
基于 ElasticSearch 实现站内全文搜索
目录
摘要 1 技术选型 1.1 ElasticSearch 1.2 springBoot 1.3 ik分词器 2 环境准备 3 项目架构 4 实现效果 4.1 搜索页面 4.2 搜索结果页面 5 具体代码实现 5.1 全文检索的实现对象 5.2 客户端配置 5.3 业务代码编写 5.4 对外接口 5.5 页面 6 小结
摘要
对于一家公司而言,数据量越来越多,如果快速去查找这些信息是一个很难的问题,在计算机领域有一个专门的领域IR(Information Retrival)研究如果获取信息,做信息检索。在国内的如百度这样的搜索引擎也属于这个领域,要自己实现一个搜索引擎是非常难的,不过信息查找对每一个公司都非常重要,对于开发人员也可以选则一些市场上的开源项目来构建自己的站内搜索引擎,本文将通过ElasticSearch来构建一个这样的信息检索项目。
1 技术选型
搜索引擎服务使用ElasticSearch 提供的对外web服务选则springboot web
1.1 ElasticSearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。1
现在开源的搜索引擎在市面上最常见的就是ElasticSearch和Solr,二者都是基于Lucene的实现,其中ElasticSearch相对更加重量级,在分布式环境表现也更好,二者的选则需考虑具体的业务场景和数据量级。对于数据量不大的情况下,完全需要使用像Lucene这样的搜索引擎服务,通过关系型数据库检索即可。
1.2 springBoot
Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”.2
现在springBoot在做web开发上是绝对的主流,其不仅仅是开发上的优势,在布署,运维各个方面都有着非常不错的表现,并且spring生态圈的影响力太大了,可以找到各种成熟的解决方案。
1.3 ik分词器
elasticSearch本身不支持中文的分词,需要安装中文分词插件,如果需要做中文的信息检索,中文分词是基础,此处选则了ik,下载好后放入elasticSearch的安装位置的plugin目录即可。
2 环境准备
需要安装好elastiSearch以及kibana(可选),并且需要lk分词插件。
安装elasticSearch elasticsearch官网. 笔者使用的是7.5.1。 ik插件下载 ik插件github地址. 注意下载和你下载elasticsearch版本一样的ik插件。 将ik插件放入elasticsearch安装目录下的plugins包下,新建报名ik,将下载好的插件解压到该目录下即可,启动es的时候会自动加载该插件。

搭建springboot项目 idea ->new project ->spring initializer
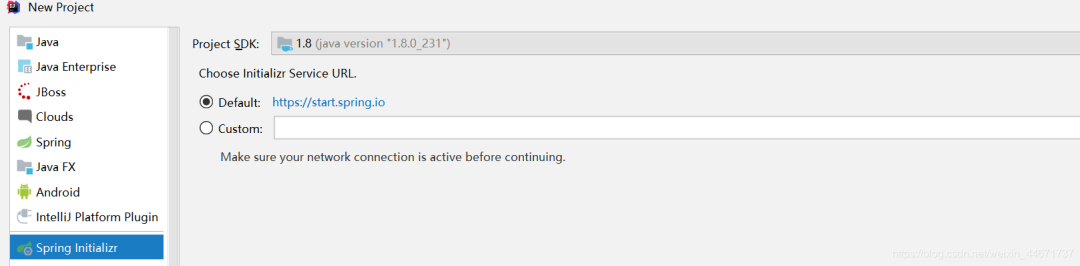
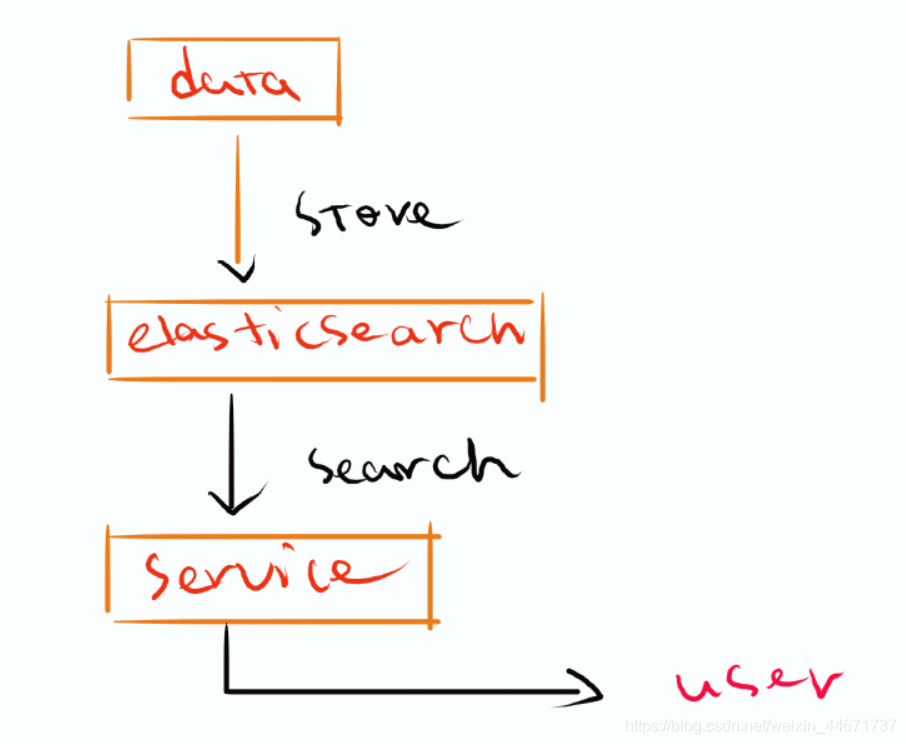
3 项目架构
获取数据使用ik分词插件 将数据存储在es引擎中 通过es检索方式对存储的数据进行检索 使用es的java客户端提供外部服务
4 实现效果
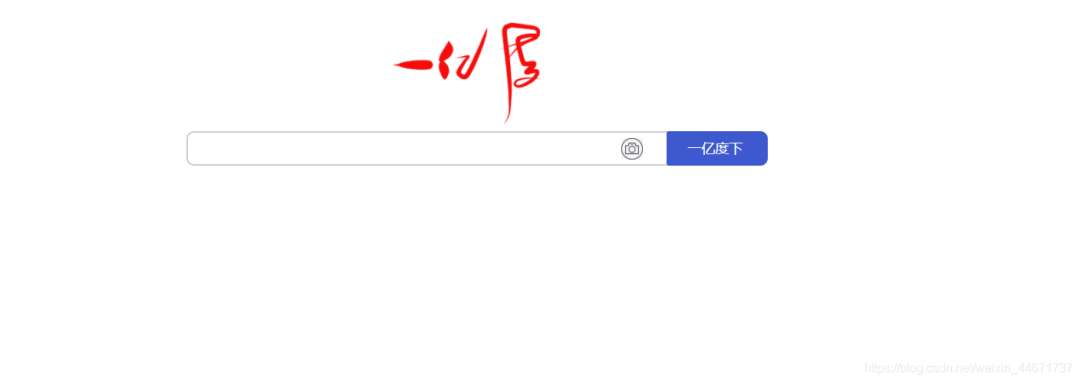
4.1 搜索页面
简单实现一个类似百度的搜索框即可。
4.2 搜索结果页面
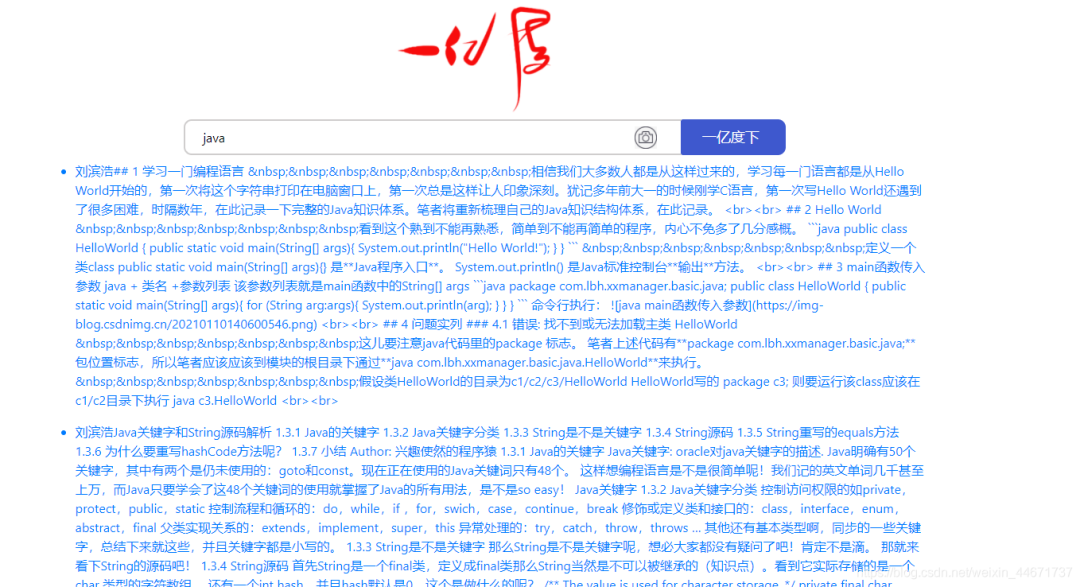
点击第一个搜索结果是我个人的某一篇博文,为了避免数据版权问题,笔者在es引擎中存放的全是个人的博客数据。

5 具体代码实现
5.1 全文检索的实现对象
按照博文的基本信息定义了如下实体类,主要需要知道每一个博文的url,通过检索出来的文章具体查看要跳转到该url。
package com.lbh.es.entity;
import com.fasterxml.jackson.annotation.JsonIgnore;
import javax.persistence.*;
/**
* PUT articles
* {
* "mappings":
* {"properties":{
* "author":{"type":"text"},
* "content":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},
* "title":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},
* "createDate":{"type":"date","format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"},
* "url":{"type":"text"}
* } },
* "settings":{
* "index":{
* "number_of_shards":1,
* "number_of_replicas":2
* }
* }
* }
* ---------------------------------------------------------------------------------------------------------------------
