
【Python基础】Python数据分析实战之分布分析
◆ ◆ ◆ ◆ ◆
import pandas as pdimport matplotlib.pyplot as pltimport math
>>> df = pd.read_csv('UserInfo.csv')>>> df.info()RangeIndex: 1000000 entries, 0 to 999999Data columns (total 4 columns):UserId 1000000 non-null int64CardId 1000000 non-null int64LoginTime 1000000 non-null objectDeviceType 1000000 non-null objectdtypes: int64(2), object(2)memory usage: 30.5+ MB
# 提取出生日期需要先把身份证号码转换成字符串> df['CardId'] = df['CardId'].astype('str')# 提取出生日期,并生成新字段> df['DateofBirth'] = df.CardId.apply(lambda x : x[6:10]+"-"+x[10:12]+"-"+x[12:14])# 提取性别,待观察性别分布> df['Gender'] = df['CardId'].map(lambda x : 'Male' if int(x[-2]) % 2 else 'Female')> df.head()
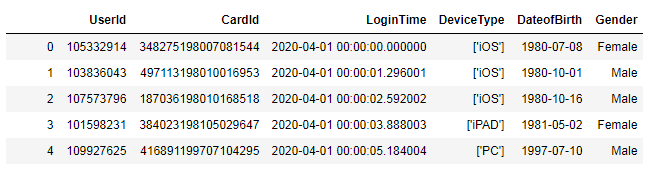
3.计算年龄
# 提取出生日期:月和日>>> df[['month','day']] = df['DateofBirth'].str.split('-',expand=True).loc[:,1:2]# 提取小月,查看是否有31号>>> df_small_month = df[df['month'].isin(['02','04','06','09','11'])]# 无效数据,如图所示>>> df_small_month[df_small_month['day']=='31']# 统统删除,均为无效数据>>> df.drop(df_small_month[df_small_month['day']=='31'].index,inplace=True)# 同理,校验2月>>> df_2 = df[df['month']=='02']# 2月份的校验大家可以做的仔细点儿,先判断是否润年再进行删减>>> df_2[df_2['day'].isin(['29','30','31'])]# 统统删除>>> df.drop(df_2[df_2['day'].isin(['29','30','31'])].index,inplace=True)
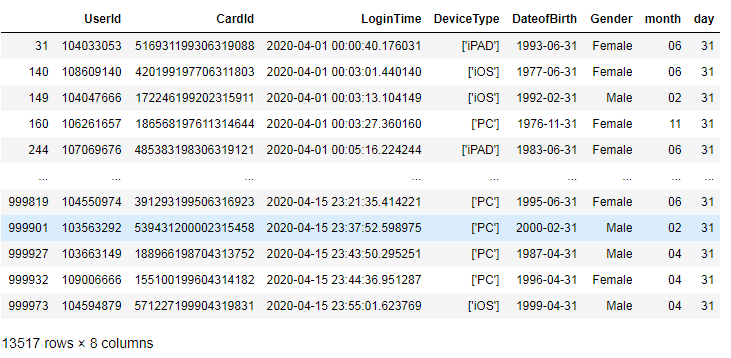
# 计算年龄# 方法一df['Age'] = df['DateofBirth'].apply(lambda x : math.floor((pd.datetime.now() - pd.to_datetime(x)).days/365))# 方法二df['DateofBirth'].apply(lambda x : pd.datetime.now().year - pd.to_datetime(x).year)
# 查看年龄区间,进行分区>>> df['Age'].max(),df['Age'].min()# (45, 18)>>> bins = [0,18,25,30,35,40,100]>>> labels = ['18岁及以下','19岁到25岁','26岁到30岁','31岁到35岁','36岁到40岁','41岁及以上']>>> df['年龄分层'] = pd.cut(df['Age'],bins, labels = labels)
# 查看是否有重复值>>> df.duplicated('UserId').sum() #47681# 数据总条目>>> df.count() #980954

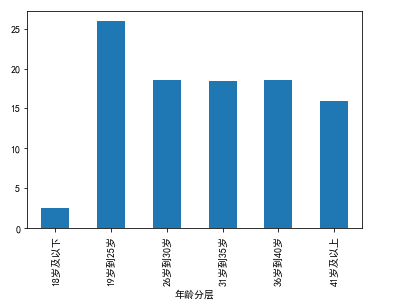
>>> df.groupby('年龄分层')['UserId'].count()年龄分层18岁及以下 2526219岁到25岁 25450226岁到30岁 18175131岁到35岁 18141736岁到40岁 18158941岁及以上 156433Name: UserId, dtype: int64# 通过求和,可知重复数据也被计算进去>>> df.groupby('年龄分层')['UserId'].count().sum()# 980954>>> df.groupby('年龄分层')['UserId'].nunique()年龄分层18岁及以下 2401419岁到25岁 24219926岁到30岁 17283231岁到35岁 17260836岁到40岁 17280441岁及以上 148816Name: UserId, dtype: int64>>> df.groupby('年龄分层')['UserId'].nunique().sum()# 933273 = 980954(总)-47681(重复)# 计算年龄分布>>> result = df.groupby('年龄分层')['UserId'].nunique()/df.groupby('年龄分层')['UserId'].nunique().sum()>>> result# 结果年龄分层18岁及以下 0.02573119岁到25岁 0.25951626岁到30岁 0.18518931岁到35岁 0.18494936岁到40岁 0.18515941岁及以上 0.159456Name: UserId, dtype: float64# 格式化一下>>> result = round(result,4)*100>>> result.map("{:.2f}%".format)年龄分层18岁及以下 2.57%19岁到25岁 25.95%26岁到30岁 18.52%31岁到35岁 18.49%36岁到40岁 18.52%41岁及以上 15.95%Name: UserId, dtype: object
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):
评论