
【论文解读】OneNet:一阶段的端到端物体检测器,无需NMS
导读
将分类损失引入到正样本的匹配过程中,每个gt只匹配一个正样本,简单的两个改动,消除了冗余的预测框,去掉了NMS。
论文:https://arxiv.org/abs/2012.05780
代码:https://github.com/PeizeSun/OneNet
后台回复“onenet”,获取下载好的论文和代码。
摘要:端到端物体检测的主要障碍在于ground truth的标签分配以及去除NMS上。目前在做标签分配的时候,只是通过位置来匹配,没有使用分类,这导致了在推理的时候会出现高置信度的冗余的框,这就需要在后处理的时候使用NMS。我们提出了一种方法,对于一个groundtruth,只分配一个正样本,其他的都是负样本。为了验证我们的方法的有效性,我们设计了一个非常简单的模型,叫做OneNet,这个模型可以避免生成冗余的框,所以不需要NMS。
1. 介绍
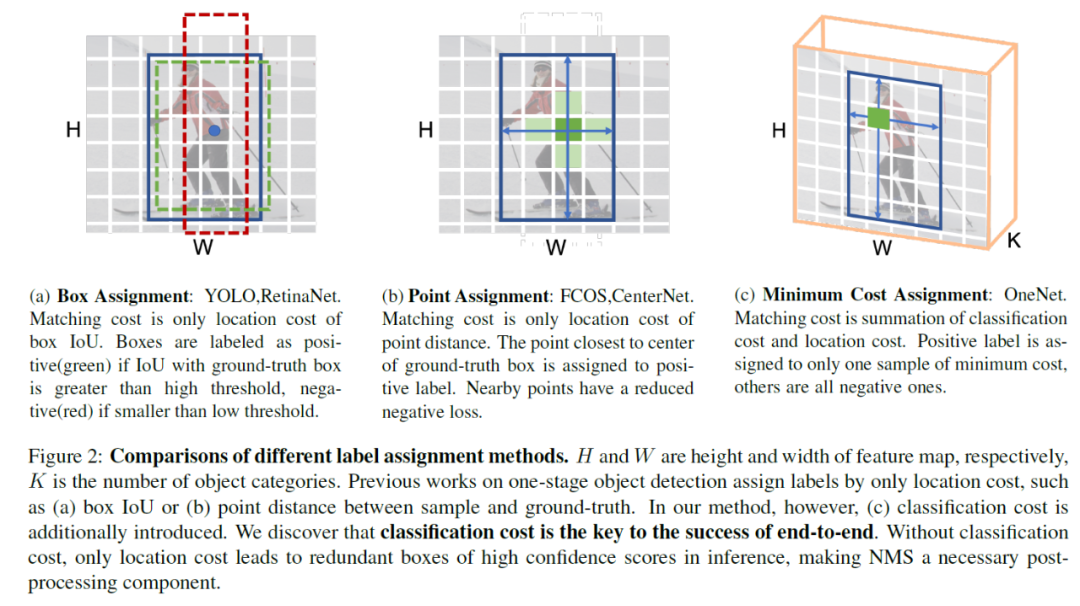
在当前的目标检测方法中,标签的匹配是一个非常重要的环节,目前的匹配方式主要基于IoU,当候选框和gt的IoU高于设定的阈值时,则匹配为正样本,我们把这种方式称为“框分配”。在进行框匹配时,需要预设大量的anchor框,而anchor框的大小,比例,对于性能的影响是很大的,而且需要手工的去设计这些anchor框。于是,后来有了anchor free的方法,这种方法将网格点作为样本,看网格点与目标点的距离以及网格点是否在目标内部来判断是否为正样本。我们将这种方式称为“点分配”。
这两种方法都有一个共同的问题,就是“多对一”,对于一个gt,可以有超过一个正样本与之匹配。这样使得模型的性能对于超参数很敏感,而且容易产生冗余的检测结果,这就需要在后处理的时候必须去使用NMS。
于是最近出现了一对一的匹配的方法,很有前途,直接给出结果,不需要NMS。如果直接在一阶段的方法中使用一对一的话,性能会很差,而且在推理的时候,还是会出现冗余的框,所以还是需要NMS。我们发现,在标签分配的时候,缺少分类损失是一阶段检测器去除NMS的主要问题。因此,我们设计了一个简单的标签分配策略,叫做Minimum Cost Assignment,具体来说,对于每个gt框,只有一个具有最小的分类和定位损失的样本被分配为正样本。见图2(c)。