* Copyright(c)lbhbinhao@163.com
* @author liubinhao
* @date 2021/3/3
*/
@Entity
@Table(name = "es_article")
public class ArticleEntity {
@Id
@JsonIgnore
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
@Column(name = "author")
private String author;
@Column(name = "content",columnDefinition="TEXT")
private String content;
@Column(name = "title")
private String title;
@Column(name = "createDate")
private String createDate;
@Column(name = "url")
private String url;
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getCreateDate() {
return createDate;
}
public void setCreateDate(String createDate) {
this.createDate = createDate;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
5.2 客户端配置
通过java配置es的客户端。
package com.lbh.es.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.List;
/**
* Copyright(c)lbhbinhao@163.com
* @author liubinhao
* @date 2021/3/3
*/
@Configuration
public class EsConfig {
@Value("${elasticsearch.schema}")
private String schema;
@Value("${elasticsearch.address}")
private String address;
@Value("${elasticsearch.connectTimeout}")
private int connectTimeout;
@Value("${elasticsearch.socketTimeout}")
private int socketTimeout;
@Value("${elasticsearch.connectionRequestTimeout}")
private int tryConnTimeout;
@Value("${elasticsearch.maxConnectNum}")
private int maxConnNum;
@Value("${elasticsearch.maxConnectPerRoute}")
private int maxConnectPerRoute;
@Bean
public RestHighLevelClient restHighLevelClient() {
// 拆分地址
List hostLists = new ArrayList<>();
String[] hostList = address.split(",");
for (String addr : hostList) {
String host = addr.split(":")[0];
String port = addr.split(":")[1];
hostLists.add(new HttpHost(host, Integer.parseInt(port), schema));
}
// 转换成 HttpHost 数组
HttpHost[] httpHost = hostLists.toArray(new HttpHost[]{});
// 构建连接对象
RestClientBuilder builder = RestClient.builder(httpHost);
// 异步连接延时配置
builder.setRequestConfigCallback(requestConfigBuilder -> {
requestConfigBuilder.setConnectTimeout(connectTimeout);
requestConfigBuilder.setSocketTimeout(socketTimeout);
requestConfigBuilder.setConnectionRequestTimeout(tryConnTimeout);
return requestConfigBuilder;
});
// 异步连接数配置
builder.setHttpClientConfigCallback(httpClientBuilder -> {
httpClientBuilder.setMaxConnTotal(maxConnNum);
httpClientBuilder.setMaxConnPerRoute(maxConnectPerRoute);
