服务。
我们可以使用 Ceph 提供的 librados 操作 RADOS 中存储的对象和对象集合,该库提供了易于操作的事务接口,在该接口之上我们可以构建出:
RADOS 网关(RGW):类似于 Amazon S3 的对象存储; RADOS 块设备(RBD):类似于 Amazon EBS 的虚拟块设备; CephFS:提供 POSIX 语义的分布式文件系统;
RADOS 中的对象会被存储在逻辑分区中,也就是池(Pool);对象会在池中分片,每个分片单位被称作放置组(Placement Groups、PGs),放置组中的数据会根据配置好的副本数同步到多个 OSD 上,这样可以在单个 OSD 宕机时保证数据的正确性。
RADOS 集群中的每个节点都会为每个本地存储设备运行独立的 OSD 守护进程,这些进程会处理来自 librados 的请求并配合其他 OSD 节点完成数据的拷贝、迁移以及错误恢复等操作,所有的数据都会通过内部的 ObjectStore 接口持久化到本地,我们可以为硬件设备实现不同的接口以满足兼容性的需求。
演进挑战
与其他的分布式文件系统不同,今天 Ceph 的存储后端 BlueStore 绕过了本地的文件系统,直接管理本地的裸设备,这是因为 Ceph 团队的经验说明在本地的文件系统上构建存储后端是一件非常麻烦的事情:
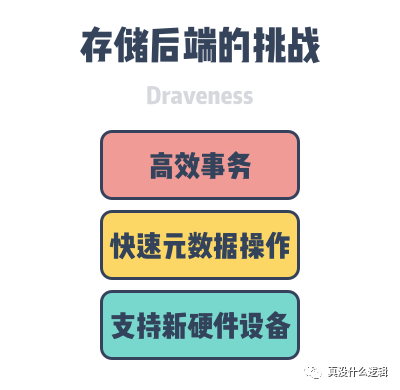
在本地文件系统上直接构建无额外开销的事务机制是非常复杂的; 本地文件系统的元数据性能对分布式文件系统的性能有很严重的影响; 成熟的文件系统有着非常严格的接口,适配新的存储硬件很困难;
高效事务
事务可以通过将一系列操作封装到独立的原子单元来简化应用程序的开发,这一系列操作要么全部执行、要么全不执行,对数据库稍有了解的工程师应该都很了解事务的四个特性,也就是原子性、一致性、隔离性和持久性,我们这里就不展开讨论了。
虽然事务能够极大地简化应用程序开发者的工作并减轻负担,但是想要在本地的文件系统之上支持高效地事务机制是非常有挑战的任务,这篇论文给出了三种实现事务的方法:
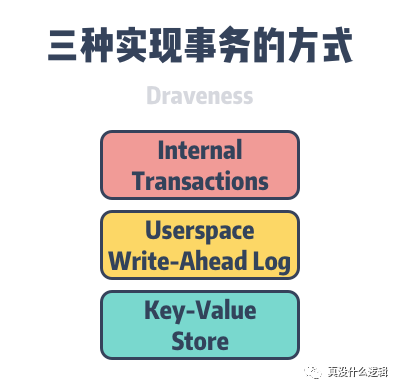
基于文件系统内部的事务机制 — 很多文件系统都在内部实现了事务,这样能够原子地执行一些内部的复合操作,然而因为这些事务机制仅用于内部,所以功能非常受限、甚至不可用,所以也就很难利用文件系统的内部事务; 在用户空间实现逻辑预写式日志(Write-Ahead Log、WAL)— 虽然这种实现方式可以工作,但是它却会遇到三个比较严重的问题; 读-修改-写操作缓慢(Slow Read-Modify-Write)— 基于 WAL 的日志机制会为每个事务执行如下所示的步骤:序列化事务并写入日志、调用 