
短链接的设计与实现
前言
短链接的实现在生活中比较常见,比如我们接受到的广告短信,短信会包含他们的活动链接。
这个链接是进行压缩过的,比较短。这样既美观也能满足字数的限制,比如短信中某个字段需要在多少字符以内。

短链跳转的基本原理
用户访问短链地址然后重定向到原来的地址。
在HTTP协议中,30X状态代表的是重定向的状态。其中可以是301 也可以是302。
301 代表永久重定向。对于GET请求, 301跳转会默认被浏览器cache。也就是说,用户第一次访问某个短链接后,如果服务器返回301状态码,则这个用户在后续多次访问同一短链接地址,浏览器会直接请求跳转地址,而不会再去短链接系统上取!
这么做优点很明显,降低了服务器压力,但是无法统计到短链接地址的点击次数。
302代表临时重定向。对于GET请求, 302跳转默认不会被浏览器缓存,除非在HTTP响应中通过 Cache-Control 或 Expires 暗示浏览器缓存。因此,用户每次访问同一短链接地址,浏览器都会去短链接系统上取。
这么做的优点是,能够统计到短地址被点击的次数了。但是服务器的压力变大了。

1. 生成策略
如果用 62 个字符 [A-Z, a-z, 0-9][A−Z,a−z,0−9] 来代表一位的话(62进制)。那么我们设计长度为 n 的短链接,则可以包含会有 62^n 个链接。当然也可以添加别的字符,让进制数变得更大,要注意特殊符号。
我们可以将自增主键的值(十进制的ID)来计算得到短链字符(62进制的字符)。然后可以用一个全局发号器来提供自增主键,这样编码生成的短链字符做成key,提供的url做value。
这样域名解析系统通过key 在表中找到value。value 和key之间靠主键关联,这样的方式别人也可以很容易的推导出来你的url(根据相应短链进行反推) 是具有规律性的。
private static final String BASE = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";public static String toBase62(long num) {StringBuilder sb = new StringBuilder();do {int i = (int) (num % 62);sb.append(BASE.charAt(i));num /= 62;} while (num > 0);return sb.reverse().toString();}
那么我们如何打乱呢,打乱的方式可以将短链的字母打乱,也可以在固定位置插入随机值。

2.全局发号器
其中全局发号器的自增主键可以涉及到分布式ID的生成。通过UUID的方式获取字符型 ID 的话,数据库占用空间大,索引效率比整型低。
分布式ID的生成:
利用数据库的自增ID 64位long类型
数据库自增ID的缺点是数据在插入前,无法获得ID。数据在插入后,获取的ID虽然是唯一的,但一定要等到事务提交后,ID才算是有效的。有些双向引用的数据,不得不插入后再做一次更新,比较麻烦
采用一个集中式ID生成器,它可以是Redis,也可以是ZooKeeper,也可以利用数据库的表记录最后分配的ID。
这种方式最大的缺点是复杂性太高,需要严重依赖第三方服务,而 且代码配置繁琐。一般来说,越是复杂的方案,越不可靠,并且测试越痛苦。
类似Twitter的Snowflake算法,它给每台机器分配一个唯一标识,然后通过时间戳+标识+自增实现全局唯一ID。
这种方式好处在于ID生成算法完全是一个无状态机,无网络调用,高效可靠。缺点是如果唯一标识有重复,会造成ID冲突。
利用数据库生成id一定要在用到的时候去生成 id 吗,是否可以提前生成这些自增 id ?设计一个专门的发号表,每插入一条记录,为短链 id 预留 (主键 id * 1000 - 999) 到 (主键 id * 1000) 的号段
发号表:url_sender_numid | gmt_create | tmp_start_num | tmp_end_num如图示:tmp_start_num 代表短链的起始 id,tmp_end_num 代表短链的终止 id。
当长链转短链的请求打到某台机器时,先看这台机器是否分配了短链号段,未分配就往发号表插入一条记录,则这台机器将为短链分配范围在 tmp_start_num 到 tmp_end_num 之间的 id。
从 tmp_start_num 开始分配,一直分配到 tmp_end_num,如果发号 id 达到了 tmp_end_num,说明这个区间段的 id 已经分配完了,则再往发号表插入一条记录就又获取了一个发号 id 区间。
画外音:思考一下这个自增短链 id 在机器上该怎么实现呢, 可以用 redis, 不过更简单的方案是用 AtomicLong,单机上性能不错,也保证了并发的安全性,当然如果并发量很大,AtomicLong 的表现就不太行了,可以考虑用 LongAdder,在高并发下表现更加优秀。流程如下图所示