return httpClientBuilder;
});
return new RestHighLevelClient(builder);
}
}
5.3 业务代码编写
包括一些检索文章的信息,可以从文章标题,文章内容以及作者信息这些维度来查看相关信息。
package com.lbh.es.service;
import com.google.gson.Gson;
import com.lbh.es.entity.ArticleEntity;
import com.lbh.es.repository.ArticleRepository;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.io.IOException;
import java.util.*;
/**
* Copyright(c)lbhbinhao@163.com
* @author liubinhao
* @date 2021/3/3
*/
@Service
public class ArticleService {
private static final String ARTICLE_INDEX = "article";
@Resource
private RestHighLevelClient client;
@Resource
private ArticleRepository articleRepository;
public boolean createIndexOfArticle(){
Settings settings = Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 1)
.build();
// {"properties":{"author":{"type":"text"},
// "content":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"}
// ,"title":{"type":"text","analyzer":"ik_max_word","search_analyzer":"ik_smart"},
// ,"createDate":{"type":"date","format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"}
// }
String mapping = "{\"properties\":{\"author\":{\"type\":\"text\"},\n" +
"\"content\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\",\"search_analyzer\":\"ik_smart\"}\n" +
",\"title\":{\"type\":\"text\",\"analyzer\":\"ik_max_word\",\"search_analyzer\":\"ik_smart\"}\n" +
",\"createDate\":{\"type\":\"date\",\"format\":\"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd\"}\n" +
"},\"url\":{\"type\":\"text\"}\n" +
"}";
CreateIndexRequest indexRequest = new CreateIndexRequest(ARTICLE_INDEX)
.settings(settings).mapping(mapping,XContentType.JSON);
CreateIndexResponse response = null;
try {
response = client.indices().create(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
if (response!=null) {
System.err.println(response.isAcknowledged() ? "success" : "default");
return response.isAcknowledged();
} else {
return false;
}
}
public boolean deleteArticle(){
DeleteIndexRequest request = new DeleteIndexRequest(ARTICLE_INDEX);
try {
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
public IndexResponse addArticle(ArticleEntity article){
Gson gson = new Gson();
String s = gson.toJson(article);
//创建索引创建对象
IndexRequest indexRequest = new IndexRequest(ARTICLE_INDEX);
//文档内容
indexRequest.source(s,XContentType.JSON);
