
搜狐智能媒体数据仓库体系建设实践
批量数据处理:根据不同的业务需求场景,需要对数据进行分层,上层数据基于底层数据通过aggregation、join等计算生成,上层数据生产任务依赖于底层数据产生任务,任务调度管理成为批量数据处理的一个核心功能诉求,以及由此衍生出的数据血缘管理、数据质量管理、数据权限管理等等一系列功能,这方面也有不少开源的产品,但在设计上或多或少都存在一些问题,本次演讲会介绍搜狐智能媒体团队自研的任务调度管理、元信息管理、数据质量管理、数据权限管理等系统的技术实践;
实时数据处理:目前业界的焦点都在stream processing系统上,但针对很多aggregation、join等应用场景,stream processing并不能很好的胜任,能够支持数据实时导和MPP查询引擎的系统--比如Apache Doris,才能很好地满足这些应用场景,本次演讲会介绍Apache Doris在搜狐智能媒体的一些技术实践。
1. 数据仓库定义

数据仓库是1991年Bill Inmon在《Building the Data Warehouse》中最开始提出的概念。数据仓库的定义是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。从定义中,可以看出数据仓库不仅仅是一个数据存储计算软件或产品,而是包含整个数据分析处理过程体系。
2. 数据分析

数据仓库主要是供给数据数据分析使用的,其分类主要参考商业智能分为三大部分:
Data Reporting:分析维度较少,延迟较低,并发度较高
OLAP:分析维度、延迟和并发度都比较适中
Data Mining:分析维度可能几百上千,维度较多,对于延迟的容忍度较高,一般用户较少,并发度较低
3. OLAP
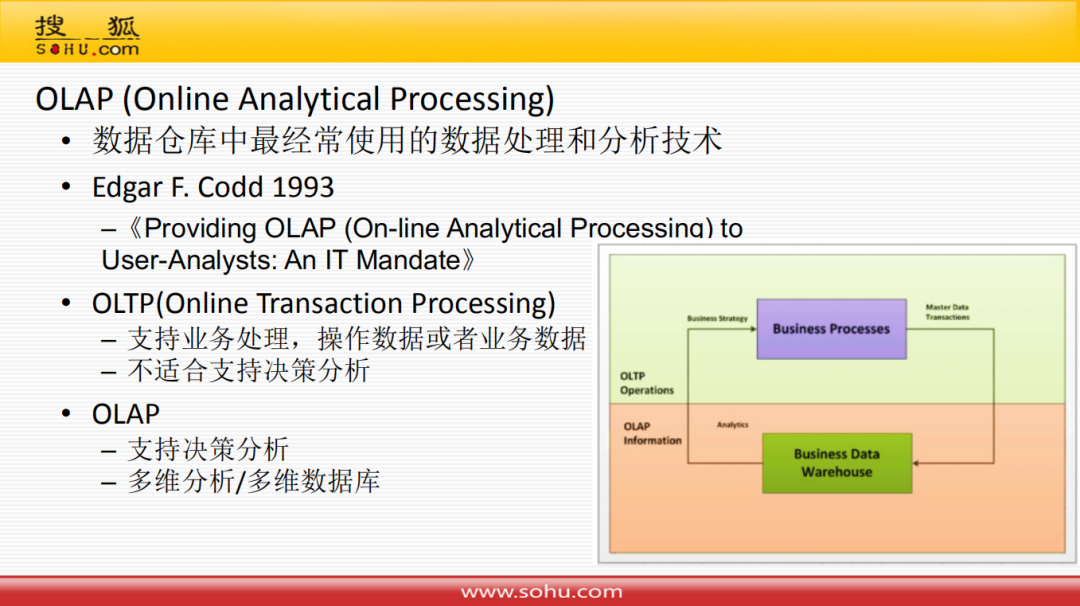
