
Python入门系列34 - 推导式与生成器
Python入门系列34

推导式与生成器
本篇阅读时间约为 6 分钟。
1
前言
从本篇开始,进入 Python 的技巧篇,介绍下编程时比较 pythonic 的写法,有些写法会非常简洁,比如本文要介绍的推导式。
推导式在各大教程中最常见的是列表推导式,但实际上不仅仅是列表可以进行推导,集合、字典都有着自己相应的推导式。当然,像廖雪峰老师写的教程中,对应的叫法是列表生成式,下面让我们来一一看下。
2
案例需求
老规矩,依然先给出一个案例的场景,通过此场景来介绍代码的编写与实现思路。
案例场景:
现有一个 list ,其中包含着一堆数字,比如 1- 10。若需要将其中的每个数字都进行平方操作,最终放回 list。此段程序如何编写呢?
简单思考一下,看过入门系列之前案例的童鞋们,在没学习列表推导式之前。肯定能想到两种方法。
1. 用 for 循环遍历每个元素节点,在 for 循环中进行平方操作,最后在放回到原有 list 中。
2. 使用 Python 内置函数 map 来实现,第一个参数传入一段计算平方的逻辑函数,第二个参数传入原有包含 1-10 的 list 即可。
1 和 2 的实现思路有了,代码就不在书写了,忘记的同学可以去翻看下高阶函数的那篇文章。
