
Netflix基于AWS架构体系
共 3215字,需浏览 7分钟
·
2022-04-10 18:05
Netflix是世界最大的收费视频网站,其整个架构体系都是搭建在AWS之上,可以看做是一个云原生架构。
同时相信大家都听过SpringCloud体系下的一大撮Netflix相关的微服务组件,而了解Netflix是如何使用这些组件,对于进一步掌握这些组件也很有必要。
先全局看下Netflix架构:
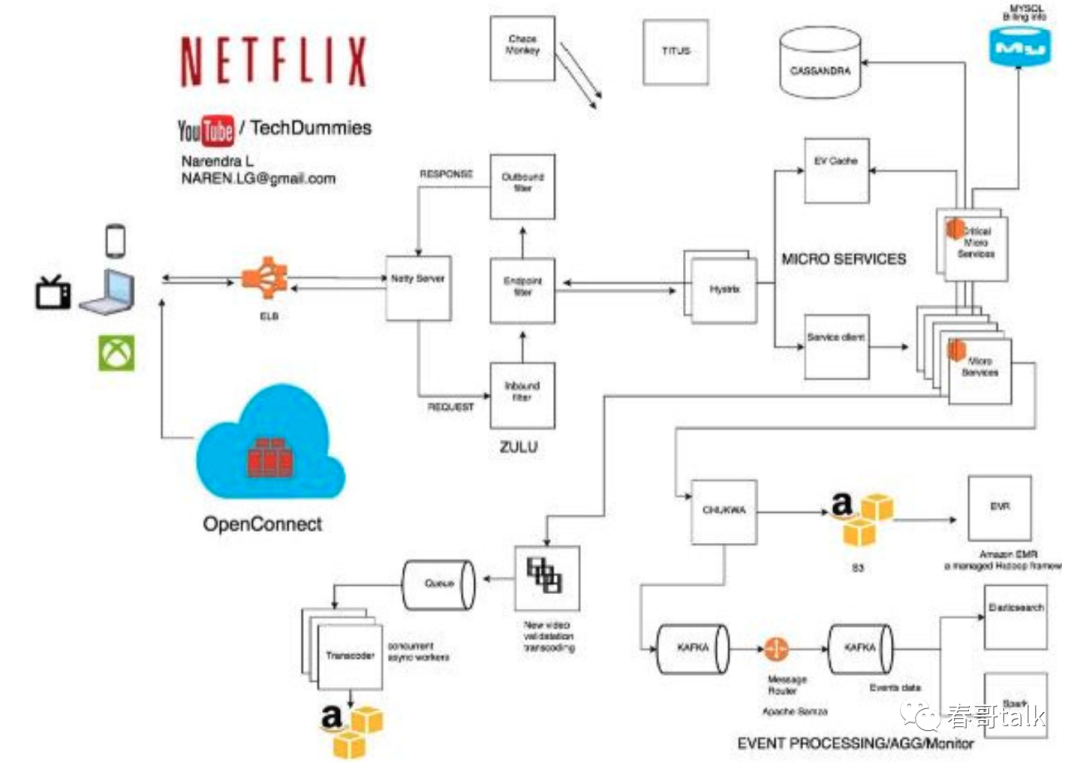
架构主要包含三部分:
1. Open Connect(Netflix CDN);
2. 后台;
3. 客户端;
客户端:定义为播放 Netflix 适配的用户界面,如 TV、XBox、笔记本、智能手机。用户点击播放之后,任何功能都由 CDN 实现。
CND:是分布式服务器系统,根据用户地理位置,网页、服务器的起点。当 Netflix 的视频被转码后,CDN 将 Netflix 视频存储到世界各地。
视频播放流程
当用户打开Netflix应用时,所有的请求都是由AWS来完成。譬如登录,推荐,主页,用户历史记录和客服等。当用户点击视频的播放按钮,Netflix应用会自动判定最佳的Open Connect服务器,最好的格式和比特率,以便让视频从附近的OCA流畅地传出。Netflix应用相当的智能,它能不间断地寻找流媒体服务器和比特率,并自动替换到能为用户带来更好体验的服务器。
ELB
Netflix对ELB进行如下设置:首先是区域间的负载平衡,然后是实例间的负载平衡。这是因为ELB的设置是有两级负载平衡方案:
1. 基于域名服务的循环负载平衡;
2. 同一区域内多个负载实例平衡;
ZUUL
作为边缘应用网关,将所有设备、网站请求导向后台的流媒体服务。
Zuul 实现了动态路由、监控、弹性、安全。(基于 Netty 实现)。
Hystris
延迟与容错代码库,可以防止级联错误、实时监控配置变动、基于并行请求缓存、基于请求崩溃自动批处理。
媒体处理
Netflix花费很多时间验证视频。视频验证包括查找数字工件,颜色变化,由于前面转码步骤的数据丢失造成的帧丢失。在视频被验证后,就会被送入Netflix称作的媒体管道。处理几兆尺寸的一个文件并不现实,所以管道的第一步是把一个文件分割成若干个小块。接下来视频块被接通到管道,这样编码会并行处理。
Archer
Archer是具有映射-规约风格的媒体处理平台。Archer使用容器,这使得用户能够处理操作系统级别的依赖性。该平台可以进行通常的媒体处理步骤。开发人员需要写三个功能:分离,映射,收集。任何编程语言都可以使用。Archer创建的目的就是大规模进行简单媒体处理。这意味着平台知道媒体格式,并给予流行媒体模式优先处理。
微服务
Netflix使用微服务架构来驱动所有的APIs。每个API调用其他的微服务来获取所需的数据和提供响应。可靠性如何实现呢?一是以来Hystris,第二是分离关键服务。
关键微服务
依照Netflix的设计,当遇到级联失败时,至少用户还可以点击并播放推荐的视频。实现这一功能的微服务被称为关键微服务。关键微服务对其它服务没有很多依赖性。
无状态服务
Netflix的一个设计目标是无状态服务。也就是说任一服务器失败的话都无关紧要。在失败的情况下请求可以被路由到另外一服务实例,或者启动一个新的服务器来取代失败的服务器。

有状态服务,数据库(部署在EC2上的MySQL)
有状态信息主要通过MySql存储。基于主机的“同步复制协议”,确保主机上写操作完成的定义是写操作在主机和远程终端都完成。单个节点的数据丢失不会造成数据的丢失。ETL工作的读流量被导向读操作副本,以便于主数据库免于繁重的批处理操作。在主数据库失败的情况下,故障转移会在已经有了复制的次节点上进行。当次节点能够胜任主数据库的工作时,route53上DNS的条目就会指向新的次节点。
KV缓存