//通过client进行http的请求
IndexResponse re = null;
try {
re = client.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return re;
}
public void transferFromMysql(){
articleRepository.findAll().forEach(this::addArticle);
}
public List queryByKey(String keyword) {
SearchRequest request = new SearchRequest();
/*
* 创建 搜索内容参数设置对象:SearchSourceBuilder
* 相对于matchQuery,multiMatchQuery针对的是多个fi eld,也就是说,当multiMatchQuery中,fieldNames参数只有一个时,其作用与matchQuery相当;
* 而当fieldNames有多个参数时,如field1和field2,那查询的结果中,要么field1中包含text,要么field2中包含text。
*/
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders
.multiMatchQuery(keyword, "author","content","title"));
request.source(searchSourceBuilder);
List result = new ArrayList<>();
try {
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit:search.getHits()){
Map map = hit.getSourceAsMap();
ArticleEntity item = new ArticleEntity();
item.setAuthor((String) map.get("author"));
item.setContent((String) map.get("content"));
item.setTitle((String) map.get("title"));
item.setUrl((String) map.get("url"));
result.add(item);
}
return result;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public ArticleEntity queryById(String indexId){
GetRequest request = new GetRequest(ARTICLE_INDEX, indexId);
GetResponse response = null;
try {
response = client.get(request, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
if (response!=null&&response.isExists()){
Gson gson = new Gson();
return gson.fromJson(response.getSourceAsString(),ArticleEntity.class);
}
return null;
}
}
5.4 对外接口
和使用springboot开发web程序相同。
package com.lbh.es.controller;
import com.lbh.es.entity.ArticleEntity;
import com.lbh.es.service.ArticleService;
import org.elasticsearch.action.index.IndexResponse;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.List;
/**
* Copyright(c)lbhbinhao@163.com
* @author liubinhao
* @date 2021/3/3
*/
@RestController
@RequestMapping("article")
public class ArticleController {
@Resource
private ArticleService articleService;
@GetMapping("/create")
public boolean create(){
return articleService.createIndexOfArticle();
}
@GetMapping("/delete")
public boolean delete() {
return articleService.deleteArticle();
}
@PostMapping("/add")
public IndexResponse add(@RequestBody ArticleEntity article){
return articleService.addArticle(article);
}
@GetMapping("/fransfer")
