
机器视觉算法的局限性
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达 
作者:Dr. Luo,东南大学工学博士,英国布里斯托大学博士后,是复睿微电子英国研发中心GRUK首席AI科学家,常驻英国剑桥。Dr. Luo长期从事科学研究和机器视觉先进产品开发,曾在某500强ICT企业担任机器视觉首席科学家。
来源:佐思汽车研究
《荀子 · 修身》曰“道虽迩,不行不至。事虽小,不为不成。”
ADS三十年之现状,可谓:“道阻且长,行则将至;行而不辍,未来可期”。《象传》故曰,“求而往,明也”。

-
(2022年7月) 台湾某市,天气良好,Auto-Pilot模式,与高速公路的路边桥墩相撞,导致车辆起火,人员重伤 -
(2022年7月) 美国佛州,天气良好,Auto-Pilot模式,与洲际公路的路肩停车位的卡车相撞,导致车辆起火,2人死亡 -
(2022年x月) 美国多州,夜晚行驶,Auto-Pilot模式,与抛锚车辆(抛锚现场设置有warning lights, flares, cones, and an illuminated arrow board)相撞,16次车祸中,15人伤1人亡 -
(2021年7月20日-2022年5月21日) 美国多州,Auto-Pilot模式,总共392起EV车祸,273次车祸来自纯视觉感知产品应用 -
(2018年3月) 美国加州,天气良好,Auto-Pilot模式,与高速公路的边界栅栏相撞,导致车辆起火,人员死亡 -
(2016年下月) 美国威州,天气良好,Auto-Pilot模式,(第一起)与洲际公路的路肩停车位的卡车相撞,导致车辆起火,1人死亡
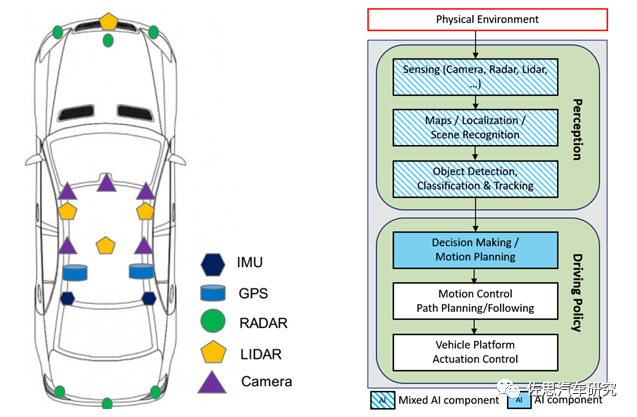
如图1所示,事故分析原因比较复杂,人为疏忽因素猜测应该是主因(例如系统感知决策能力不满足应用场景时责任人主体未能及时接管车辆等等)。有关系统感知决策能力问题,目测分析有可能来自于感知层目标识别,其原因可能包括:未能准确识别倒地的货车、路边桥墩、可行驶的区域,或者摄像头脏污,器件突然失灵等等。从上述分析可以看出,从2016年的第一起,到2022年的相同事故发生,纯视觉方案未能有效识别路肩停车位的卡车还是有很大可能性的。我们的出发点是希望能够更好的解决ADS行业落地的众多难题,当然不希望这些前沿技术探讨误导了行业专家和消费者心理,也特别注明不会对文中任何敏感领域的问题探讨承担任何法律责任,完整的事故分析结果请读者以官方出台的报告为事实依据。
