
【推荐】7个强大实用的Python机器学习库!
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
来源:今日头条-IT技术资源爱好者
https://www.toutiao.com/article/7179178014276698662/

Prophet 是 Facebook 开源的时间序列预测工具库,基于 Stan 框架,可以自动检测时间序列中的趋势、周期性和节假日效应,并根据这些信息进行预测。这个库在 GitHub 上有超过 15k 星。
# Pythonforecast = m.predict(future)forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()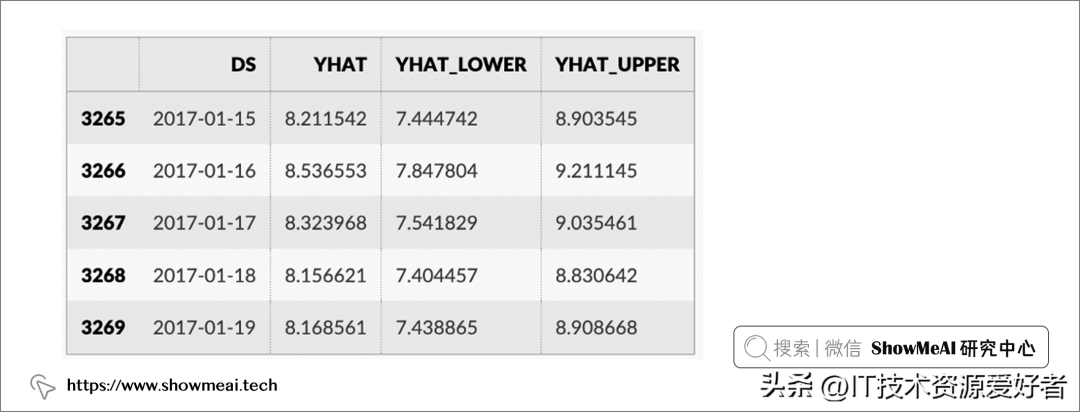
2.Deep Lake

for epoch in range(2): running_loss = 0.0 for i, data in enumerate(deeplake_loader): images, labels = data['images'], data['labels'] # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(images) loss = criterion(outputs, labels.reshape(-1)) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 100 == 99: #print every 100 mini-batches print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100)) running_loss = 0.03.Optuna

import ... # Define an objective function to be minimized.def objective(trial): # Invoke suggest methods of a Trial object to generate hyperparameters regressor_name = trial.suggest_categorical('regressor',['SVR', 'RandomForest']) if regressor_name = 'SVR': svr_c = trial.suggest_float('svr_c', 1e-10, 1e10, log=True) regressor_obj = sklearn.svm.SVR(C=svr_c) else: rf_max_depth = trial.suggest_int('rf_max_depth', 2, 332) regressor_obj = sklearn.ensemble.RandomForestRegressor(max_depth=rf_max_depth) X, y = sklearn.datasets.fetch_california_housing(return_X_y=True) X_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X, y, random_state=0) regressor_obj.fit(X_train, y_train) y_pred = regressor_obj.predict(X_val) error = sklearn.metrics.mean_squared_error(y_val, y_pred) return error # An objective value linked with the Trial object. study = optuna.create_study() # Create a neW studystudy.optimize(objective, n_trials=100) # Invoke opotimization of the objective function4.pycm

它可以计算多种常用的指标,包括准确率、召回率、F1值、混淆矩阵等。此外,pycm 还提供了一些额外的功能,例如可视化混淆矩阵、评估模型性能的指标来源差异等。pycm是一个非常实用的库,可以帮助快速评估模型的性能。
from pycm import *y_actu = [2, 0, 2, 2, 0, 1, 1, 2, 2, 0, 1, 2] y_pred = [0, 0, 2, 1, 0, 2, 1, 0, 2, 2, 2, 2] cm = ConfusionMatrix(actual_vector=y_actu, predict_vector=y_pred) cm.classes cm.print_matrix() cm.print_normalized_matrix()5.NannyML

为数据科学家设计的 NannyML 具有易于使用的交互式可视化界面,目前支持所有表格式的用例(tabular use cases)、分类(classification)和回归(regression)。NannyML 的核心贡献者研发了多种用于估算模型性能的新算法:基于信心的性能估算(CBPE)与直接损失估算(DLE)等。NannyML 通过构建“性能监控+部署后数据科学”的闭环,使数据科学家能够快速理解并自动检测静默模型故障。通过使用 NannyML,数据科学家最终可以保持对他们部署的机器学习模型的完全可见性和信任。
import nannyml as nmlfrom IPython.display import display # Load synthetic data reference, analysis, analysis_target = nml.load_synthnetic_binary_classification_dataset()display(reference.head())display(analysis.head()) # Choose a chunker or set a chunk sizechunk size = 5000 # initialize, specify required data columns,, fit estimator and estimateestimator = nml.CBPE( y_pred_proba='y_pred_proba', y_pred='y_pred', y_true='work_home_actual', metrics=['roc_auc'], chunk_size=chunk_size, problem_type='classification_binary',)estimator = estimator.fit(reference)estimated_performance = estimator.estimate(analysis) # Show resultsfigure = estimated_performance.plot(kind='performance', metric='roc_auc', plot_reference=True)figure.show()6.ColossalAI

ColossalAI 提供了一系列预定义的模型和模型基础架构,可用于快速构建和训练模型。它还提供了一系列工具,用于模型评估,调优和可视化,以确保模型的高质量和准确性。此外,ColossalAI 还支持部署模型,使其能够通过各种不同的接口与其他系统集成。ColossalAI 的优势在于它易于使用,可以为数据科学家和机器学习工程师提供快速和有效的方法来构建和部署高质量的大型模型。
from colossalai.logging import get_dist_loggerfrom colossalai.trainer import Trainer, hooks # build components and initialize with colossaalai.initialize... # create a logger so that trainer can log on thhe consolelogger = get_dist_logger() # create a trainer objecttrainer = Trainer( engine=engine, logger=logger)7.emcee
import numpy as npimport emcee def log_prob(x, ivar): return -0.5 * np.sum(ivar * x ** 2) ndim, nwalkers = 5, 100 ivar = 1./np.random.rand(ndim)p0 = np.random.randn(nwalkers, ndim) sampler = emcee.EnsembleSampler(nwalkers, ndim, log_prob, args=[ivar])sampler.run_mcmc(p0, 10000)总结
本文仅做学术分享,如有侵权,请联系删文。