fsync提交事务、事务操作提交到文件系统,因为每个事务在执行前都需要读取前一个事务执行的结果,即等待三个步骤执行完成,所以这种实现比较低效;非幂等操作(Non-Idempotent Operations)— 部分文件的操作可能不是幂等的,错误恢复重放日志时会导致数据发生错误的结果甚至数据损坏; 双写(Double Writes)— 所有数据都会被先写入 WAL 并随后写入文件系统,同时向两个地方写入相同的数据会降低一半的磁盘带宽; 使用支持事务的键值数据库 — 元数据存储在 RocksDB 中,而对象仍然使用文件系统存储,因为在存储中写入对象需要分别将对象写入文件、将元数据写入 RocksDB 并调用两次 fsync,而部分文件系统(JFS)对每个fsync都会触发两次昂贵的FLUSH CACHE,这也就是一致性带来的高额外开销;
快速元数据操作
本地文件系统中低效地元数据操作对分布式文件系统的影响非常大,当我们使用 readdir 操作在 Ceph 中遍历大的文件目录时,就可以体会到元数据操作对整体性能的影响。
RADOS 集群中的对象会根据文件名的哈希映射到某一个放置组中,这些对象在遍历时也会遵循哈希顺序,当我们在系统中遇到很长的对象名时,可能需要使用扩展属性突破本地文件系统的文件名长度限制,查找这些文件时也需要调用 stat 获取文件的真实文件名进行比对。为了解决系统的缓慢遍历问题,我们使用如下所示的层级结构来存储文件对象:
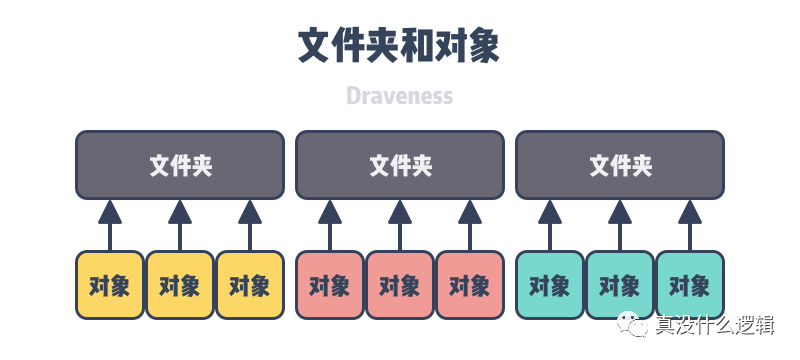
查找或者遍历文件时,我们会先选择合适的文件夹,再遍历文件夹中的对象,而为了减少 stat 函数的调用,存储后端需要保证每个文件夹中的文件尽可能少;当文件夹中的内容逐渐增加时,我们也需要将其中的内容拆分到多个文件夹中,不过这个内容分割的过程却是极其耗时的。
支持新硬件设备
因为分布式的文件系统的运行基于本地的文件系统,而存储硬件的高速发展会为分布式文件系统带来更多的挑战。为了提高存储设备的容量与性能,HDD、SSD 的提供商通过引入主机管理的 SMR 以及 ZNS 技术对现有的硬件进行改进,这些技术对提高分布式文件系统的性能异常重要,而存储设备的开发商也在开发新的硬件,这也增加了文件系统的适配成本。
总结
传统的分布式文件系统开发者一般都会将本地的文件系统作为它们的存储后端,然后尝试基于本地的文件系统构建更加通用的文件系统,然而因为底层的工具并不能完全兼容,所以这会为项目带来极大的复杂性,这是因为很多开发者认为开发新的文件系统可能需要 10 年的时间才能成熟,然而基于 Ceph 团队的经验,从零开始开发成熟的存储后端并不要那么长的周期。
从作者的角度来看,Ceph 的演进过程其实是合理的,我们在刚开始构建系统时希望尽可能利用现有的工具减少我们的工作量,只有当现有的工具不再趁手时,才应该考虑从零构建复杂的系统,如果 Ceph 从立项开始就从零构建存储后端,可能 Ceph 也不会占领市场并得到今天这样的地位。