
TiDB 数仓 | Flink + TiDB,体验实时数仓之美
作者介绍
王天宜,TiDB 社区部门架构师。曾就职于 Fidelity Investment,Softbank Investment,拥有丰富的数据库高可用方案设计经验,对 TiDB、Oracle、PostgreSQL、MySQL 等数据库的高可用架构与数据库生态有深入研究。
实时数仓的经典架构 Flink 在 TiDB 上的实时读写场景 Flink + TiDB 的典型用户案例
实时数仓经典架构
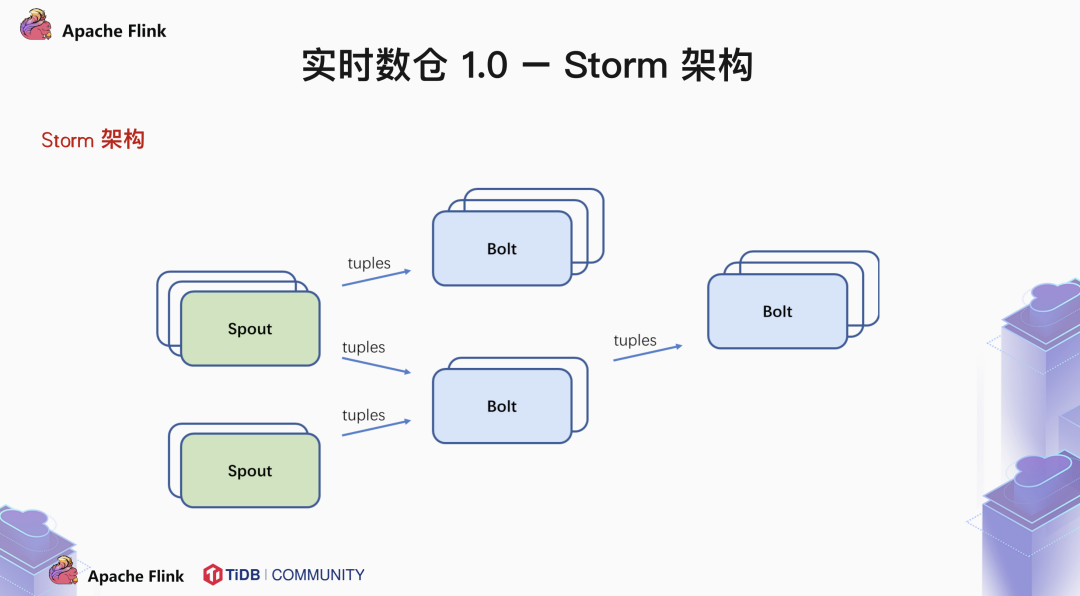
1.1 Storm 架构
