
使用多尺度空间注意力的语义分割方法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Abhinav Sagar
编译:ronghuaiyang
用于自动驾驶的新的state of the art的网络。

本文提出了一种新的神经网络,利用不同尺度的多尺度特征融合来实现精确高效的语义分割。
我们在下采样部分使用了膨胀卷积层,在上采样部分使用了转置卷积层,并在concat层中对它们进行拼接。 alternate blocks之间有跳跃连接,这有助于减少过拟合。 我们对我们的网络训练和优化细节进行了深入的理论分析。 我们在Camvid数据集上使用每个类的平均精度和IOU作为评价指标来评估我们的网络。 我们的模型在语义分割上优于之前的state of the art网络,在超过100帧每秒的速度下,平均IOU值为74.12。
语义分割需要对输入图像的每个像素预测一个类,而不是对整个输入图像进行分类。为了预测图像中每个像素的内容,分割不仅需要找到输入图像中的内容,还需要找到它的位置。语义分割在自动驾驶、视频监控、医学影像等方面都有应用。这是一个具有挑战性的问题,因为要在准确性和速度之间进行权衡。由于模型最终需要在现实环境中部署,因此精度和速度都应该很高。
在训练和评估中使用了CamVid数据集。数据集提供了ground truth标签,将每个像素与32个类中的一个相关联。图像大小为360×480。数据集的ground truth样本图像如图1所示:
将原始图像作为ground truth。对于任何算法,总是在与ground truth数据的比较中进行指标的评估。在数据集和测试集中提供ground truth信息用于训练和测试。对于语义分割问题,ground truth包括图像、图像中目标的类别以及针对特定图像中每个目标的分割掩模。对于图2中的12个类别,这些图像分别以二进制格式显示:

这些类别为:Sky, Building, Pole, Road, Pavement, Tree, SignSymbol, Fence, Car, Pedestrian 和 Bicyclist.
对网络结构的解释如下:
我们将原来360×480像素的图像调整为224×224像素。 我们将数据集分成两个部分,训练集中有85%的图像,测试集中有15%的图像。 使用的损失函数是分类交叉熵。 我们用扩张卷积来代替下采样层中的普通卷积层这是用来减少特征图的,用转置卷积来代替上采样层中的普通卷积层来恢复特征。 我们在图层之间使用concat操作来合并不同尺度的特征。 对于convolutional layer我们没有使用任何padding,使用3 * 3 filter,并且使用relu作为激活函数。对于最大池化层,我们使用2×2的过滤器和2×2的步长。 我们使用VGG16作为训练模型的预训练主干。 在最后一层使用Softmax作为激活函数,输出一个物体是否存在于一个特定像素位置的离散概率。 我们使用adam作为优化器。 为了避免过拟合,我们使用了我们认为最优的batch size值4。
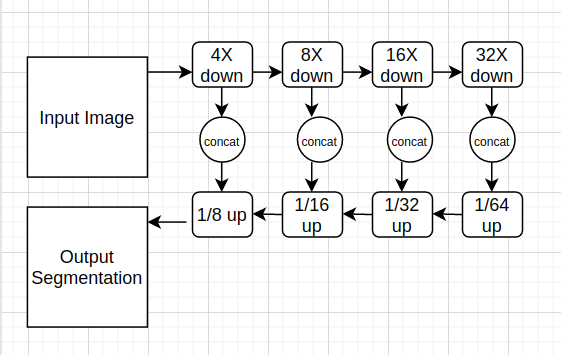
本工作中使用的网络结构图3所示:
假设给定一个局部特征C,我们将其输入一个卷积层,分别生成两个新的特征图B和C。对A与B的转置进行矩阵乘法,应用softmax层计算空间注意力图,定义如下式:
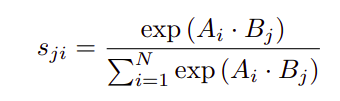
我们在X和A的转置之间进行矩阵乘法并reshape它们的结果。然后将结果乘以一个尺度参数β,并与A进行元素和运算,得到最终的输出结果如下式所示:

