
数据结构是如何装入 CPU 寄存器的?
内存与数据
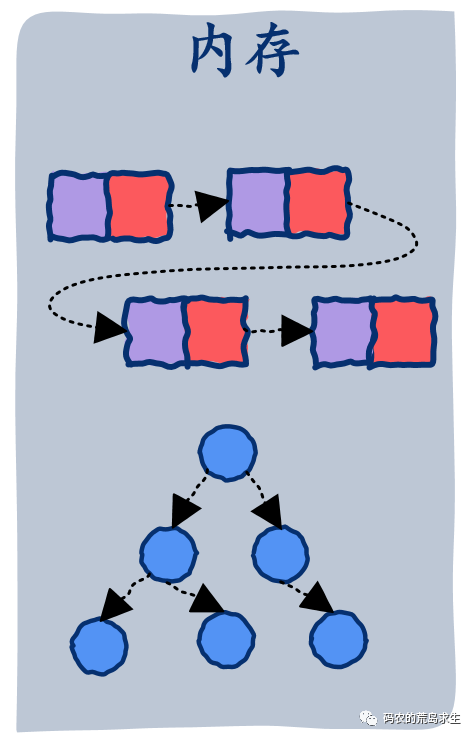
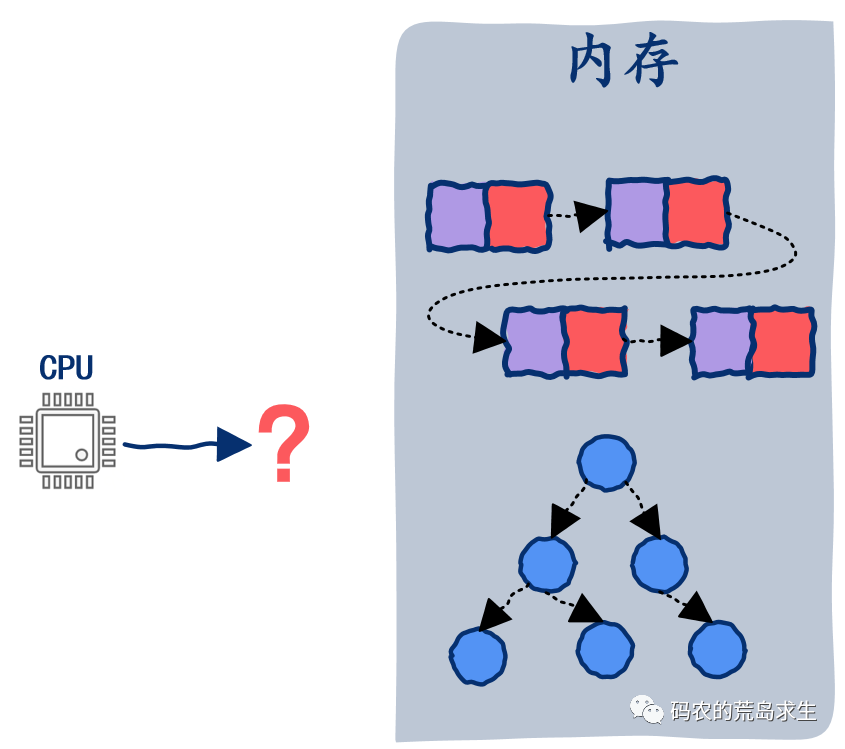
搬运数据的机器指令
int* huge_arr = new int[1 * 1024* 1024 *1024];long int sum = 0;for (int i = 0; i < 1 * 1024* 1024 *1024; i++) {sum += huge_arr[i];}
sum += huge_arr[i];
load $r0 100($r2)add $r1 $r1 $r0
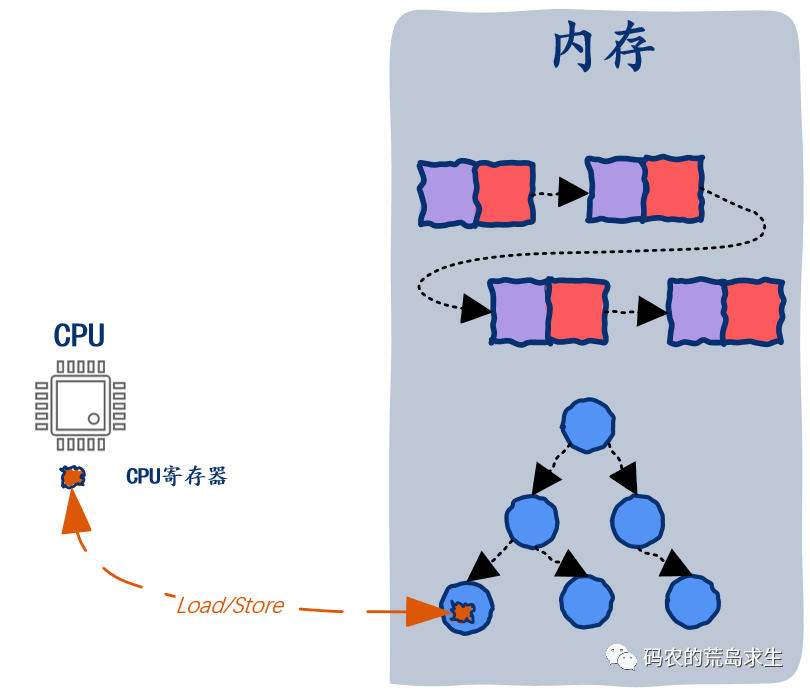
编译器
总结
评论