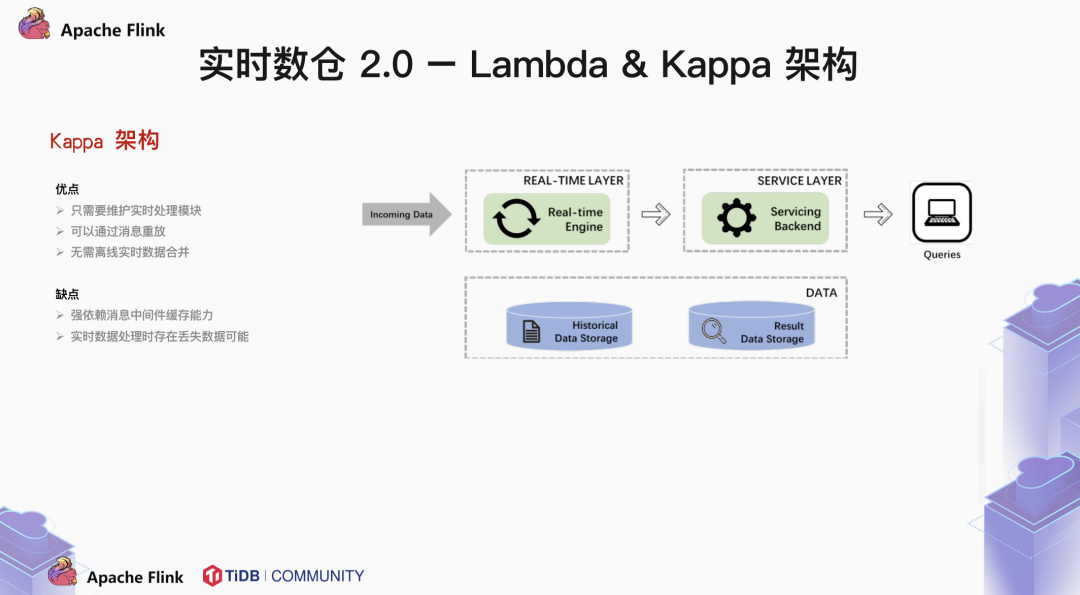
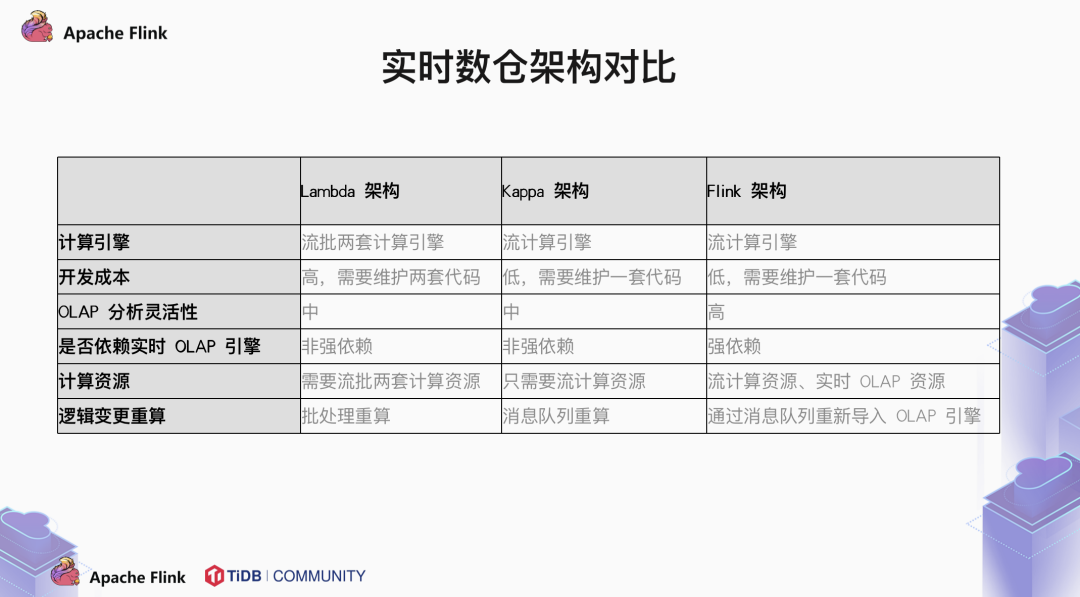
1.2 Lambda & Kappa 架构
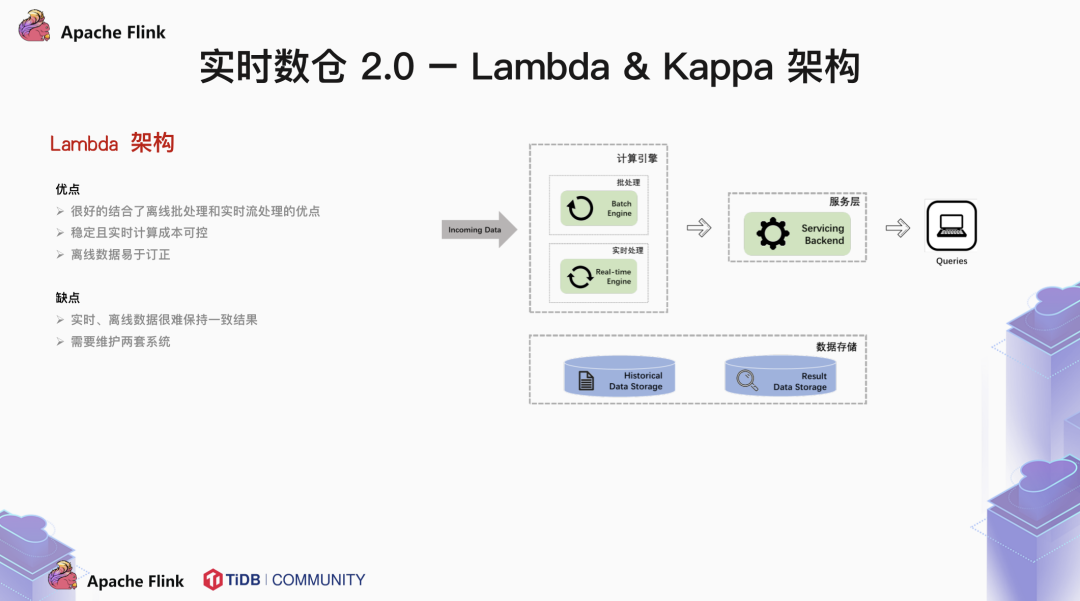
Batch enging & Real-time enging 两路架构,相互独立。
逻辑完全不同,对齐困难。
技术栈与模块多,结构复杂。
为什么不能改进流计算让他处理所有全量数据?
流计算天然的分布式性注定其扩展性一定是很好的,能够通过添加并发来处理海量数据?
