
一个搜索需求搞垮微服务
“编程十几年,我只希望能把技术讲明白而已,当然能帮到各位更是深感荣幸
“假如你是一名架构师或者技术领导人,一定要深深的知道,
没有完美的技术方案,要不然编程技术早就万佛归一。
微服务作为近几年新兴的技术概念,其实也并不是一蹴而就,它也是随着技术不断发展衍生出来的,就像前几年的SOA概念一样,虽然解决了很多技术性或者架构性的问题,但是随之而来的也伴随着一些技术或者架构难题,无论是SOA还是微服务,在部署的维度来看都是分布式的,分布式在解决系统的性能和可用性上很有优势,这毋庸置疑。
说到分布式系统,分布式有它自己独有的缺陷,比如最常见,也是技术面试官最常问的装逼话题:分布式事务,这是一个很沉重的话题,并非今天的重点。今天的主角是另外一个分布式问题:业务的搜索问题。
搜索需求无处不在
无论是过去式的单体应用,还是现代的微服务以及未来的XX架构,为了支持良好的用户体验,每个系统都会有对应的搜索功能,类似:淘宝的商品搜索,订单搜索等等。
先不论搜索的性能问题,就单单实现功能的问题,在单体和分布式架构下就有很大不同。在单体时代,因为共用一个大的数据库,开发人员只需要根据条件写出对应的SQL语句即可,即便是连接了N张表,但是完成功能性需求还是问题不大,碰到性能问题,可能加几条对应的索引即可,当然这只是针对于中小型系统而言。
在微服务的架构下,数据库和应用系统都根据业务进行了物理拆分,要想用一条SQL来实现之前是搜索,需要跨越多个数据库来执行,而且这样也打破了微服务之间的隔离性和封装性。
“微服务很讲究封装性和自治性
使用微服务API组合搜索
如果只是搜索某个业务特有的数据,只需要从某个业务的服务接口获取即可,实现这样的需求很简单。但是,现实情况是很多搜索需要从多个业务中联合获取数据,举一个很简单的例子:用户信息服务保存着用户的基本信息,订单服务中保存着订单的信息,如果要根据用户的姓名查找用户的订单信息(还需要把用户信息展示出来)就可能需要跨越这两个服务进行搜索(不要在乎细节)
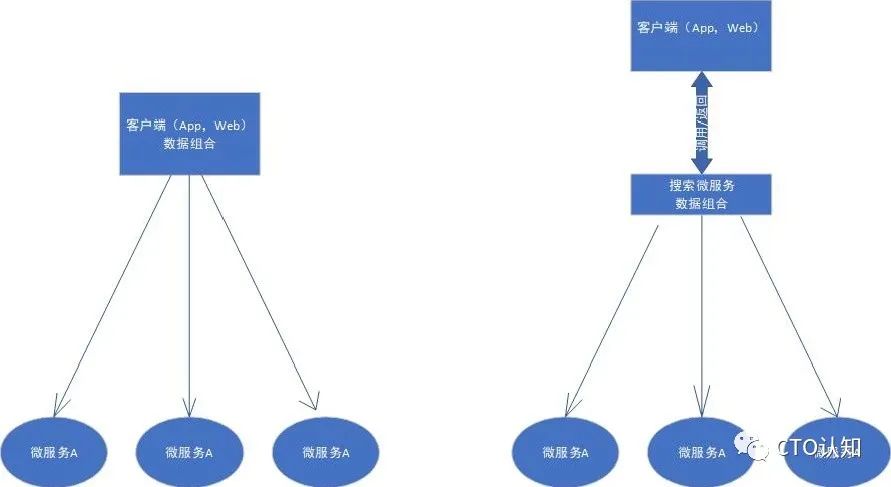
在这种情况下呢,最直接也是最常用的方案就是进行多个微服务API数据的组合,整个流程涉及到两种角色:
API数据的组合器 API数据的提供方
API数据的组合器通过从数据的提供方检索的数据并组合结果来实现搜索功能。这里的API数据组合器根据不同的业务架构可以分为几种:
呈现数据的客户端,例如:App端或者Web应用程序,甚至是小程序 专门用于组合数据的服务端应用程序,这里不同的架构师有不同的看法,有人喜欢使用微服务,有人喜欢用网关,有人喜欢用无状态的API站点,用什么无所谓,实现的功能大家都是一致的
问题多多
