
为什么说大模型微调是每个人都必备的核心技能?
▼最近直播超级多,预约保你有收获
近期直播:《基于开源 LLM 大模型的微调(Fine tuning)实战》
0 —
为什么要对 LLM 大模型进行微调(Fine tuning)?
— 1 —
如何对 LLM 大模型进行微调(Fine tuning)?
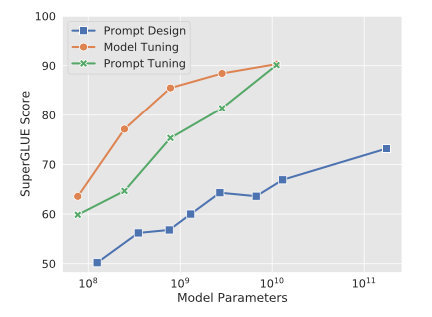
从参数规模的角度,对大模型进行微调(Fine tuning)有两条技术路线:
— 2 —
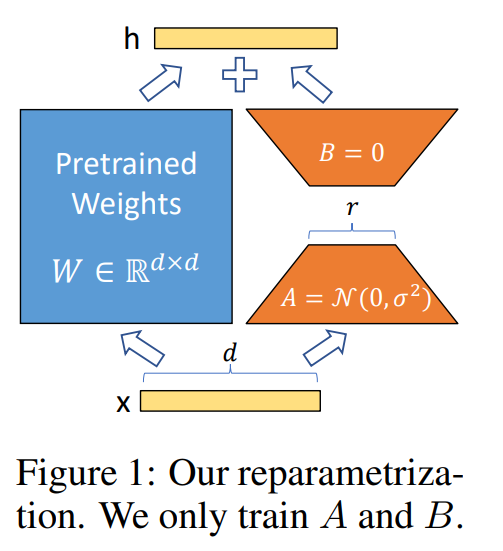
主流部分参数 PEFT 微调(Fine tuning)方案剖析
— 3—
免费超干货 LLM 大模型直播
为了帮助同学们掌握好 LLM 大模型的微调技术,本周日晚8点,我会开一场直播和同学们深度聊聊大模型的技术、分布式训练和参数高效微调,请同学点击下方按钮预约直播,咱们本周日晚8点不见不散哦~~
END
评论