由上式可知,得到的各通道特征是各通道特征的加权和,并模拟了各尺度特征图之间的语义依赖关系。主干网络以及子阶段聚合方法可表示为:
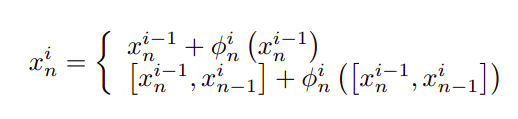
这里i指的是stage的索引。
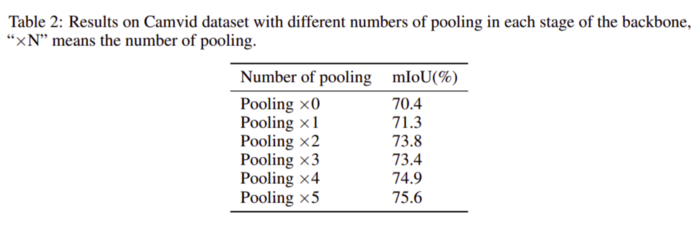
池化层的数量对IOU的影响如表2所示。
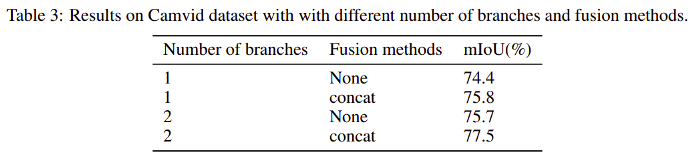
模型架构中使用的分支数和融合方法对IOU的影响如表3所示。
模型训练了40个epoch,训练的平均像素精度为93%,验证的平均像素精度为88%。损失和像素级精度(训练和测试)被绘制成epoch的函数,如图4所示:
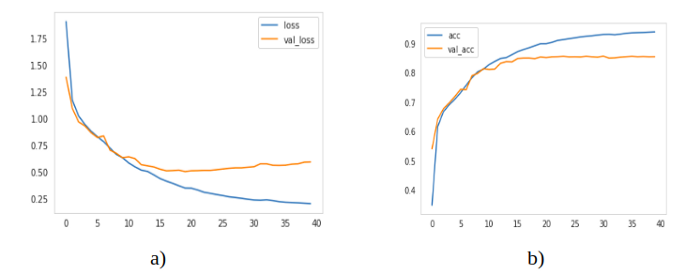
图4:a) Loss vs epochs b) Accuracy vs epochs
对于评价,使用了以下两个指标:
1、每个类的平均精度:这个度量输出每个像素的类预测精度。
2、平均IOU:它是一个分割性能参数,通过计算与ground truth掩模之间的交集和并集的比来度量两个目标之间的重叠率。
按类别计算IOU值的方法如下所示。

其中TP为真阳性,FP为假阳性,FN为假银性,IOU表示交并比。
使用多个block、FLOPS和参数对IOU的影响如表5所示。在这里,FLOPS和参数是我们的模型架构所需要的计算量的度量。
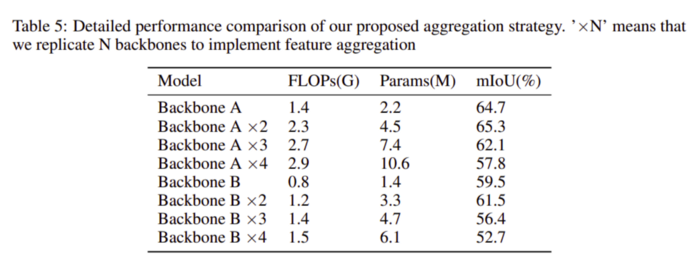
表6中显示了之前的stage和我们的模型结构所实现的FPS和IOU的比较分析。

将预测的分割结果与来自数据集的ground truth图像进行比较,结果如图5所示。
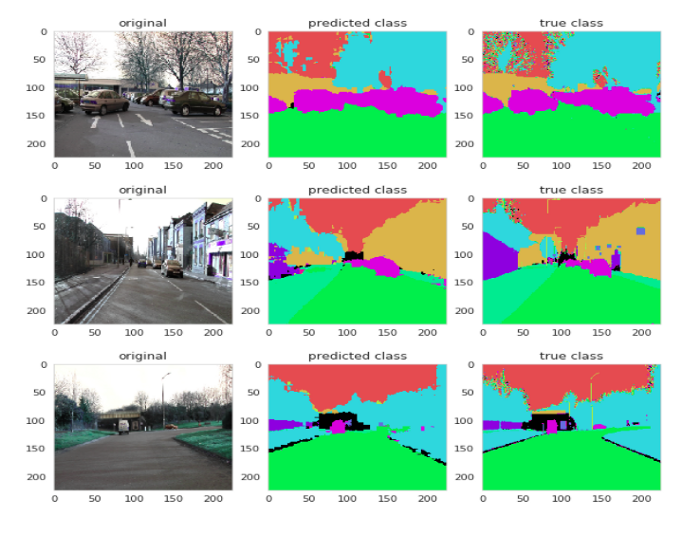
图5:预测图像的结果 —— 第一列来自dataset的原始图像,第二列来自network的预测图像,第三列来自dataset的ground truth图像
本文提出了一种基于多尺度关注特征图的语义分割网络,并对其在Camvid数据集上的性能进行了评价。我们使用了一个下采样和上采样结构,分别使用了扩展卷积和转置卷积层,并结合了相应的池化层和反池化层。我们的网络在语义分割方面的表现超过了以往的技术水平,同时仍能以100帧每秒的速度运行,这在自动驾驶环境中非常重要。
论文地址:https://abhinavsagar.github.io/files/sem_seg.pdf
代码:https://github.com/abhinavsagar/mssa

英文原文:https://towardsdatascience.com/semantic-segmentation-with-multi-scale-spatial-attention-5442ac808b3e
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~