我们为OneNet总结了几条优点:
整个网络是个全卷积结构,端到端的,没有任何的ROI和注意力交互之类的操作。 标签的分配基于分类和定位的最小损失,而不是手工设计的规则。 不需要后处理,比如NMS或者是最大池化。
2. 标签分配
2.1 匹配损失
之前方法是通过IoU或者是点的距离来进行匹配的,我们把这种方式总结为位置损失,位置损失定义为:
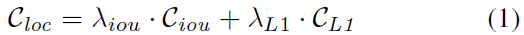
其中,是IoU损失,是L1损失,在框分配中,,在点分配中,。
但是,检测是个多任务,既有分类又有回归,所以只使用位置损失并不是最优的,会导致高置信度的冗余框的出现,导致后处理的时候需要NMS。因此,我们把分类损失引入匹配损失中,定义如下:
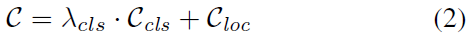
2.2 最小损失分配
下面的算法显示了最小损失的例子,分类损失使用交叉熵,定位损失使用L1。在dense的检测器中,分类损失可以使用Focal Loss,定位损失可以同时包含L1和GIoU Loss。
# For simplicity,
# cross entropy loss as classification cost
# L1 loss as location cost
# Input:
# class_pred, box_pred: network output(HxWxK, HxWx4)
# gt_label, gt_box: ground-truth (N, Nx4)
# Output:
# src_ind: index of positive sample in HW sequence(N)
# tgt_ind: index of corresponding ground-truth (N)
# flattened class: HWxK
output_class = class_pred.view(-1, K)