能否使用API组合模式来实现搜索的功能,还要取决于特定的业务以及数据的形式和API的功能,甚至是使用的数据库类型(比如:redis就不太适合内容型的关键词搜索)
即便搜索业务可以使用API组合方式来实现,数据聚合器也可能需要执行大量数据的聚合,去重,连接等低效操作。不仅如此:

延迟问题
由于API组合器需要调用多个API才可以组合出所需要的数据,所以API组合器应该尽可能的并行调用服务API,这样可以最大限度的缩短搜索请求的响应时间,但是请注意,有的时候,这些服务接口之间有依赖关系,必须要等到第一个API接口数据返回,才可以调用另外一个服务。
开销增加
在单体时代,一个搜索请求对应一条SQL语句,相比之下,API组合搜索需要不同的业务服务器执行对应的SQL语句(当然这里可以走缓存,但是,这不是今天的重点),这无疑增加了DB资源的浪费,而且每个API多数情况下还需要返回搜索结果中不需要的字段(其他服务可能依赖于这些字段),当然带宽资源现在来说成本很低了
无法保证ACID
由于API组合搜索行为执行多个独立数据库的搜索查询操作,所以无法做到事务性保证,不过回头一想,查询操作其实对于事务性要求并不是很高啊
可用性降低
说到系统的可用性,其实是个很大的话题,不过有一个大家都共识的规则:操作经过的节点越多,流程越长,发生故障的概率就越大。就像单体服务,查询操作只需要一步即可,假设每个节点的可用性为两个9,即:99%。如果存在三个节点操作的情况下,可用性为:0.990.990.99=0.970299 ,即可用性降到了97%。
在某个系统不可用的时候,其实我们可以制定很多策略来响应客户端,其中返回异常是最不友好的。
可以把异常API那部分数据删除掉,只返回可用API的数据给客户端,这样客户端仍然可以显示那些正常的数据 在组合器中,设置设置服务不可用的默认返回数据或者缓存之前可用的数据,即使数据不是最新的,最少也比没有数据要好一些。
完美解决方案CQRS?
在系统逐渐复杂之后,无论多么微服务化的业务,面对复杂的搜索需求,都会显得无能为力。导致简单的搜索需求在分布式环境下复杂化的根本原因是数据的分布式化,数据的存储多元化。
既然明白了搜索难度的根本原因,我们只要解决了根本问题,搜索自然而然就解决了。所以,从原始数据分离搜索数据,从原始数据聚合搜索数据就被发明了出来,也就是现在的CQRS。
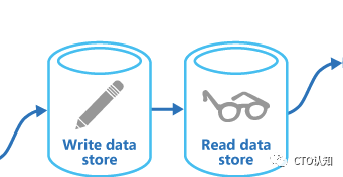
“命令查询职责分离模式(Command Query Responsibility Segregation,CQRS),该模式从业务上分离修改(Command,增,删,改,会对系统状态进行修改)和查询(Query,查,不会对系统状态进行修改)的行为。
