
《我们与恶的距离》豆瓣剧评分析

一、爬取豆瓣剧评



drama_code = 30181230
base_url = "https://movie.douban.com/subject/{}/comments".format(drama_code)
for i in range(25):
params = {'percent_type': '', 'start': str(20*i), 'limit': '20', 'status': 'P', 'sort': 'new_score',
'comments_only': '1', 'ck': 'qN8_'}
try:
# 发送GET请求获取数据,headers和cookies从浏览器中获取
response = requests.get(base_url, headers=headers, cookies=cookies, params=params)
if response.status_code != 200:
break
result = response.json()
print('[INFO]第{}页数据获取成功。'.format(i + 1, ))
except Exception as e:
print('[ERROR]第{}页数据获取失败:{}'.format(i + 1, e))

二、数据有效性验证


三、评论分析和数据可视化
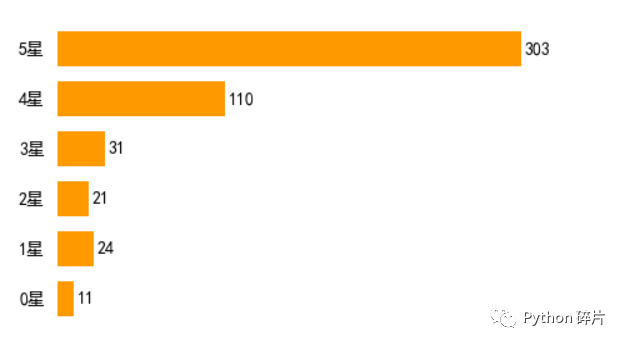
1. 500位用户分别打了多少星?
2. 评论中主要在讨论些什么?

讨论剧中的受害者和家属等人物之间的关系
讨论民主、法治等社会问题,也有不少人讨论剧中具体的问题,如精神病患,新闻,编辑室,律师等
认为该剧是年度最佳华语剧集
3. 评论热词被提到了多少次?

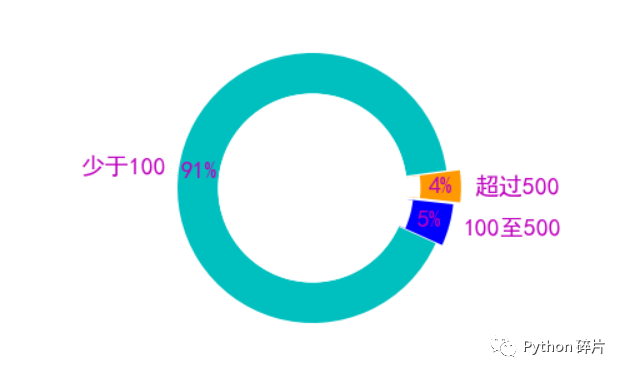
4. 评论获得了多少网友的赞同?
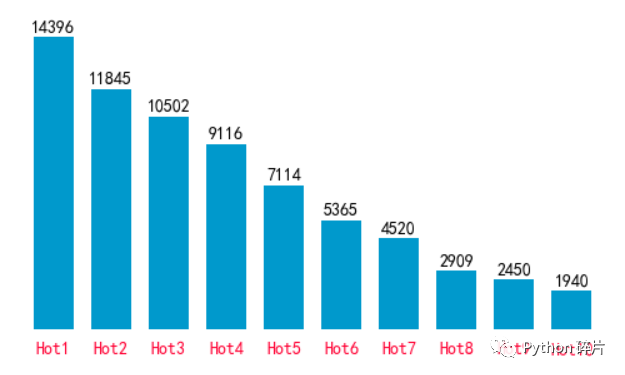
5. 热评都获得了多少点赞?
6. 点赞前三的评论内容是什么?
台剧质量都已经拍到这个深度了,国产剧还在拍什么家长里短,情情爱爱。。。。
韩剧在稳中求变,台湾剧在爆发式突变。我们的剧以不变应万变(反正没人看)
民众在斩草,政府在除根,媒体在浇水,只有王赦在研究土壤。
四、代码获取
评论