
用 Scrapy 爬取 5 秒盾站点,结果万万没想到,速度可以这么快!
阅读本文大概需要 12 分钟。
立即加星标

每月看好文

一、前言介绍
大家好,我是 TheWeiJun。我怀揣着对技术的热爱,迫不及待要与大家分享一场关于 Scrapy 爬虫的技术奇遇。在这个数字化飞速发展的时代,我们时刻面临新的技术挑战。在今天的故事中,我将引领大家穿越 Scrapy 的技术迷雾,通过 twisted 源码改造,实现高并发爬取,成功攻克五秒盾站点的技术难关。
如果你对技术探险充满好奇,渴望突破技术的边界,不妨关注我的公众号。在这里,我们将一同探索未知领域,共同启程,为 2024 年的技术征途揭开崭新的篇章!记得点关注,一同踏上这场技术冒险之旅吧!
二、实战分析
1. 首先,我们需要寻找一个使用了 CloudFlare 的网站。然后,创建一个 Scrapy 项目,并编写以下 Spider 代码:
# -*- coding: utf-8 -*-from urllib.parse import urlencodeimport scrapyclass CloudflareSpider(scrapy.Spider):name = 'cloudflare_spider'def __init__(self):super().__init__()self.headers = {'authority': 'xxxxx','accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8','cache-control': 'no-cache','pragma': 'no-cache','referer': 'https://xxxxx/feed','sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"macOS"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',}self.url = 'https://xxxx/xxx/xxx/'def start_requests(self):for page in range(1, 100):params = {'page': page,'posts_to_load': '5','sort': 'top',}proxies = {"http": "http://127.0.0.1:59292","https": "http://127.0.0.1:59292",}full_url = self.url + '?' + urlencode(params)yield scrapy.Request(url=full_url,headers=self.headers,callback=self.parse,dont_filter=True,meta={"proxies": proxies})def parse(self, response, **kwargs):print(response.text)
2. 代码编写完成后,让我们一起来查看整个 Scrapy 项目的结构。以下是项目目录结构的截图:

3. 接着,我们编写 run_spider.py 文件,并在其中注册我们想要启动的 Spider(使用 spider_name 变量)以下是代码示例:
from scrapy.crawler import CrawlerProcessfrom scrapy.utils.project import get_project_settingsdef run_spider():process = CrawlerProcess(get_project_settings())process.crawl('cloudflare_spider')process.start()if __name__ == "__main__":run_spider()
4. 通过 run_spider.py 模块运行爬虫,可以看到 403 状态码错误请求,截图如下:
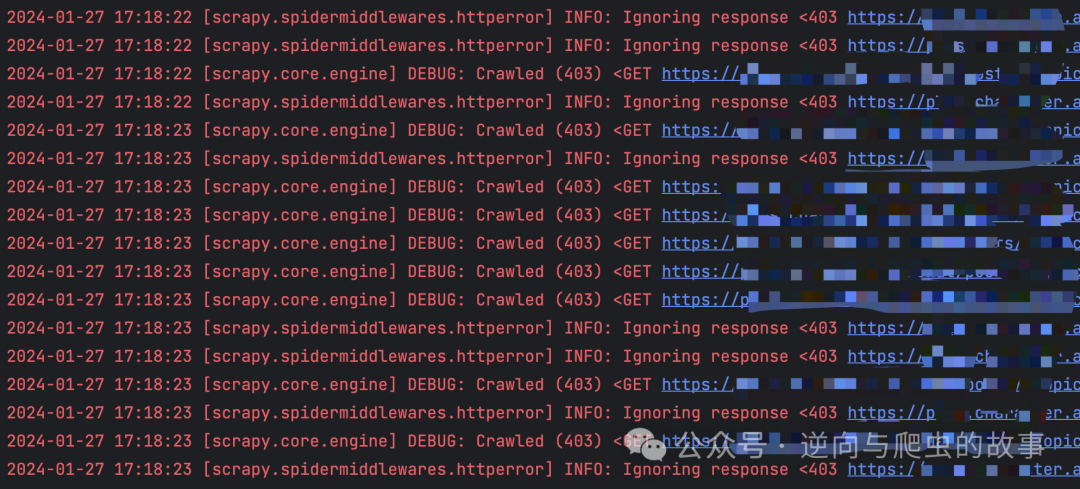
5. 此时,Scrapy的parse 解析函数可能无法获取到失败的 response,因为 Scrapy 默认只处理状态码在 200 范围内的请求。为了能够查阅失败的请求结果,我们需要设置允许通过的状态码参数。以下是相应的代码设置:
HTTPERROR_ALLOWED_CODES = [403]
6. 接下来讲解一下为什么要这么设置? 我们打开 scrapy 源码,截图如下:

7. 在 spidermiddlewares 中间件中,我们可以观察到 HttpErrorMiddleware 模块。当 Scrapy 启动时,各个模块会被注册到 spidermiddlewares 中间件。现在让我们深入了解它是如何运行的,以下是相关代码截图:
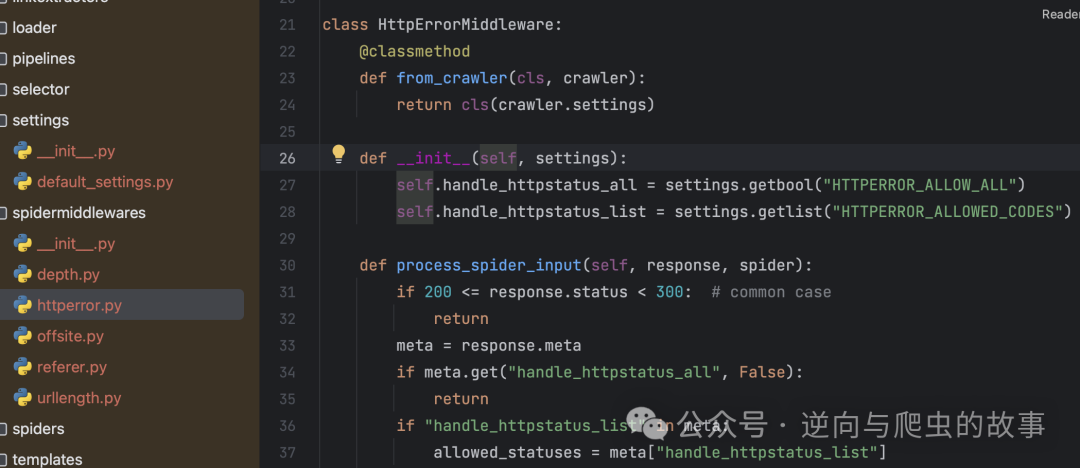
总结:观察上述代码,我们可以注意到 Scrapy 的作者默认会过滤掉状态码在 200 以内的请求,因为在作者看来,以 200 开头的请求都是成功的。然而,如果我们想要自定义允许通过的请求状态码,就需要设置 HTTPERROR_ALLOWED_CODES。
8. 我们知道 spider 中间件原理并设置 403 状态码后,重新运行代码,截图如下:
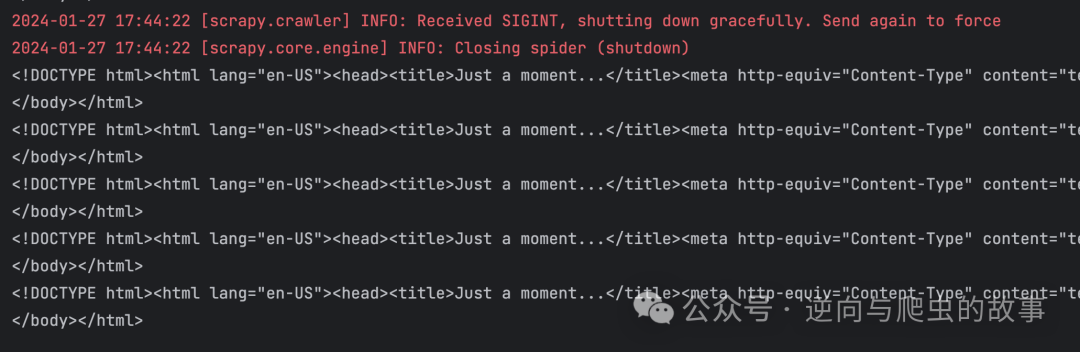
总结:这张页面截图对于那些已经接触过 5 秒盾的 Spider 开发者来说应该不陌生。接下来,我们将使用 tls_client 包来绕过 5 秒盾机制。
9.此外,大家应该都使用过 download middlewares 中间件。下面我们将在下载器中间件中处理 5 秒盾请求,相关代码如下:
from scrapy.http import HtmlResponsefrom tls_client import Sessionclass DownloaderMiddleware(object):def __init__(self):: Session = Session(client_identifier="chrome_104")def process_request(self, request, spider):proxies = request.meta.get("proxies") or Noneheaders = request.headers.to_unicode_dict()if request.method == "GET":response = self.session.get(url=request.url,headers=headers,proxy=proxies,timeout_seconds=60,)else:response = self.session.post(url=request.url,headers=headers,proxy=proxies,timeout_seconds=60,)return HtmlResponse(url=request.url,status=response.status_code,body=response.content,encoding="utf-8",request=request,)
10. 将上面的模块注册到下载器中间件后,我们启动爬虫观察请求结果,截图如下所示:
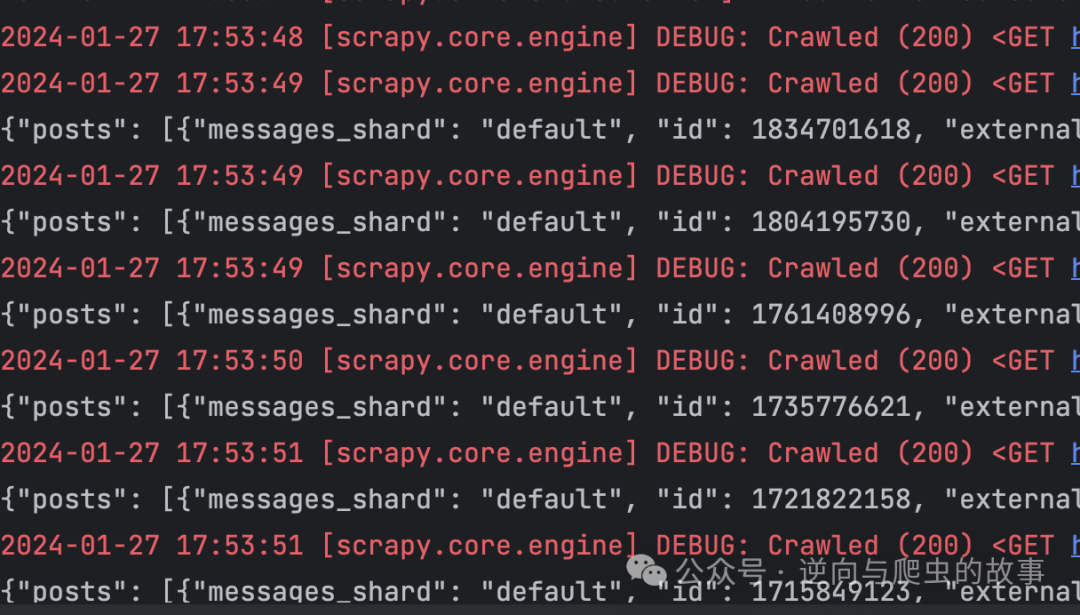
总结:尽管 5 秒盾已经能够成功解决并返回结果,我们却发现 Scrapy 并没有充分发挥 Twisted 的异步机制。这是因为我们在下载器中间件中处理请求时,实际上是在同步的环境下运行的。如果我们希望 Scrapy 能够实现高并发,就必须修改 Twisted 的请求模块。我们可以通过重写 Twisted 请求组件或者兼容 tls_client 模块来实现高并发。在这里,我们选择后者的方式,以达到 Scrapy 高并发的目标。接下来,我们将进入源码重写的环节。
三、源码重写
1. 首先,我们来了解一下 Scrapy 的运行机制,然后找到相应的模块,并查看 Scrapy 源码的实现。以下是相应的截图:
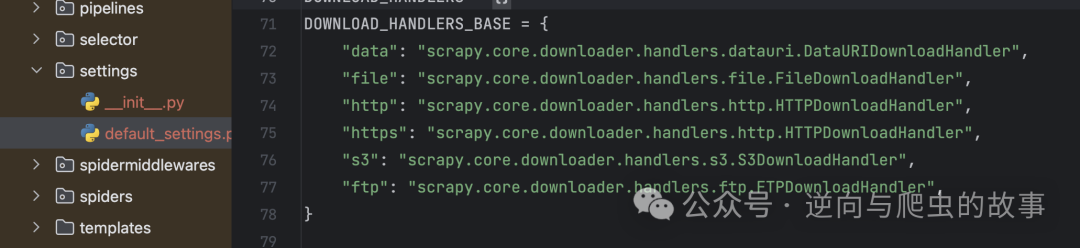

总结:在 Scrapy 启动时,它通过 downloader_handlers 中的 download_request 方法加载 Twisted 模块,从而进行请求的异步处理。一旦我们获得了灵感,就可以开始继承并重写 Scrapy 的源码。
2. 我们继承重写 downloader hanlders 中的模块,重写后源码如下:
"""Download handlers for http and https schemes"""import loggingfrom time import timefrom urllib.parse import urldefragfrom tls_client import Sessionfrom twisted.internet import threadsfrom