
实时数仓建设思考与方案记录
前言
随着我司业务飞速增长,实时数仓的建设已经提上了日程。虽然还没有正式开始实施,但是汲取前人的经验,做好万全的准备总是必要的。本文简单松散地记录一下想法,不涉及维度建模方法论的事情(这个就老老实实去问Kimball他老人家吧)。
动机
随着业务快速增长,传统离线数仓的不足暴露出来:
运维层面——所有调度任务只能在业务闲时(凌晨)集中启动,集群压力大,耗时越来越长;
业务层面——数据按T+1更新,延迟高,数据时效价值打折扣,无法精细化运营与及时感知异常。
实时数仓即离线数仓的时效性改进方案,从原本的小时/天级别做到秒/分钟级别。
底层设计变动的同时,需要尽力保证平滑迁移,不影响用户(分析人员)之前的使用习惯。
指导思想:Kappa架构
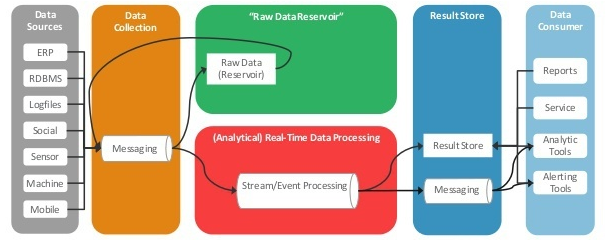
计算引擎
硬性要求
批流一体化——能同时进行实时和离线的操作;提供统一易用的SQL interface——方便开发人员和分析人员。
可选项:Spark、Flink,较优解:Flink
优点:
严格按照Google Dataflow模型实现;在事件时间、窗口、状态、exactly-once等方面更有优势;非微批次处理,真正的实时流处理;多层API,对table/SQL支持良好,支持UDF、流式join等高级用法。
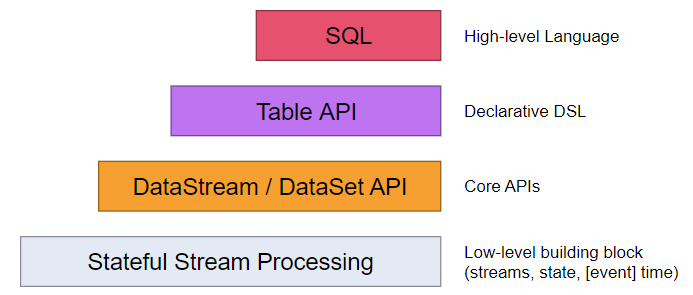
缺点
生态系统没有Spark强大(不太重要);
1.10版本相比1.9版本的改动较多,需要仔细研究。
底层(事实数据)存储引擎
硬性要求
数据in-flight——不能中途落地,处理完之后直接给到下游,最小化延迟;可靠存储——有一定持久化能力,高可用,支持数据重放。可选项:各种消息队列组件(Kafka、RabbitMQ、RocketMQ、Pulsar、...)
较优解:Kafka
优点:
吞吐量很大;与Flink、Canal等外部系统的对接方案非常成熟,容易操作;团队使用经验丰富。
中间层(维度数据)存储引擎
硬性要求
支持较大规模的查询(主要是与事实数据join的查询);能够快速实时更新。可选项:RDBMS(MySQL等)、NoSQL(HBase、Redis、Cassandra等)
较优解:HBase
优点
实时写入性能高,且支持基于时间戳的多版本机制;
接入业务库MySQL binlog简单;
可以通过集成Phoenix获得SQL能力。
高层(明细/汇总数据)存储/查询引擎
根据不同的需求,按照业务特点选择不同的方案。
当前已大规模应用,可随时利用的组件:
Greenplum——业务历史明细、BI支持、大宽表MOLAP
Redis——大列表业务结果(PV/UV、标签、推荐结果、Top-N等)
HBase——高并发汇总指标(用户画像)
MySQL——普通汇总指标、汇总模型等
当前未有或未大规模应用的组件:
ElasticSearch(ELK)——日志明细,似乎也可以用作OLAP?
