
谈谈CNN中的位置和尺度问题
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


1 CNN是否存在平移和尺度的不变性和相等性
1.1 不变性和相等性的定义
cell的存在,其对于平移、旋转有一定的不变性,另外由于对图像局部对比度归一化的操作,使其对于光照也有着一定的不变性。又比如说SIFT特征提取,其对于以上四点都有着不变性,其中由于尺度金字塔,使得对尺度也有不变性。这里我们对于不变性的理解就是,同一对象发生平移、旋转、光照变化、尺度变换甚至形变等,其属性应该一致。下面我们给出具体的不变性和相等性的定义。 而对于相等性(equivalence),顾名思义,就是对输入进行变换之后,输出也发生相应的变换:
而对于相等性(equivalence),顾名思义,就是对输入进行变换之后,输出也发生相应的变换: 不过如果我们只考虑输出对于输入不变性和相等性的情况,则会难以理解,因为我们更多地是想象着特征层面的映射,比如:
不过如果我们只考虑输出对于输入不变性和相等性的情况,则会难以理解,因为我们更多地是想象着特征层面的映射,比如: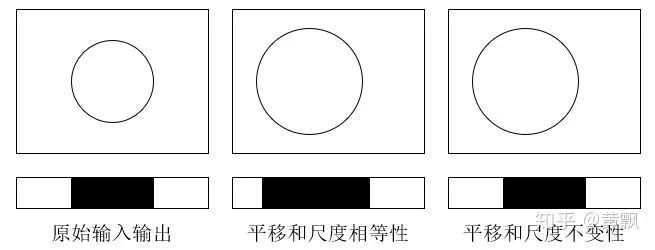
1.2 CNN网络的执行过程

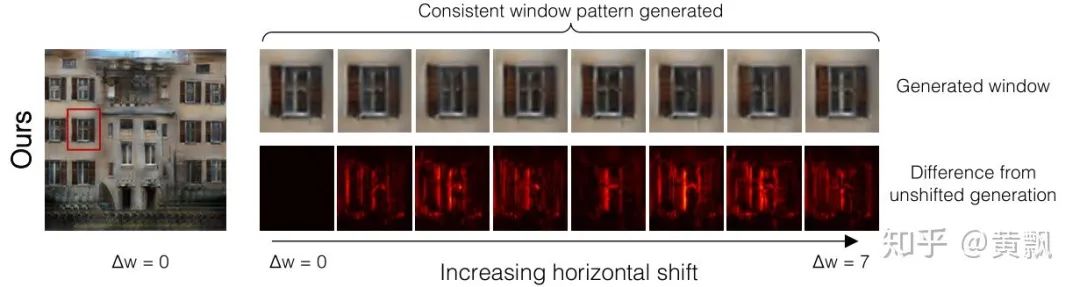
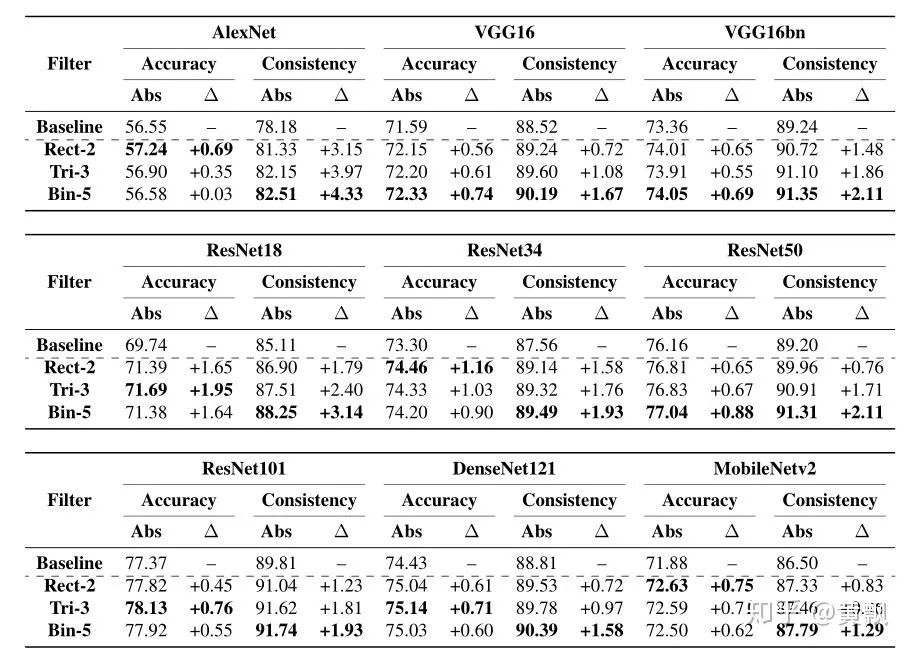