下面介绍下,如何使用列表推导式来完成上述需求。
3
列表推导式
代码实现如下:
# 定义一个包含 1-10 的 list
list_a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 实现列表表达式,用新的 list 接收下,看的明确一些
list_b = [i*i for i in list_a]
print(list_b)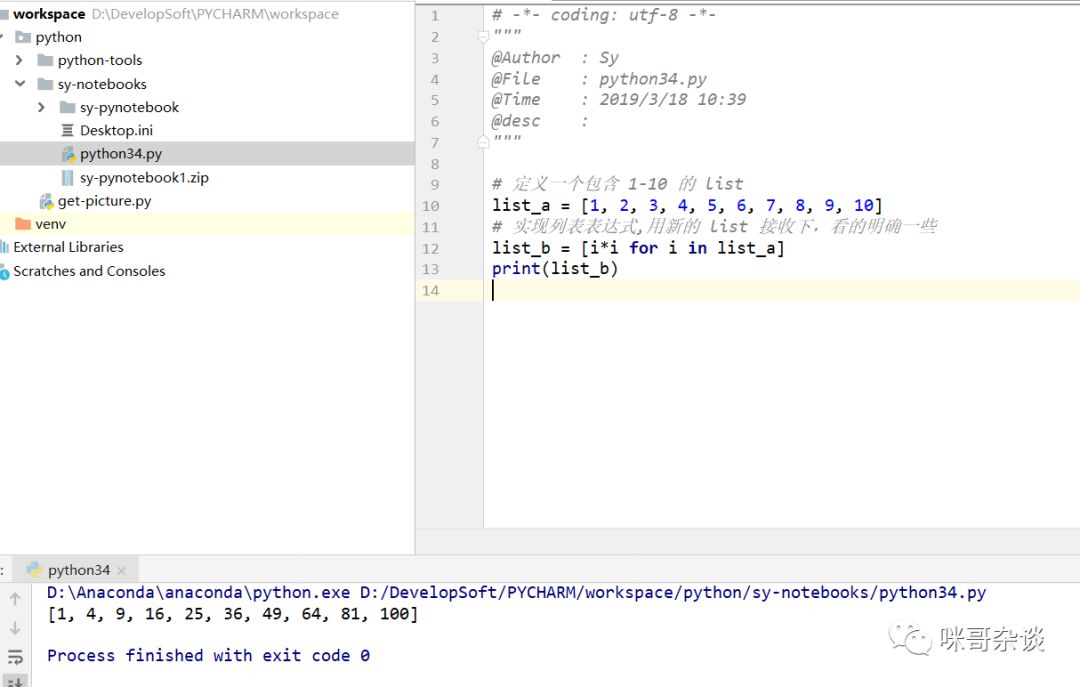
实际上,说起列表推导式,此处介绍的也只能是 Python 实现的语法而已,Python 解释器看到此写法的语法,会将其进行相应的语法解析。解释一下,上述代码中的列表推导式写法。
既然叫列表推导式,所以 list_b 的定义使用定义 list 的 [] 进行定义。在 [] 中的内容,可以使用表达式来书写,依然使用 for 进行对原列表遍历,与普通的 for 循环不同的是,简单计算逻辑,可以直接使用遍历出来的变量放在 for 关键词的前面进行逻辑处理。
[i*i for i in list_a] # 列表推导式如果说列表推导式中书写的是简单的表达式,那么自然也可以进行一些逻辑判断。
假设只想让原列表中的偶数进行平方计算的逻辑,可以修改代码如下:
# 定义一个包含 1-10 的 list
list_a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 实现列表表达式,用新的 list 接收下,看的明确一些
list_b = [i * i for i in list_a if i % 2 == 0]
print(list_b)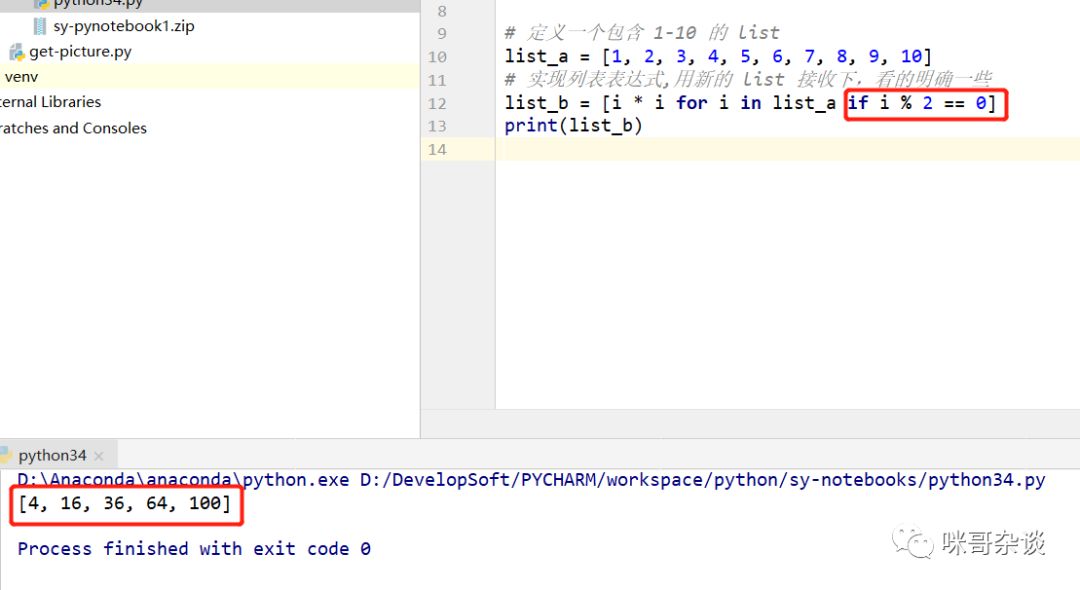
语法上来讲只需继续在 for 循环后面加上判断逻辑即可。
4
集合推导式
集合推导式,与列表推导式类似,既然叫集合推导式,那么最终要的结果必然是以集合形式的语法写出来的,所以只需要将我们上面推导式地方的代码,由 list 改为 set 即可。
# 定义一个包含 1-10 的 list
list_a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 实现集合表达式,用新的变量接收下,看的明确一些
b = {i * i for i in list_a if i % 2 == 0}
print(type(b))
print(b)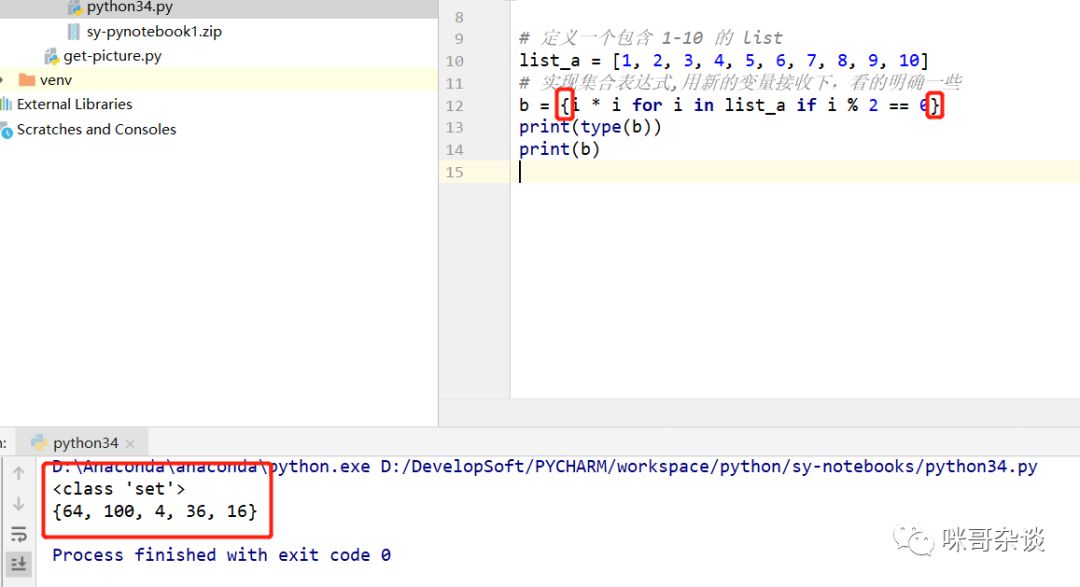
集合推导式,修改了定义集合语法的位置,使用 {} 定义,打印结果变成了 set 。类型也是 set。
5
字典推导式
字典推导式与前面介绍的两种有些区别,因为字典是两个值,key 与 value,所以在写法上,不能仅仅改变定义,还需要借助字典本身的方法才能实现字典推导式,先看错误的写法,如下:
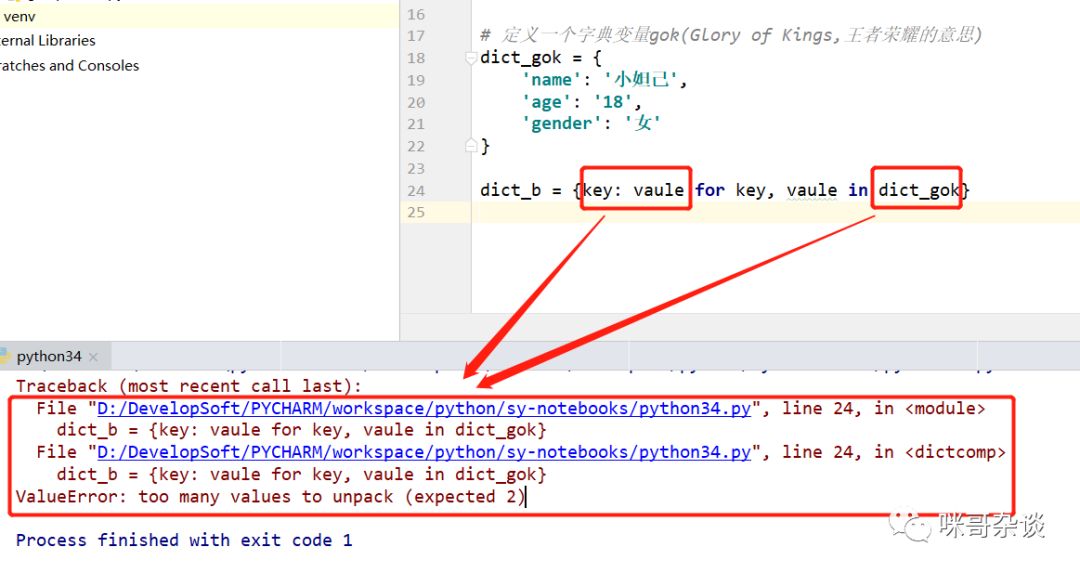
执行一下,提示错误,解包的时候有太多值了。
正确的写法:
# 定义一个字典变量gok(Glory of Kings,王者荣耀的意思)
dict_gok = {
'name': '小妲己',
'age': '18',
'gender': '女'
}
dict_b = {key: vaule for key, vaule in dict_gok.items()}
print(dict_b)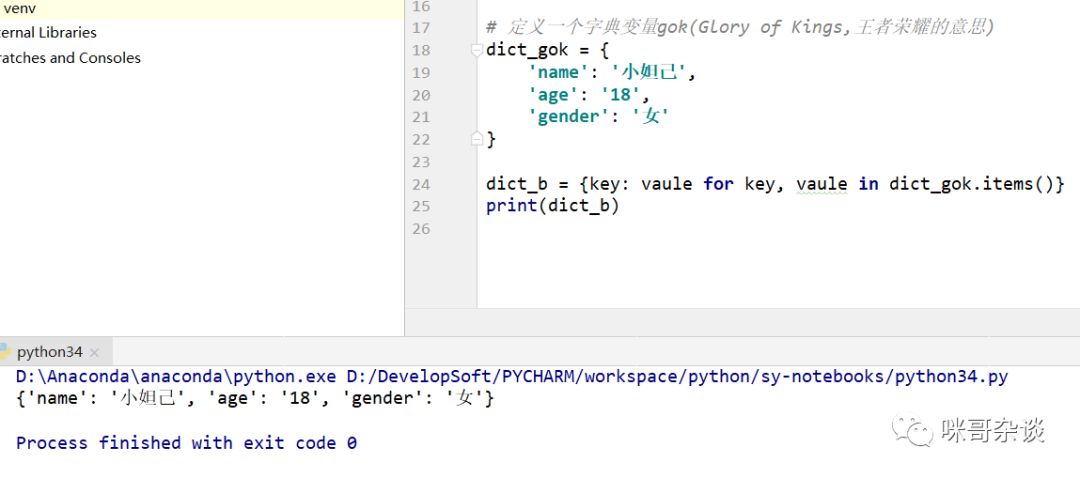
正确的写法是字典调用 items方法,将 key - value 取出使用。
小技巧,通过取出时交换 key - value 位置,得到的字典值也相反:
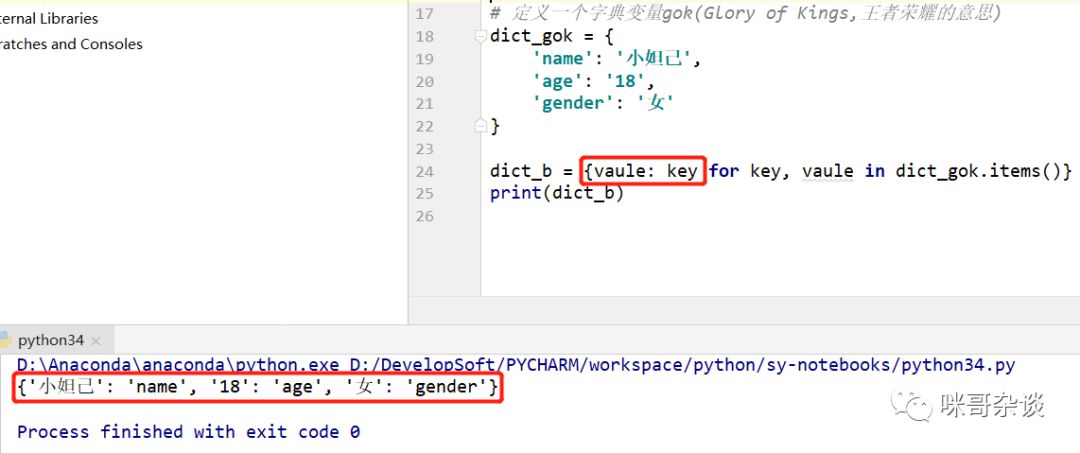
6
生成器generator
你一定会奇怪,为什么没有元组推导式?那么我们来试试,若按照上面的逻辑来一次元组推导式的写法会怎么样呢?
# 定义一个包含 1-10 的 list
list_a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 实现集合表达式,用新的变量接收下,看的明确一些
b = (i * i for i in list_a if i % 2 == 0)
print(type(b))
print(b)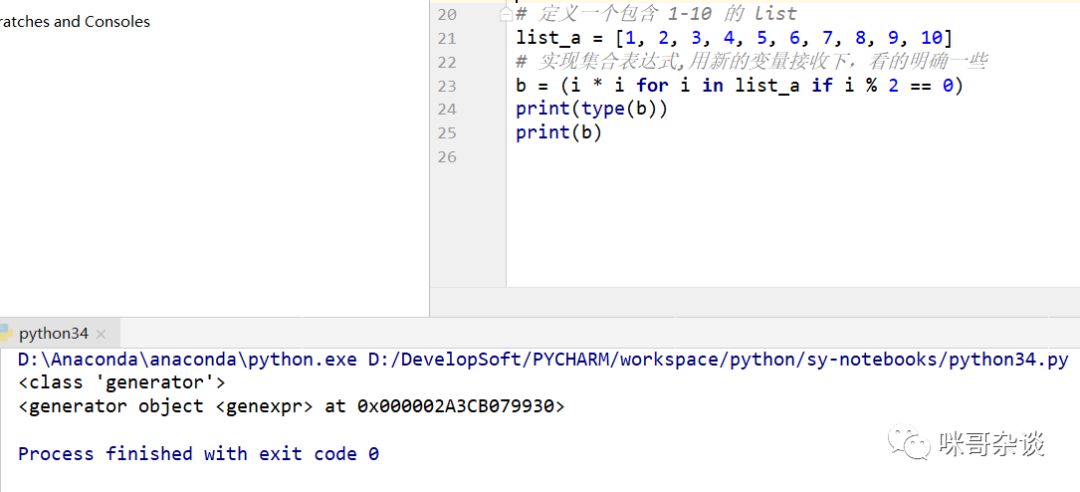
可以发现,使用“元组定义推导式”,生成出来的是一个 generator 的类型。对于 generator 的使用方法有两种,一种是直接调用 next 方法,还有一种通过 for 循环遍历使用,推荐使用 for 循环。
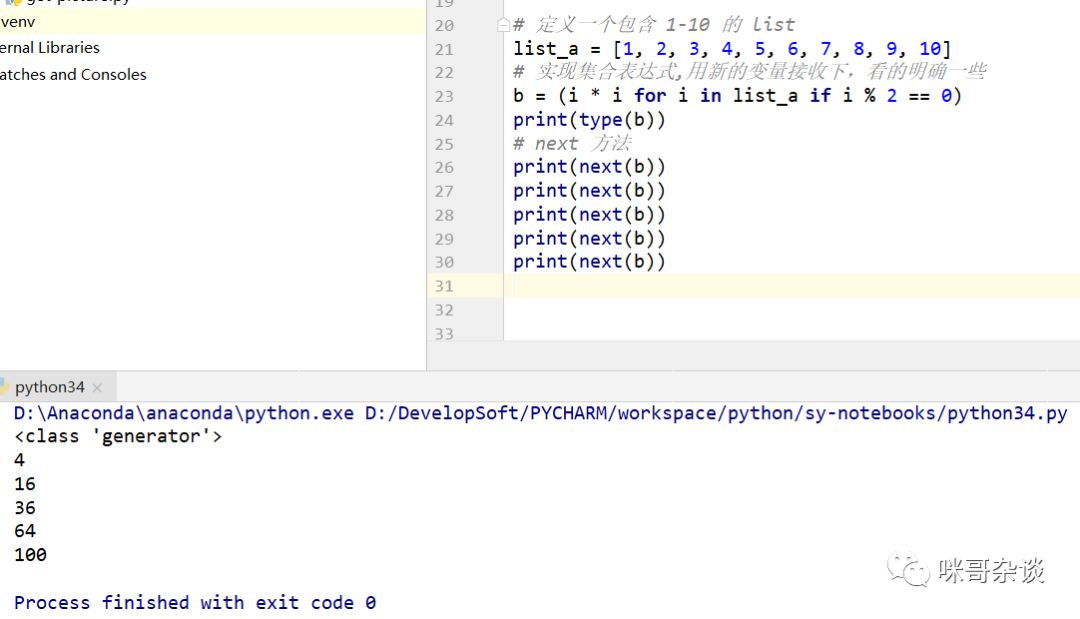
此种方式调用非得累死,generator 保存的是算法,每次调用 next ,就计算出下一个元素的值,直到计算到最后一个元素,没有更多的元素时,还会主动抛出 StopIteration 的错误。
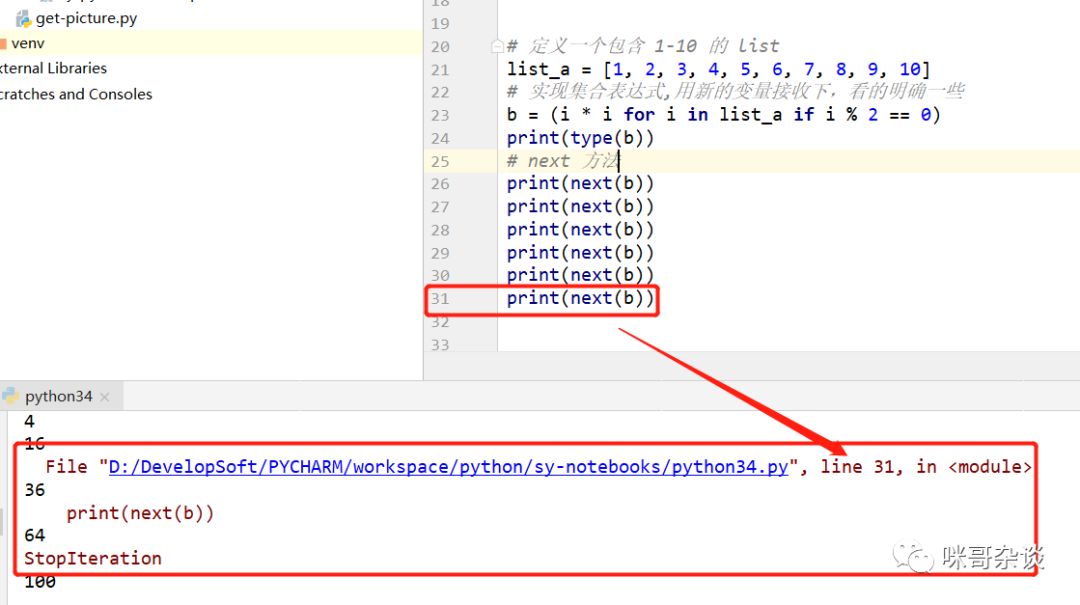
所以说,还是 for 循环最省事:
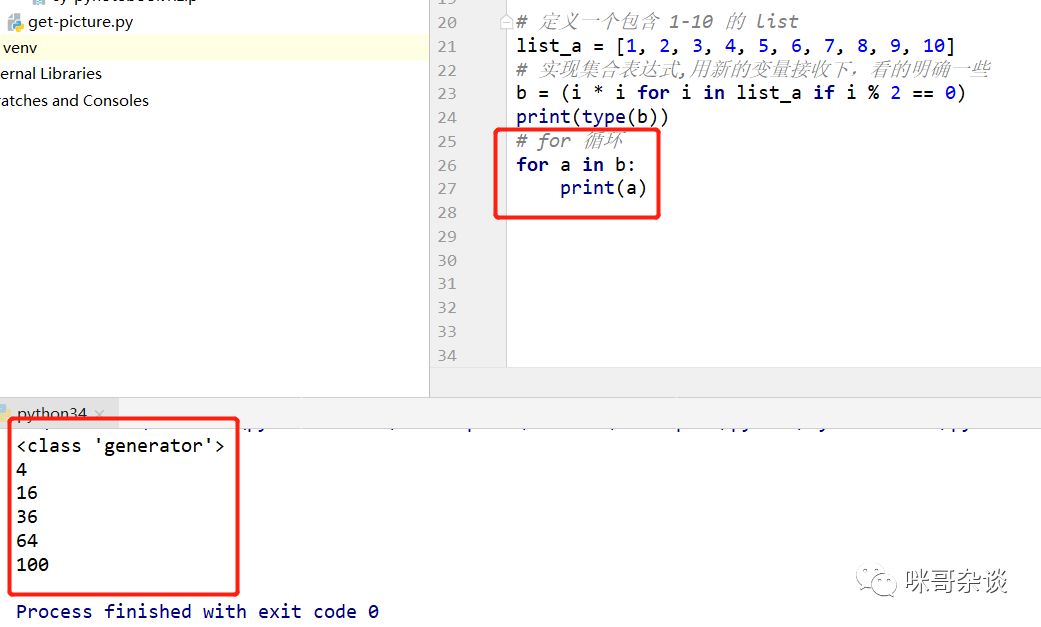
7
生成器的优点
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
廖雪峰的官方网站 - 生成器
在廖雪峰老师官方网站(自行百度查看即可) - 生成器的定义处,其实就很清楚的说明了生成器与列表推导式最大的区别,这里笔者直接引用过来了,而生成器最大的优点就是节省内存,不会因为数据庞大而导致内存溢出。
当然说到生成器,并不仅仅有上面的写法可以写出生成器。在函数中,通过 yield 关键字来代替 return 关键词,也可以生成对应的 generator 生成器。
def test():
for i in range(5):
print('before yield i')
yield i
print('after yield i')
