
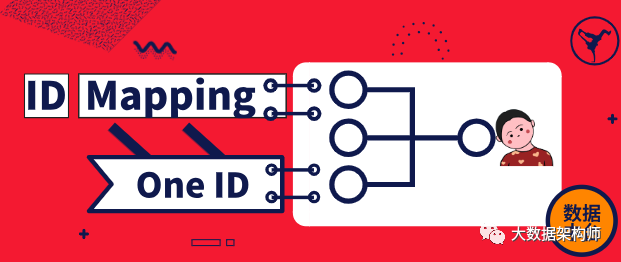
你管这玩意儿叫 ID-Mapping ?
这是彭文华的第153篇原创
网上 ID Mapping 的技术文章不多,我正好经历过传统数据清洗和互联网 ID Mapping 两种场景,今天就把具体方法总结分享一下。欢迎大家加我微信:shirenpengwh ,一起探讨大数据相关技术。每天一篇原创,分享给大家,我们一起学习,共同进步。
其实技术都是为了解决实际业务问题的。如果没有数据孤岛的问题,也就不会有这波澜壮阔的数字技术发展和改革。
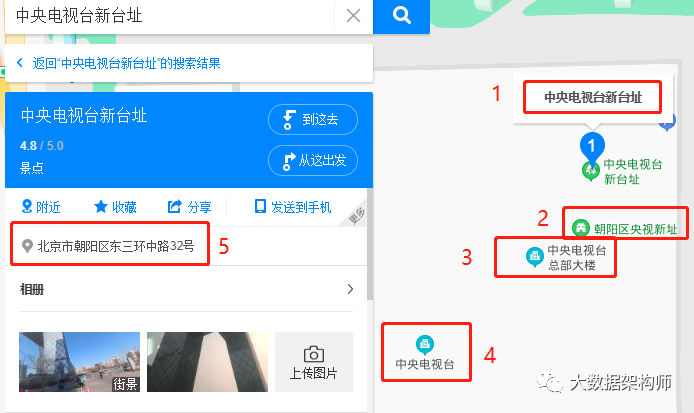
在 10 多年前的时候,当时IT界都还在做“四库十二金”的项目。我就接了这么一个活,就是把一个地区的所有地址给弄干净。这可就费劲了,因为同一个地址有 N 多种写法,比如说“大裤衩”,全称叫“中央电视台总部大楼”,门牌号是“北京市朝阳区东三环中路32号”,也有别称叫“中央电视台新址”,而且还有具体经纬度。
这么乱的情况,一不小心就给弄错了。我们当时接的项目就是把这乱七八糟的地址给统一了,给地理信息库提供基础数据。这上那弄去啊?太费劲了好么!
我们当时是怎么弄的呢?说来也很简单,就是比对。写规则比对,简单规则对不上,就用复杂规则对,复杂规则还对不上,就肉眼雷达看。先对大厦、门牌号啥的做清洗,把错别字等都清洗好。然后以相对比较精准的数据源为准,匹配一波,相同的先打上标记。然后把类似的也放一边,最后把都匹配不上的放一边,最后把经纬度也加上一起看。最后再人工肉眼雷达过两遍,最后剩下的就不管了。
这太痛苦了!不过我那时候技术不行,不知道用高技术。百度这边就用图数据库解决这个问题,现在在百度上搜索啥都给你弄出来:
在互联网场景中,这种例子到处都是。数据中台盛行之前,在 DSP (互联网广告投放平台)中就有 ID Mapping 的应用场景。他们必须要识别在不同端(家里电脑、公司电脑)登录的同一个用户。他们拿不到很多详细的数据,只能靠浏览器的 Cookie 数据来识别,所以 DSP 系统中的 ID Mapping 是基于 cookie 来做的,同一个客户,在不同端登录的时候,相同的 cookie 在 DMP (数据管理平台)识别成为同一个客户。
但是这里还有一个问题,就是 cookie 只能隶属于同一个域名,也就是说你访问邮箱的 cookie ,与百度广告联盟的 cookie 并不是同一个,所以在网站和DSP之间,也要做 ID Mapping 。他们通过这么 Mapping 之后,就能知道你在那些网站上登录,都看了些啥东西,然后再给你推荐相关的内容。
这就有了你在百度上搜索了“养生”,到购物网站上就会给你推荐“枸杞”一样。
而现在,由于我们的系统越来越复杂,对客户的价值发现要求越来越高,我们在普通的场景中也有类似的需求。比如我们的交易平台上的用户交易信息和 ERP 中有可能只是通过订单关联,两遍的系统中的用户根本就是两码事,另外,我们 CRM 中的客户信息又是独立的。交易平台、 ERP 、 CRM 中的用户根本都是相互独立的,我们没法掌握与客户接触的全貌,也就没法精准的识别客户的价值。
而阿里当时遇到的情况比我们更复杂,它不仅是各个系统之间的数据孤岛现象严重,更糟糕的是各个业务线各自一套。这可就要了命了。所以当时阿里就利用 DSP 中的 ID Mapping 逻辑,对所有数据进行了彻底的贯通。这就是阿里数据中台的 One ID 基础。
ID Mapping的核心技术
ID Mapping 有几个场景:1、多端数据的识别;2、多源数据的打通。这两种情况的处理方式基本是一样的。先举一个例子:老王在商城PC端浏览商品,在手机端下单,后台自动生成订单,交给ERP进行后续的订单、物流处理。后来老王有点不耐烦,给供应链金融客服打电话咨询。那么老王的数据如下:
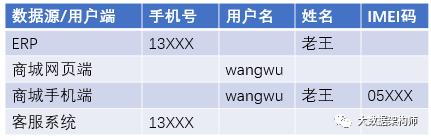
(注:大多数情况下网页端和手机端的 UUID 是一样的,这只是一个例子,理解大意就行)
这种情况,我们用写 SQL 的方式不是那么好使,因为关联情况太多了。而且这是一个个例,你要让所有数据都直接打通,这可不好弄啊。
你非要写 SQL 也能行,但是这规则可就复杂的多了,而且对系统的要求也非常高。而且,你还得考虑在某端偶尔登录一次的情况。这就更蒙圈了好么?在落地的时候你会遇到一堆的问题。
现在大数据环境了,技术也发展的很快,当然不能用我之前做数据清洗的方式那么弄,写 SQL 就显得太傻了。之前我就介绍过,百度用的是图数据库的方式解决的。图计算的逻辑就是把数据抽象成“点”和“边”,然后用图计算天然的“连接”特效,实现数据的自动识别和打通。
你看,其实我们要做的,就是把这几个数据做一个打通,类似于这样:
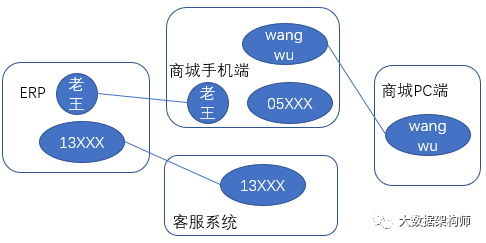
你看这个图,既没有方向,也可能不能形成“环”状。这就是一个无向连通图。这么着一连,这些信息就能对上了。
你现在想写,写 SQL 是不是非常难?但是用图计算就非常简单了。把数据处理成图数据库需要的格式,然后用图计算就很容易得到我们要的结果。而且,我们还能对“边”设定阈值,把用户在打印室等临时登录场景给去掉,过滤噪音,是不是非常好用?
所以呢, ID Mapping 的过程基本是以下几步:
1、各源/端的要素识别,就是能够识别用户信息的各个要素,原始 ID 也是有用的;
2、各自抽象和组装成“点”和“边”的数据集,设置边阈值,过滤弱连接;
3、构建一个图模型,用连通子图算法求得那些ID标识属于同一个对象;
4、得到结果集,分配一个新的 ID ;
5、去重、合并数据,生成最终结果;
6、循环 3-5 环节,同时在3环节使用已有结果集,已有 id 则沿用老 ID 。
最后,就生成一张 id 映射字典,大概的意思就是:
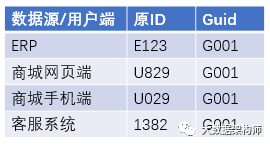
就这样,孤立的系统数据就算是从 ID 层面打通了,我们基于这个字典我们就能做更多事情了,比如更全面的画一个用户画像。
数据我们也能存好,怎么放都行,最好是扔ES等查询速度快的数据库里,对外提供 One ID 的查询服务。
以上就是ID-Mapping的核心技术了。在实际落地的时候,你还会遇到各种各样的问题,比如遇到多对多的情况怎么办?之前缺少要素匹配不上,但是后来用户增加了信息,又匹配上了咋办?结果数据存成什么样比较好用?放在那里比较好?要不要建一个DV模型方便找数据?那是工程建设中需要考虑的问题。这就得完全靠实践出真知了。
总结
One ID的核心价值是打通数据孤岛,把不同时期孤立建设的系统,用统一的ID串联起来。One ID功能就像是在修桥梁,把各个数据孤岛贯通之后,这些孤岛就连成一片。
数据孤岛被打破之后,我们就能更全面、更完整的了解我们的用户、产品、商家,能够更加精准的评价他们的价值,进行进一步的价值发现,为精细化运营夯实数据基础。
One ID的核心技术是ID-Mapping,其原理是将各系统的关键要素抽象成图计算用的“点”和“边”,用图计算算法很轻易的判定同一个“对象”,从而构建一个个无向连通图,生成ID映射字典。这个ID映射字典就是一座座通往各个数据孤岛的桥梁。我们通过这些桥梁,可以把相同“对象”在不同孤岛中的数据串联起来。这样,我们就掌控了全局,而非局部。
欢迎大家加我微信:shirenpengwh ,一起探讨大数据相关技术。每天一篇原创,分享给大家,我们一起学习,共同进步。
配合以下文章享受更佳
下载 | 大数据职业发展体系全解
思考 | 为什么说你的运营团队一定要有一名女生?