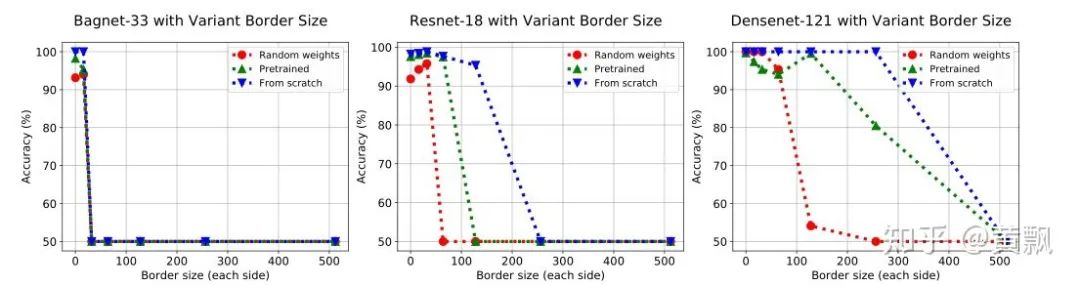
1.3CNN网络潜在问题与改进

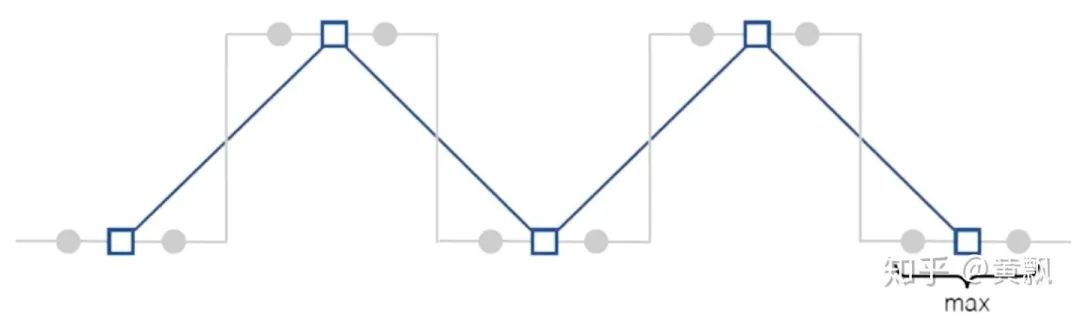
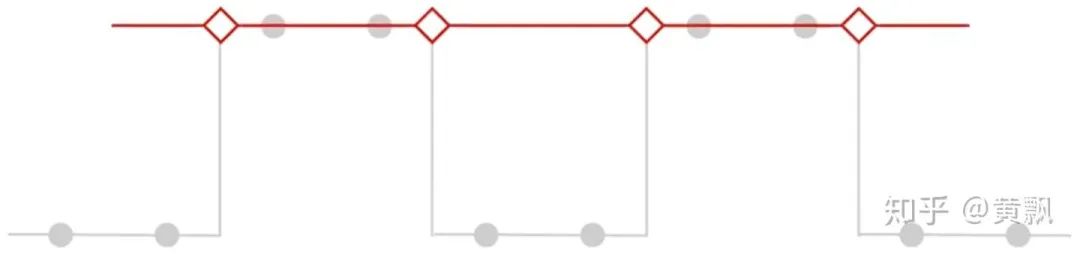
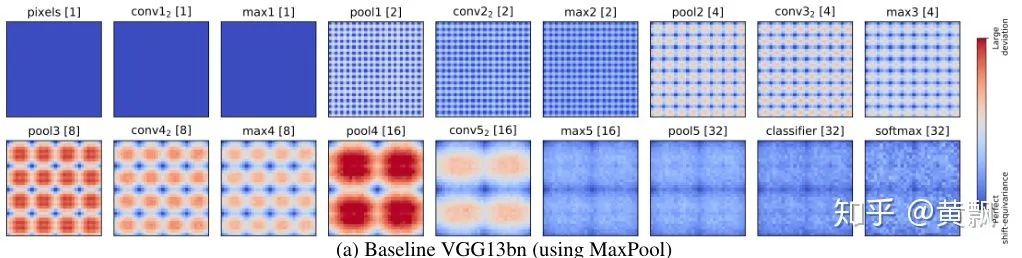
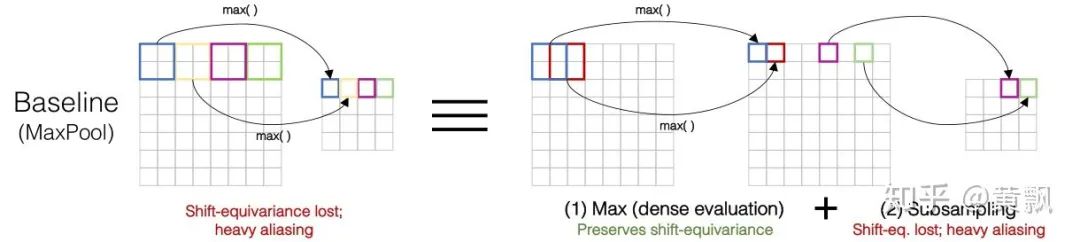

Rectangle-2:[1, 1],类似于均值池化和最近邻插值;
Triangle-2:[1, 2, 1],类似于双线性插值;
Binomial-5:[1, 4, 6, 4, 1],这个被用在拉普拉斯金字塔中。

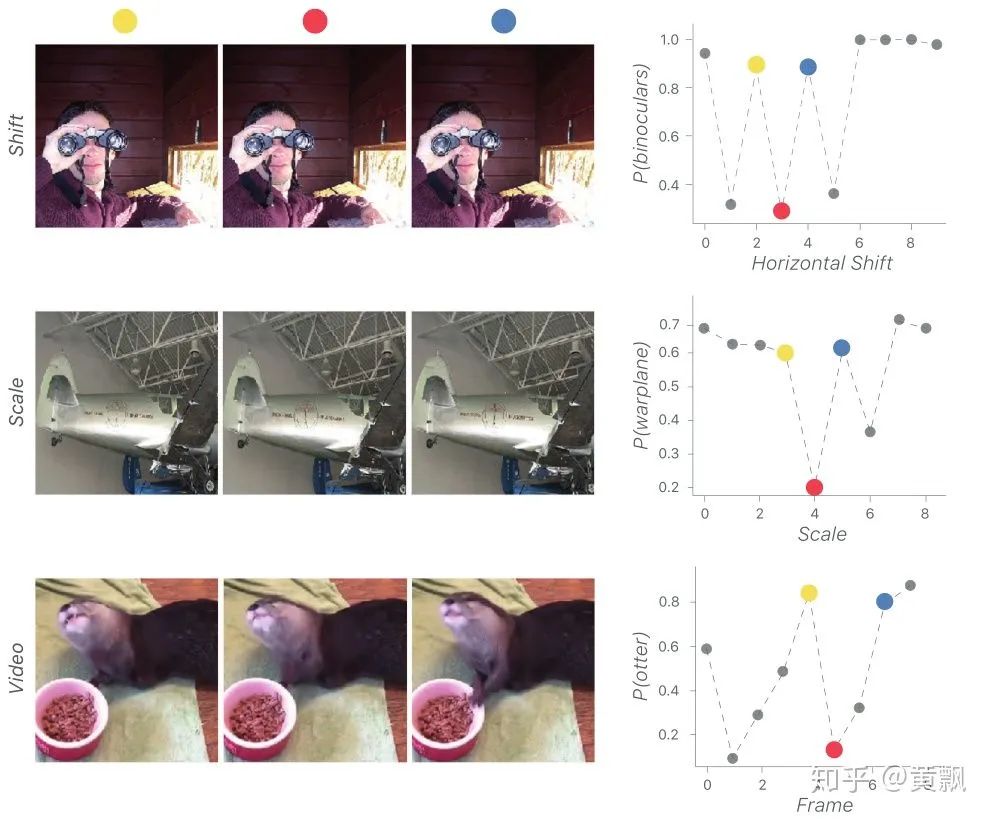
如果
 是经过卷积操作且满足平移不变性的特征,那么全局池化操作
是经过卷积操作且满足平移不变性的特征,那么全局池化操作  也满足平移不变性;
也满足平移不变性;对于特征提取器
 和降采样因子
和降采样因子  ,如果输入的平移都可以在输出上线性插值反映出来:
,如果输入的平移都可以在输出上线性插值反映出来:
由香农-奈奎斯特定理知, 满足可移位性,要保证采样频率至少为最高信号频率的2倍。
抗锯齿,这个就是我们刚刚介绍的方法;
数据增强,当前在很多图像任务中,我们基本都会采用随机裁剪、多尺度、颜色抖动等等数据增强手段,的确也让网络学习到了部分不变性;
减少降采样,也就是说只依赖卷积对于输入尺度的减小来变化,这一点只对小图像适用,主要是因为计算代价太高。
2 CNN对于位置和深度信息的预测
2.1CNN如何获取目标的位置信息


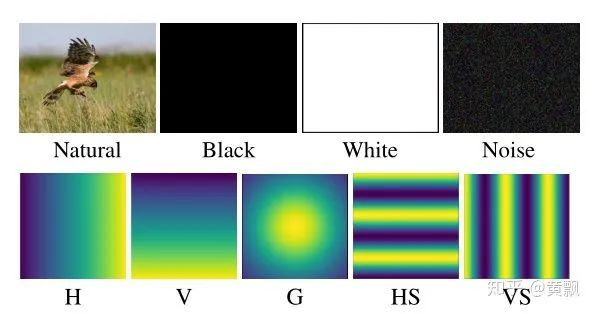




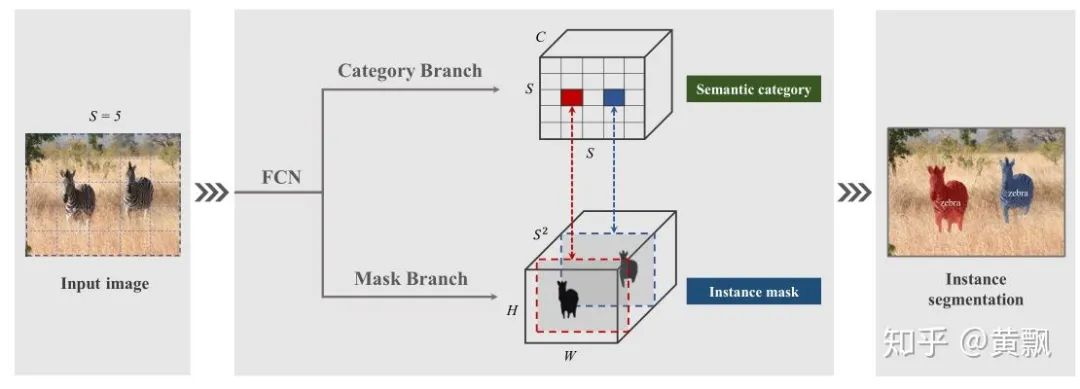
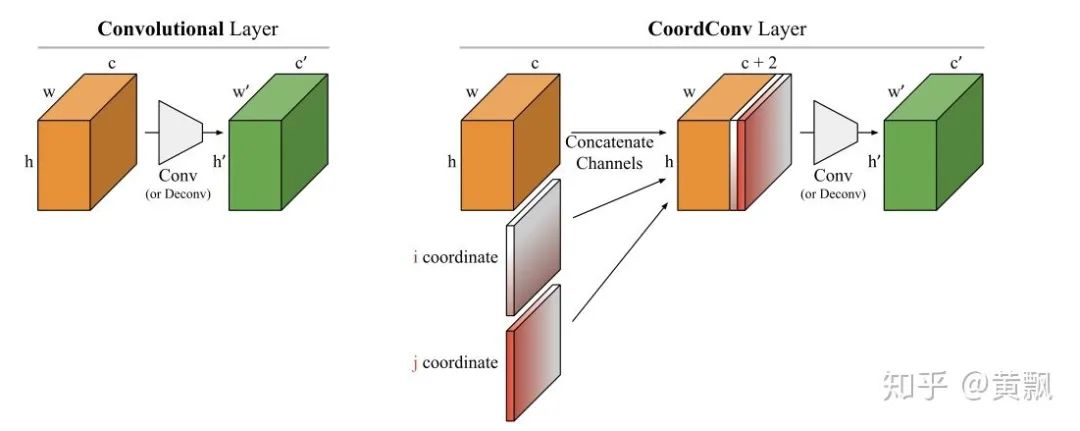
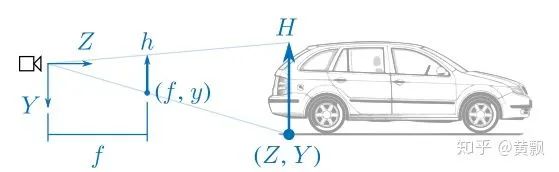
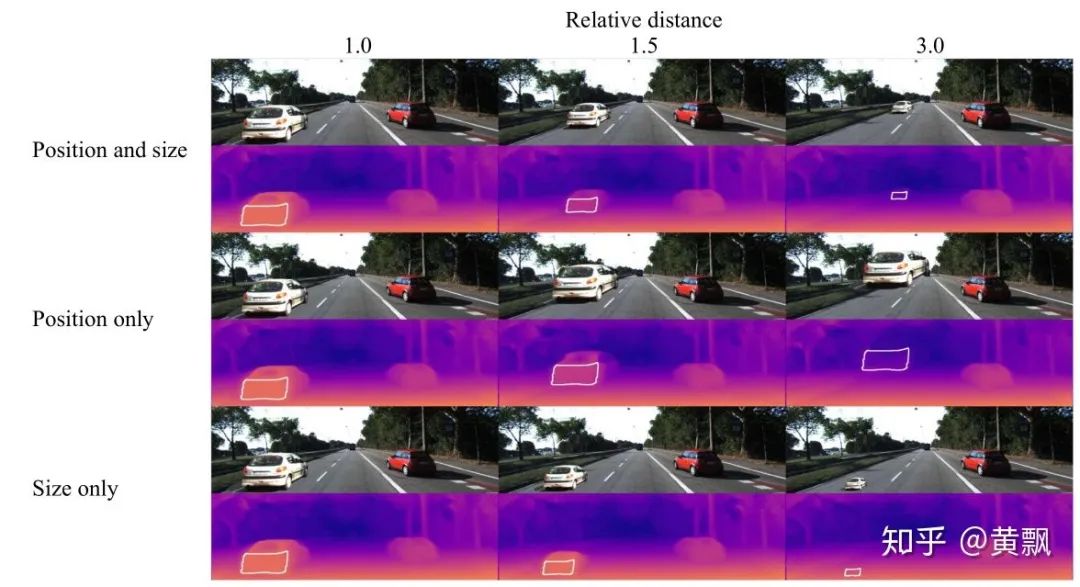
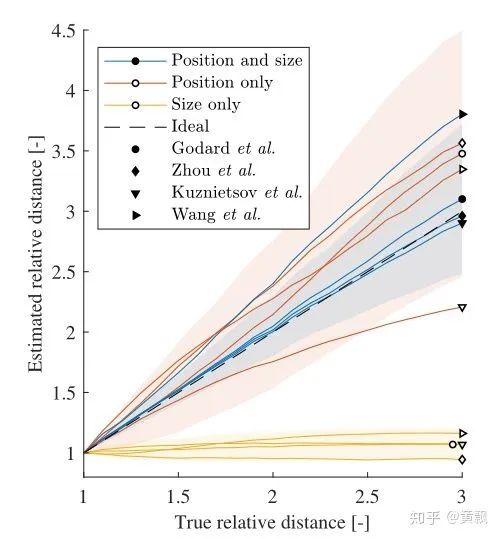
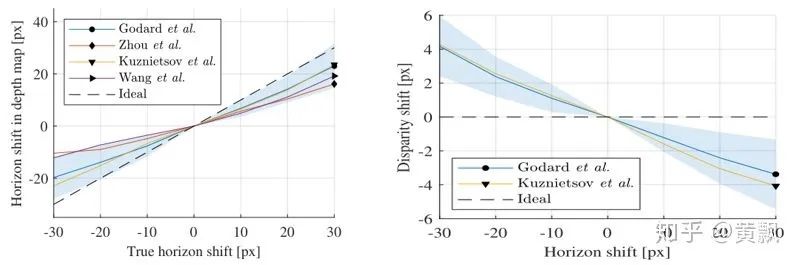
2.2CNN如何预测目标的深度信息
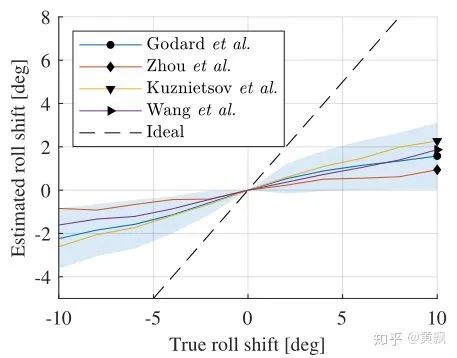
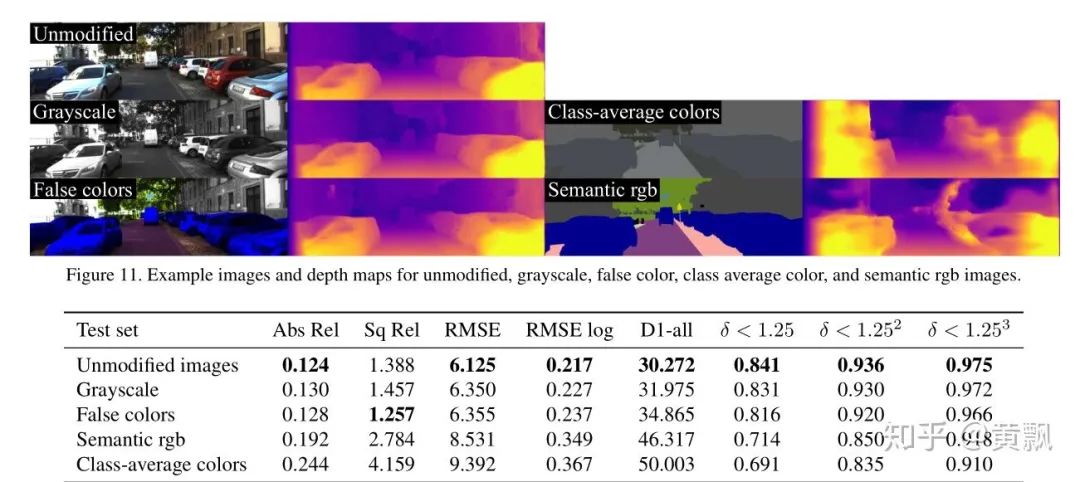
2020.3.18更新
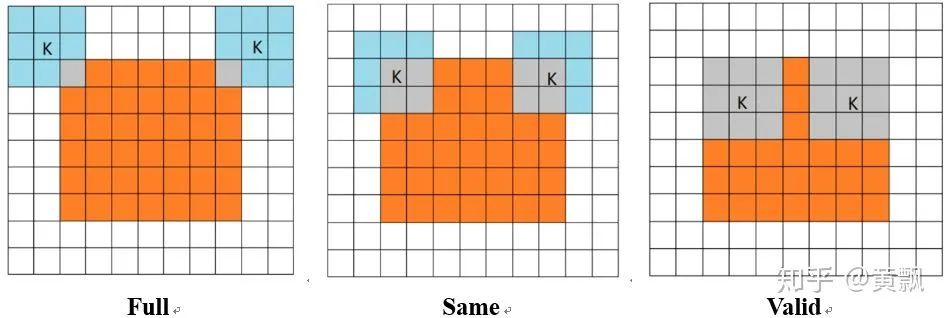
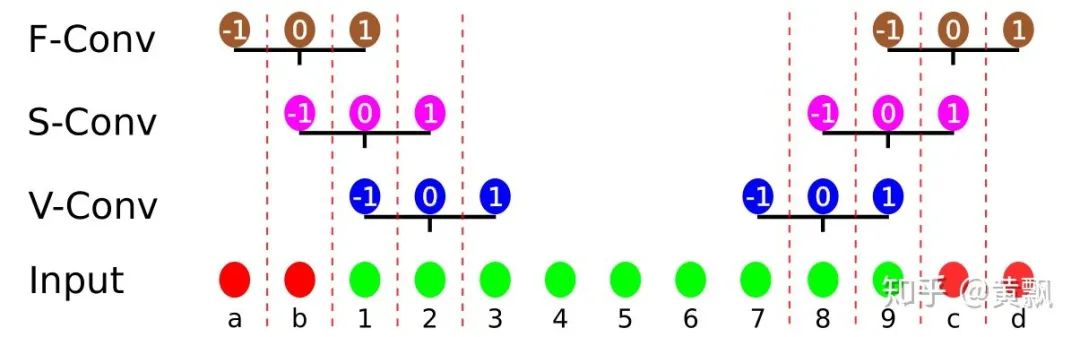
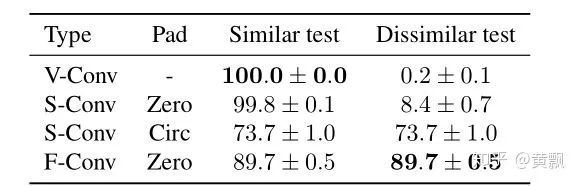
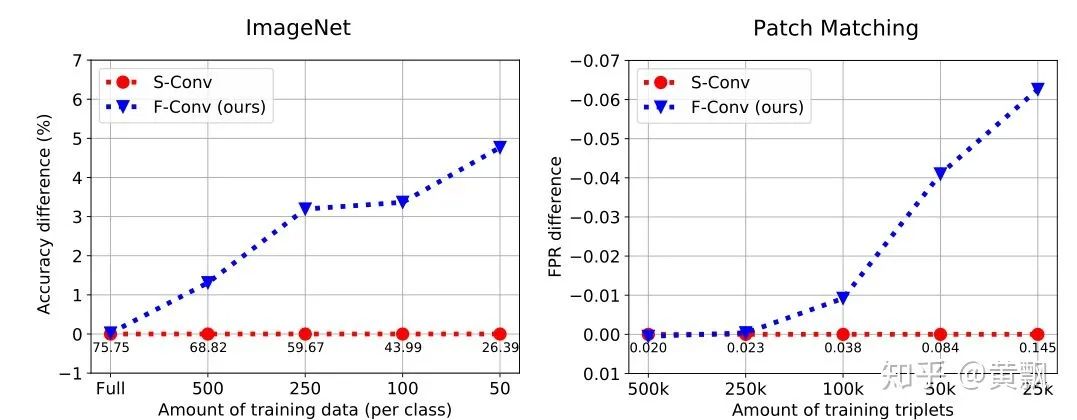
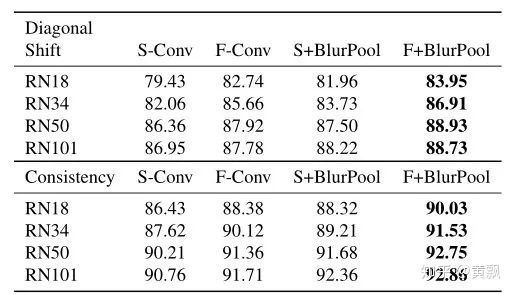
valid模式下卷积核最右边的1永远无法作用于绿色部分的1,same模式下的卷积核最右边 1永远无法作用于绿色部分的1 。作者以zero-padding和circular-padding两种模式做了一个例子说明:
1,valid和same+zero-padding模式对于待卷积区域的绝对位置比较敏感。紧接着作者又分析了每个位置被卷积的次数:


好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论