那么如何使用流计算对全量数据进行重新计算呢:
1.3 Flink 架构
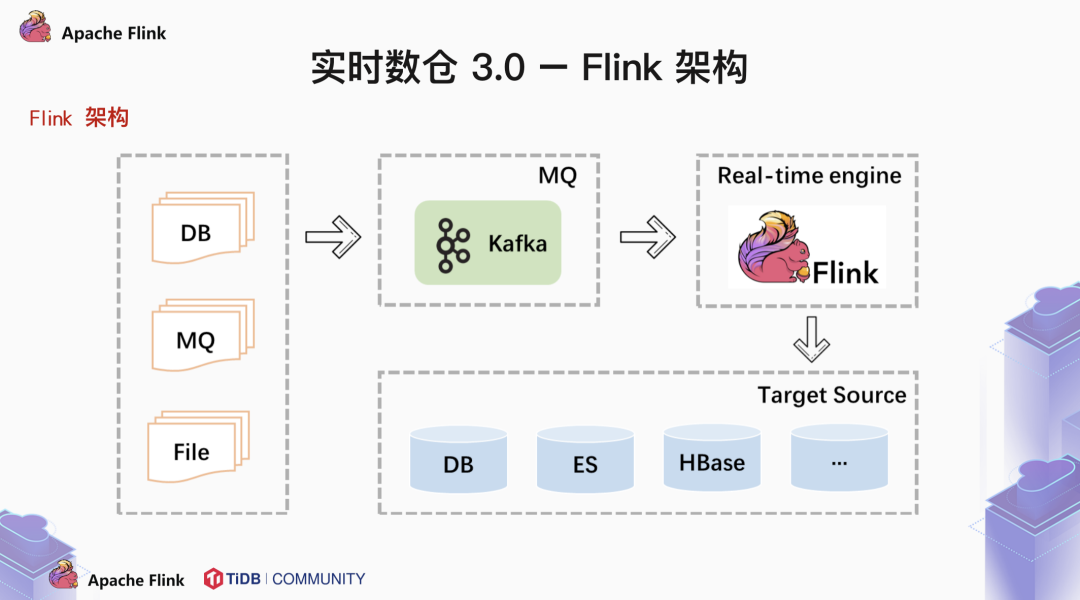
一般来说,前端不同的数据源将数据写入 MQ 中,由 Flink 消费 MQ 中的数据,做一些简单的聚合操作,最后将结果写入 OLAP 数据库中。
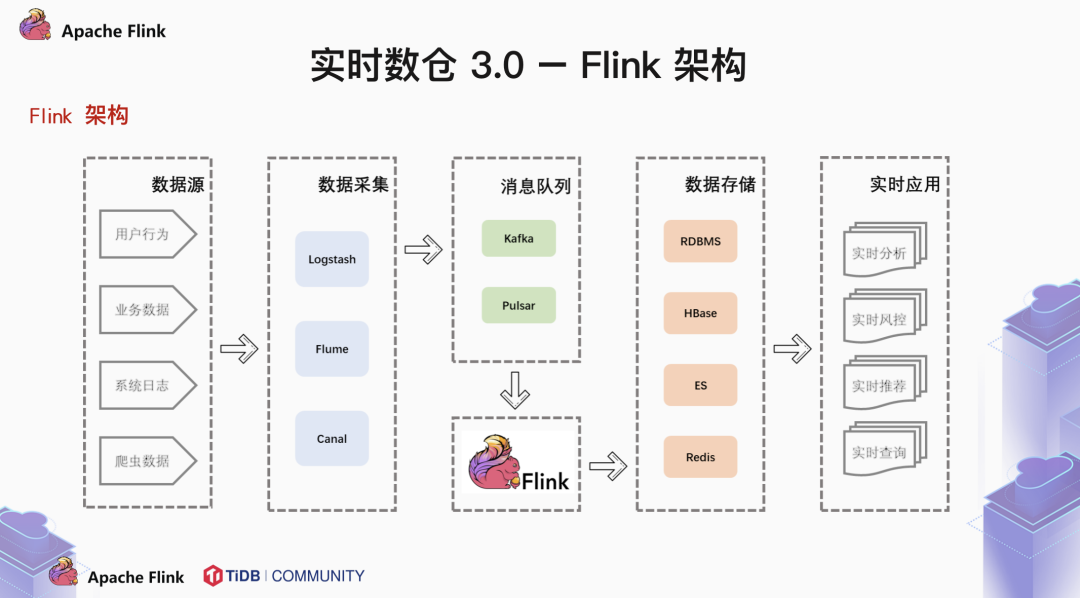
怎样才能统一规划管理数据?使用数据仓库。
如何才能实现实时处理?使用实时计算引擎。
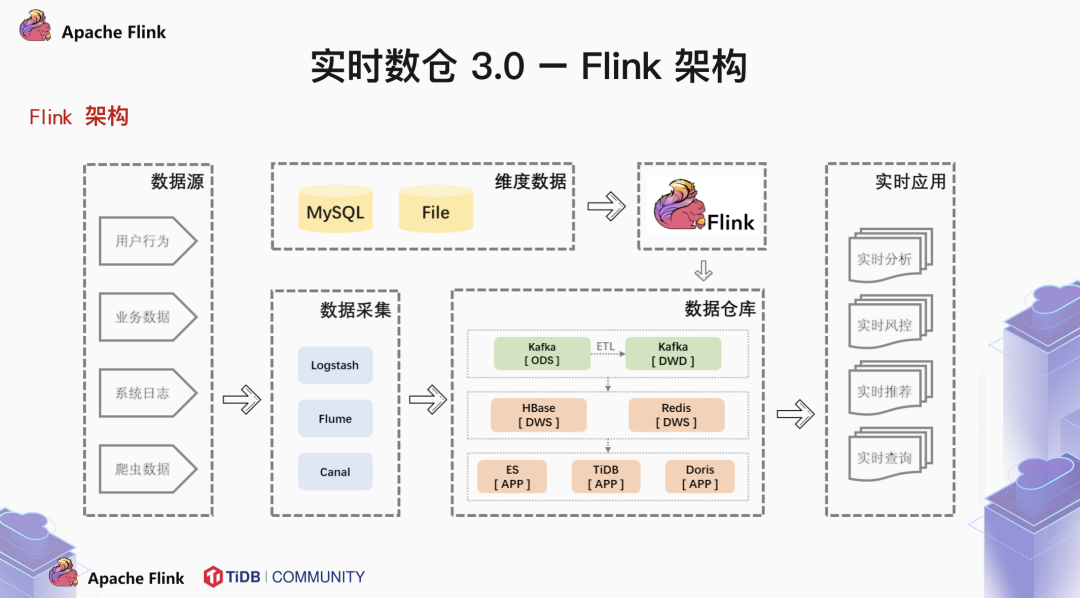