当一个节点失败后,节点上的缓存也会跟着失败,这样就会有性能损失,除非所有数据都有缓存。Netflix的解决方案是使用KV缓存,一个基于Memcached的封装。不是简单的封装,是有冗余度的分片集群。在存操作时,所有的分片都被更新。在读操作的情况下,是从最近的缓存或节点读取数据。当最近的节点失败,则会从其它的节点读取。KV缓存每天能够处理三千万的请求,并具有毫秒级的线性扩展性。
Cassandra
Cassandra用来存储用户的阅读历史数据的。Netflix的Cassandra集群也经历了重新设计。重新设计的理念是:更小的存储,在用户阅读量增加情况下的一致的读写性能。对应的解决方案就是:
1. 压缩旧的数据。
2. 数据被分成两类。
实时阅读历史(LiveVH):频繁被更新的少量的最近阅读的数据,这部分数据未被压缩的形式存储。
压缩阅读历史(CompressedVH):很少被更新的大量的旧的阅读数据,这部分数据被压缩以减少存储空间。压缩阅读历史被存储在基于行密匙的单个列里。
Apache Chukwa
一个开源的监控大规模分布式系统的数据采集系统。基于Hadoop HDFS和映射-规约架构。其继承了Hadoop的可扩展性和稳健性。Apache Chukwa还包含功能强大的显示、监控、分析功能。Kafka的路由服务负责把数据从Kafka 的前端移动到不同的目标节点:也就是S3、Elasticsearch、次级Kafka。这个路由服务叫Apache Samza。当Chukwa把流量发给Kafka,既可以是全部数据流,也可以是过滤流。
Elastic Search
Elastic search在Netflix被越来越广泛的应用。如一个用户想要播放一个视频但却没有成功,该用户向客服反馈。客服通过elastic search来查询数据(日志)来深入研究问题出在哪里,并给与用户反馈。
AWS应用自动缩放功能 - TITUS
Titus的目的是快速启动可靠的部署应用程序对应的容器。
主要目的如下:
允许容器化的应用与AWS,Netflix个其它云服务无缝连接;
可操作性上能够保证系统能运行关键任务载荷和SLA;
可扩展性上保证成千上万的主机上能够运行成千上万个容器,来实现众多的运行实例;
Titus是一个基于Apache Mesos开发的框架,是连接众多主机资源的集群管理系统。
1. Titus包括一个可复制的,提供领导选择的调度器。该调度器叫做Titus Master。
2. Titus Master负责将容器实例放置到EC2虚拟机的一个大池子里。该EC2虚拟机亦叫Titus Agents,负责管理单个容器的生命周期。
3. Zookeeper管理领导选择,Cassandra存储Titus Master的数据。
Titus的主要功能是实现容器的自动缩放。
自动缩放是怎样工作的呢?例如,一个用户在东岸打开Netflix,Netflix 的服务自动扩大业务的服务实例来满足该用户的视频需求。
功能实现是基于AWS自动缩放引擎实现的。其能够计算一个Titus服务的期望容量,把容量信息传递给Titus,从而使得Titus能够根据容量来启动或停止容器来调整实例载荷。
该方案有几个优势:
第一,充分利用经过检验的AWS自动缩放引擎。
第二,Titus用户可以使用已经熟悉的EC2。
第三,应用能够缩放自己的指标(譬如每秒请求和容器CPU利用率)和AWS的指标(譬如SQS队列深度)。
第四,用户能够从AWS对自动缩放的完善中获益。
Titus的一个大的挑战是启动AWS自动缩放引擎调用Titus控制平台。为了解决这个问题,Netflix充分利用AWS的API网关。
AWS的API网关是一个提供API访问的服务,同时也提供了后台服务来调用Titus。
API网关提供了供AWS访问的API,以调整资源载荷和载荷状态,以便后台实现可扩展的资源。当Titus服务配置了自动缩放策略,Titus便在AWS上创建了一个可缩放目标。
完。希望对你有用。