
关于数仓基础知识的超全概括!

面对大数据的多样性,在存储和处理这些大数据时,我们就必须要知道两个重要的技术。
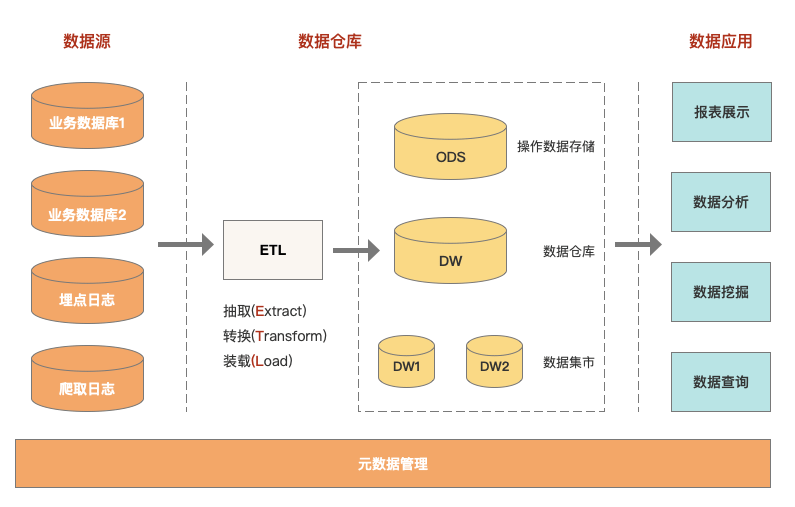
分别是:数据仓库技术、Hadoop。当数据为结构化数据,来自传统的数据源,则采用数据仓库技术来存储和处理这些数据,如下图:
1)基础能力上的区别
2)业务能力上的区别
描述 "数据"背后的业务含义。
主题定义:每段 ETL、表背后的归属业务主题。
业务描述:每段代码实现的具体业务逻辑。
标准指标:类似于 BI 中的语义层、数仓中的一致性事实;将分析中的指标进行规范化。
标准维度:同标准指标,对分析的各维度定义实现规范化、标准化。
不断的进行维护且与业务方进行沟通确认。
根据 ETL 目的的不同,可以分为两类:数据清洗元数据;数据处理元数据。
数据清洗,主要目的是为了解决掉脏数据及规范数据格式;因此此处元数据主要为:各表各列的"正确"数据规则;默认数据类型的"正确"规则。
数据处理,例如常见的表输入表输出;非结构化数据结构化;特殊字段的拆分等。源数据到数仓、数据集市层的各类规则。比如内容、清理、数据刷新规则。
星型模型
雪花模型
星座模型
分层可以清晰数据结构,使用时更好的定位和理解
方便追踪数据的血缘关系
规范数据分层,可以开发一些通用的中间层数据,能够减少极大的重复计算
把复杂的问题简单化
屏蔽原始数据的异常,下游任务没有感知异常
评论