twisted.internet.error import TimeoutErrorfrom scrapy.http import HtmlResponsefrom scrapy.core.downloader.handlers.http11 import HTTP11DownloadHandlerlogger = logging.getLogger(__name__)class CloudFlareDownloadHandler(HTTP11DownloadHandler):def __init__(self, settings, crawler=None):super().__init__(settings, crawler)self.session: Session = Session(client_identifier="chrome_104")def from_crawler(cls, crawler):return cls(crawler.settings, crawler)def download_request(self, request, spider):from twisted.internet import reactortimeout = request.meta.get("download_timeout") or 10# request detailsurl = urldefrag(request.url)[0]start_time = time()# Embedding the provided code asynchronouslyd = threads.deferToThread(self._async_download, request)# set download latencyd.addCallback(self._cb_latency, request, start_time)# check download timeoutself._timeout_cl = reactor.callLater(timeout, d.cancel)d.addBoth(self._cb_timeout, url, timeout)return ddef _async_download(self, request):timeout = int(request.meta.get("download_timeout"))proxies = request.meta.get("proxies") or Noneheaders = request.headers.to_unicode_dict()if request.method == "GET":response = self.session.get(url=request.url,headers=headers,proxy=proxies,timeout_seconds=timeout,)else:response = self.session.post(url=request.url,headers=headers,proxy=proxies,timeout_seconds=timeout,)return