
(附代码)干货 | 你必须知道的代码内存占用
点击左上方蓝字关注我们

作者 | Tirthajyoti Sarkar
链接 | https://towardsdatascience.com/how-much-memory-is-your-ml-code-consuming-98df64074c8f
pip install scalene
scalene <yourapp.py>
load_ext scalene
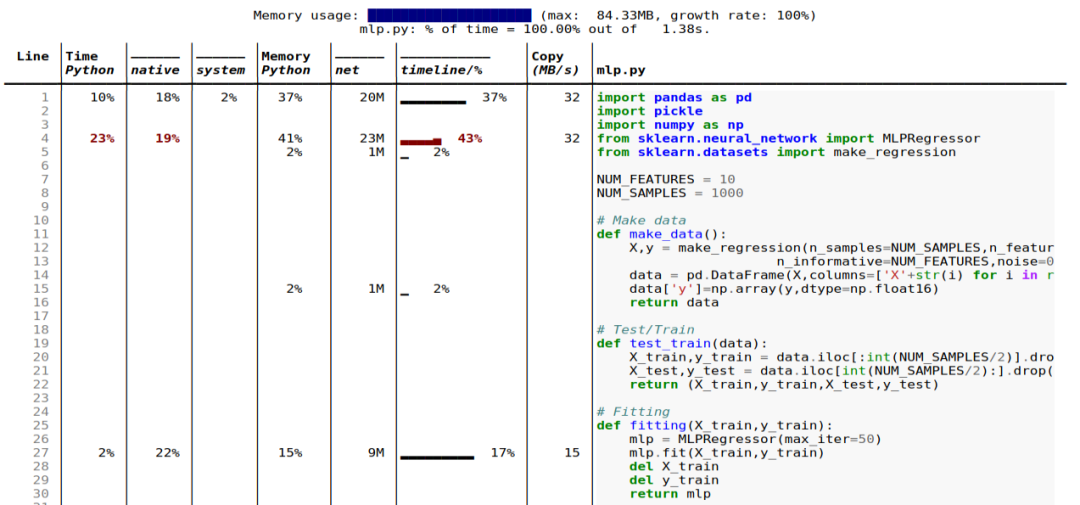
行和函数:报告有关整个函数和每个独立代码行的信息;
线程:支持 Python 线程;
多进程处理:支持使用 multiprocessing 库;
Python 与 C 的时间:Scalene 用在 Python 与本机代码(例如库)上的时间;
系统时间:区分系统时间(例如,休眠或执行 I / O 操作);
GPU:报告在英伟达 GPU 上使用的时间(如果有);
复制量:报告每秒要复制的数据量;
泄漏检测:自动查明可能造成内存泄漏的线路。
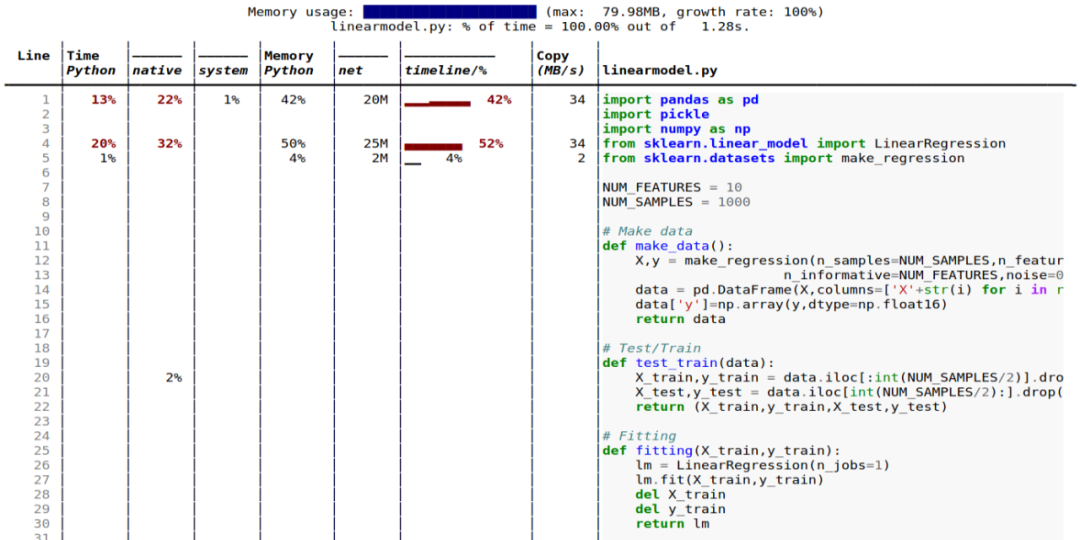
多元线性回归模型;
具有相同数据集的深度神经网络模型。
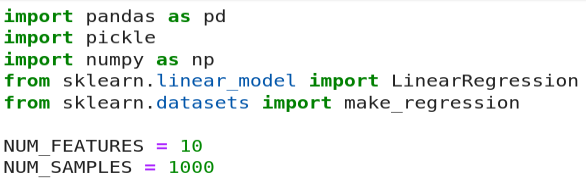


$ scalene linearmodel.py --html linearmodel-scalene.html