public String transfer(){
articleService.transferFromMysql();
return "successful";
}
@GetMapping("/query")
public List query(String keyword) {
return articleService.queryByKey(keyword);
}
}
5.5 页面
此处页面使用thymeleaf,主要原因是笔者真滴不会前端,只懂一丢丢简单的h5,就随便做了一个可以展示的页面。
搜索页面
html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>YiyiDutitle>
<style>
input:focus {
border: 2px solid rgb(62, 88, 206);
}
input {
text-indent: 11px;
padding-left: 11px;
font-size: 16px;
}
style>
<style class="input/css">
.input {
width: 33%;
height: 45px;
vertical-align: top;
box-sizing: border-box;
border: 2px solid rgb(207, 205, 205);
border-right: 2px solid rgb(62, 88, 206);
border-bottom-left-radius: 10px;
border-top-left-radius: 10px;
outline: none;
margin: 0;
display: inline-block;
background: url(/static/img/camera.jpg) no-repeat 0 0;
background-position: 565px 7px;
background-size: 28px;
padding-right: 49px;
padding-top: 10px;
padding-bottom: 10px;
line-height: 16px;
}
style>
<style class="button/css">
.button {
height: 45px;
width: 130px;
vertical-align: middle;
text-indent: -8px;
padding-left: -8px;
background-color: rgb(62, 88, 206);
color: white;
font-size: 18px;
outline: none;
border: none;
border-bottom-right-radius: 10px;
border-top-right-radius: 10px;
margin: 0;
padding: 0;
}
style>
head>
<body>
<div style="font-size: 0px;">
<div align="center" style="margin-top: 0px;">
<img src="../static/img/yyd.png" th:src = "@{/static/img/yyd.png}" alt="一亿度" width="280px" class="pic" />
div>
<div align="center">
<form action="/home/query">
<input type="text" class="input" name="keyword" />
<input type="submit" class="button" value="一亿度下" />
form>
div>
div>
body>
html>
搜索结果页面
html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<link rel="stylesheet" href="https://cdn.staticfile.org/twitter-bootstrap/4.3.1/css/bootstrap.min.css">
<meta charset="UTF-8">
<title>xx-managertitle>
head>
<body>
<header th:replace="search.html">header>
<div class="container my-2">
<ul th:each="article : ${articles}">
<a th:href="${article.url}"><li th:text="${article.author}+${article.content}">li>a>
ul>
div>
<footer th:replace="footer.html">footer>
body>
html>
6 小结
上班撸代码,下班继续撸代码写博客,花了两天研究了以下es,其实这个玩意儿还是挺有意思的,现在IR领域最基础的还是基于统计学的,所以对于es这类搜索引擎而言在大数据的情况下具有良好的表现。每一次写实战笔者其实都感觉有些无从下手,因为不知道做啥?所以也希望得到一些有意思的点子笔者会将实战做出来。