OLAP是数据仓库中最经常使用数据处理和分析技术,是Edgar F.Codd在1993年发表于《Providing OLAP(On-line Analytical Processing) to User-Analysts:An IT Mandate 》论文中。OLAP主要是针对OLTP对比来说的:
OLTP:支持业务处理,操作数据或者业务数据,不适合支持决策分析
OLAP:支持决策分析、多维分析/多维数据库
上方图中可以看出,OLTP产生的业务数据汇总到OLAP的数据仓库中,然后数据仓库中产生的分析结果会促进业务系统的改进。
4. 多维模型 ( Multidimensional Model)

前面提到的多维分析是建立在多维模型之上的:
多维模型就是OLAP中的数据组织范型
主要概念:多维数据集 ( Cube );维度 ( Dimension );维度层次 ( Hierarchy );维度级别 ( Level );维度成员 ( Member );度量/指标 ( Measure )
多维分析操作:上卷 ( Roll-up );下钻 ( Drill-down );切片 ( Silce );切块 ( Dice );旋转 ( Pivot )
5. 多维分析操作
① 上卷
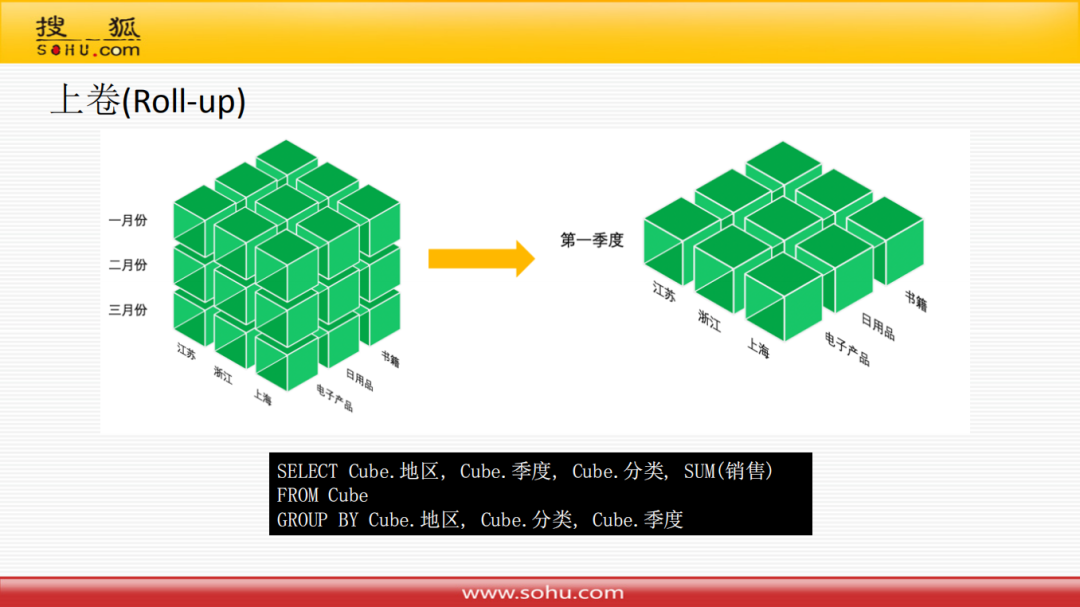
虽然多维分析都是对立方体的操作,但是可以映射到关系模型的sql语句上来;上卷就是通过group by把一些多的维度去掉。
② 下钻
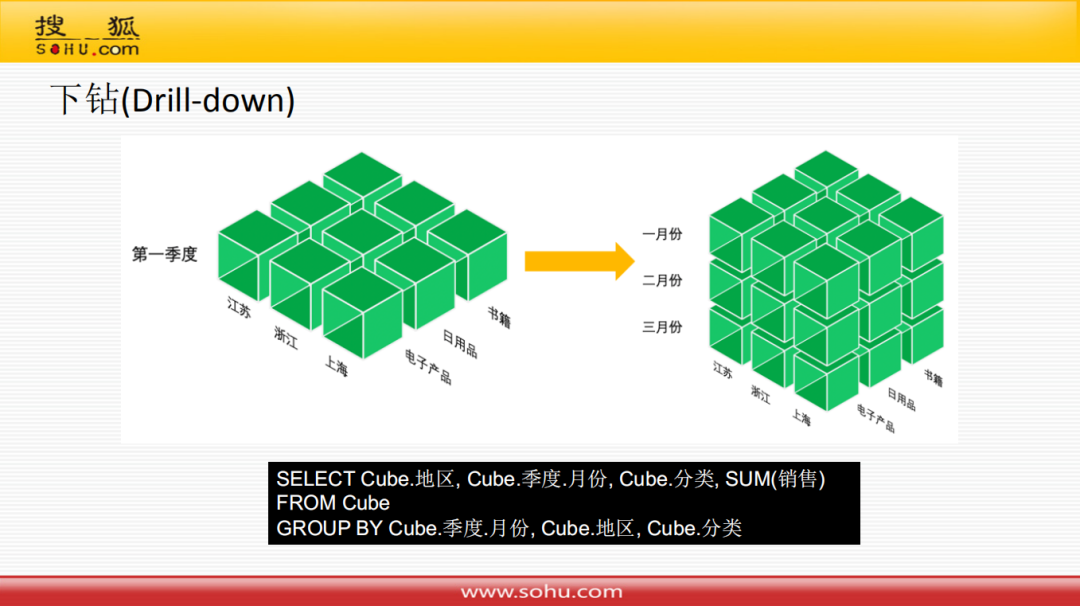
下钻操作,对应到关系模型的sql语句就是对一些低层次维度进行group by。
③ 切片
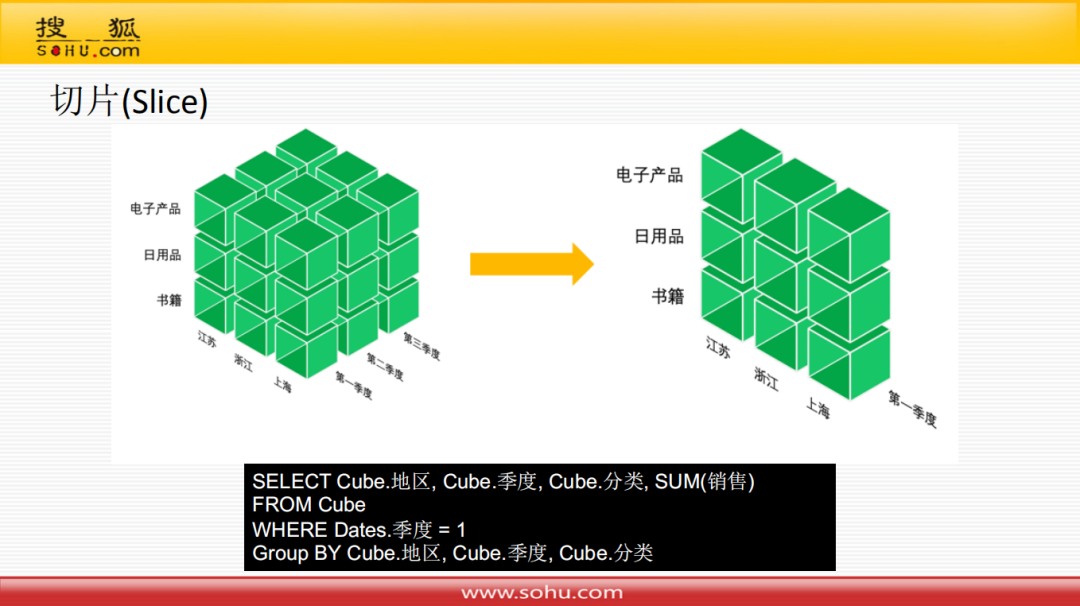
切片操作,对应到关系模型的sql语句就是增加一个where条件。
④ 切块
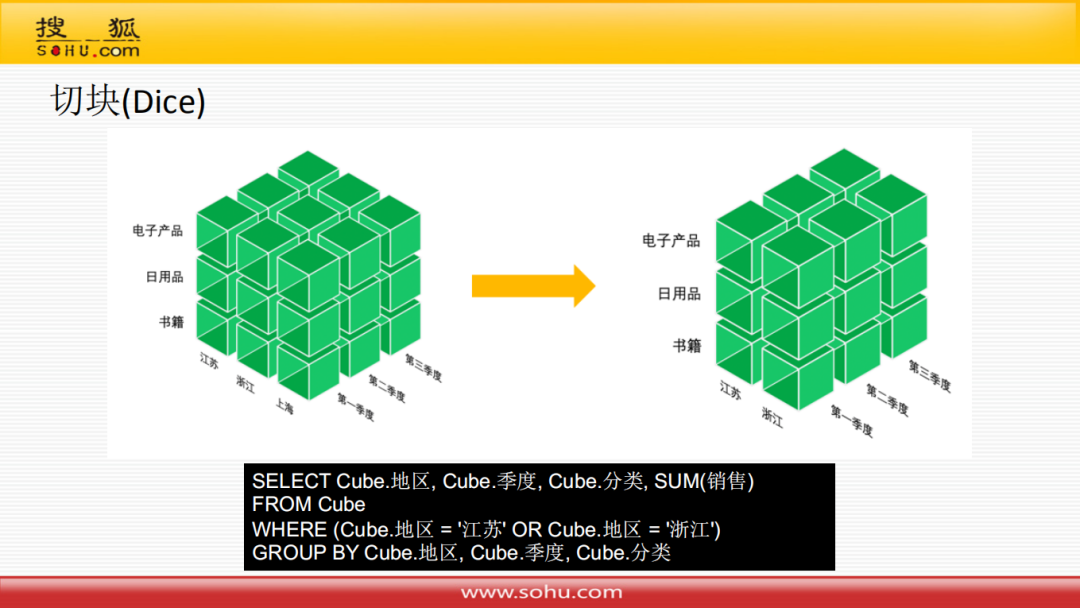
切块操作,对应到关系模型的sql语句就是增加两个where条件。
⑤ 旋转
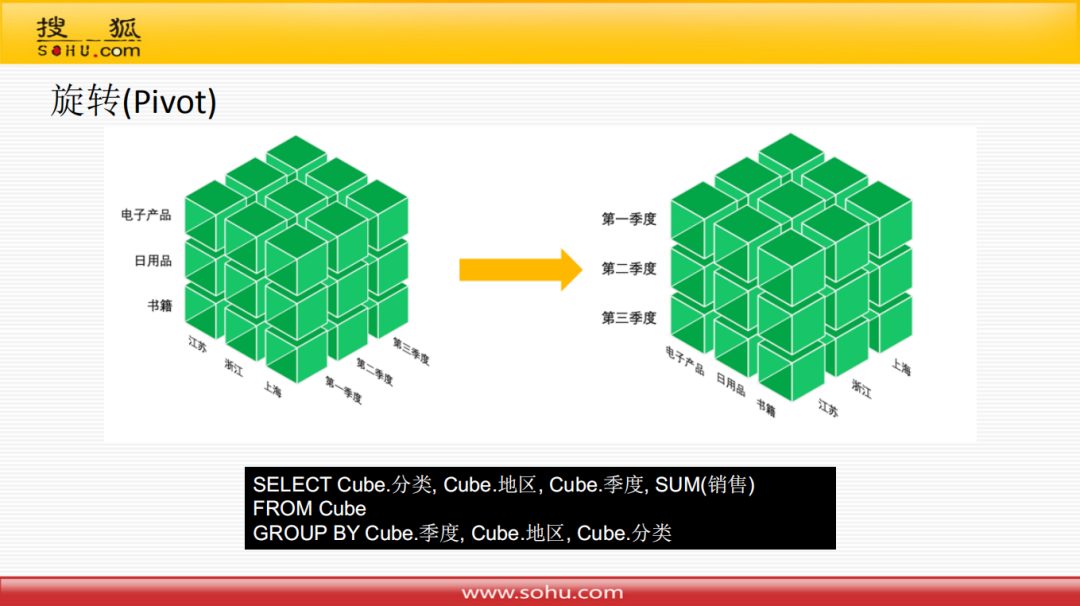
旋转操作,对应到关系模型的sql语句就是select时,把列的顺序重新编排一下。
6. OLAP Cube构建
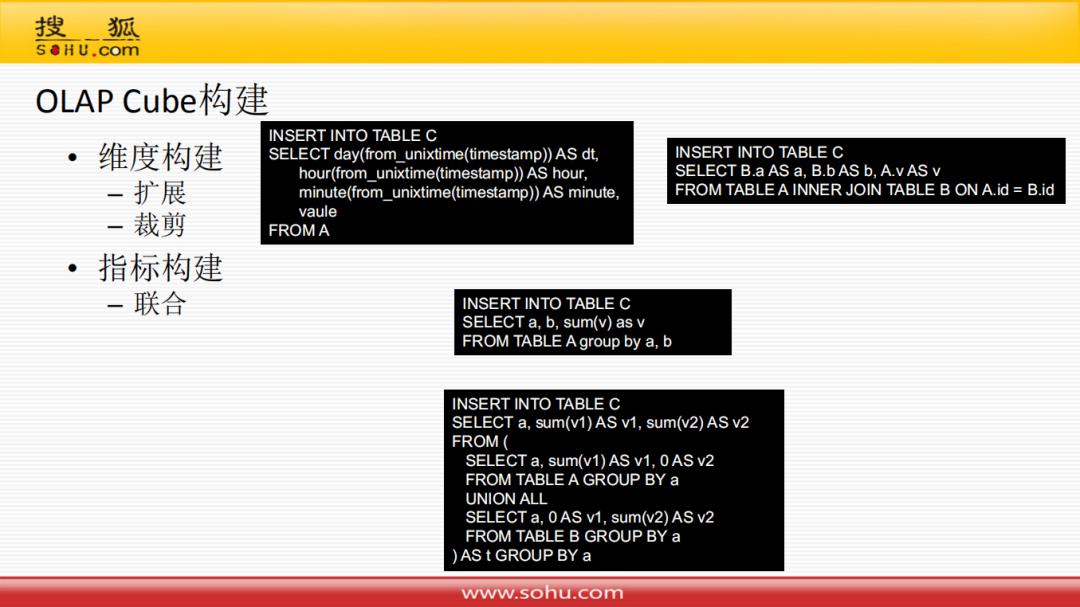
Cube构建主要包含两类:
维度构建:扩展 ( 例如:a. 通过时间戳字段扩展天、小时和分钟维度;b. 利用Id关联将维度表的属性放到Cube里面来 );剪裁 ( 类似于上卷操作,缩减维度 )
指标构建:联合 ( 指标在两个Cube里面,通过union all方式放到一个Cube里面 )
7. OLAP多维数据库
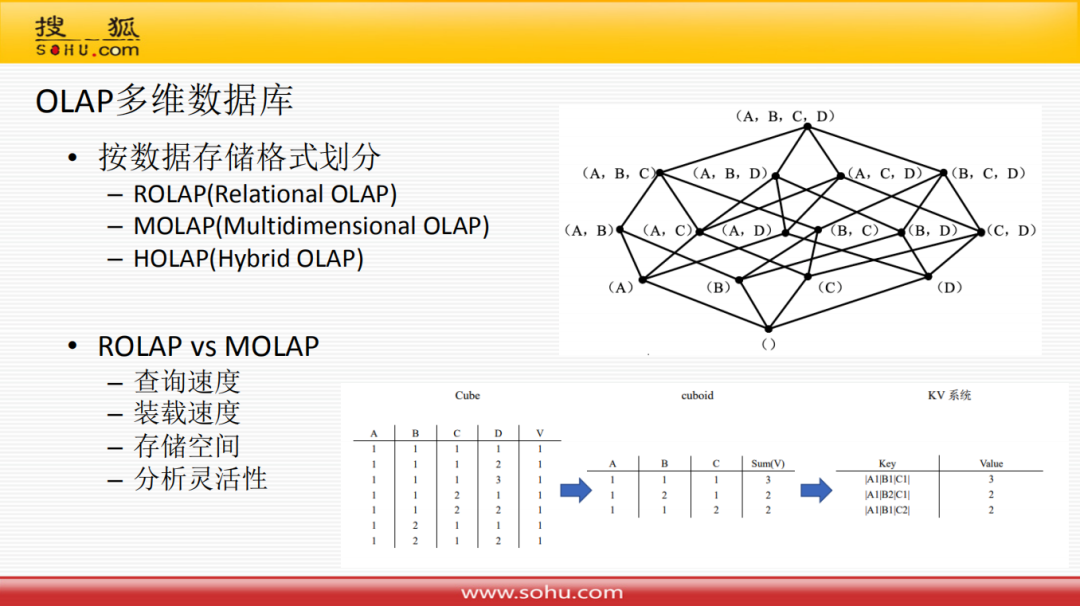
OLAP多维数据库按照存储格式划分:
ROLAP:基于关系型模型的数据库
MOLAP:基于多维模型的数据库,如上图所示,将不同的维度组成一个CuboId,然后将结果存储到KV数据库中,MOLAP大概就是这样
HOLAP:就是讲ROLAP和MOLAP的一些特点综合起来
ROLAP和MOLAP对比来看:
查询速度:严格按照多维分析方式查询,MOLAP查询速度会更快一些,但是目前随着ROLAP的几十年发展,包含分布式和索引的一些优化,查询速度已经开始接近于MOLAP
装载速度:因为MOLAP需要做一些组合,所以装载速度慢于ROLAP
存储空间:MOLAP存储空间膨胀还是比较厉害的,所以要大于ROLAP
分析灵活性:MOLAP基本上只能基于KV查询,ROLAP是基于关系型的,灵活性上MOLAP要比ROLAP差的较多
8. 维度建模
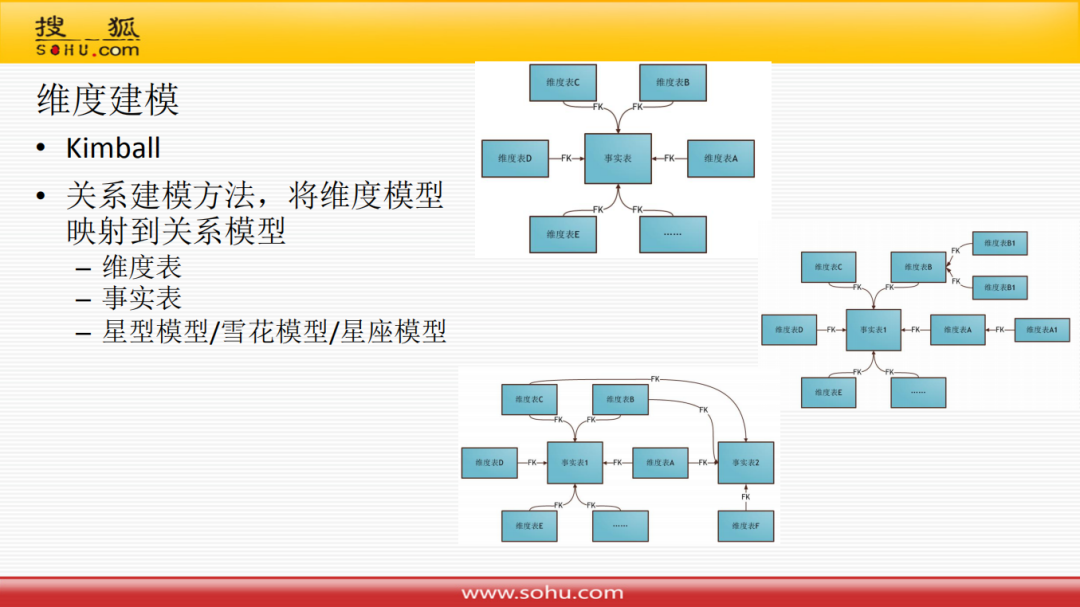
提到ROLAP就要提到维度建模,维度建模是数据仓库另一位大师Ralph Kimall倡导的,关系建模方法,就是将维度模型映射到关系模型:
维度表
事实表
星型模型/雪花模型/星座模型
9. 表分层

另一个比较重要的就是数据仓库都是面向主题的,一般创建Cube都会对表进行分层,主要分为下面几个层次:STG原始数据层、ODS操作数据层、DWD明细数据层、DWS汇总数据层、ADS应用数据层、DIM维度层。
这样分层的优势是:
防止烟囱模式,减少重复开发
将复杂问题简单化
层次清晰,便于使用和理解
10. 数据仓库体系架构
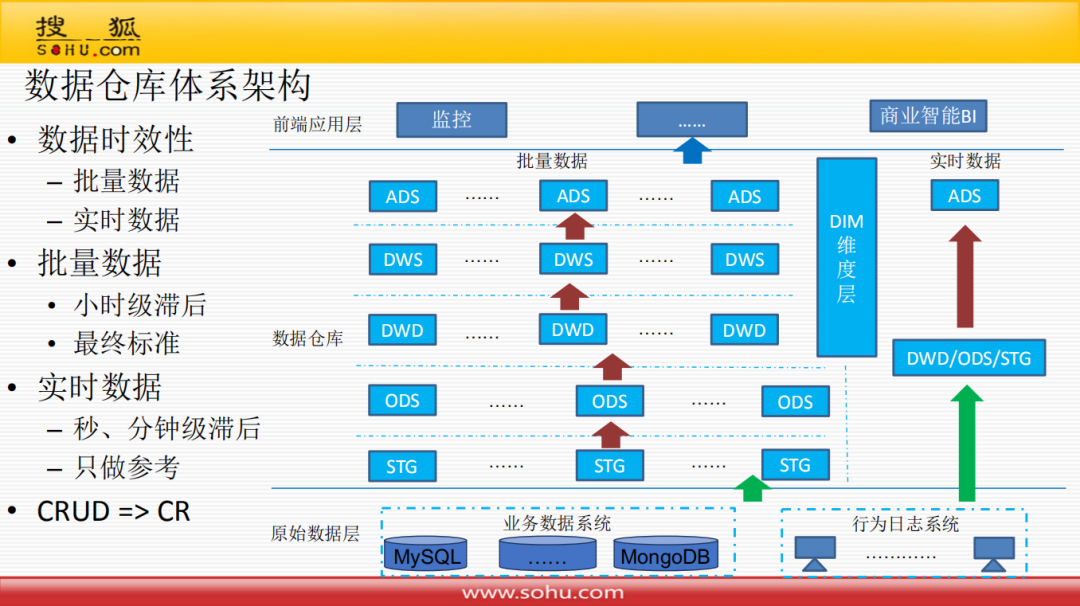
此处数据仓库体系架构主要参考了Lambda架构,按照数据时效性,分为实时层和批量层,只做新增和读取,一般不做删除和修改:
批量数据一般是小时级滞后,是最终标准
实时数据一般是秒、分钟级滞后,只作参考
批量数据层从原始的业务数据系统或者行为日志系统抽取数据到STG层,然后经由ODS、DWD、DWS层最终到ADS层供给应用方使用;实时数据层一般没有那么多层次,经过Spark Streaming等处理后直接放到Kafka里面,最后存储到ADS层供给业务系统使用
上面主要讲了数据仓库体系建设主要工作,也就是需求;接下来讲一下搜狐智能媒体的相关技术实践。
1. 搜狐智能媒体数据仓库技术架构
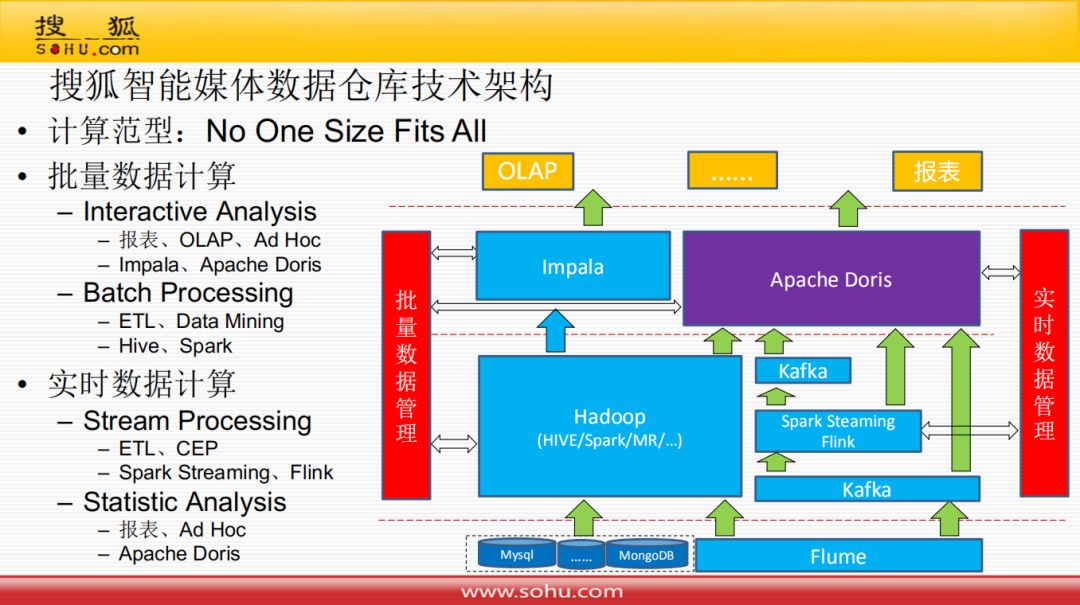
首先简单分析一下计算泛型,主要是根据Michael Stonebraker的论文《One Size Fits All》,不同场景选用不同的数据库:
批量数据计算:交互式分析 ( 场景:报表、OLAP、Ad HOC;技术:Impala、Apache Doris );批量处理 ( 场景:ETL、数据挖掘;技术:Hive、Spark )
实时数据计算:流处理 ( 场景:ETL、复杂事件处理;技术:Spark Streaming、Flink );统计分析 ( 场景:报表、Ad HOC;技术:Apache Doris )
2. Apache Doris

Apache Doris是百度开发的MPP架构的分析性数据库,看一下和其他技术选型的对比:
Kylin:MOLAP型数据库,因为目前主流应该是ROLAP数据库,所以没有考虑
ClickHouse/Druid/Elaticsearch:早期的典型的两阶段计算,没法做复杂的SQL处理,从分析复杂性角度上没有考虑
Impala/Presto:目前比较主流是MPP架构的数据库,Presto和Hawq可以认为是查询引擎,依赖HDFS作为存储引擎,HDFS适合批量数据导入,对实时数据导入支持不好;Impala也是查询引擎,但Impala既可以使用HDFS作为批量数据存储引擎,也可以使用KUDU作为实时数据存储引擎,但Impala的缺点是部署依赖太多,另外kudu只支持Unique Key模式,数据导入性能较Doris差,且对聚合查询不友好
1. 批量数据管理

批量数据管理和业界的方案基本相似,分为数据任务管理、数据元信息管理、数据质量管理和数据安全管理。
批量数据处理都是对全域数据在Hadoop上进行一些分析计算,最后供给业务层使用;在Hadoop上分析计算时候我们会进行上述的管理,首先对执行的数据任务进行管理,然后对产生的数据质量进行校验,校验通过后才能给业务方使用,基于这之上做了元信息和安全的管理。
2. 数据任务管理
① Workflow管理系统
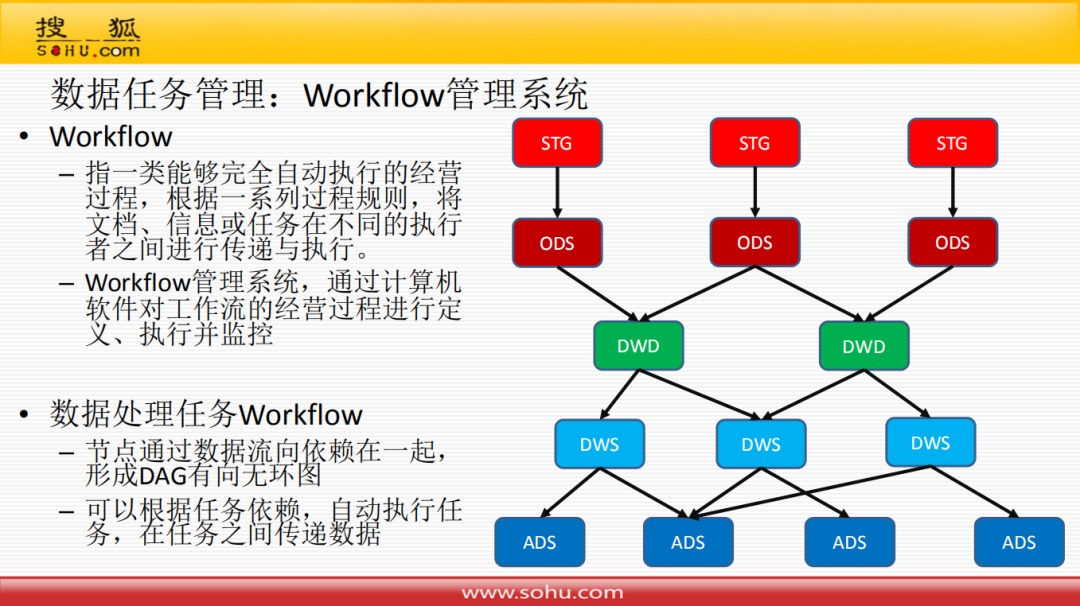
数据任务管理实际上就是Workflow的管理,Workflow是指一类能够完全自动执行的经营过程,根据一系列过程规则,将文档、信息或任务在不同的执行者之间进行传递与执行;Workflow管理系统通过计算机软件对工作流的经营过程进行定义、执行并监控。
数据处理任务Workflow就是将节点通过数据流向依赖在一起,形成DAG有向无环图;可以根据任务依赖,自动执行任务,在任务之间传递数据。
开源的数据仓库Workflow管理系统:

目前用的比较多的框架有国外的Azkaban、Oozie和Airflow,但是他们都存在一些问题:
以Flow为单位进行编辑、管理和发布部署,对多人协同开发不友好
复杂的任务依赖不友好,如天依赖小时任务,需要写代码调度的辅助代码
新建任务或修复任务,需要有补数据功能,以Flow为单位进行调度,不适合补数据处理
② DAG节点=>任务&实例

在数据任务管理中,将DAG节点抽象为两个概念:任务和实例。
任务:用户以任务为单位进行编辑,使用SQL、Shell等进行数据处理代码,支持最细小时粒度的周期属性,可配置依赖父节点、就近依赖和自依赖以及一些其他属性、告警等
实例:按天或小时为单位,根据任务周期属性,生成一个或多个实例,并制定每个实例运行时间;继承对应任务中的数据处理代码;根据任务依赖属性和运行时间动态生成;依赖的父节点运行成功或者自身运行时间已到则会生成一个实例
③ 实例依赖生成规则
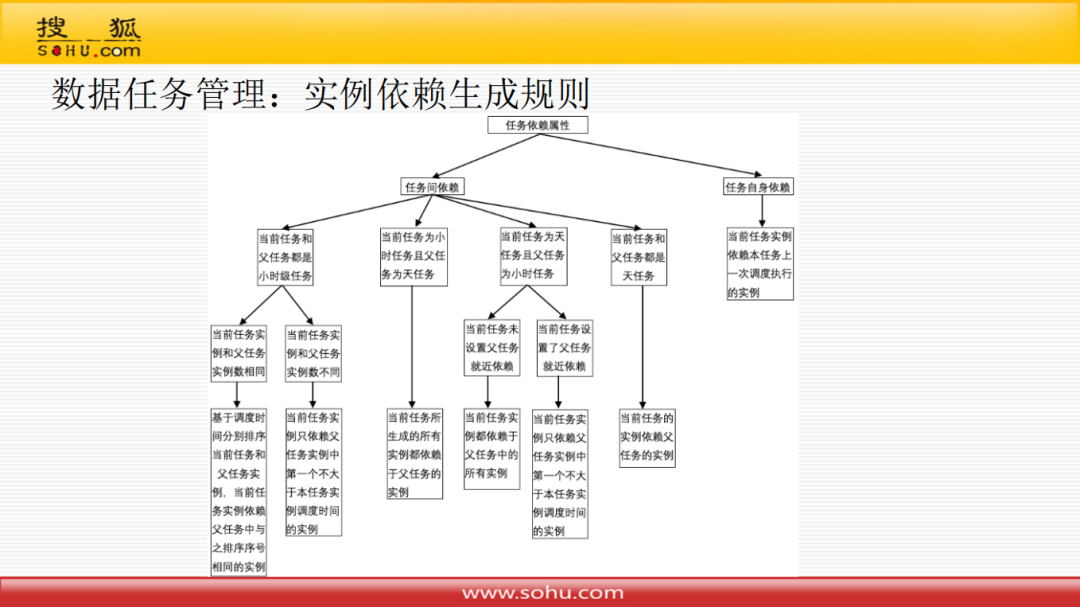
上图展示了实例依赖生成的具体规则。
④ 实例依赖示例
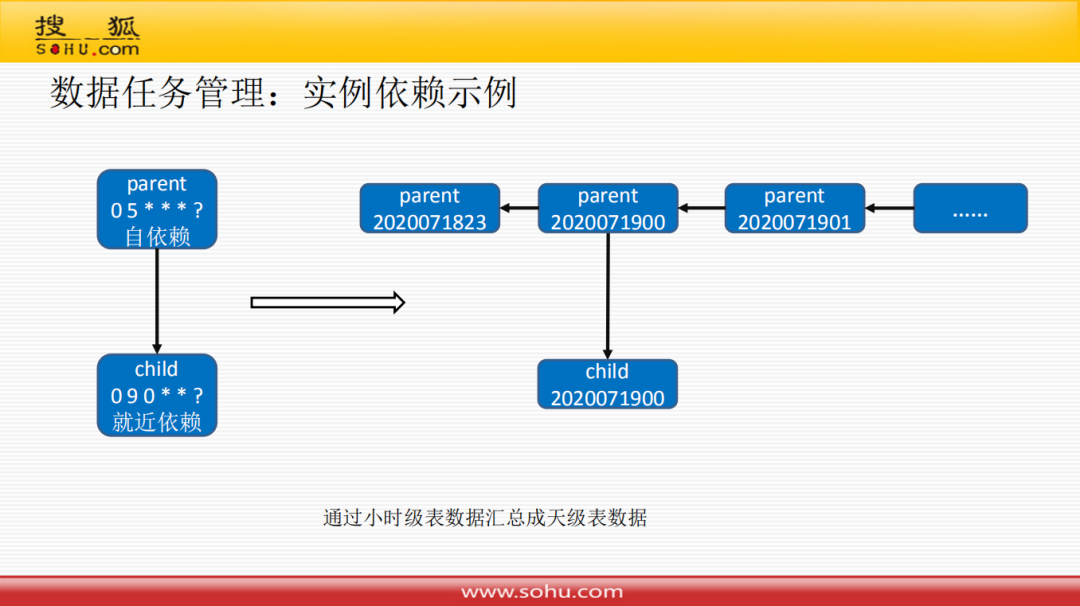
根据上面举的例子来看上图实例依赖的示例,通过小时级表数据汇总成天级表数据,父任务会在每小时调度一次,子任务在每天的0点9分执行一次,然后根据父任务的结果产生一个天级别的数据;父任务要设置自依赖,子任务要设置就近依赖,这样就可以通过这样的语义设置很方便地达到业务要求。
⑤ 补历史数据
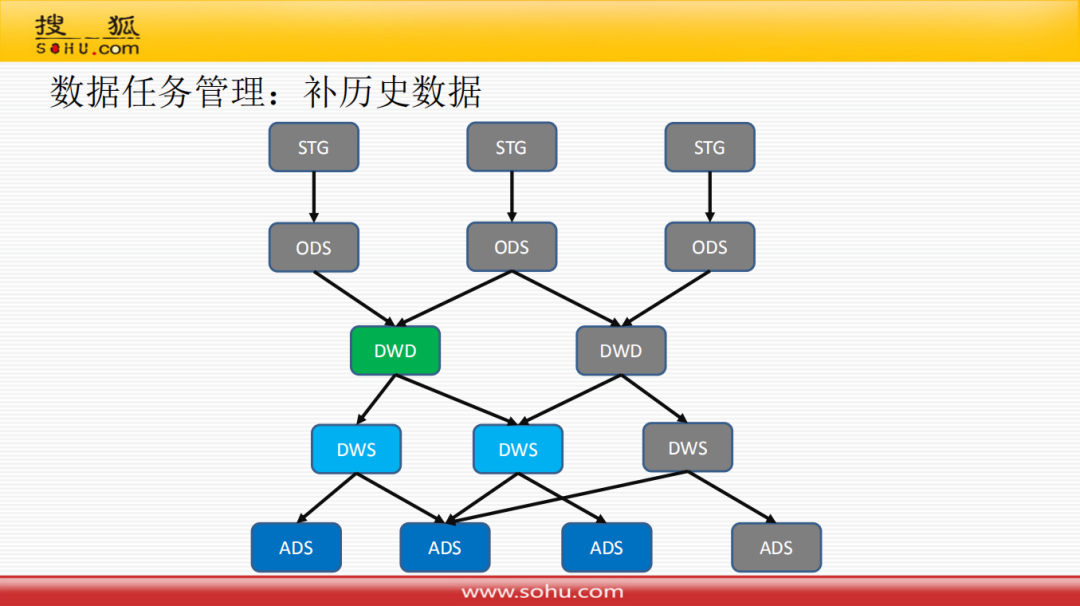
介绍一下补历史数据的问题,一个大的DAG任务中需要新增数据处理任务,或者是某个任务运行或逻辑有问题,就把这块的根节点拿出来从对应的时间段开始向下游修复数据,这样的模型实现起来就比较方便了。
3. 数据质量管理
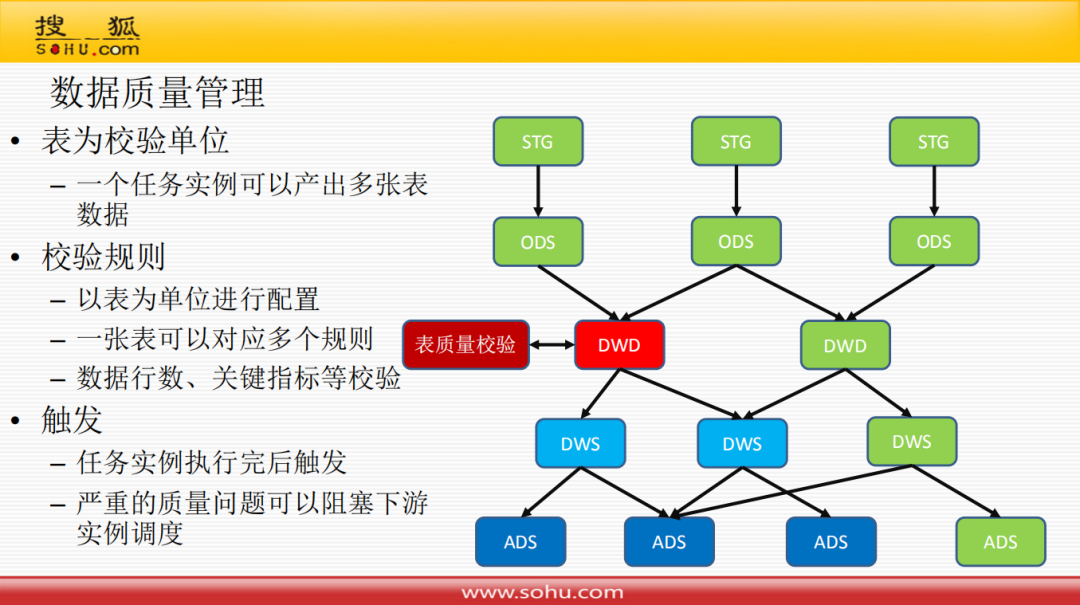
表为校验单位:一个任务实例可以产生多张表数据
校验规则:以表为单位进行配置;一张表可以对应多个规则;数据行数、关键指标等校验
触发:任务实力执行完后触发;严重的质量问题可以阻塞下游实例调度
4. 数据元信息管理
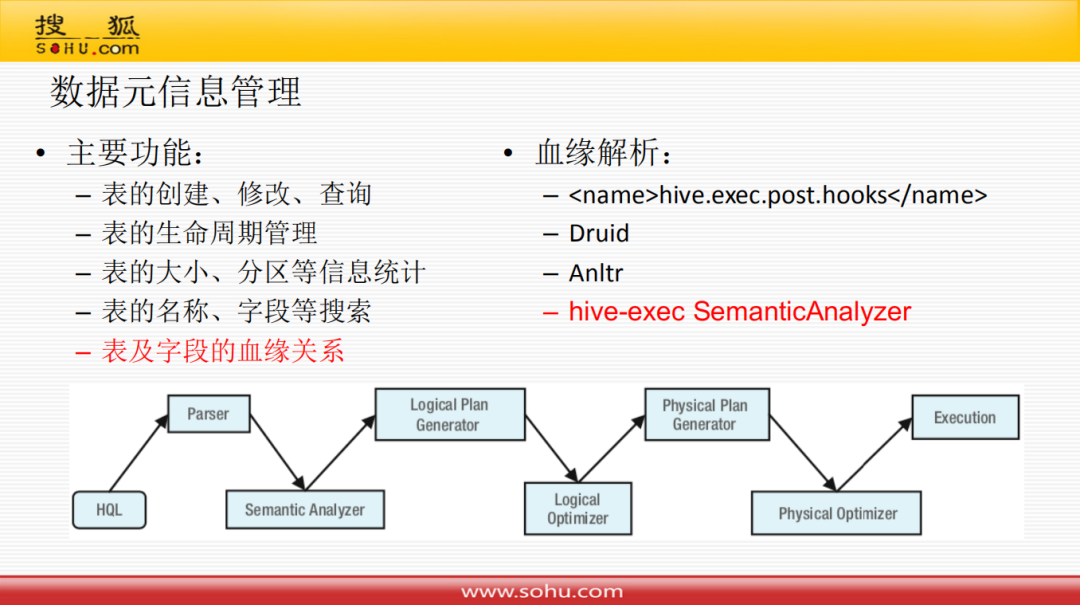
元信息管理主要功能包含:表的创建、修改、查询;表的生命周期管理;表的大小、分区等信息统计;表的名称、字段等搜索;表及字段的血缘关系。
主要说一下血缘解析的做法,这块是设计时候的难点:目前业内的大部分做法是通过hive的hook将字段信息释放出来,然后直接导入到mysql表里面;但目前没有采用这种方案原因是集群不是自主维护,另外就是它是在任务执行完之后才执行,我们需要在任务保存时候就要进行数据血缘关系的解析。
在这块有调研一些方案:阿里的Druid提供一些解析功能,但是对Hive支持不是很好;利用Anltr结合网上开源的一些代码进行解析,但是对Hive的集成也是有一定问题的;后来调研了Hive的代码,发现可以重写SematicAnalyzer函数,放到自己代码里面,像是hook那样在保存或者执行代码时候解析血缘关系。
接下来看一下上图的Hive的整个生命操作流程:
HQL->Parser->Semantic Analyzer->Logic Plan Generator->Logical Optimizer->Physical Plan Generator->Physical Optimizer->Execution血缘解析:
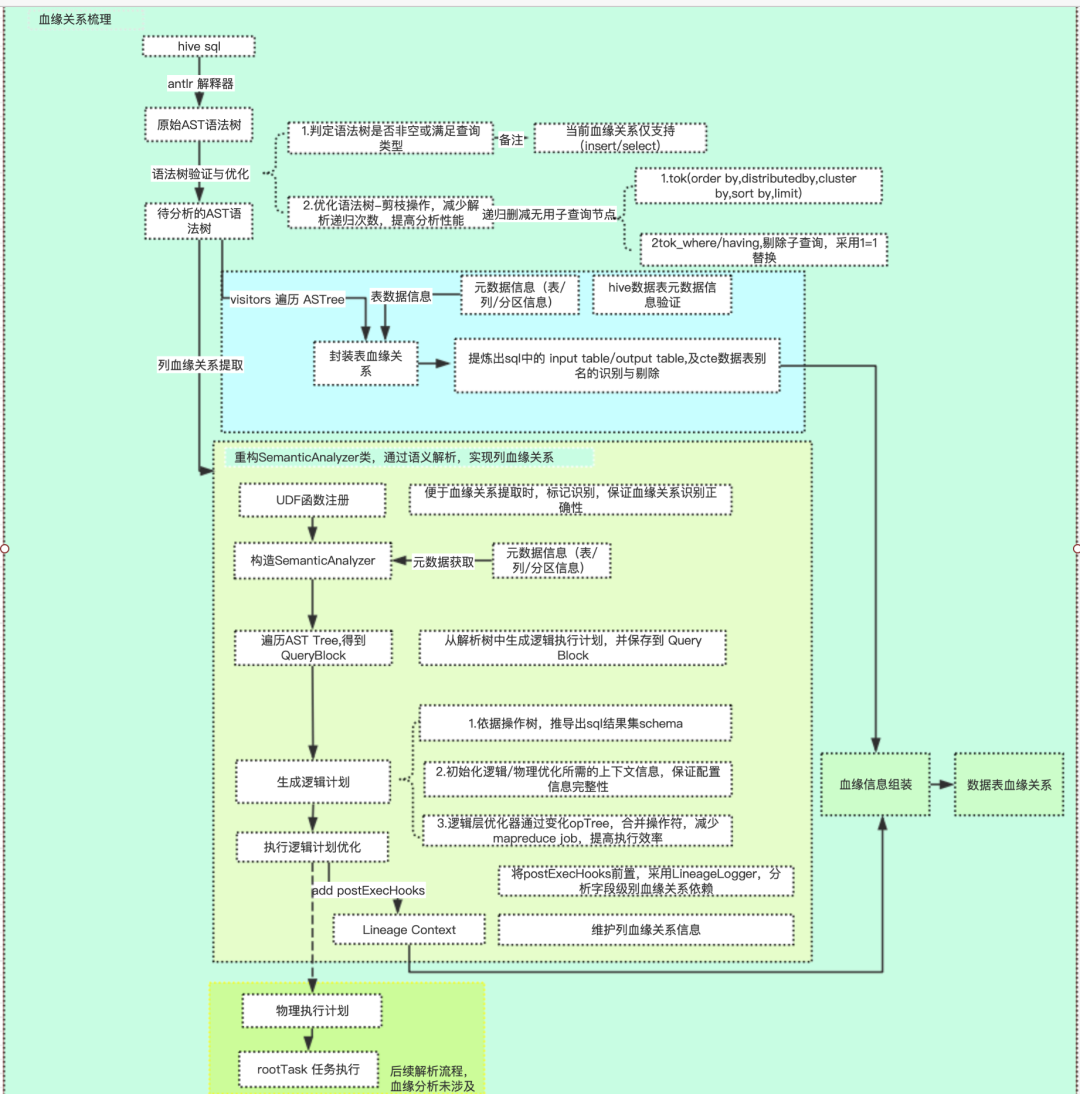
血缘解析这块主要分为两部分:
表血缘解析:解析SQL语句获得抽象语法树;对抽象语法树进行验证和裁剪;遍历抽象语法树获取上游表名 ( TOK_TAB ) 和下游表名 ( TOK_TABREF )
字段血缘解析:注册UDF;重构SemanticAnalyzer;逻辑计划生成和逻辑计划优化;添加postExecHook,执行LineageLogger获得Lineage Context;从LineageContext中组装血缘信息
5. 数据安全管理
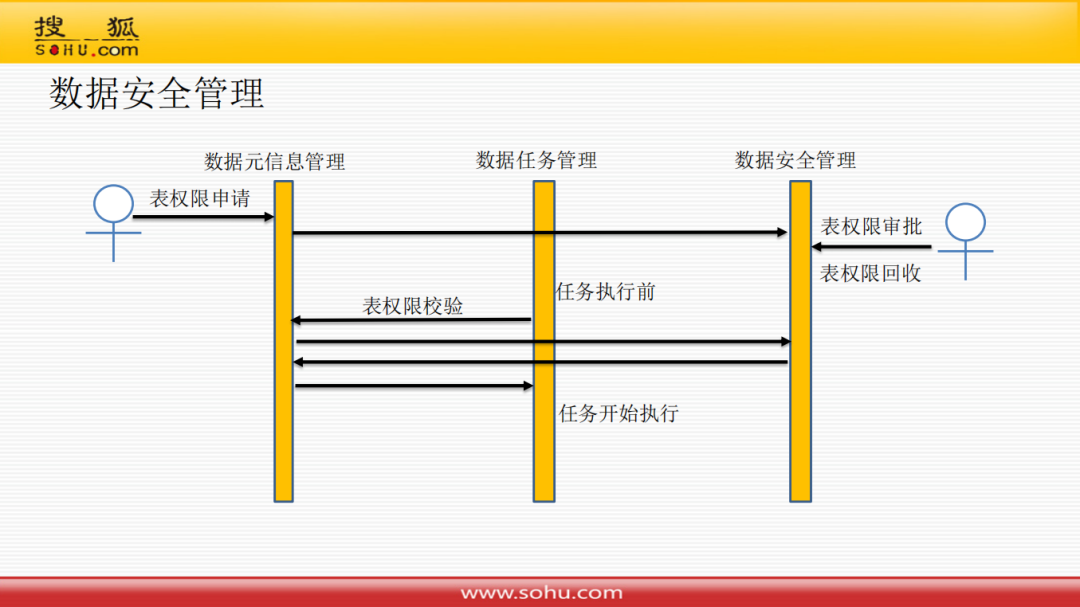
有了数据血缘关系之后做数据安全管理就很简单了,目前只做了表级别的安全管理,字段级别太复杂,可能会对用户使用产生一定的影响。
数据安全管理流程是:用户针对要使用的表进行权限申请,然后管理者就会对表权限进行审批或者回收;在数据任务执行前,会进行表权限的校验,如果没有权限则会暂停任务执行,并通过使用方。
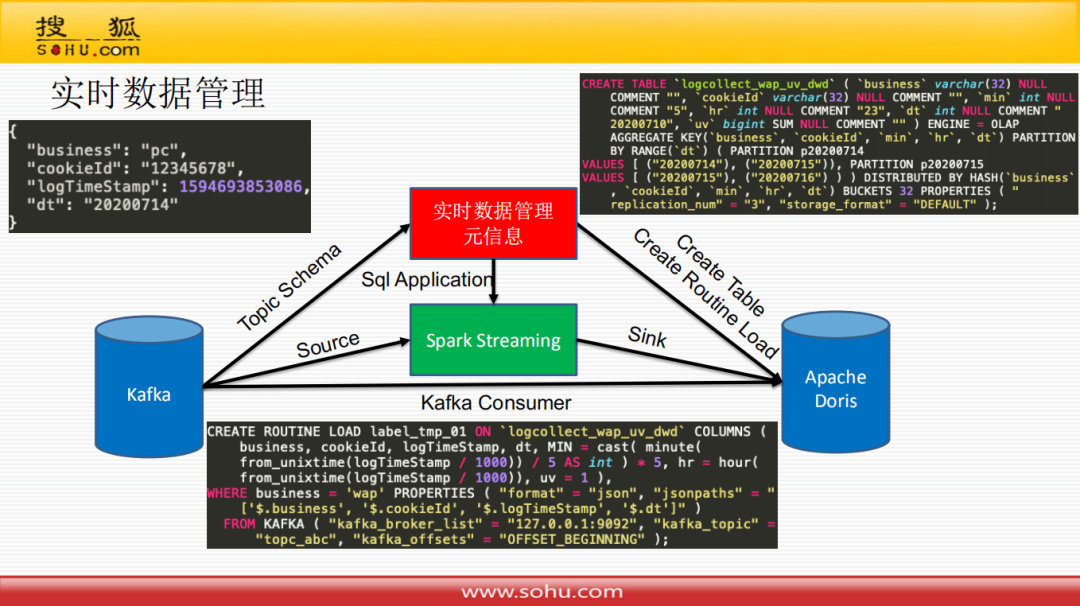
实时数据管理比较简单一点,表没有很分散,不需要Workflow方式执行;只需要把Kafka的Topic抽象成一张表,然后在Apache Doris里面再建一张表,将两边字段映射起来,然后下发一个任务,任务方式有两种:一种是写个Sql下发到Spark Streaming导入到Apache Doris里面;另一种是创建一个Doris的Routine Load任务,这里面主要是看Doris的使用,提供代码支持解析这种Json格式数据,只需要先在Doris里面先创建一张表,然后创建一个Routine Load任务从Kafka中消费Json格式数据直接处理映射到表中。
简单总结下:我们在做整个项目时的思想是产品化、服务化,可以方便业务对接。在做技术实践时,选择可靠的开源产品和开源代码,并借鉴可靠的业务解决方案,可以帮助我们快速实践应用。