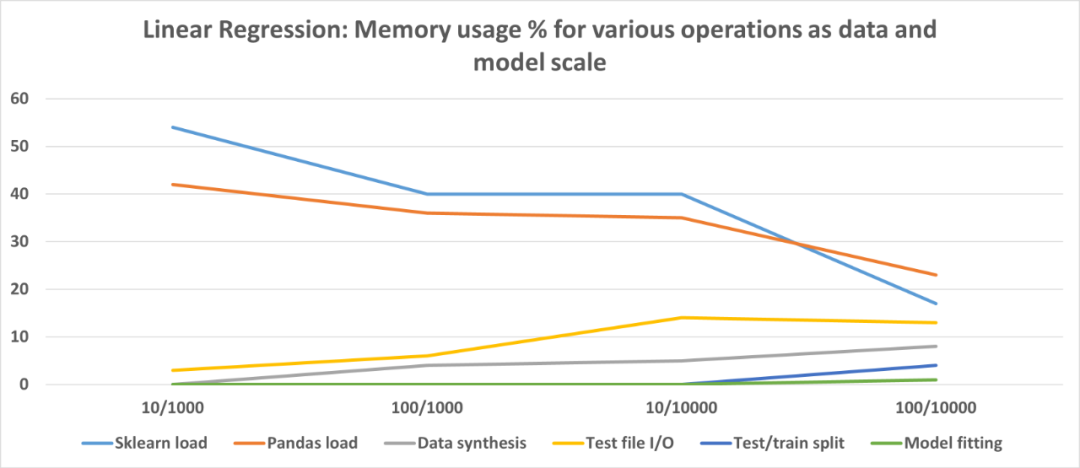
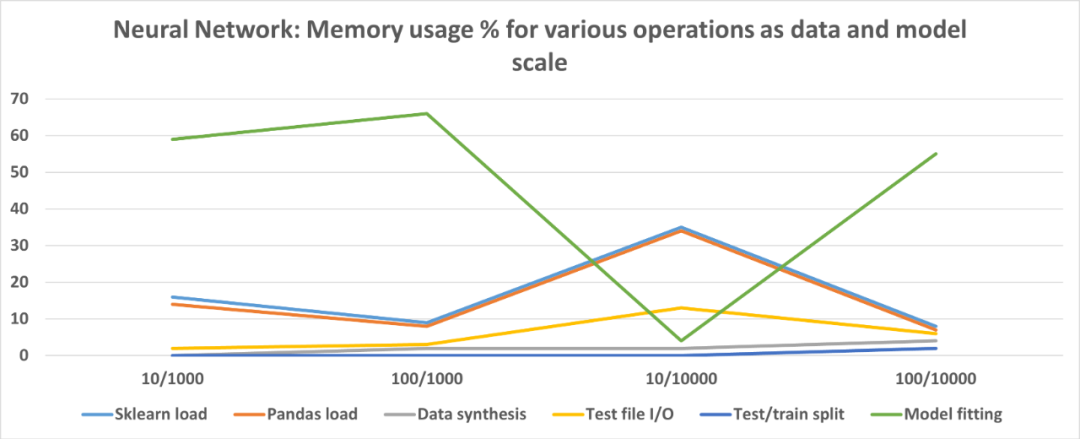
最好在代码中编写专注于单个任务的小型函数;
保留一些自由变量,例如特征数和数据点,借助最少的更改来运行相同的代码,在数据 / 模型缩放时检查内存配置文件;
如果要将一种 ML 算法与另一种 ML 算法进行比较,请让整体代码的结构和流程尽可能相同以减少混乱。最好只更改 estimator 类并对比内存配置文件;
数据和模型 I / O(导入语句,磁盘上的模型持久性)在内存占用方面可能会出乎意料地占主导地位,具体取决于建模方案,优化时切勿忽略这些;
出于相同原因,请考虑比较来自多个实现 / 程序包的同一算法的内存配置文件(例如 Keras、PyTorch、Scikitlearn)。如果内存优化是主要目标,那么即使在功能或性能上不是最佳,也必须寻找一种占用最小内存且可以满意完成工作的实现方式;
如果数据 I / O 成为瓶颈,请探索更快的选项或其他存储类型,例如,用 parquet 文件和 Apache Arrow 存储替换 Pandas CSV。可以看看这篇文章:
仅分析 CPU 时间,不分析内存;
仅使用非零内存减少资源占用;
指定 CPU 和内存分配的最小阈值;
设置 CPU 采样率;
多线程并行,随后检查差异。
END
整理不易,点赞三连↓