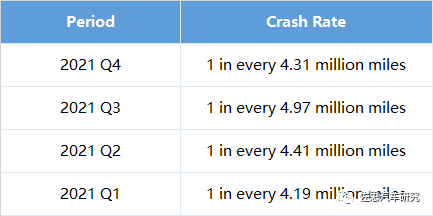
对比US全国1 in 484,000 miles的事故率,来自某著名T车厂发布的2021年自产车交通事故安全评估的分析数据如下:
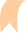
极端恶劣场景问题
Camera
-
可以提供360环视和远距前后视角的环境语义表征。 -
单目和多目Camera可以提供一定程度的目标深度信息。
不足:
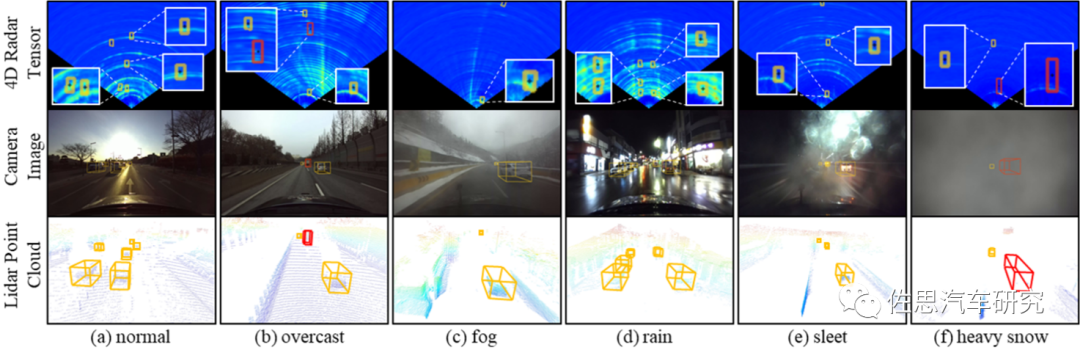
(如图4和图7所示)受恶劣场景影响严重:雨雪、浓雾、强光等场景。
镜头脏污会严重影响图像质量。
需要一个照明环境。
LIDAR
优势:
可以提供场景的空间信息。
不足:
-
难以检测有反光效应的或者透明的物体。 -
(如图5所示)当雨速高于40mm/hr到95mm/hr,信号反射密度严重损失并产生雨枕现象。 -
(如图5、图6所示)大雪天气下可视距离缩短并产生反射干扰波形。 -
(如图5所示)浓雾场景会产生鬼影现象。 -
温差会产生额外时间延迟。
Radar
优势:
-
总体对环境的适应性高。 -
对周围车辆检测准确率高,可以提供目标的速度信息。 -
4D Radar还可以提供目标高度的可靠信息。
不足:
-
不适合做小目标检测。 -
不能检测塑料袋等材料。 -
(如图6所示)大雨浓雾和暴风雪会产生接收信号强衰减和斑点噪声。
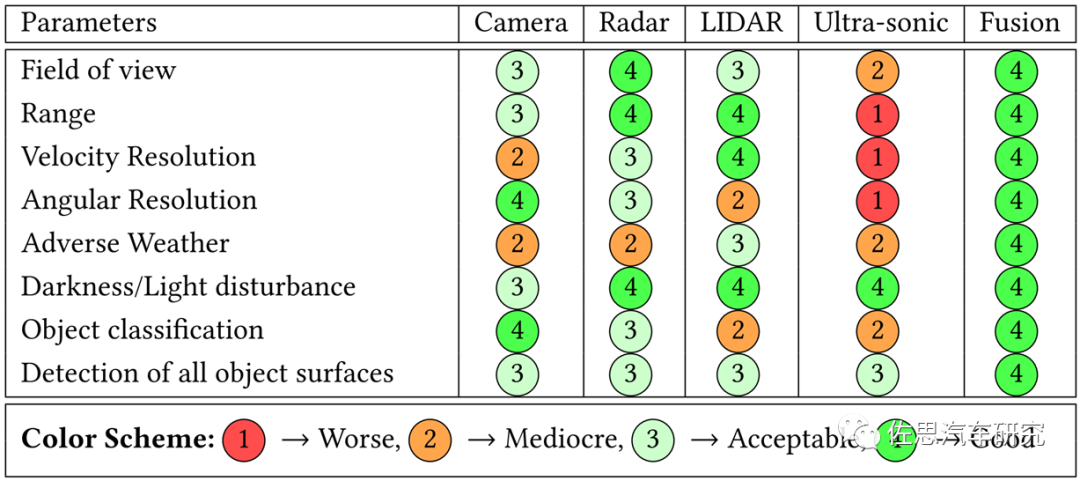
图3:ADS传感层的不确定性与性能对比(Khan, 2022)
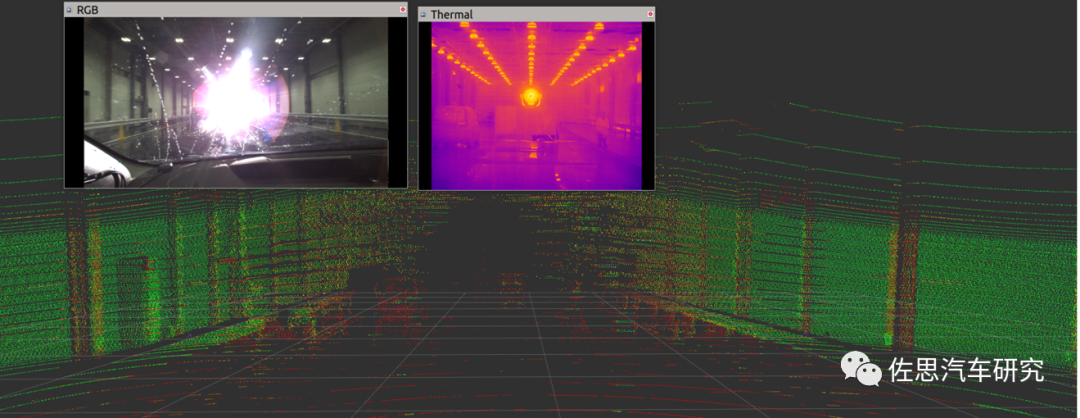



ADS感知层的一个主要挑战是恶劣场景的挑战。如图8所示,对比LiDAR和Camera,4D高清Radar发送的毫米波,可以有效穿越雨滴和雪花,不受低照与雨雪雾天气影响,但会受到多径干扰问题影响,总体来说对环境的适应性高,单独或者组合应用对2D/3D目标检测非常有优势,同时还可以提供高精度的目标高度和速度信息,可以有助于ADS的预测规划性能提升。
遮挡场景问题