那么什么才是一个好的数据模型呢?这里我们可以借鉴一下传统的离线数仓的架构,将数据存储层细分成 ODS,DWS 和 DWS。基于这样的结构,可以统一规范,更稳定,业务适配性也更强。
1.4 实时数仓架构未来展望
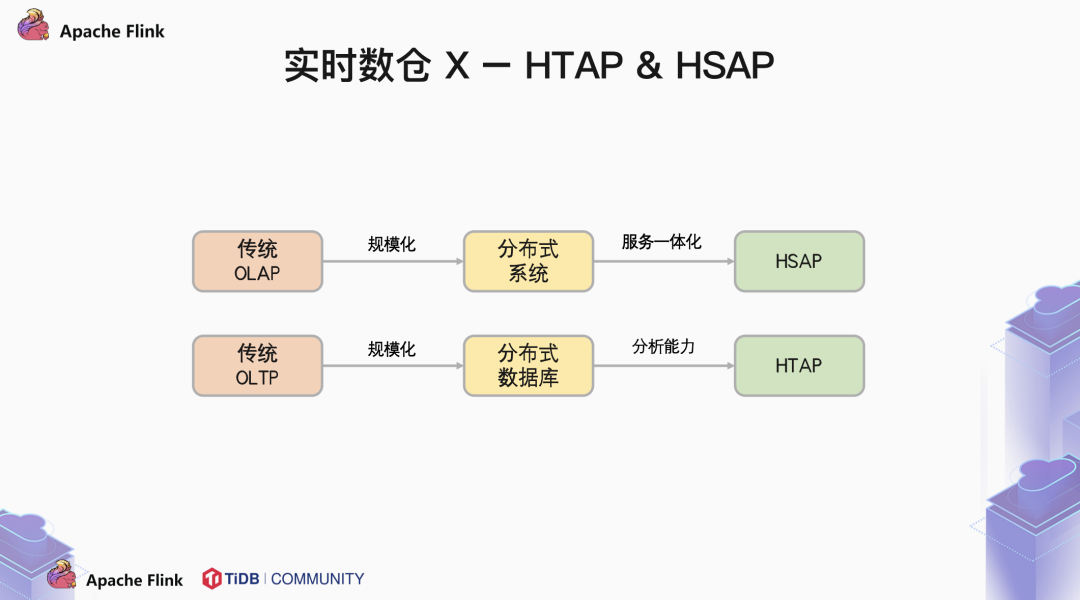
未来是一定会有第四个分水岭的。我们可以随意的畅想一下。
对于分布式 OLTP 数据库,我们通过添加分析类的引擎,最终实现将 OLTP 与 OLAP 合二为一,在使用上作为一个统一,在存储上分离,而做到 OLAP 与 OLAP 互不干扰。这种 HTAP 的架构允许我们在 OLTP 的库里面直接分析,而又不影响在线的业务,那么他会不会取代大数据系统呢?
在我看来,用户的业务数据只是交易系统的一部分。还有大量的用户行为事件,日志、爬虫数据等信息需要汇总到数仓中进行分析。如何做到技术栈的统一也是未来大数据行业需要面临的巨大的挑战。友商 hologress 已经为我们做出了一个典范。把 Flink + Holo 这一套系统服务化,用户不需要去学习和接受每个产品的问题和局限性,这样能够大大简化业务的架构,提升开发效率。当然,我也看到的是越来越多的 HTAP 产品 HSAP 化,越来越多的 HSAP 产品 HTAP 化。边界与定义越来越模糊,就好比说 TiDB 有了自己的 DBasS 服务 TiDB Cloud,Holo 也有行存和列存两种引擎。在我看到的是,越来越多的用户,将爬虫业务,日志系统接入 TiDB 中,HTAP 和 HSAP 都将成为数据库生态中不可或缺的重要组成部分。
Flink 在 TiDB 上的实时读写场景
2.1 Flink + TiDB 的生态架构全貌
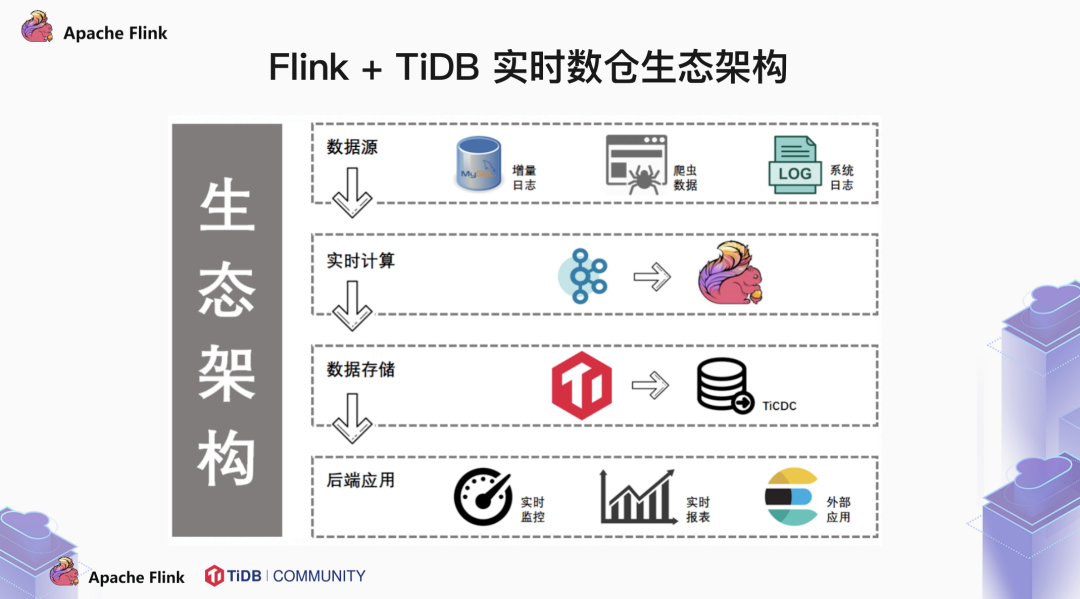
最后一层是后端应用。可能是直接连接实时监控系统,实时报表系统,也可能是将数据流入到 ES 这样的搜索引擎中,进行下一步操作。
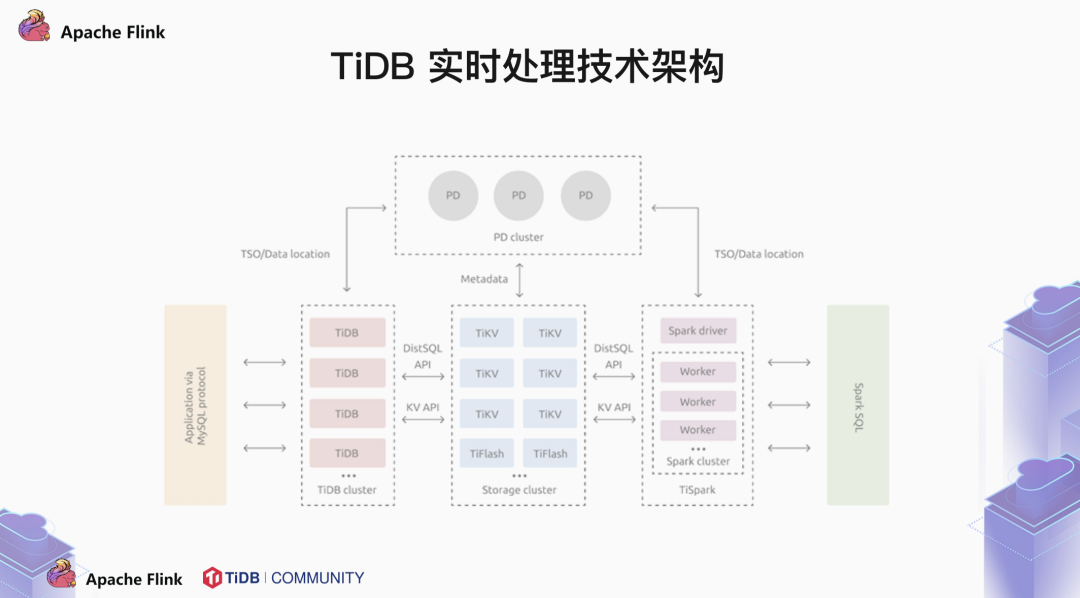
TiDB 兼容 MySQL 5.7 协议,我们常说,TiDB 是一个大号的 MySQL,其实我们希望用户能够像使用单节点的 MySQL 那样使用 TiDB。不用考虑什么分布式,不用考虑分库分表。这一切操作由 TiDB 来完成。那么 TiDB 是如何将执行计划下推的呢?这中间必然涉及到 metadata。我们的元数据存储在 PD server 中。TiDB 到 PD 中获取到数据分布的信息后再下推执行计划。所以我们也称 PD 是 TiDB 集群的大脑。
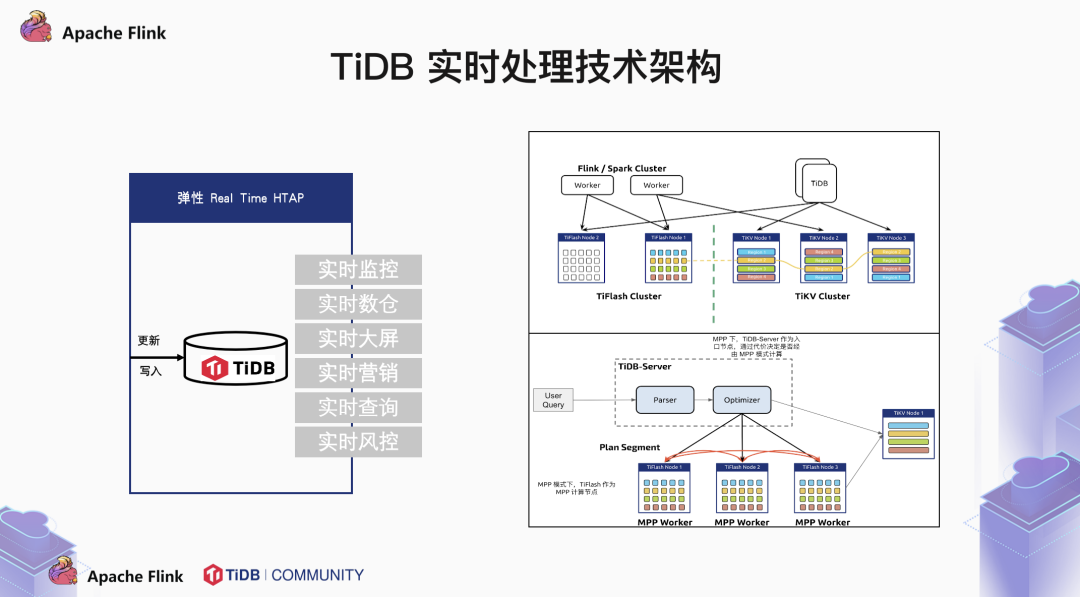
2.2 实时写入场景

其实我们一直在讨论 Flink + TiDB 的链路解决方案。消息队列这个词反复地出现。Kafka,RabbitMQ,RocketMQ 这一类 MQ 工具,主要做的就是一发,一存,一消费这三件事情。我们可以看到使用 flink-sql-connector-kafka 这个 jar 包,可以轻松地通过 Flink 消费 Kafka 的数据。

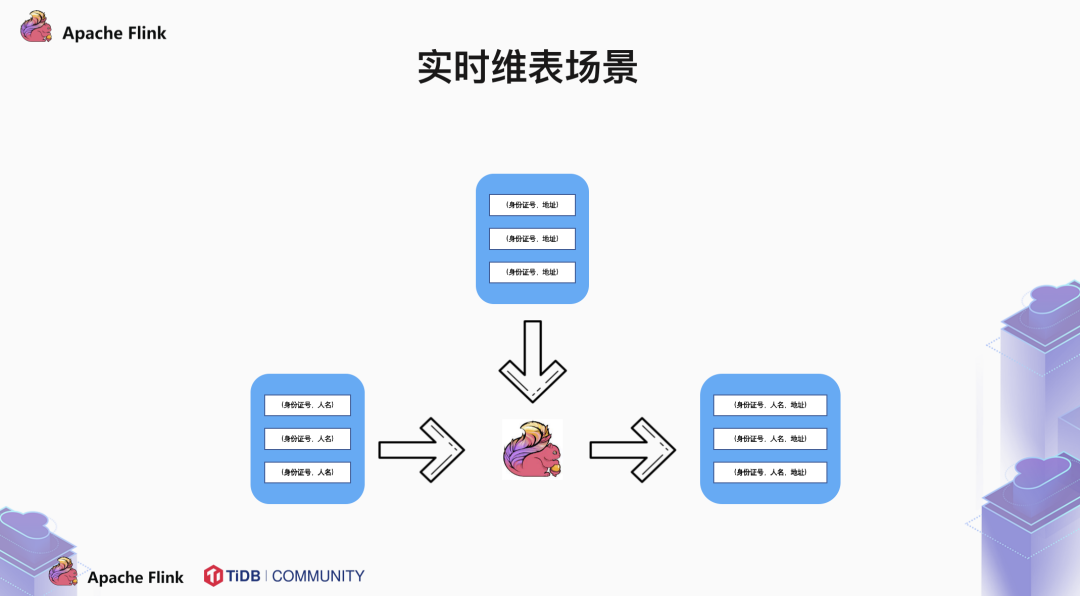
2.3 实时维表场景

2.4 CDC场景

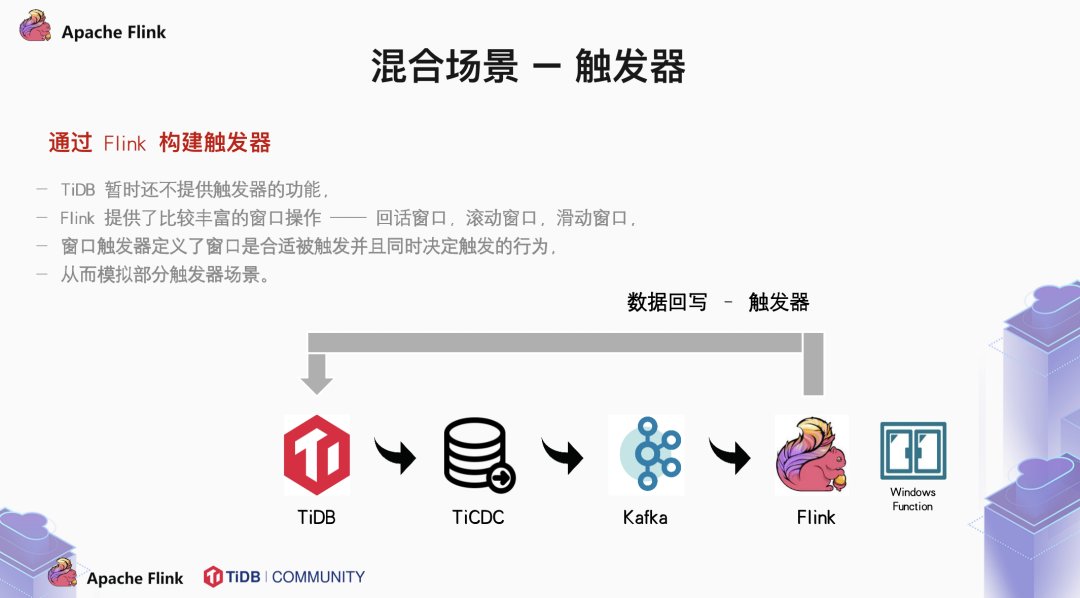
2.5 混合场景