Druid——OLAP
InfluxDB/OpenTSDB——时序数据
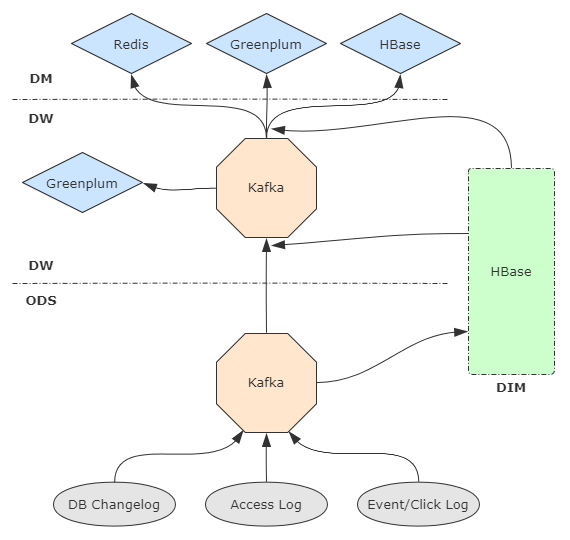
数仓分层设计
参照传统数仓分层,尽量扁平,减少数据中途的lag,草图如下。
元数据管理
必要性 Kafka本身没有Hive/GP等传统数仓组件的metastore,必须自己维护数据schema。(Flink 1.10开始正式在Table API中支持Catalog,用于外部元数据对接。)
可行方案
外部存储(e.g. MySQL) + Flink ExternalCatalog
Hive metastore + Flink HiveCatalog(与上一种方案本质相同,但是借用Hive的表描述与元数据体系)
Confluent Schema Registry (CSR) + Kafka Avro Serializer/Deserializer 现在仍然纠结中。
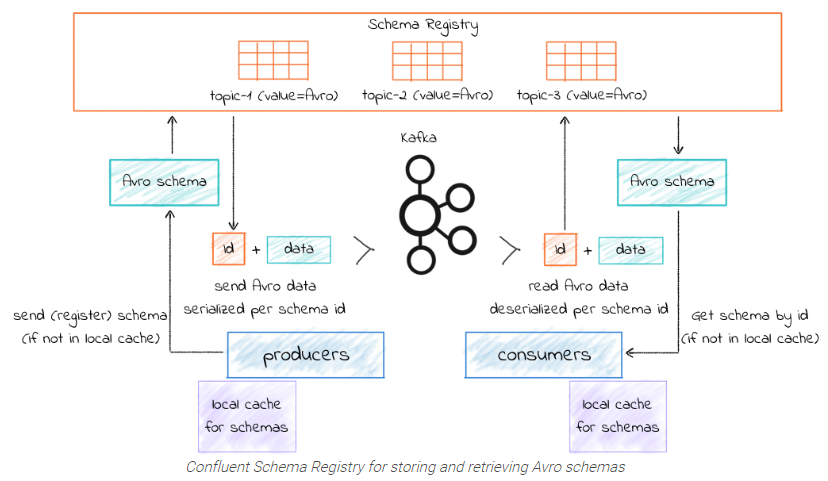
CSR是开源的元数据注册中心,能与Kafka无缝集成,支持RESTful风格管理。producer和consumer通过Avro序列化/反序列化来利用元数据。
SQL作业管理
必要性:实时数仓平台展现给分析人员的开发界面应该是类似Hue的交互式查询UI,即用户写标准SQL,在平台上提交作业并返回结果,底层是透明的。但仅靠Flink SQL无法实现,需要我们自行填补这个gap。
可行方案:AthenaX(由Uber开源)
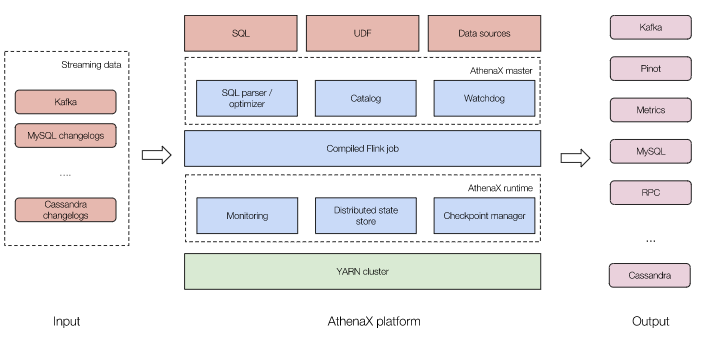
流程:用户提交SQL → 通过Catalog获取元数据 → 解释、校验、优化SQL → 编译为Flink Table/SQL job → 部署到YARN集群并运行 → 输出结果 重点仍然是元数据问题:如何将AthenaX的Catalog与Flink的Catalog打通?
需要将外部元数据的对应到Flink的TableDescriptor(包含connector、format、schema三类参数),进而映射到相应的TableFactory并注册表。
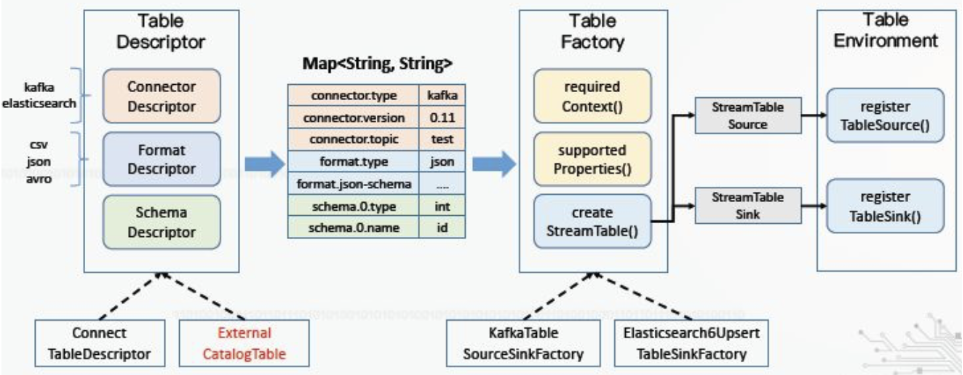
另外还需要控制SQL作业对YARN资源的占用,考虑用YARN队列实现,视情况调整调度策略。
性能监控
使用Flink Metrics,主要考虑两点:
算子数据吞吐量(numRecordsInPerSecond/numRecordsOutPerSecond)
Kafka链路延迟(records-lag-max)→ 如果搞全链路延迟,需要做数据血缘分析
数据质量保证
手动对数——旁路写明细表,定期与数据源交叉验证
自动监控——数据指标波动告警 etc