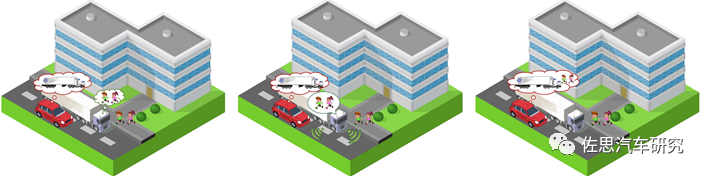
如图10所示的对比案例,可以看出车路协同可以有效解决盲区与上述所说的长距感知的挑战,但对应的缺点也不言而喻,部署的成本与长期可靠运营费用以及如何防网络攻击问题,这决定了对乡村和偏远地区的场景,需要寻求AVs自身的多模感知认知决策能力提升。

如图11所示,V2X的可行解决方案包括交通要道部署的RSU Camera,LiDAR,或者Radar,对算法设计来说,需要解决海量点云数据的压缩与实时传输,以及针对接收数据的时间轴同步,多模感知与特征融合目标识别等。目前这个领域基于Transformer在BEV空间进行多任务多模态的融合感知已经有了一些长足进展,融合的方式也可以自由组合,包括多视觉的Camera视频融合,以及 Camera与LiDAR或者Radar的组合融合模式,对点云数据的超分变率会改善融合效果,但融合对延迟非常敏感。
目标可感知和小目标的问题
立体盲Stereoblindness的问题
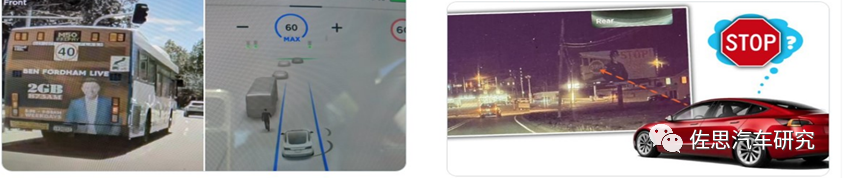
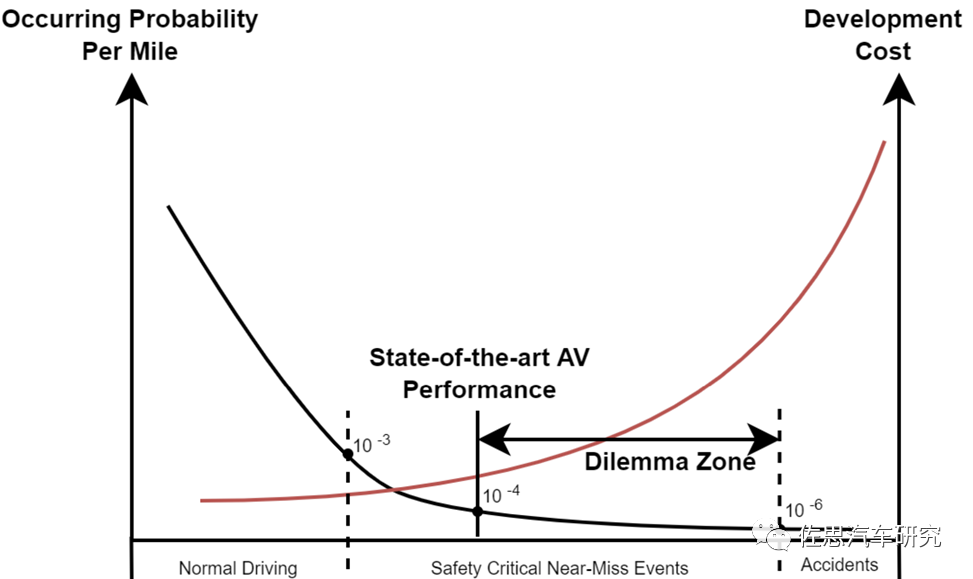
从UN的统计数据可以看到,全球每年道路交通事故都约有5000万人伤,125万人亡,经济损失可以高达约1.85万亿美元,而94%交通事故均来自可以避免的人为因素,且90%发生在中低收入的国家。研究表明,将有效预警提前1.9秒,事故率可下降90%,而提前2.7秒,事故率可下降95%,所以AI算法的感知认知领域的技术进展推动了辅助ADAS以及自动驾驶ADS技术的行业落地也是势在必然的。2021年统计数据表明,一个US司机在自然驾驶环境NDE下每英里的车祸发生平均概率约在百万分之一的水平。而2021年US加州自动驾驶车辆AVs最好的disengagement rate也只能做到十万分之一。由于篇幅原因,本文不准备全面展开讨论感知算法中众多不确定性问题。只重点讨论1-2个大家比较关注的技术难点。
稀缺目标检测的问题
“长尾问题”没有一个很明确的定义,一般指AVs即使经历了交通公路百万公里数的路况测试,对每个AI算法模块而言,包括感知层和决策层(预测+规划),仍不能完全覆盖各种各样的低概率安全至关重要的复合驾驶场景,即所谓的“Curse of Rarity(CoR)稀缺问题”。业界对如何实现一个通用的任意目标种类的检测器或者是一个通用的运动目标检测器,依旧是一个未解的技术难题。如何定义和分析这些稀有场景,也可以有助于更好理解目标检测识别语义理解预测决策算法性能的提升,从而加速安全可靠的ADS解决方案的开发与部署。
