
数据项目总结 -- 蛋壳公寓租金分析!
Datawhale干货
作者:牧小熊,华中农业大学,Datawhale原创作者
最近爬取了武汉蛋壳公寓的租房信息,并对租房信息进行了清洗及可视化操作。
并构建相应模型来分析武汉蛋壳公寓房租价格与房屋特征的相关性挖掘。
后台回复【实践项目】可进项目实践交流群。
1.数据爬取
我们爬取了蛋壳公寓的租房网站,将区域位置选择为武汉,通过爬虫访问网页获得房屋的相关信息,并输出到csv文件中。

方法:requests、lxml、BeautifulSoup
import requests
from lxml import etree
from bs4 import BeautifulSoup
import random
import time
from tqdm import tqdm
import csv
我们定义了几个爬虫伪装头,每次访问时随机选择不同的访问头对网页进行访问。
通过使用不同的访问头,能一定程度上保护爬虫。
#这里增加了很多user_agent
#能一定程度能保护爬虫
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)"]
访问蛋壳公寓的网站,并获得每个房屋的链接。这里我们使用了BeautifulSoup对网页进行解析,并通过便签及class对房屋信息进行定位,同时获得每个房租的超链接。
通过自定义函数get_house_info来访问房屋链接,并返回房屋相关信息的列表,将获得的列表导出到csv文件中,需要注意的是,为了避免对对方服务器造成过大的压力,我们每次访问中间需要休息几秒。
def get_info():
#武汉地区总共有267页
csvheader=['价格','面积','编号','户型','楼层','朝向','位置1','位置2','小区','地铁']
with open('wuhan_danke.csv', 'a+', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(csvheader)
for i in tqdm(range(1,268)): #总共有267页
timelist=[2,3,4,5]
time.sleep(random.choice(timelist)) #休息2-5秒,防止给对方服务器过大的压力!!!
url='https://www.danke.com/room/wh?search=1&search_text=&from=home&page={}'.format(i)
headers = {'User-Agent': random.choice(user_agent)}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'lxml')
all_info = soup.find_all('div', class_='r_lbx_cena')