# flattened box: HWx4
output_box = box_pred.view(-1, 4)
# classification cost: HWxN
cost_class = -torch.log(output_class[:, gt_label])
# location cost: HWxN
cost_loc = torch.cdist(out_box, gt_bbox, p=1)
# cost matrix: HWxN
cost_mat = cost_class + cost_loc
# index of positive sample: N
_, src_ind = torch.min(cost_mat, dim=0)
# index of ground-truth: N
tgt_ind = torch.arange(N)
定义如下:
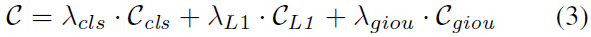
3. OneNet
OneNet是一个端到端的结构,具体的pipeline如图3:
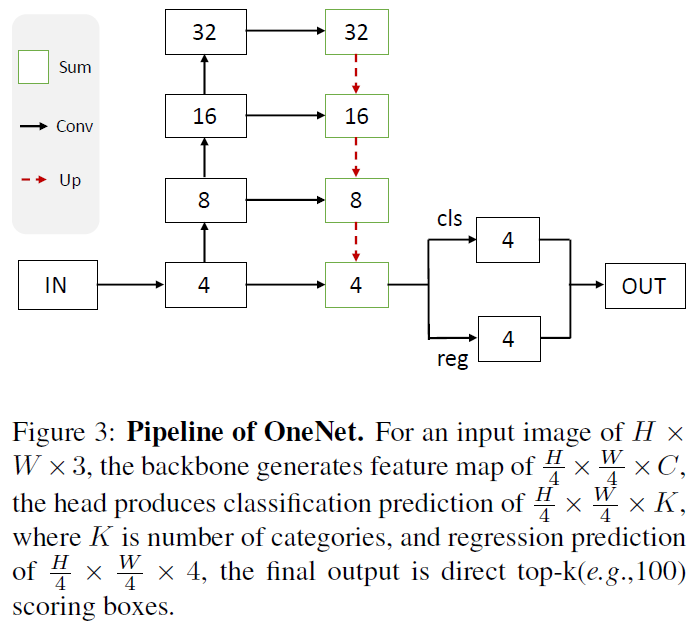
backbone:这里的backbone包括主干网络和一个FPN,最后只输出了一张特征图,尺寸为H/4xW/4。
head:head包括两个并行的分支,分别进行分类和回归。
训练:标签分配的方法使用最小损失方法,训练损失和匹配损失类似,包括Focal Loss,L1 Loss, GIoU Loss。
推理:最后的输出直接就是按照得分进行排序,取TopK,不需要后处理NMS或者max-pooling。
3.1 多头训练
还有一种可选的策略叫做多头训练,包括了一个级联的预测头和共享的权重。如图4:

Cascading heads:在第一个stage中,特征图用F0来表示,将F0的channel维度C广播为2C,得到维度为H/4xW/4x2C,然后通过卷积得到F1,F1的维度为H/4xW/4xC,然后基于F1进行分类和回归,对于后面的stage j,原始的特征F0和前一个stage的特征Fj-1拼接起来,得到的维度为H/4xW/4x2C,然后再卷积得到Fj,维度为H/4xW/4xC,然后基于Fj进行分类和回归。
