
内部群炸了锅,隔壁同事真删库了啊。。
事件起因
我们的系统中有数据导入的功能,可以把特定的格式的 excel 数据导入到系统中来。
由于客户电脑的文件比较多,很多文件的名字也比较相近,客户在导入 excel 时选错了文件。
这个错误的 excel 文件的格式恰好能被系统解析,客户也没及时发现导错了文件,所以就将 6 万多条没用的数据导入到了系统中。

这 6 万多条数据对系统来说就是无用的数据,不会影响系统的运行,最多也就是占用一点数据库空间而已。
客户只需要把正确的 excel 重新导入,就可以继续完成他的业务了。
但是,客户是一个重度强迫症患者,他觉得在管理平台看到这 6 万多条没用的数据令他抓狂。
客户想要把这些数据删除,我们系统又没有提供批量删除功能,只能单个删除,这无疑是一个巨大的工作量。
客户就通过客服部门找到了研发团队,想让我们研发人员从数据库中直接删除。
删库经过
虽然在生产环境直接操作数据库明显是违规操作,但客户的要求又不得不满足,谁让人家是爸爸呢?

由于生产环境的数据和表结构属于商业机密,我们讨论的重点也不在于数据和表结构,而是数据恢复的思路。所以我在测试环境新建了用户表,导入了一些测试数据,当作是生产环境进行操作
研发人员登录生产数据库,执行如下 sql,找到了这 6 万多条错误数据。
select * from t_user where age>18 and deptid=100;
在确认这 6 万多条数据确实是错误导入的数据后就准备开始删除。由于表里面没有逻辑删除字段,所以只能进行物理删除。
需要删除的数据已经确定,通常情况下把 sql 中的select *替换为delete去执行,出错的机率会小一点。
但是,研发人员并没有去改原来的 sql,而是重新写了一个删除语句并且执行。
delete from t_user where age>18;
问题就这样出现了,在新写的删除语句中缺少了deptid=100的条件
不要问我为什么删除之前没有备份,这都是血泪的教训
重新查表后发现误删了 10 多万条数据。
生产环境中,很多业务都依赖这个表,算是系统的核心表。虽然是只删除了 10 万条数据,但系统的很多功能无法正常使用,其实和删库没啥区别了。

研发人员发现删库后,第一时间报告给了领导(居然没有第一时间跑路)。
领导当机立断,要求系统停止运行,给所有客户发送停服通知,打开所有客服通道,处理客户投诉和答疑。
同时,也安排研发人员进行数据找回,要求尽快搞定。
数据找回
我们找到删库的研发人员询问他有没有备份,他的回答是没有。
我们又去咨询运维的同事,看看生产环境有没有开启数据库定期自动备份,运维的回答也是没有。
事情比较难办了,只能把希望寄托于 mysql 的 binlog 了。
binlog 二进制日志文件,数据库的 insert、delete、update、create、alter、drop 等写入操作都会被 binlog 记录(下文对 binlog 有详细介绍)。
binlog 记录日志是需要开启配置的,希望生产环境的 mysql 数据库开启了 binlog 日志,否则只能找专业的磁盘数据恢复的第三方公司了。
登录生产环境数据库,查看 binlog 是否开启。
SHOW VARIABLES LIKE 'LOG_BIN%';

从图中可以看到log_bin是处于ON的状态,说明 binlog 是开启的。
悬着的心终于放下了一大半,接下来就是想办法从 binlog 中把数据恢复就行了。
从上图中也可以看到log_bin_basename是/var/lib/mysql/bin-log,说明 binlog 是存放在 mysql 所在的服务器的/var/lib/mysql目录下,文件是以bin-log开头,比如:bin-log.000001。
登录 mysql 所在的服务器,进入到 binlog 所在的目录。
cd /var/lib/mysql
查看 binlog 日志文件。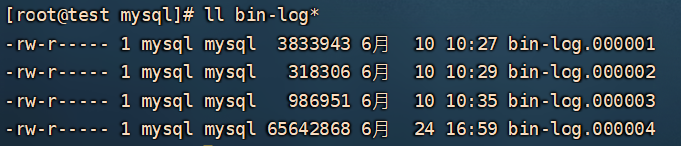
binlog 日志文件是滚动生成的,从图中看到现在已经有 4 个文件了。
通常情况下,生产环境的 binlog 会有成百上千个,这时候就需要确认我们需要的数据是在第几个 binlog 中了,下文也会讲怎么确定我们需要的是第几个。
因为我们删库是刚刚发生的事情,所以我们需要的数据大概率是在第 4 个文件中。
直接去查看第 4 个 binlog 文件,看到的全都是乱码,就像下面这样,这是因为 binlog 文件是二进制的。

我们需要借助 mysql 官方提供的mysqlbinlog命令去才能正确解析 binlog 文件。
用 mysqlbinlog 命令可以打开 binlog 文件,但是一个 binlog 文件的大小可能有几百兆,要从几百兆日志中找到我们需要的日志,还是比较麻烦的。
还好 mysqlbinlog 命令提供一些参数选项可以让我们对 binlog 文件进行筛选,最常用的参数就是时间参数(下文也会对 mysqlbinlog 的详细用法进行说明)。
经过和删库的研发人员确定,删库的时间大概是**「10:40」**,那我们就以这个时间点为参考,找前后 5 分钟的日志。
mysqlbinlog -v --start-datetime='2021-06-10 10:35:00' --stop-datetime='2021-06-10 10:45:00' bin-log.000004 | grep t_user

从图中可以看到,这个时间点的日志确实包含我们删除数据的日志。
接下来我们就需要把这些日志整理一下,然后想办法恢复到数据库就可以了。
首先,把我们需要的日志单独保存到 tmp.log 文件中,方便下载到本地。
mysqlbinlog -v --start-datetime='2021-06-10 10:35:00' --stop-datetime='2021-06-10 10:45:00' bin-log.000004 > tmp.log
把 tmp.log 下载到本地,用文本编辑工具打开看一下,可以看到一堆伪 sql。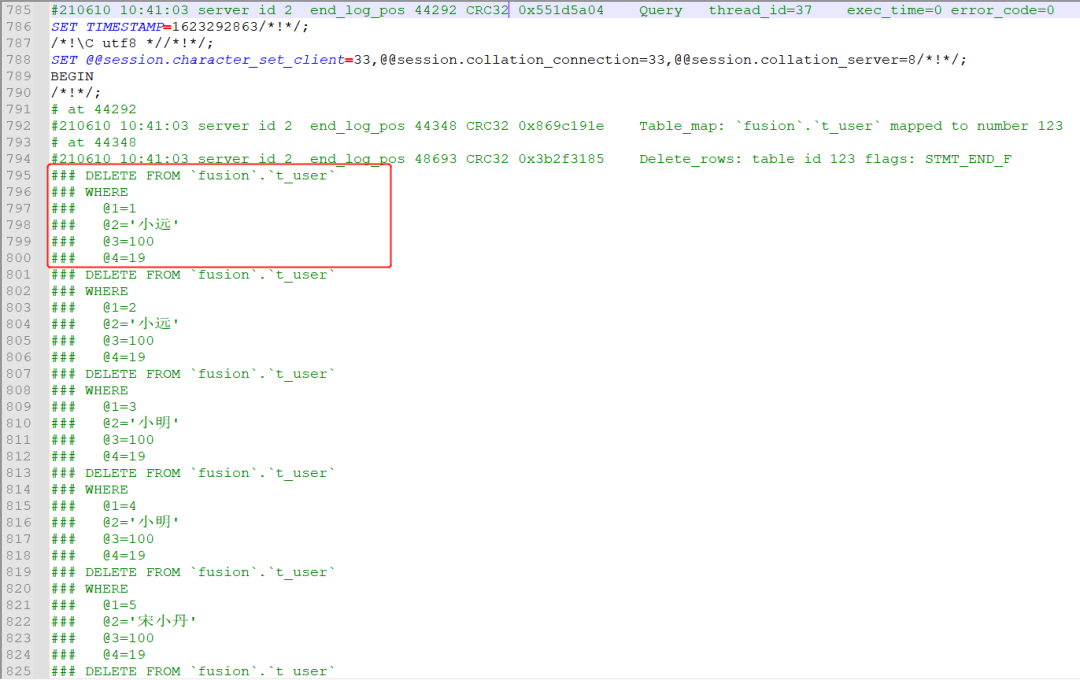
在上图的伪 sql 中 @1 表示第一个字段 @2 表示第二个字段 其他的以此类推
日志中包含的 sql 是一些伪 sql,并不能直接在数据库执行,我们需要想办法把这些伪 sql 处理成可在数据库执行的真正的 sql。
我们使用的文本编辑工具的批量替换功能,就像下面这样: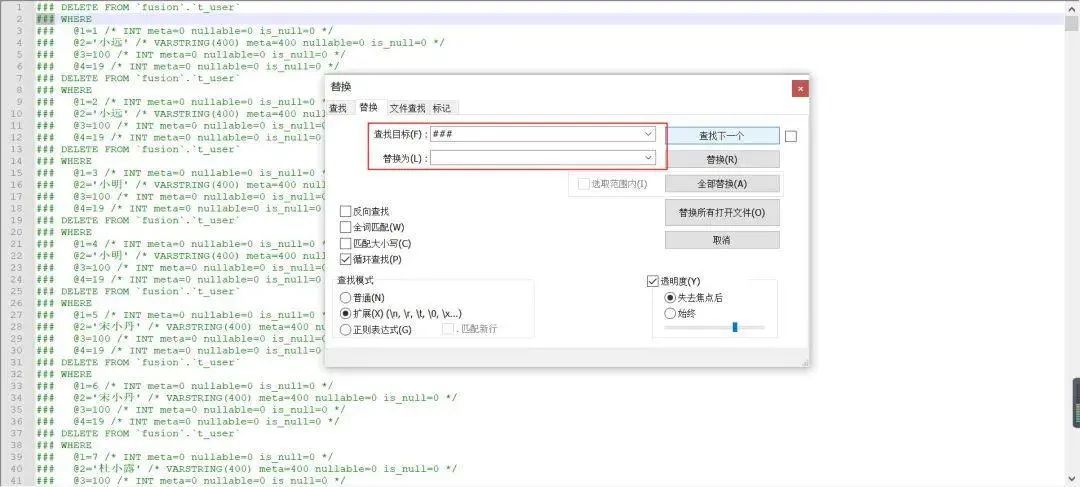
最终处理好的 sql 就像是这样: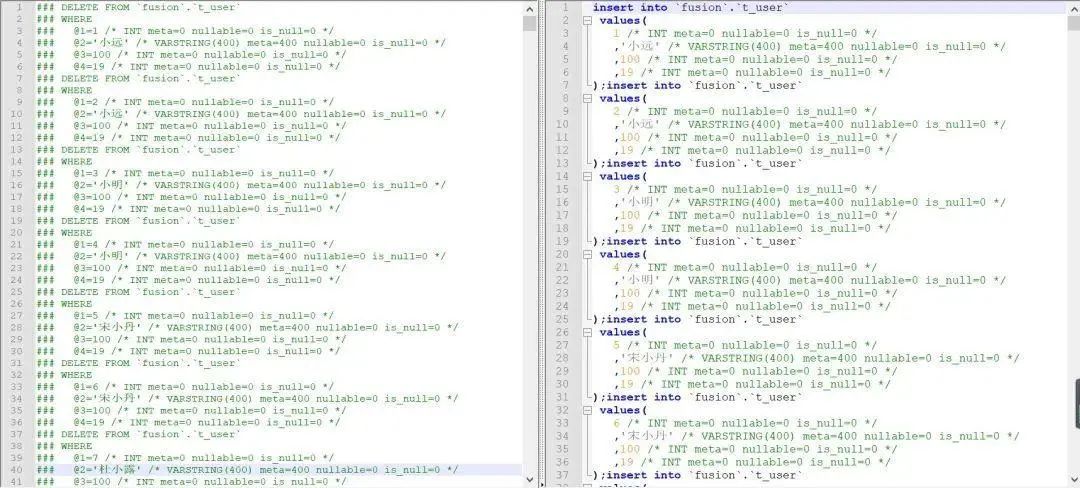
把处理好的 sql 在测试数据库验证一下没问题后直接在生产库执行。
sql 执行完以后,被误删除的数据就恢复回来了。
我们和删库的研发一起,把客户要求删除的 6 万多条数据重新给删除,算是完成了客户的要求。
至此,删库事件就暂时告一段落。不要问删库的研发受到了什么处分,问就是什么处分都没有。
几点建议
删库跑路真的不只是一句玩笑话,如果真的不小心删库了而又无法找回数据的话,不仅仅是简单的罚款、扣绩效就完事了,甚至有可能会面临牢狱之灾。
对于公司来说,一个不小心的删库操作,就有可能把公司删没了。毕竟删库造成的数据损失、经济损失不是所有公司都有能力承担的。
所以,生产环境的数据安全一定是重中之重。根据我多年的删库经历,也总结了一些经验分享给你们,希望对你们有所帮助。
「1、研发人员不能直连生产库」
生产库一般由 DBA 或者运维来维护,研发人员很少有需要登录生产数据库查看数据的需求,就算数据真的有问题,一般情况下 DBA 或运维人员也能解决。
如果一个系统需要研发人员频繁的登录数据库去维护数据,这时就该考虑在系统中增加一个管理功能来使用,而不是频繁登录数据库。
所以,研发就不应该具有生产库的登录权限。如果偶尔的需要登录生产库查看数据,可以找 DBA 开一个临时账号。
「2、登录生产库使用只读账号」
大部分人使用数据库都会使用连接工具,比如 Navicat、SQLyog 等
每个人的电脑上,大概率也只有一个连接工具。开发库、测试库、生产库都在同一个连接工具中打开,有时只是想在开发库中修改一条数据,却不小心修改了生产库。
而 MySql 的事务是自动提交的,在连接工具中,正在修改的当前行失去光标后就会自动提交事务,极其容易操作失误。
所以,如果确实的需要登录生产库,尽量使用具有只读权限的账号登录。
「3、关闭 autocomit、多人复核」
如果确实需要在生产库进行数据的增加、修改或删除,在执行 sql 之前最好先关闭事务的自动提交。
在需要登录生产库修改数据的情况下,想必问题也比较复杂,一条 sql 语句应该是完成不了,可能需要写 N 多个 sql 才能完成数据的修改。
这么多的 sql,很有可能在执行的时候会选错。有时你只是想执行一个 select 语句,结果发现执行的是 delete。
更坑爹的是,大部分的数据库连接工具有执行当前选中内容的功能。有时候你只想执行当前选中的内容,结果发现执行的是全部内容。
如果关闭了自动提交,就算出现上面的情况,也还有机会挽回。比如下面这样:
-- 关闭事务自动提交set @@autocommit=0;-- 查看需要删除的数据,共65600条select * from t_user where age>18 and deptid=100;-- 删除delete from t_user where age>18;-- 发现有问题,回滚select * from t_user where age>18 and deptid=100;rollback ;-- 确认没问题,提交-- commit;
另外,在commit之前需要至少再找一个同事进行确认。所谓当局者迷,自己有时可能处于一个错误的思路上,就想当然的认为结果没问题,这时就需要一个旁观者来指点迷津。
两个人都确认没问题之后再提交,出错的机率也会小很多。
「4、修改数据之前先备份」
备份、备份、备份,重要的事情说三遍。
备份虽然会麻烦一点,但它是保证数据准确性最有效的手段。
况且,掌握一些技巧后,备份也不是很麻烦的事情。
比如,我们删除数据之前可以先这样备份。
-- 创建一个和原表一样的备份表(包含索引)create table t_user_bak like t_user;-- 拷贝数据到备份表INSERT into t_user_bak select * from t_user;-- 确认数据拷贝完成select * from t_user_bak;
这样备份的数据,就算原表数据误删了,甚至都不用恢复数据,只需要把备份表的名字改成原表的名字直接使用就可以了。
在生产库修改数据之前,一定要记得备份,一旦数据修改出错,这是成本最低并且最有效的恢复途径。
「5、设置数据库定期备份」
生产环境,运维人员一定要设置数据库定期备份。研发人员也有义务提醒运维同事编写自动备份脚本,因为生产库一旦出现问题需要恢复数据,没有定期备份的话,麻烦的不只是运维人员,研发人员也要跟着麻烦。
备份周期可以根据业务需要来决定。如果业务对数据要求的实时性比较高,备份周期相对短一点,恢复数据时可以最大程度的避免数据丢失;反之,备份周期可以长一点,节省磁盘空间。
如果有必要,可以定期把备份文件拷贝到异地服务器,避免由于一些不可抗力因素导致的当前服务器磁盘损坏,如地震、台风等。
binglog 日志
binlog 即 Binary Log,它是二进制文件,用来记录数据库写操作的日志。
数据库的 insert、delete、update、create、alter、drop 等写入操作都会被 binlog 记录。
因此,数据库的主从数据同步通常也是基于 binlog 完成的,本文只对 binlog 做一些简单介绍,后期会单独写一篇文章讲基于 binlog 的主从数据同步。
binlog 日志需要配置开启,可以通过脚本查看 binlog 是否开启。
SHOW VARIABLES LIKE 'LOG_BIN%';
如果log_bin参数显示的是OFF说明 binlog 是关闭状态,需要手动开启。
开启 binlog 需要修改数据库的my.cnf配置文件,my.cnf文件通常在服务器的/etc目录下。
打开/etc/my.cnf文件,配置 binlog 的相关参数,下文配置 binlog 的常用参数。
# 启用binlog并设置binlog日志的存储目录log_bin = /var/lib/mysql/bin-log# 设置binlog索引存储目录log_bin_index = /var/lib/mysql/mysql-bin.index# 30天之前的日志自动删除expire_logs_days = 30# 设置binlog日志模式,共有3种模式:STATMENT、ROW、MIXED binlog_format = row
binlog 的日志有三种格式,分别是 STATEMENT、ROW、MIXED。在 mysql5.7.7 版本之前默认使用的是 STATEMENT,之后的版本默认使用的是 ROW。
ROW 格式
ROW 格式下,binlog 记录的是每一条数据被修改的详细细节。
比如,执行 delete 语句,删除的数据有多少条,binlog 中就记录有多少条伪 sql。
delete from t_user where age>18;
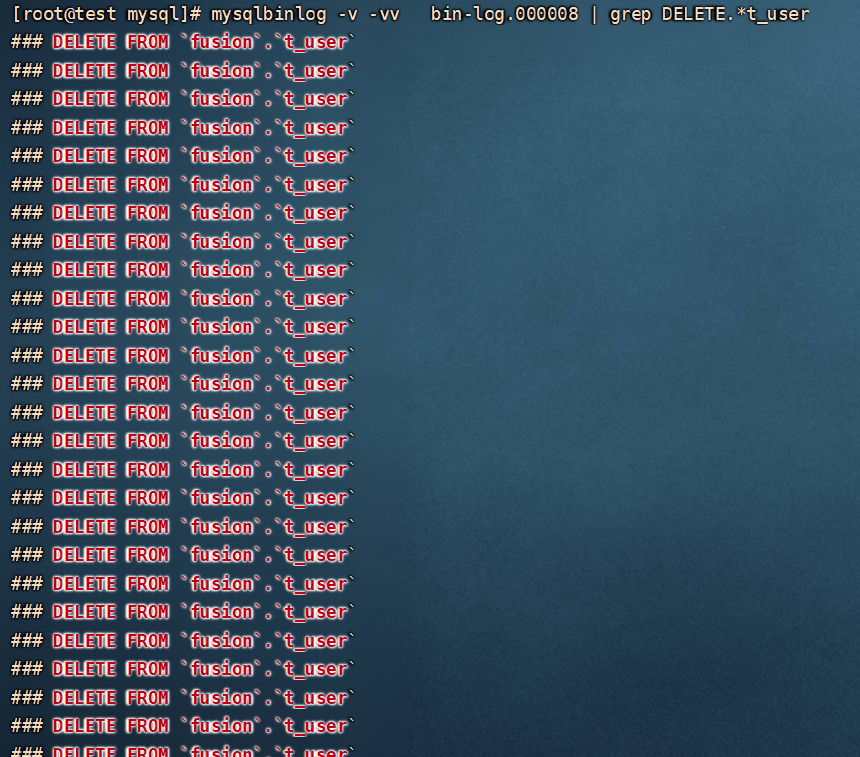
那么 row 格式的日志的缺点就很明显,在发生批量操作时,日志文件中会记录大量的伪 sql,占用较多的磁盘空间。
尤其是当进行 alter 操作时,每条数据都发生变化,日志文件中就会有每一条的数据的日志。此时,如果表中的数据量很大的话,日志文件也会非常大。
在 mysql5.6 版本之后,针对 ROW 格式的日志,新增了binlog_row_image参数。
当binlog_row_image设置为minimal时,日志中只会记录发生改变的列,而不是全部的列,这在一定程度上能减少 binlog 日志的大小。
虽然记录每行数据的变化会造成日志文件过大,但这也是它的优点所在。
因为它记录了每条数据修改细节,所以在一些极端情况下也不会出现数据错乱的问题。在做数据恢复或主从同步时能很好的保证数据的真实性和一致性
STATEMENT 格式
STATEMENT 格式下,日志中记录的是真正的 sql 语句,就像是这样。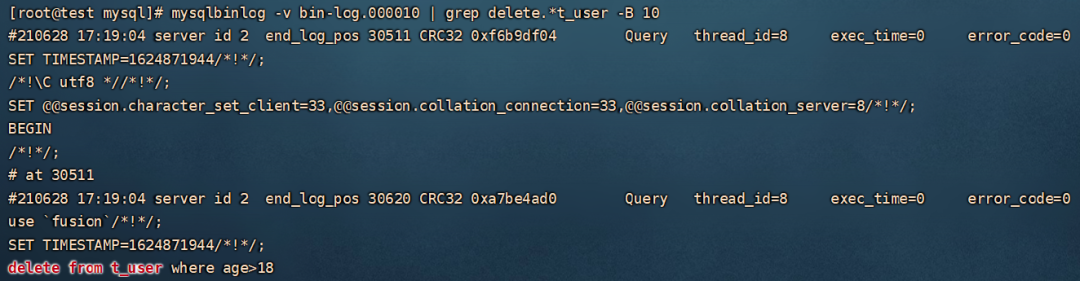
日志中的 sql 是直接可以拿到数据库运行的。
STATEMENT 格式的日志的优缺点和 ROW 格式的正好相反,它记录的是 sql 语句和执行语句时的上下文环境,而不是每一条数据。所以它的日志文件会比 ROW 格式的日志文件小一些。
由于记录的只是 sql 语句和上下文的环境,STATEMENT 格式的日志在进行主从数据同步时会有一些不可预估的情况出现,导致数据错乱。比如 sleep()、last_insert_id() 等函数会出现问题。
MIXED 格式
MIXED 格式是 STATEMENT 和 ROW 的结合,mysql 会根据具体执行的 sql 语句,来选择合适的日志格式进行记录。
MIXED 格式下,在执行普通的 sql 语句时会选 STATEMENT 来记录日志,在遇到复杂的语句或函数操作时会选择 ROW 来记录日志。
mysqlbinlog 命令
mysql 数据库的 binlog 文件是二进制的,基本看不懂,使用数据库自带的mysqlbinlog命令可以把二进制文件转换成能看懂的十进制文件。
由于数据库的 binlog 文件可能会很大,查看起来会很麻烦,所以mysqlbinlog命令也提供了一些参数可以用来筛选日志。
「mysqlbinlog 语法」
mysqlbinlog [options] log-files
options:可选参数log-files:文件名称
「options 的常用值」
-d: 根据数据库的名称筛选日志-o:跳过前N行日志-r, --result-fil: 把日志输出到指定文件--start-datetime: 读取指定时间之后的日志,时间格式:yyyy-MM-dd HH:mm:ss--stop-datetime: 读取指定时间之前的日志,时间格式:yyyy-MM-dd HH:mm:ss--start-position: 从指定位置开始读取日志--stop-position: 读取到指定位置停止--base64-output:在 row 格式下,显示伪 sql 语句-v, --verbose:显示伪 sql 语句,-vv 可以为 sql 语句添加备注
「常用写法」查看 fusion 数据库的日志
mysqlbinlog -d=fusion bin-log.000001
查看某个时间段内的日志
mysqlbinlog --start-datetime='2021-06-09 19:30:00' --stop-datetime='2021-06-09 19:50:00' bin-log.000001
恢复数据,事件的开始位置是 4300,结束位置是 10345
mysqlbinlog --start-position 4300 --stop-position 10345 bin-log.000001 | mysql -uroot -p123456 fusion
好了,接下来推一下二哥的 B 站吧,目前已经突破了 1000 粉,新一期视频也刚好新鲜出炉,小伙伴们可以来给二哥打 call,三连呀。
视频连接:https://www.bilibili.com/video/BV1XM4y137ao/
点击阅读原文也可以跳转到视频原贴,大家来玩啊,一万粉的 B 站需要老铁们支持~~~
没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。
推荐阅读: