
(三)RASA NLU语言模型
作者简介
原文:https://zhuanlan.zhihu.com/p/331791105
转载者:杨夕
面筋地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study

什么时候要用语言模型?我们前面讲过,RASA整体就是pipeline结构,NLU,DST,DPL一系列处理下来,执行一个动作。而NLU模块也是一个可细分pipeline结构,过程是Tokenize->Featurize->NER Extract->Intent Classify。熟悉Word2Vec的知友知道,如果要获取句子的word2vec特征,首先要有个分词器,然后要有个word2vec模型。同理,如果Rasa NLU里面引用预训练的语言模型,那就需要提前加载,如果Tokenize使用空格分词或者结巴分词,特征向量使用One-hot编码或者CountVectorsFeaturizer编码,那就不在需要语言模型了。
RASA里面的语言模型有:
MITIENLP
mitie 基于dlib库开发,dlib是一个c++高性能机器学习库。所以对性能有要求的信息抽取场景,可以考虑使用mitie。mitie现有的资料比较少,github最近更新也是五六年前了。
从mitie代码中看到它的NER使用structural_sequence_labeling_trainer.实现的细节见
https://www.aaai.org/Papers/ICML/2003/ICML03-004.pdf
文中指出,MITIE的NER是HMM 和SVM相结合做的。相比单纯的HMM,这种方法是基于最大margin 标准。这相比纯CRF或者最大熵的HMM有很多优势:
1)可以通过核函数学习非线性的判断关系
2)可以处理overlapping features.
但毕竟是基于传统机器学习的方式,相对于BERT这种海量语料预训练模型来说,效果还是稍差一点,这个可以使用RASA的NLU评估工具跑分试一下[NLU pipelines评估]。但MITIE有无可比拟的速度优势,在算力敏感的情况下自己权衡选择,RASA已经不做官方推荐了。
使用前先下载mitie模型
github.com/mit-nlp/MITI
RASA配置使用MITIENLP
pipeline: - name: "MitieNLP" model: "data/total_word_feature_extractor.dat"另外,MITIE没有预训练的中文模型,如果想开发中文机器人,需要自己训练语言模型。具体参考用Rasa NLU构建自己的中文NLU系统。
SpaCyNLP
spaCy是一个用Python和Cython编写的高级自然语言处理的库。它跟踪最新的研究成果,并将其应用到实际产品。spaCy带有预训练的统计模型和单词向量,目前支持60多种语言。它用于标记任务,解析任务和命名实体识别任务的卷积神经网络模型,在非常快速的情况下,达到比较好的效果,并且易于在产品中集成应用。在github上接近18k的stars,并且更新比较活跃。最新发布的spaCy3.0也集成了Transformer相关模型。
使用spaCy时,文本字符串的第一步是将其传递给NLP对象。NLP对象本质上是由几个文本预处理操作组成的管道,输入文本字符串通过管道后,最终输出文档,完成各种功能。
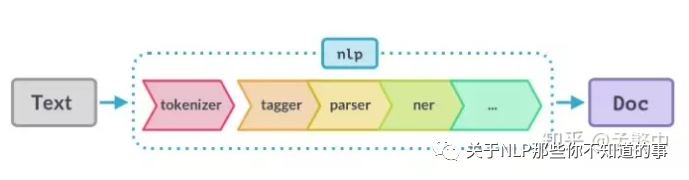
上图示意了这个过程,在nlp对象中,要引入预训练spacy的语言模型。
spacy的中文模型的下载地址:
https://github.com/explosion/spacy-models也可以在命令行中输入:
python -m spacy download zh_core_web_smRASA中模型加载方式
pipeline:
- name: "SpacyNLP"
model: "zh_core_web_sm"下表显示了SpaCy在各个任务中的得分

以前还有一个HFTransformersNLP,里面主要包含一些BERT,GTP等比较新的Transformer模型,现在已经在LanguageModelFeaturizer中实现了,不在需要在pipeline里面配置HFTransformersNLP语言模型。