这里有个需要注意的地方,我们可能需要防止多次相同的长链生成不同的短链 id 这种情况,这就需要每次先根据长链来查找 db 看是否存在相关记录,一般的做法是给长链加索引,但这样的话索引的空间会很大,所以我们可以对长链适当的压缩,比如 md5,再对长链的 md5 字段做索引,索引就会小很多。这样只要根据长链的 md5 去表里查是否存在相同的记录即可。
如何让各个机器分配的号段区间不重?
小结
以上做法为给要生成的链接分配一个分布式id,然后再生成62进制数。
以上为通过自增序列来区别各个断链的生成。还可以通过hash的方法来生成id。
3. 哈希算法
通过hash将原来的长链hash成一个序列数,然后再进行62进制转换。用到hash就要防止hash冲突,可通过数据库主键避免冲突,或者通过布隆过滤器优化判断是否存在冲突的逻辑。
数据库避免冲突方式可先查找是否有再进行插入,2 次数据库操作。对于这块的优化可通过DUPLICATE语句 优化成一次。
推荐 Google 出品的 MurmurHash 算法,MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。
与其它流行的哈希函数相比,对于规律性较强的 key,MurmurHash 的随机分布特征表现更良好。
非加密意味着着相比 MD5,SHA 这些函数它的性能肯定更高(实际上性能是 MD5 等加密算法的十倍以上),也正是由于它的这些优点,所以虽然它出现于 2008,但目前已经广泛应用到 Redis、MemCache、Cassandra、HBase、Lucene 等众多著名的软件中。
MurmurHash 提供了两种长度的哈希值,32 bit,128 bit,为了让网址尽可通地短,我们选择 32 bit 的哈希值,32 bit 能表示的最大值近 43 亿,对于中小型公司的业务而言绰绰有余。
比如对一个长链做 MurmurHash 计算,得到的哈希值为 3002604296,此时我们再将哈希值转换为62进制数。

4. 更高性能设计
在电商公司,经常有很多活动,秒杀,抢红包等等,在某个时间点的 QPS 会很高。
考虑到这种情况,我们引入了 openResty,它是一个基于 Nginx 与 Lua 的高性能 Web 平台。
由于 Nginx 的非阻塞 IO 模型,使用 openResty 可以轻松支持 100 w + 的并发数,一般情况下你只要部署一台即可,不过为了避免单点故障,两台为宜。
同时 openResty 也自带了缓存机制,集成了 redis 这些缓存模块,也可以直接连 mysql。不需要再通过业务层连这些中间件,性能自然会高不少
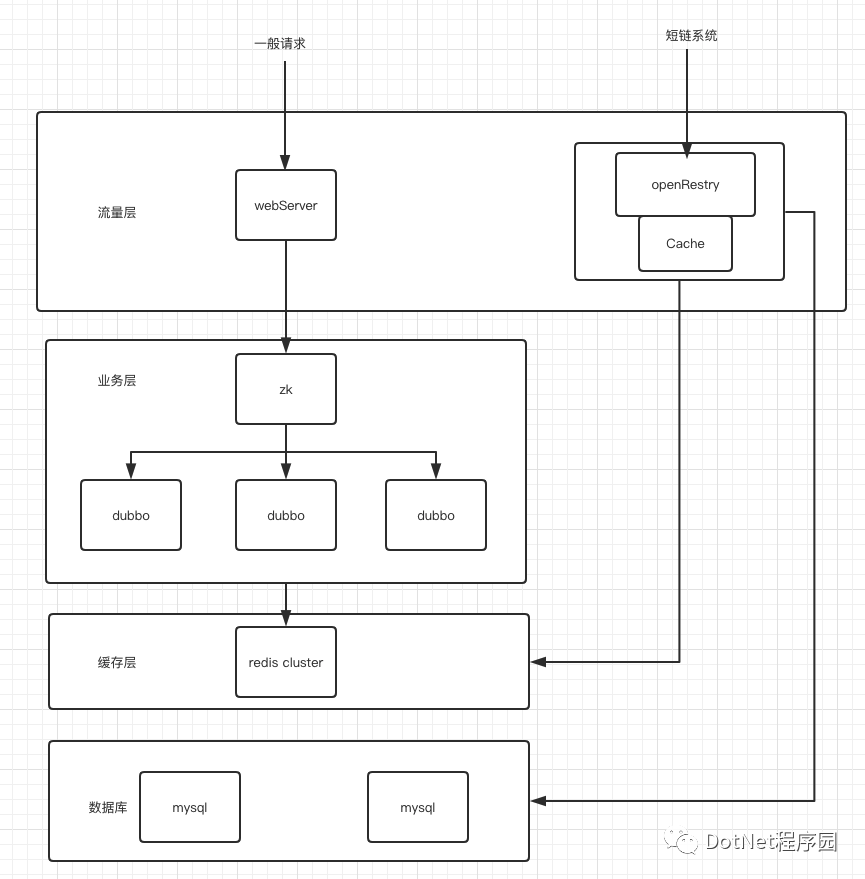
如图示,使用 openResty 省去了业务层这一步,直达缓存层与数据库层,也提升了不少性能。
最后
通常我们用分布式id + "62进制"就可以了,哈希的方法可作为拓展思路。
References
【原创】这可能是东半球最接地气的短链接系统设计liaoxuefeng.com/article/1280526512029729高性能短链设计