如同图15和本文开头所提到的交通事故原因分析所述,CoR问题中稀有(小样本)目标的场景比比皆是,这里简短罗列一些供大家参考:
Traffic Cone,Traffic Barrels, Traffic Warning Triangles未能被准确识别导致的二次车祸场景
不容易被检测到的公路上飘逸的塑料袋
山体滑坡导致公路路面障碍物
公路上行走的各类动物
车前方正常行驶交通车辆,如果装载了交通交通标志物体如何有效检测和决策
有一定坡度的路面如何有效进行2D/3D物体检测

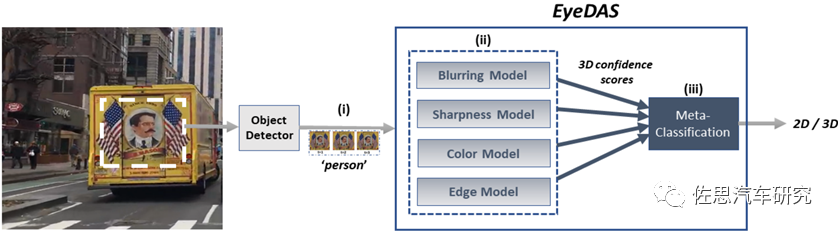
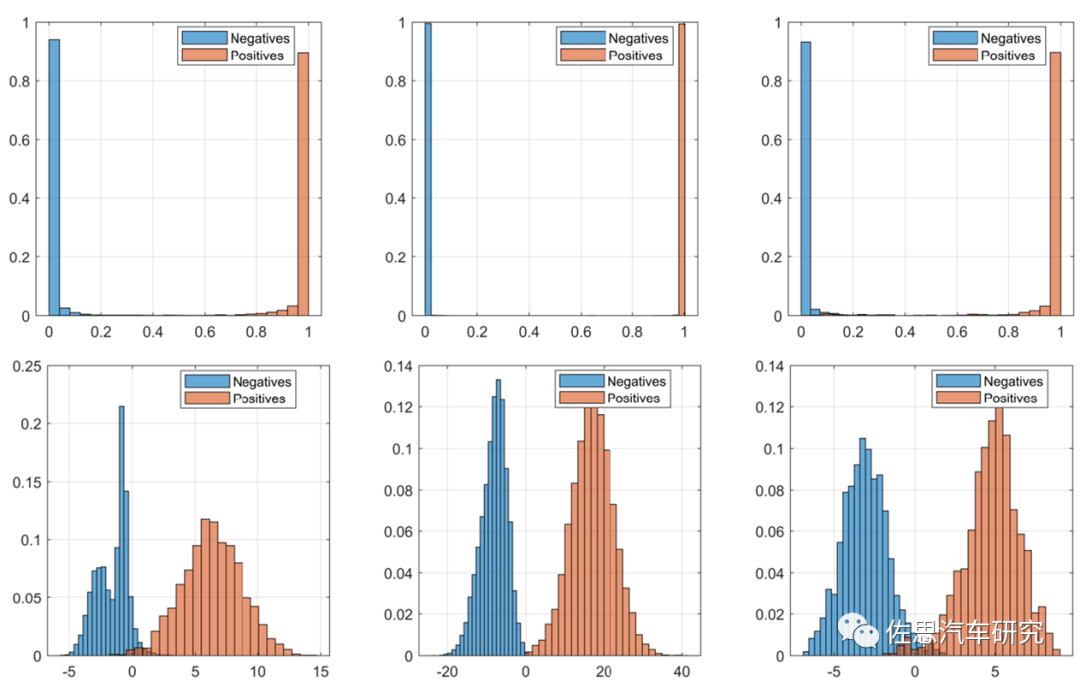
目标检测置信度问题
参考文献:
【1】Z. Wu and etc., “DST3D: DLA-Swin Transformer for Single-Stage Monocular 3D Object Detection”, https://ieeexplore.ieee.org/document/9827462
【2】W. Wang and etc., “Towards Data-Efficient Detection Transformers”, https://arxiv.org/abs/2203.09507
【3】S. Nageshrao and etc., “Robust AI Driving Strategy for Autonomous Vehicles”, https://arxiv.org/pdf/2207.07829.pdf
【4】M. Khan and etc., “Level-5 Autonomous driving – are we there yet?”, https://www.researchgate.net/publication/358040996
【5】D. Paek and etc., “K-Radar: 4D Radar Object Detection Dataset” https://arxiv.org/pdf/2206.08171.pdf
【6】R. Mao and etc., “perception Enabled Harmonious and Interconnected Self-Driving”, https://arxiv.org/pdf/2207.07609.pdf
【7】L. Fan and etc., “Fully Sparse 3D Object Detection”, https://arxiv.org/pdf/2207.10035.pdf
【8】Z. Hau and etc., “Using 3D Shadows to Detect Object Hiding Attacks on Autonomous Vehicle Perception”, https://arxiv.org/pdf/2204.13973.pdf
【9】Y. Zhang and etc., “Autonomous Driving in Adverse Weather Conditions: A Survey”, https://arxiv.org/pdf/2112.08936v1.pdf
【10】N. Li and etc., “Traffic Context Aware Data Augmentation for Rare Object Detection in Autonomous Driving”,https://arxiv.org/pdf/2205.00376.pdf
【11】G. Melotti and etc., “Reducing Overconfidence Predictions in Autonomous Driving Perception”, https://arxiv.org/pdf/2202.07825.pdf
【12】E. Levy and etc., “EyeDAS: Securing Perception of Autonomous Cars Against the Stereoblindness Syndrome”, https://arxiv.org/pdf/2205.06765.pdf
本文仅做学术分享,如有侵权,请联系删文。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~