
基于深度学习的花卉图像关键点检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在本文中,我们描述了我们如何使用卷积神经网络 (CNN) 来估计花卉图像中关键点的位置,并且在 3D 模型上渲染这些图像上茎和花的位置等关键点。
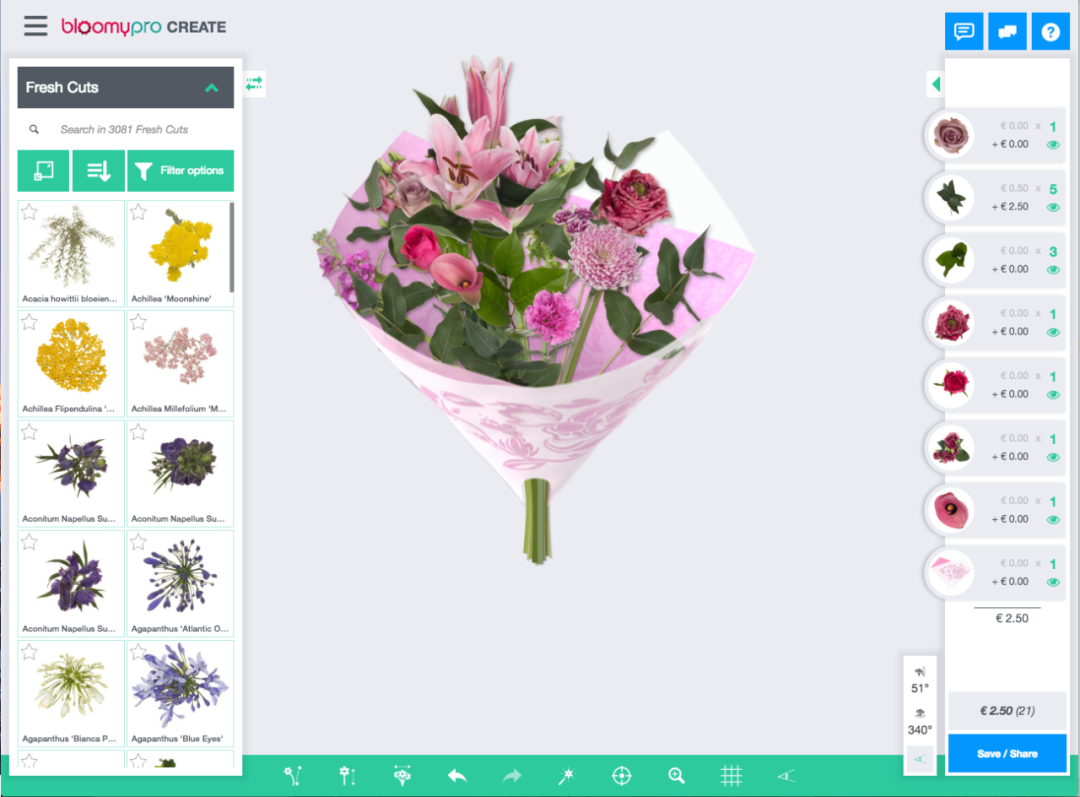
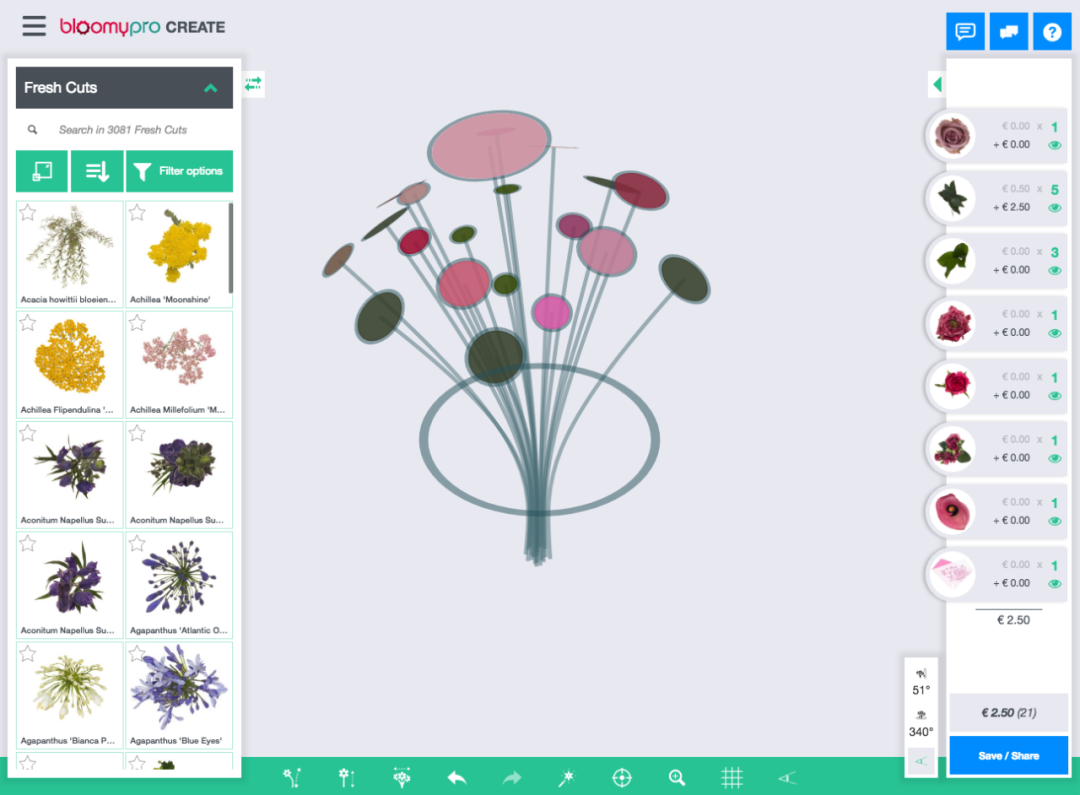

在数据集中,成千上万的图像已经手动标注了关键点,所以我们有大量的训练数据可以使用。

以上是训练数据集中的一些带注释的花,它从几个不同的角度展示了同一朵花。茎位置为蓝色,花顶部位置为绿色。在一些图片中,茎的起源被花本身隐藏了。在这种情况下,我们需要“有根据的猜测”最有可能在哪里。

因为模型必须输出一个数字而不是一个类,所以我们实际上是在做回归。CNN 以分类任务而闻名,但在回归方面也表现良好。例如,DensePose使用基于 CNN 的方法进行人体姿势估计。
网络从几个标准卷积块开始。这些块由3个卷积层组成,然后是最大池、批量标准化层和退出层。
所述卷积层含有多个滤波器。每个过滤器就像一个模式识别器。下一个卷积块有更多的过滤器,所以它可以在模式中找到模式。
最大池化会降低图像的分辨率。这限制了模型中的参数数量。通常,对于图像分类,我们对某个对象在图像中的位置不感兴趣,只要它在那里即可。在我们的例子中,我们对位置感兴趣。尽管如此,拥有几个最大池化层并不会影响性能。
批量标准化层有助于模型更快地训练(收敛)。在一些深度网络中,没有它们,训练完全失败。
退出层将随机禁用节点,这将防止过度拟合模型。
在卷积块之后,我们将张量展平,使其与密集层兼容。全局最大池化或平均最大池化也将实现平坦张量,但会丢失所有空间信息。扁平化在我们的实验中效果更好,尽管它的(计算)成本是拥有更多模型参数导致更长的训练时间。
在两个带有Relu激活的密集隐藏层之后是输出层,我们想要预测2 个关键点的x和y坐标,所以我们需要在输出层有 4 个节点。图像可以有不同的分辨率,因此我们将坐标缩放到 0 到 1 之间,并在使用前将它们放大。输出层没有激活函数。即使目标变量在 0 和 1 之间,这对我们来说也比使用sigmoid效果更好。作为参考,以下是我们使用的 Python 深度学习库Keras的完整模型摘要:
_________________________________________________________________Layer (type) Output Shape Param #=================================================================conv2d_1 (Conv2D) (None, 126, 126, 64) 2368_________________________________________________________________conv2d_2 (Conv2D) (None, 124, 124, 64) 36928_________________________________________________________________conv2d_3 (Conv2D) (None, 122, 122, 64) 36928_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 61, 61, 64) 0_________________________________________________________________batch_normalization_1 (Batch (None, 61, 61, 64) 256_________________________________________________________________dropout_1 (Dropout) (None, 61, 61, 64) 0_________________________________________________________________conv2d_4 (Conv2D) (None, 59, 59, 128) 73856_________________________________________________________________conv2d_5 (Conv2D) (None, 57, 57, 128) 147584_________________________________________________________________conv2d_6 (Conv2D) (None, 55, 55, 128) 147584_________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 27, 27, 128) 0_________________________________________________________________batch_normalization_2 (Batch (None, 27, 27, 128) 512_________________________________________________________________dropout_2 (Dropout) (None, 27, 27, 128) 0_________________________________________________________________flatten_1 (Flatten) (None, 93312) 0_________________________________________________________________dense_1 (Dense) (None, 256) 23888128_________________________________________________________________batch_normalization_3 (Batch (None, 256) 1024_________________________________________________________________dropout_3 (Dropout) (None, 256) 0_________________________________________________________________dense_2 (Dense) (None, 256) 65792_________________________________________________________________batch_normalization_4 (Batch (None, 256) 1024_________________________________________________________________dropout_4 (Dropout) (None, 256) 0_________________________________________________________________dense_3 (Dense) (None, 4) 1028=================================================================Total params: 24,403,012Trainable params: 24,401,604Non-trainable params: 1,408_________________________________________________________________
你们可能会问:为什么是 3 个卷积层?或者为什么是 2 个卷积块?我们在超参数搜索中将这些数字作为超参数包括在内。连同诸如密集层数、退出层、批量标准化和卷积滤波器数量之类的参数,我们进行了随机搜索以找到超参数的最佳组合。
对于训练,我们使用学习率为的Adam 优化器0.005。当验证损失在几个时期内没有改善时,学习率会自动降低。作为损失函数,我们使用均方误差 (MSE)。因此,大错误比小错误受到的惩罚相对更多。
这些是训练 50 个时期后的损失(误差)图:
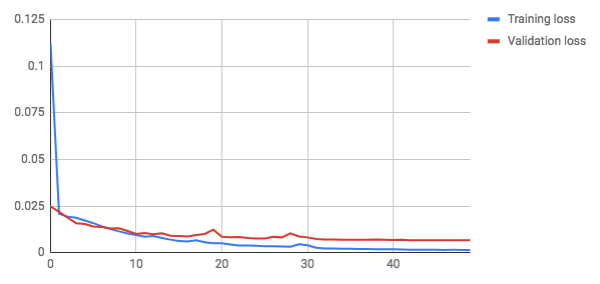
大约 8 个 epoch 后,验证损失变得高于训练损失。直到训练结束,验证损失仍然减少,因此我们没有看到模型严重过度拟合的迹象。测试集上的最终损失 (MSE) 为0.0064. MSE 的解释可能非常不直观。
MAE 是——这意味着预测平均降低 1.7%
白色圆圈包含目标关键点,实心圆圈包含我们的预测。在大多数情况下,它们非常接近(重叠)。

我们有一些改进的想法,但我们还没有时间实施:
目前,单个模型正在估计两个关键点。为每个关键点训练一个特定的模型可能会更好。这还有一个额外的好处,可以稍后添加新的关键点,而无需重新训练完整的模型。
另一个想法是考虑照片的角度。例如,将其添加为密集层的输入,可能会争辩说,角度会改变任务的性质,因此提供此信息可能有助于网络。按照这种思路,为每个角度训练一个单独的网络也可能是有益的。
通过这项研究,我们证明了使用 CNN 检测花卉图像中的关键点的可行性。所使用的方法也可能适用于其他领域的后处理任务,例如产品摄影。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~