a = test()
print(type(a))
for i in a:
print(i)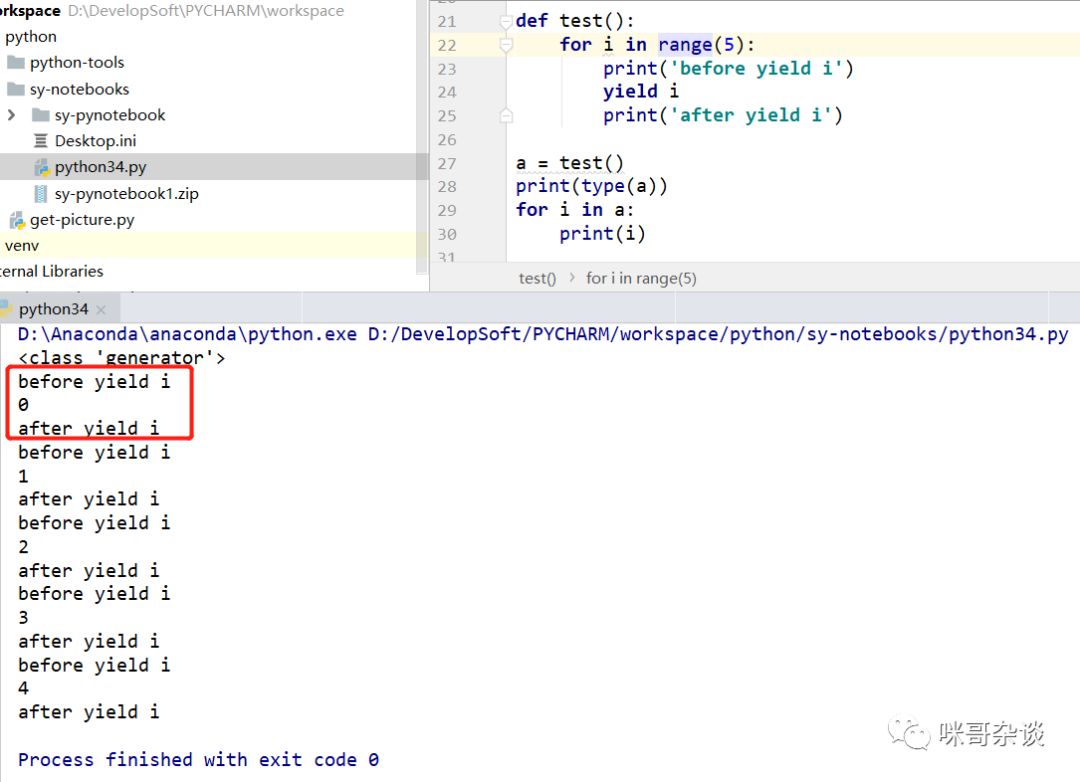
与return不同,虽然 yield 会将当前值先返回调用处,但依然会执行 yield 后的逻辑,可以看到上面的案例中,返回了 i 后,依然打印了“after yield i”。
8
总结
列表生成器在编写代码时,用得好可以大大简洁代码,而生成器有助于大数据遍历时的操作。
笔者早期刚写代码时,就遇到了大数据读取到内存的问题,那时也是初学 Python ,对于生成器的了解还不是那么深刻,所以没有利用上,依然清晰地记着项目第一版的代码,就是暴力的将 3~4 GB 文件内容直接读到内存中,最后程序跑着跑着就内存溢出了,直接导致程序自己死掉了。
如果当时利用好生成器,想必后来也不用那么麻烦的使用“分而治之”的思想去处理文件了。所以当遇到大数据时,不妨利用生成器试试,尤其是 yield 关键词,使用得当会省去不少麻烦呢!
至此完!