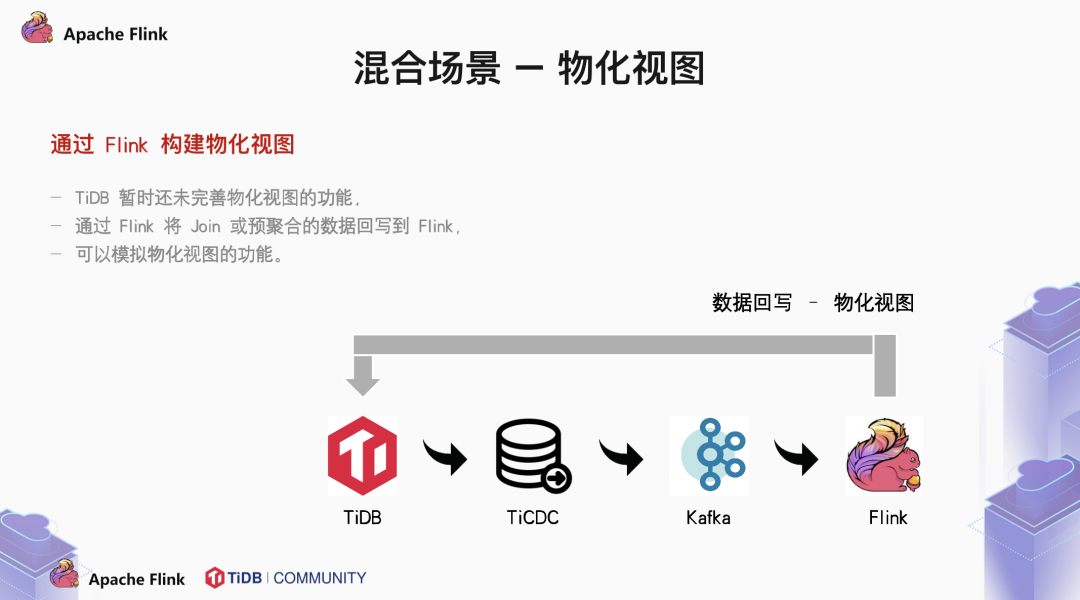
精力多的可以考虑自己手动修改源码。
精力少的可以考虑通过不同组件的拼接以搭积木的方式完善功能。
Flink + TiDB 的典型用户案例
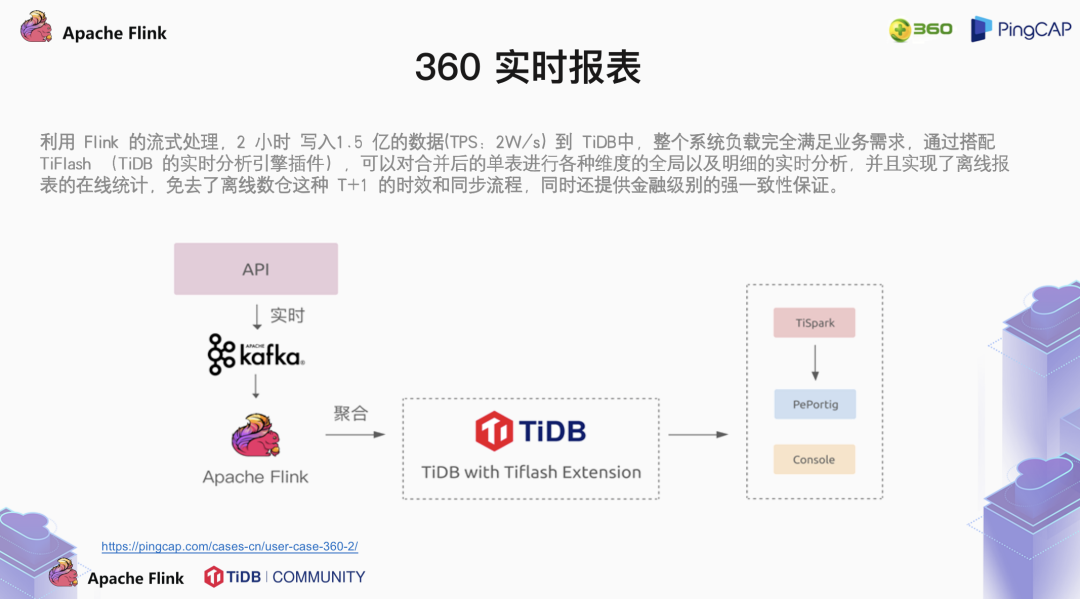
3.1 360 的实时报表案例
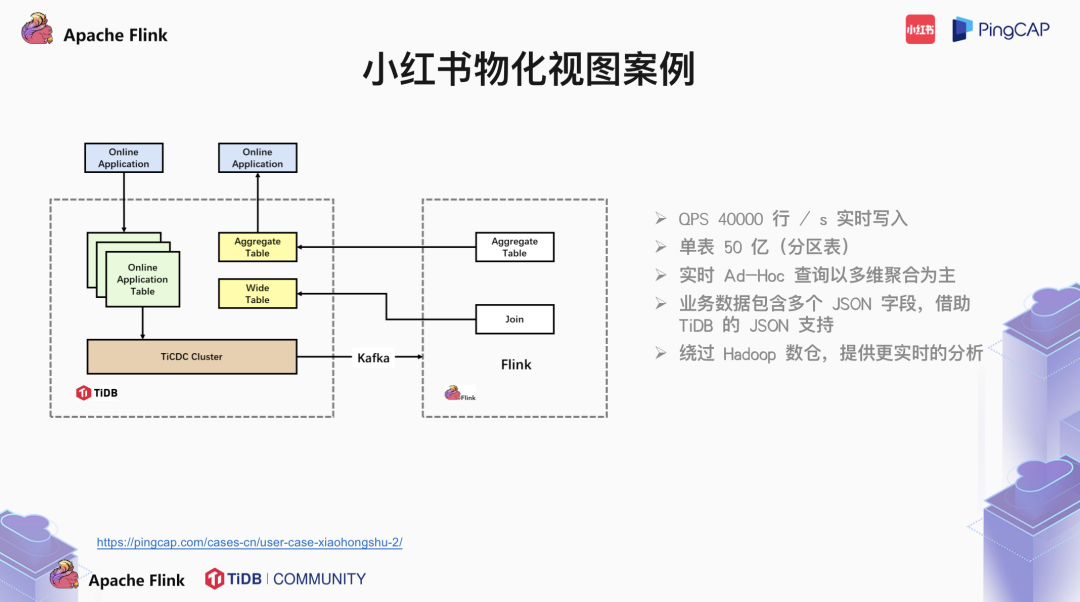
3.2 小红书的物化视图案例
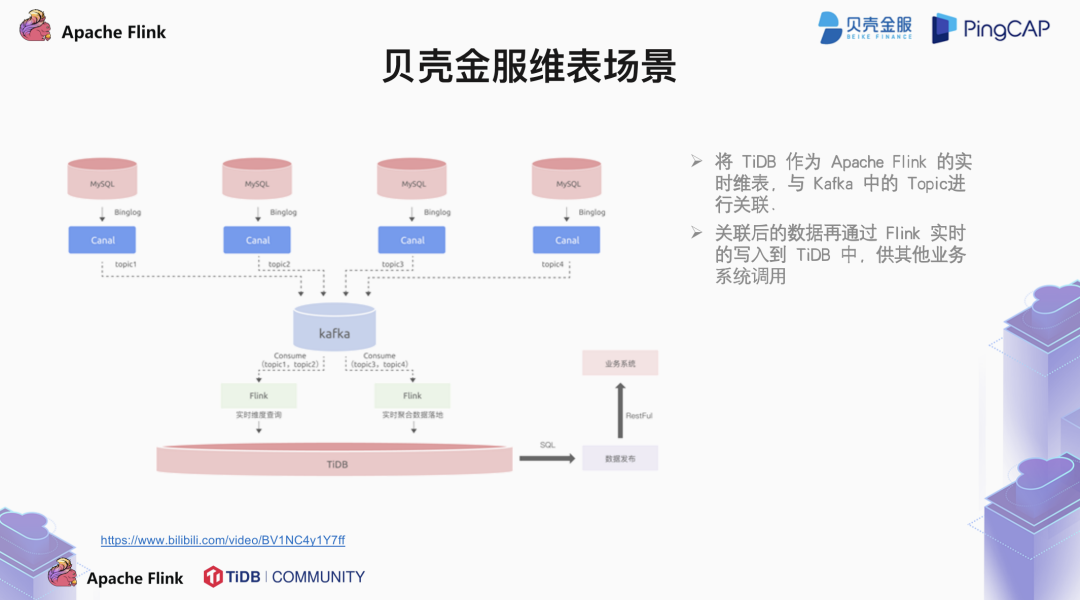
3.3 贝壳金服的实时维表案例
💡 更多 TiDB、TiKV、TiSpark、TiFlash 技术问题或生态应用可点击「阅读原文」,登录 AskTUG.com ,与更多 TiDB User 随时随地交流使用心得~