for info in all_info:
href = info.find('a')
if href !=None:
href=href['href']
house_info=get_house_info(href)
writer.writerow(house_info)
def get_house_info(href):
#得到房屋的信息
time.sleep(3)
headers = {'User-Agent': random.choice(user_agent)}
response = requests.get(url=href, headers=headers)
response=response.content.decode('utf-8', 'ignore')
div = etree.HTML(response)
room_price=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[3]/div[2]/div/span/div/text()")[0]
room_area=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[1]/div[1]/label/text()")[0].replace('建筑面积:约','').replace('㎡(以现场勘察为准)','')
room_id=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[1]/div[2]/label/text()")[0].replace('编号:','')
room_type=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[1]/div[3]/label/text()")[0].replace('\n','').replace(' ','').replace('户型:','')
room_floor=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[2]/div[3]/label/text()")[0].replace('楼层:','')
room_dir=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[2]/div[1]/label/text()")[0].replace("朝向","")
room_postion_1=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[2]/div[4]/label/div/a[1]/text()")[0]
room_postion_2=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[2]/div[4]/label/div/a[2]/text()")[0]
room_postion_3=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[2]/div[4]/label/div/a[3]/text()")[0]
room_subway=div.xpath("/html/body/div[3]/div[1]/div[2]/div[2]/div[4]/div[2]/div[5]/label/text()")[0]
room_info=[room_price,room_area,room_id,room_type,room_floor,room_dir,room_postion_1,room_postion_2,room_postion_3,room_subway]
return room_info
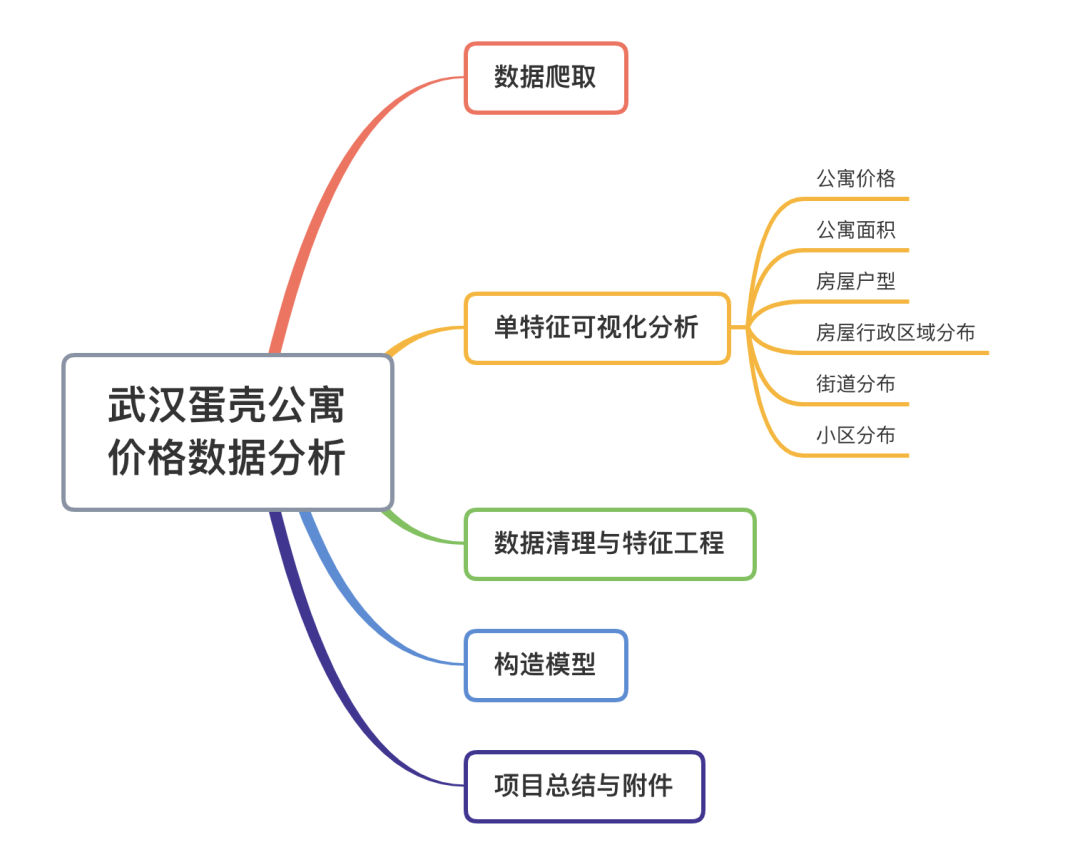
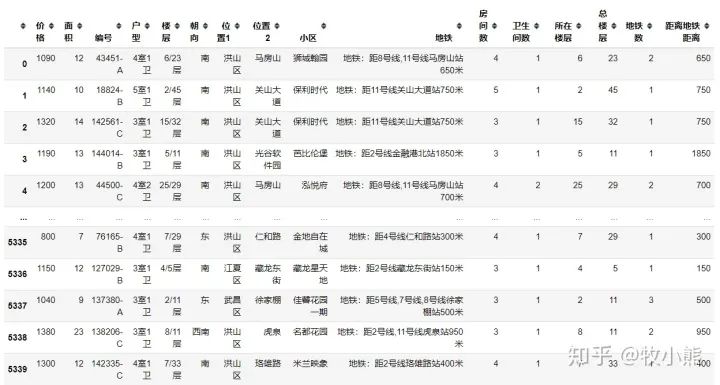
看看爬取之后的结果:

2.单特征可视化分析
使用pandas将武汉蛋壳公寓的数据导入,同时对公寓的单特征数据进行可视化展示。
方法:pandas、plotly
导入第三方库:
import pandas as pd
import plotly_express as px
import plotly.offline as of
import plotly as py
import plotly.graph_objs as go
import re
导入数据:
data=pd.read_csv('wuhan_danke.csv')
data
各个字段含义
价格---租金 单位元/月 面积---房屋实际面积 单位:㎡ 编号---房屋的编号 户型---房屋的总体户型情况 楼层---房屋所在小区总共有多少层 其中出租屋在多少层 朝向---房屋的方向 位置1---房屋所在的区 位置2---房屋所在街道 小区---房屋所在小区名称
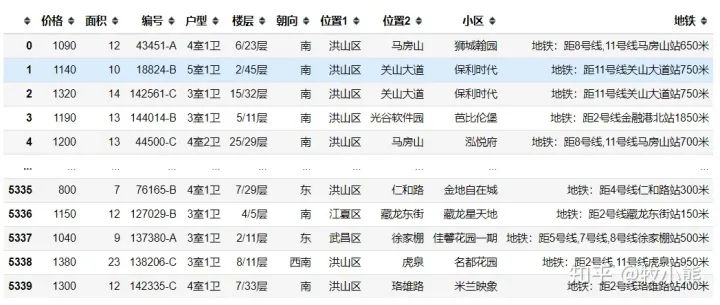
2.1公寓价格
price = go.Histogram(x = data['价格'],histnorm = 'probability')
fig = go.Figure(data=price)
fig
通过直方图可以看到,公寓的价格分布呈现一个非标准正态分布,公寓的价格主要是集中在1100-1200之间。
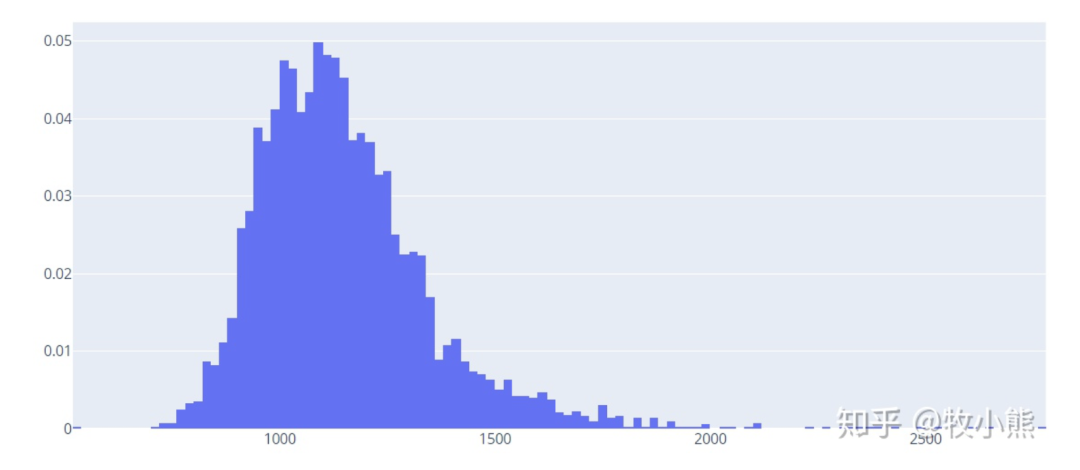
2.2公寓面积
我们选取了公寓面积数目最多的前15个:
area = pd.DataFrame(data["面积"].value_counts()[:15]).reset_index()
area["index"] =[ '%sm²' % i for i in area["index"]]
fig = go.Bar(x = area['index'],y=area['面积'],text=area['面积'],textposition='outside')
fig = go.Figure(data=fig)
fig
通过柱状图可以看到蛋壳公寓面积更加偏向于9-12m²,分析原因主要是小区的房子卧室一般的面积会在9-12m² 直接将房屋的卧室进行分割,能最大程度减小成本。
2.3房屋户型
roomtype = pd.DataFrame(data["户型"].value_counts()).reset_index()
fig = px.pie(roomtype,names="index",values="户型")
fig
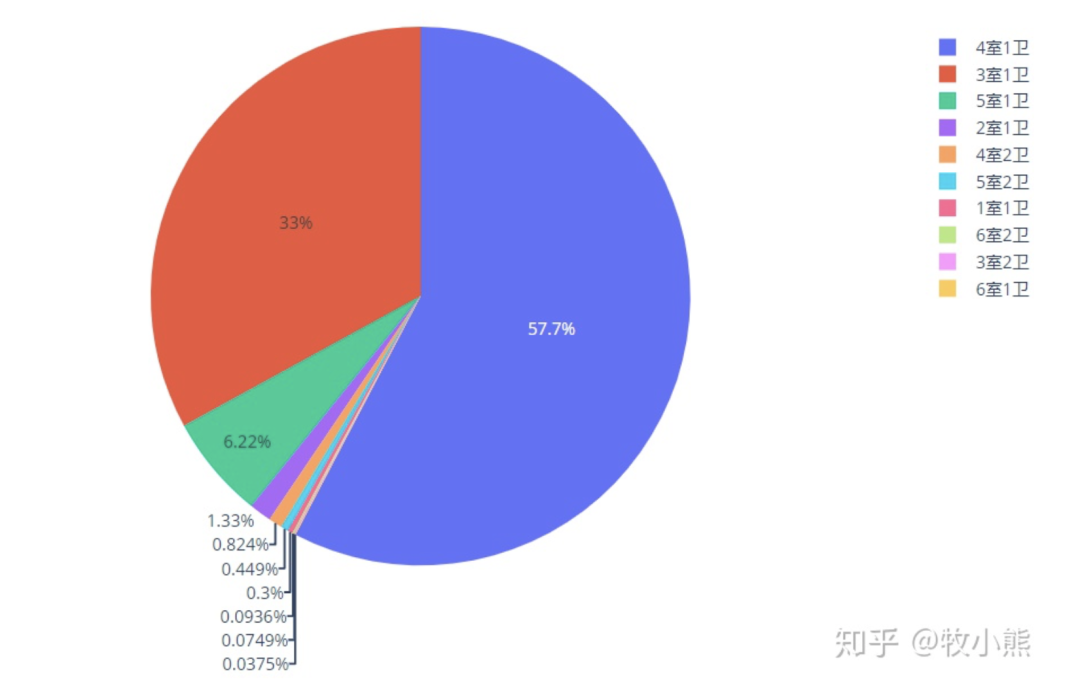
通过分析发现蛋壳公寓收取的房屋中大部分是4室1卫和3室1卫,而这2种户型也是房地产开放商喜欢开放的主流户型。
2.4房屋行政区域分布
position = pd.DataFrame(data["位置1"].value_counts()).reset_index()
fig = px.pie(position,names="index",values="位置1")
fig.show()
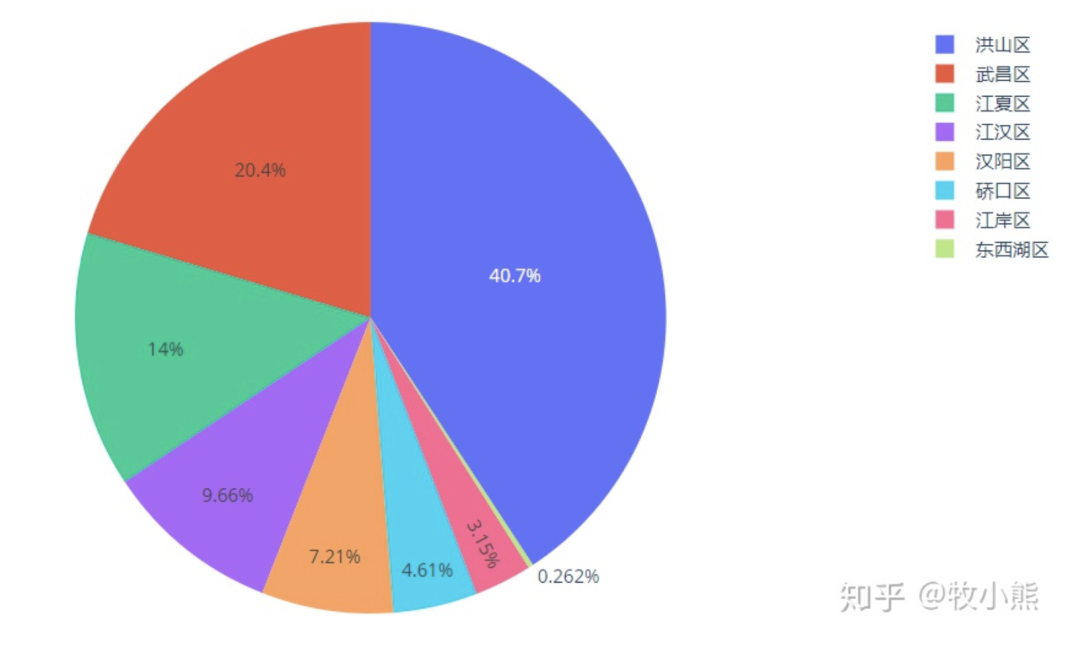
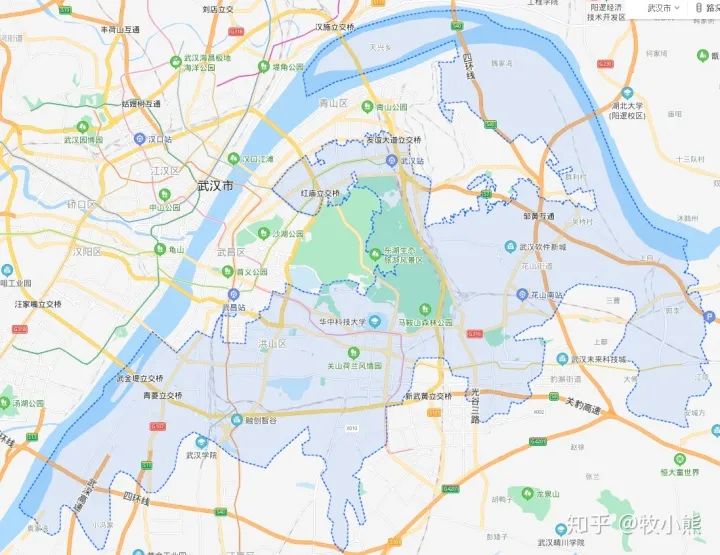
通过饼状图可以看到,蛋壳公寓名下的房屋主要集中在洪山区、武昌区以及江夏区,从百度地图上进行查询洪山区区域图,可以看到洪山区覆盖了较多的大学,同时洪山区覆盖面积较大,因此具有较大的占比。
2.5街道分布
我们选取了数目最多的15个街道:
area = pd.DataFrame(data["位置2"].value_counts()[:15]).reset_index()
fig = go.Bar(x = area['index'],y=area['位置2'],text=area['位置2'],textposition='outside')
fig = go.Figure(data=fig)
fig

通过可视化图可以看到,房屋在光谷软件园、佛祖岭、光谷广场数量具有较大的占比,光谷软件园附件有较多的互联网公司。
2.6小区分布
我们选取了蛋壳公寓小区数目种最多的前10个:
area = pd.DataFrame(data["小区"].value_counts()[:10]).reset_index()
fig = go.Bar(x = area['index'],y=area['小区'],text=area['小区'],textposition='outside')
fig = go.Figure(data=fig)
fig
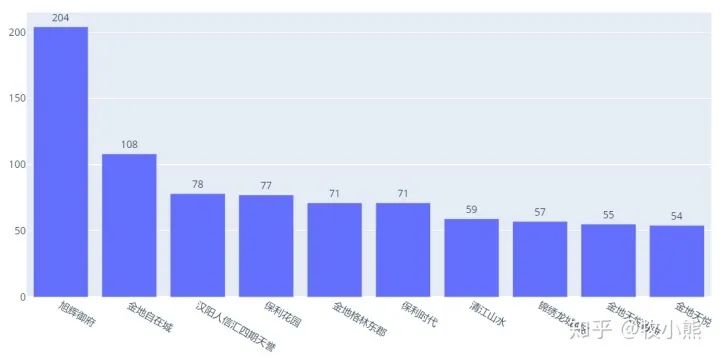
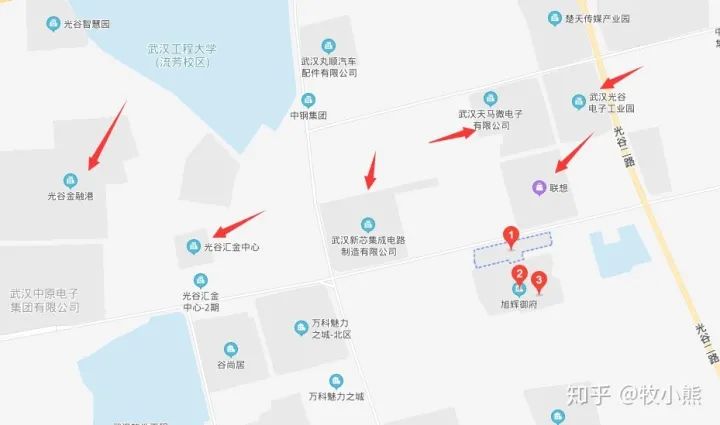
数目最多的居然是旭辉御府,查看了一下旭辉御府周围的商业点,附件有光谷金融港、武汉联想、光谷电子工业园这些地方对劳动力具有一定的吸引力,因此旭辉御府小区也是受到较大的欢迎。
同时旭辉御府小区开盘时间较晚 居民的居住率不高,因此大家更愿意把房屋进行出租。
3.数据清理与特征工程
对爬取的数据进行清洗,同时进行特征构造,对房屋定价进行挖掘:
##房屋的编号与房屋的价格几乎没有关系
def get_subway_num(row):
subway_num=row.count('号线')
return subway_num
def get_subway_distance(row):
distance=re.search(r'\d+(?=米)',row)
if distance==None:
return -1
else:
return distance.group()
data['房间数']=data['户型'].apply(lambda x:x[0])
data['卫生间数']=data['户型'].apply(lambda x:x[2])
data['所在楼层']=data['楼层'].apply(lambda x:x.split('/')[0])
data['总楼层']=data['楼层'].apply(lambda x:x.split('/')[1].replace('层',''))
data['地铁数']=data['地铁'].apply(get_subway_num)
data['距离地铁距离']=data['地铁'].apply(get_subway_distance)
data
同时对不需要的特征进行删除 以及LabelEncoder编码:
data=data.drop(['编号'],axis=1)
data=data.drop(['户型'],axis=1)
data=data.drop(['楼层'],axis=1)
data=data.drop(['地铁'],axis=1)
from sklearn.preprocessing import LabelEncoder
data=data.fillna(-1)
le = LabelEncoder()
direction={'东':0,'南':270,'西':180,'北':90,'西南':225,'东南':315,'东北':45,'西北':135}
data['朝向']=data['朝向'].map(direction)
data['位置1']=le.fit_transform(data['位置1'])
data['位置2']=le.fit_transform(data['位置2'])
data['小区']=le.fit_transform(data['小区'])
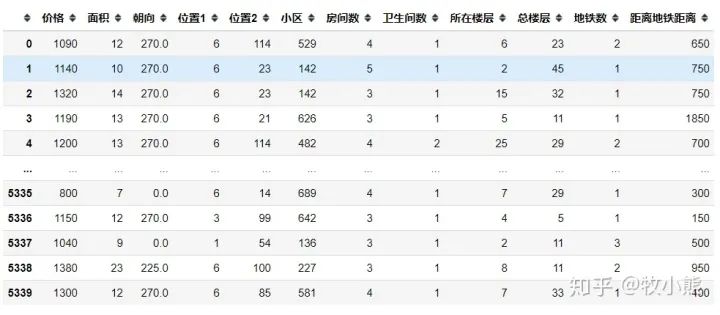
将公寓的房屋特征全部转换成了数字特征。
4.构造模型
对数据采用lightgbm回归模型,同时使用5折的方式进行模型交叉训练,找出各个特征对房屋价格的重要性:
data=data.fillna(-1)
data=data.astype('int')
import lightgbm
from sklearn.model_selection import KFold
train_label=data['价格']
train_data=data.drop(['价格'],axis=1)
def select_by_lgb(train_data,train_label,random_state=2020,n_splits=5,metric='mse',num_round=10000,early_stopping_rounds=100):
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
feature_importances = pd.DataFrame()
feature_importances['feature'] = train_data.columns
fold=0
for train_idx, val_idx in kfold.split(train_data):
random_state+=1
train_x = train_data.loc[train_idx]
train_y = train_label.loc[train_idx]
test_x = train_data.loc[val_idx]
test_y = train_label.loc[val_idx]
clf=lightgbm
train_matrix=clf.Dataset(train_x,label=train_y)
test_matrix=clf.Dataset(test_x,label=test_y)
params={
'boosting_type': 'gbdt',
'objective': 'regression',
'learning_rate': 0.1,
'metric': metric,
'seed': 2020,
'nthread':-1 }
model=clf.train(params,train_matrix,num_round,valid_sets=test_matrix,early_stopping_rounds=early_stopping_rounds)
feature_importances['fold_{}'.format(fold + 1)] = model.feature_importance()
fold+=1
feature_importances['averge']=feature_importances[['fold_{}'.format(i) for i in range(1,n_splits+1)]].mean(axis=1)
return feature_importances