是不是很熟悉,和MySql的读写分离思想是不是很像?把复杂业务需要的资源剥离出来,永远是复杂业务的良药呀
数据同步
网络上你能搜索到的关于CQRS的文章,几乎都和DDD(领域驱动)相关,我自认为这有点误人子弟,CQRS本质上是一种架构思想,和具体技术关系不大(虽然DDD也属于思想范畴)。一个现有的系统要想改造出CQRS可能会很容易,但是要想改造成DDD,一般会很难。所以,读到这里,可以遗忘DDD了
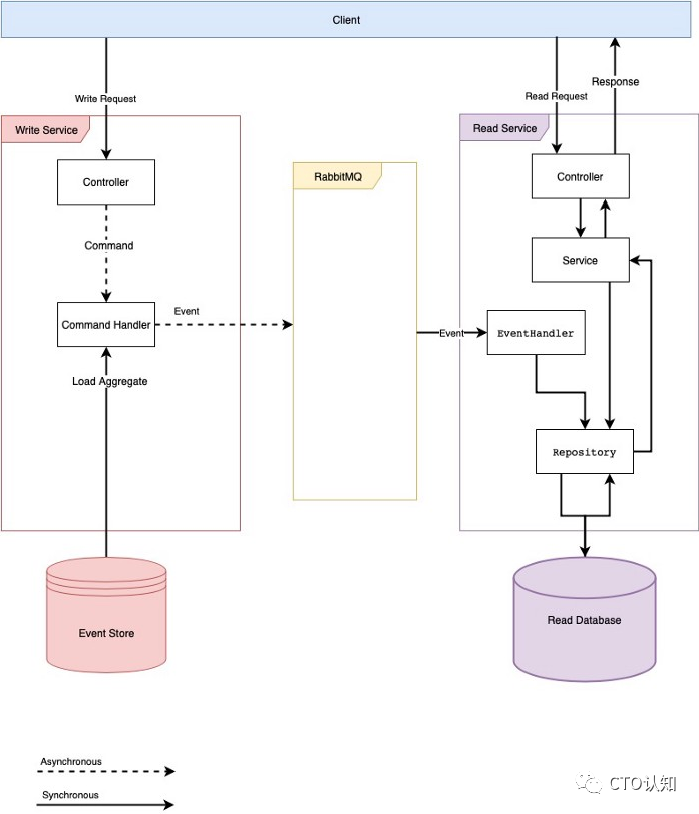
CQRS模式设计到两部分数据源:查询的数据和增删改的数据。这两部分数据源的存储技术很大可能性不会相同,例如:查询的数据一般会使用适合搜索的ES来存储,而增删改的数据一般会使用Mysql或者SqlServer来存储。
两个数据源之间的数据同步可以使用定时任务程序来实现,但是这也是针对于那些对于数据修改不敏感的业务数据,比如:商品的搜索功能,一般的电商系统不会要求新加的商品马上会被搜索到。
如果你的系统是基于DDD来开发的,自然而然会引入领域事件的概念,数据的同步肯定也是基于领域事件来实现的,这一般都会引入第三方的MQ中间件。同步的过程中还涉及到网络的问题,数据重复问题,组件的高可用问题..... 想想就让人头疼
CQRS失败了
CQRS虽然说起来很华丽,好像能解决微服务下的很多搜索问题,是这样吗?
由于CQRS的数据同步通常都是异步的,异步可以明显提高系统的吞吐量这毋庸置疑,但是也意味着调用方得不到操作是否成功的结果。举个例子:用户在客户端发送了修改商品名称的操作,源数据的系统会返回客户端成功的标识,而此标识也仅仅代表了源数据的修改成功或者投递事件或者投递MQ消息成功,至于搜索系统是否正确的更新了数据无从得知。 由于数据的分离,开发者们需要维护两套微服务系统,而且在两个系统之间的数据同步方面要投入很大的精力。 如果所有的微服务都引入CQRS,微服务的数量将是正常数量的两倍。这个问题在于我们错误的理解了CQRS的用途。所有的技术手段都来自于业务需求,如果不能在技术中获得业务利益,那就是徒劳的。
CQRS本质上还是“分”思想的一种落地实现,它把读写的数据源分开来满足不同的业务,就像平时的报表服务,完全可以是读数据源的一类节点,而查询服务又是另外一类数据节点。
“CQRS和DDD并非是一体的,而CQRS的数据同步也并非只有领域事件一种方式
写在最后
即便微服务下使用API组合方式来实现搜索有很多缺陷,但是在某些简单场景下依然是最简单最常用的解决方案。CQRS虽然能解决很多发杂的搜索问题,但是也不是万能的解决方案。
“所以说嘛,人无完人,编程技术亦是如此。


微服务并不能解决你的烂代码问题