HtmlResponse(url=request.url,status=response.status_code,body=response.content,encoding="utf-8",request=request,)def _cb_timeout(self, result, url, timeout):if self._timeout_cl.active():self._timeout_cl.cancel()return resultraise TimeoutError(f"Getting {url} took longer than {timeout} seconds.")def _cb_latency(self, result, request, start_time):request.meta["download_latency"] = time() - start_timereturn result
总结:源码重写工作已经圆满完成,此时我们迫不及待地期待着 Scrapy 在高并发环境下的表现。怀揣这个疑问,让我们迅速进入性能对比环节。在进行最后的步骤时,请确保将重写的代码注册到 DOWNLOAD_HANDLERS 中间件模块。
四、性能对比
为了进行性能对比,我们按照以下规则进行测试:
执行 100 个请求的情况下使用下载器中间件方案。
执行 100 个请求的情况下使用 Twisted 源码重写方案。
执行 500 个请求的情况下使用下载器中间件方案。
执行 500 个请求的情况下使用 Twisted 源码重写方案。
1. 阅读完对比流程后,我们先执行下载器中间件方案,scrapy 输出日志如下:

2. 接着,在相同的环境中,执行源码重写方案,Scrapy 输出的日志如下:
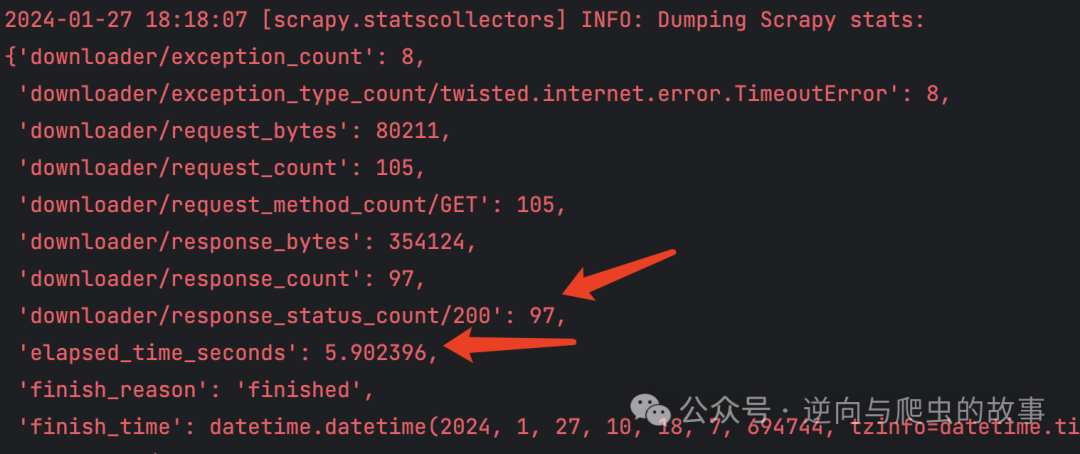
总结:通过对比两张截图的 elapsed_time_seconds 字段,明显可以观察到 Scrapy Twisted 源码重写方案在执行 100 次请求时,爬取速度提升了 6 倍。为了确保性能对比的权威性,接下来我们将分别执行 500 次请求。
3. 在执行 500 次请求时,仍然首先采用下载器中间件方案,Scrapy 输出的日志如下:

4. 紧接着,我们执行 500 次请求,采用 twisted 源码重写方案,Scrapy 输出的日志如下:
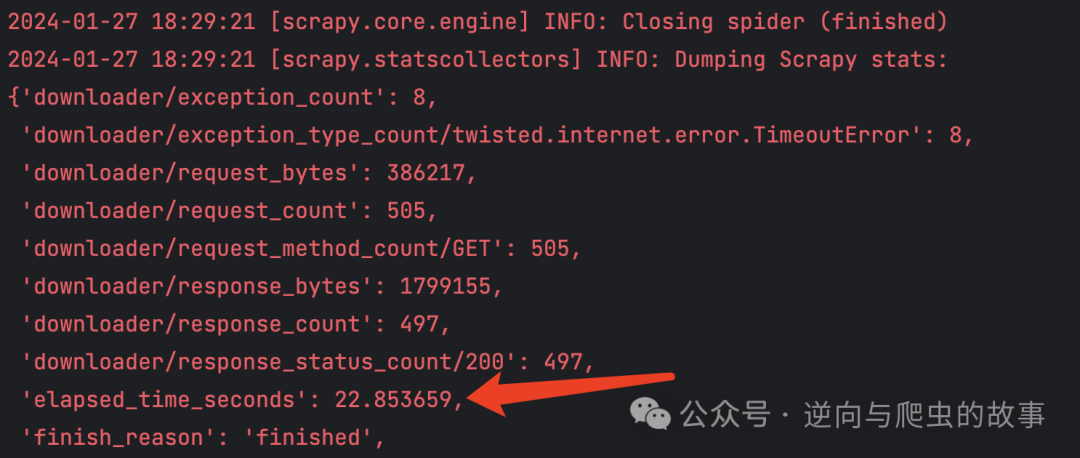
总结:通过比较 500 次请求的两张截图,我们可以观察到,在 elapsed_time_seconds 方面,Scrapy Twisted 源码重写方案明显优于下载器中间件方案。在同时执行 500 次请求的情况下,爬取速度提升约为 9 倍。基于这个结果,我相信在请求量足够大的场景下,采用 Scrapy Twisted 源码重写方案能够显著提升爬取效率。
建了一个免费的知识星球,扫码入即可。
点个在看你最好看