feature_importances=select_by_lgb(train_data,train_label)
feature_importances['averge']=feature_importances[['fold_{}'.format(i) for i in range(1,6)]].mean(axis=1)
对5次运算的特征进行求平均值 并按照特征重要性进行降序排列:
feature_importances=feature_importances.sort_values(by='averge',ascending=False)
feature_importances
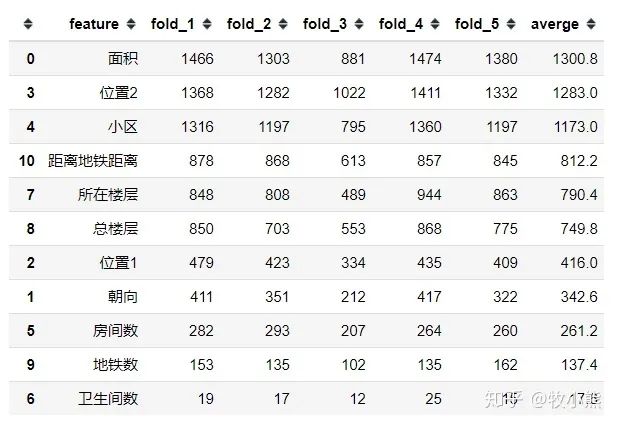
对特征进行可视化的展示:
fig = go.Bar(x = feature_importances['feature'],y=feature_importances['averge'],text=feature_importances['averge'],textposition='outside')
fig = go.Figure(data=fig)
fig
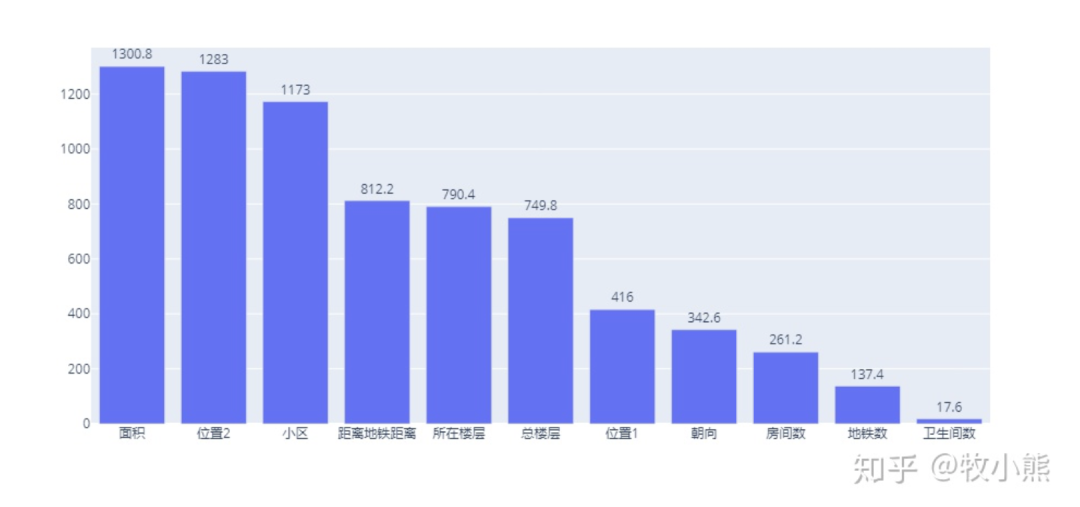
通过特征分析我们发现,对蛋壳公寓房屋价格特征进行挖掘,我们发现房屋的面积以及房屋所在的街道对房屋的价格有较大的影响。
因为小区与距离地铁的距离与所在的街道有较强的关联,因此蛋壳公寓在进行房屋定价时,对公寓的面积以及公寓所在的街道有较大的权重考虑,然后再考虑房屋所在的楼层。
5.项目总结
本项目对O2O互联网长租公寓蛋壳公寓武汉区进行的租房信息进行了爬取,获得了蛋壳公寓对外出租房屋的相关信息。因为爬取的信息为待租公寓的信息,我们可以认为待租公寓类似样本抽样,能一定程度反映总体数据的分布情况。
我们对蛋壳公寓的公寓价格、公寓面积、公寓所在房屋户型、公寓所在的行政区、公寓所在的街道及小区进行了可视化的展示与分析。通过分析发现,蛋壳公寓在收取小区房屋时,会重点考虑小区附件是否有吸收劳动力的商业街或公司,从而提升公寓的入住率。从房屋的户型及公寓的面积我们发现,武汉主流公寓的面积在9-12m²,蛋壳公寓一般会将房屋分割成3-5个卧室进行对外出租,同时公寓的租金主要集中在1100-1200元之间。
最后我们对蛋壳公寓的定价进行了建模与结构性挖掘,我们发现蛋壳公寓的租金定价主要考虑3个方面,公寓的面积、公寓所在的街道以及公寓所在楼层。
6.项目附件
蛋壳公寓房屋数据:链接:https://pan.baidu.com/s/1CmYdX8dj-JgwAnaU3_Wnnw提取码:x6fd
蛋壳公寓爬虫代码:链接:https://pan.baidu.com/s/1D_d0T4SVRrgOXwYI7S0-Cw提取码:vjr0
蛋壳公寓数据分析代码:链接:https://pan.baidu.com/s/1-8cJJqfUiHC0B9Bvysftew提取码:q47x