Weight-sharing:分类的卷积和回归的卷积在每个头中进行权重共享。
单纯的引入这个多头训练在精度上并没有什么提升,而且速度还会变慢,之所以这么做是为了引入另外两个修改,大的学习率和单头推理。
Large learning rate:增大学习率是有可能提高精度的,但是直接增加学习率会导致训练不稳定,所以需要使用级联的头和共享的权重,这样增大学习率也可以稳定的训练,同时提高精度。
Single-head Inference:在推理的时候,只使用第一个stage,其他的不使用,相比多头推理,只有非常微小的精度损失。我们的实验表明,使用多头训练和大学习率可以提高AP一个点。
4. 实验
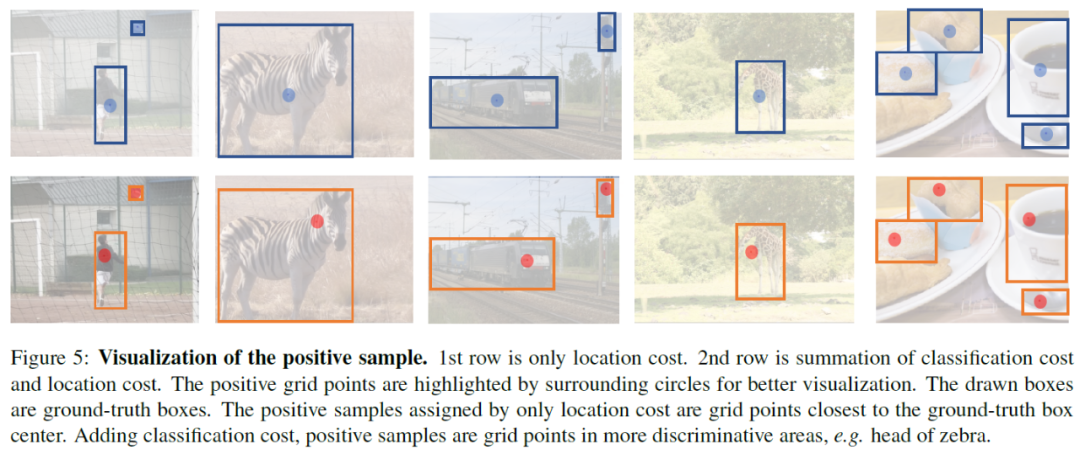
4.1 正样本的可视化
我们对OneNet和CenterNet的正样本进行了可视化的对比,如下图,在CenterNet中,正样本都在gt框附件的网格点上,这种方法对框的回归是有好处的,但是对正负样本的分类并不是最好的选择,比如第一列图片上的人,第一排是CenterNet的框,由于人身体的扭曲,导致了网格点定位到了人身体的边缘上,并不是特征区分最明显的区域。而对于OneNet,可以看到,正样本定位到了人的身体上,是最具特征区分性的地方。
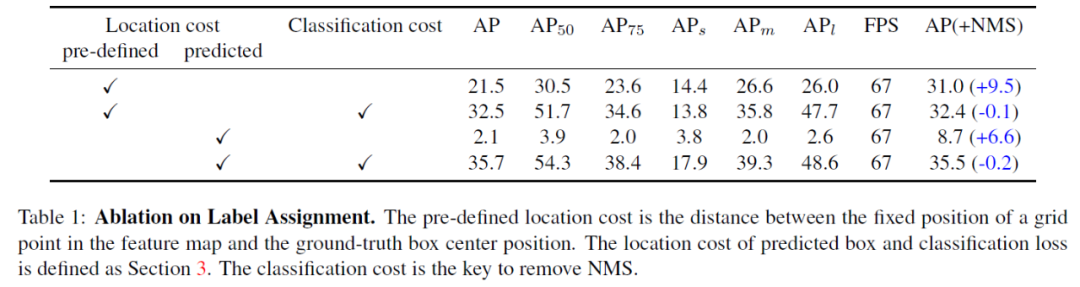
4.2 消融实验
表1进行了标签分配的方案的有效性的对比:
多头训练的效果对比:

图像尺寸的对比:
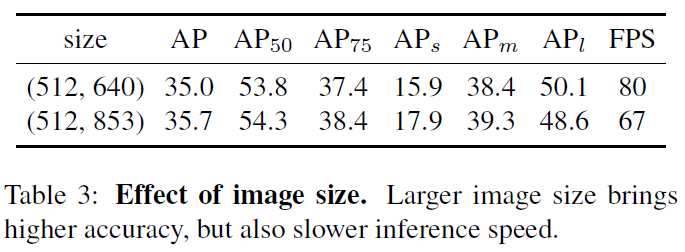
训练策略的对比:
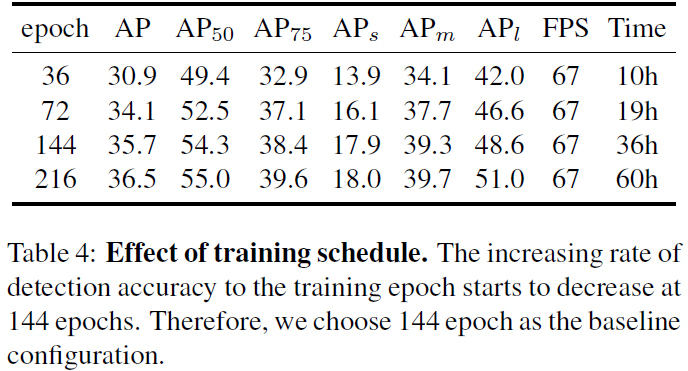
和CenterNet的对比:

在其他方法上使用的对比:
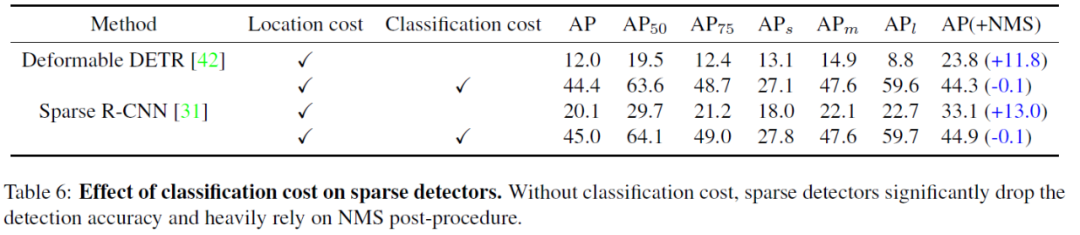

论文链接:https://arxiv.org/abs/2012.05780
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: