
基于SSD的Kafka应用层缓存架构设计与实现

总第432篇
2021年 第002篇

Kafka在美团数据平台的现状
Kafka出色的I/O优化以及多处异步化设计,相比其他消息队列系统具有更高的吞吐,同时能够保证不错的延迟,十分适合应用在整个大数据生态中。
目前在美团数据平台中,Kafka承担着数据缓冲和分发的角色。如下图所示,业务日志、接入层Nginx日志或线上DB数据通过数据采集层发送到Kafka,后续数据被用户的实时作业消费、计算,或经过数仓的ODS层用作数仓生产,还有一部分则会进入公司统一日志中心,帮助工程师排查线上问题。

目前美团线上Kafka规模:
集群规模:节点数达6000+,集群数100+。
集群承载:Topic数6万+,Partition数41万+。
处理的消息规模:目前每天处理消息总量达8万亿,峰值流量为1.8亿条/秒
提供的服务规模:目前下游实时计算平台运行了3万+作业,而这其中绝大多数的数据源均来自Kafka。
Kafka线上痛点分析&核心目标
当前Kafka支撑的实时作业数量众多,单机承载的Topic和Partition数量很大。这种场景下很容易出现的问题是:同一台机器上不同Partition间竞争PageCache资源,相互影响,导致整个Broker的处理延迟上升、吞吐下降。
接下来,我们将结合Kafka读写请求的处理流程以及线上统计的数据来分析一下Kafka在线上的痛点。
原理分析

对于Produce请求:Server端的I/O线程统一将请求中的数据写入到操作系统的PageCache后立即返回,当消息条数到达一定阈值后,Kafka应用本身或操作系统内核会触发强制刷盘操作(如左侧流程图所示)。
对于Consume请求:主要利用了操作系统的ZeroCopy机制,当Kafka Broker接收到读数据请求时,会向操作系统发送sendfile系统调用,操作系统接收后,首先试图从PageCache中获取数据(如中间流程图所示);如果数据不存在,会触发缺页异常中断将数据从磁盘读入到临时缓冲区中(如右侧流程图所示),随后通过DMA操作直接将数据拷贝到网卡缓冲区中等待后续的TCP传输。
综上所述,Kafka对于单一读写请求均拥有很好的吞吐和延迟。处理写请求时,数据写入PageCache后立即返回,数据通过异步方式批量刷入磁盘,既保证了多数写请求都能有较低的延迟,同时批量顺序刷盘对磁盘更加友好。处理读请求时,实时消费的作业可以直接从PageCache读取到数据,请求延迟较小,同时ZeroCopy机制能够减少数据传输过程中用户态与内核态的切换,大幅提升了数据传输的效率。
但当同一个Broker上同时存在多个Consumer时,就可能会由于多个Consumer竞争PageCache资源导致它们同时产生延迟。下面我们以两个Consumer为例详细说明:

如上图所示,Producer将数据发送到Broker,PageCache会缓存这部分数据。当所有Consumer的消费能力充足时,所有的数据都会从PageCache读取,全部Consumer实例的延迟都较低。此时如果其中一个Consumer出现消费延迟(图中的Consumer Process2),根据读请求处理流程可知,此时会触发磁盘读取,在从磁盘读取数据的同时会预读部分数据到PageCache中。当PageCache空间不足时,会按照LRU策略开始淘汰数据,此时延迟消费的Consumer读取到的数据会替换PageCache中实时的缓存数据。后续当实时消费请求到达时,由于PageCache中的数据已被替换掉,会产生预期外的磁盘读取。这样会导致两个后果:
消费能力充足的Consumer消费时会失去PageCache的性能红利。
多个Consumer相互影响,预期外的磁盘读增多,HDD负载升高。
我们针对HDD的性能和读写并发的影响做了梯度测试,如下图所示:

可以看到,随着读并发的增加,HDD的IOPS和带宽均会明显下降,这会进一步影响整个Broker的吞吐以及处理延迟。
线上数据统计
目前Kafka集群TP99流量在170MB/s,TP95流量在100MB/s,TP50流量为50-60MB/s;单机的PageCache平均分配为80GB,取TP99的流量作为参考,在此流量以及PageCache分配情况下,PageCache最大可缓存数据时间跨度为80*1024/170/60 = 8min,可见当前Kafka服务整体对延迟消费作业的容忍性极低。该情况下,一旦部分作业消费延迟,实时消费作业就可能会受到影响。
同时,我们统计了线上实时作业的消费延迟分布情况,延迟范围在0-8min(实时消费)的作业只占80%,说明目前存在线上存在20%的作业处于延迟消费的状态。
痛点分析总结
总结上述的原理分析以及线上数据统计,目前线上Kafka存在如下问题:
实时消费与延迟消费的作业在PageCache层次产生竞争,导致实时消费产生非预期磁盘读。
传统HDD随着读并发升高性能急剧下降。
线上存在20%的延迟消费作业。
按目前的PageCache空间分配以及线上集群流量分析,Kafka无法对实时消费作业提供稳定的服务质量保障,该痛点亟待解决。
预期目标
根据上述痛点分析,我们的预期目标为保证实时消费作业不会由于PageCache竞争而被延迟消费作业影响,保证Kafka对实时消费作业提供稳定的服务质量保障。
解决方案
为什么选择SSD
根据上述原因分析可知,解决目前痛点可从以下两个方向来考虑:
消除实时消费与延迟消费间的PageCache竞争,如:让延迟消费作业读取的数据不回写PageCache,或增大PageCache的分配量等。
在HDD与内存之间加入新的设备,该设备拥有比HDD更好的读写带宽与IOPS。
对于第一个方向,由于PageCache由操作系统管理,若修改其淘汰策略,那么实现难度较为复杂,同时会破坏内核本身对外的语义。另外,内存资源成本较高,无法进行无限制的扩展,因此需要考虑第二个方向。
SSD目前发展日益成熟,相较于HDD,SSD的IOPS与带宽拥有数量级级别的提升,很适合在上述场景中当PageCache出现竞争后承接部分读流量。我们对SSD的性能也进行了测试,结果如下图所示:

从图中可以发现,随着读取并发的增加,SSD的IOPS与带宽并不会显著降低。通过该结论可知,我们可以使用SSD作为PageCache与HDD间的缓存层。
架构决策
在引入SSD作为缓存层后,下一步要解决的关键问题包括PageCache、SSD、HDD三者间的数据同步以及读写请求的数据路由等问题,同时我们的新缓存架构需要充分匹配Kafka引擎读写请求的特征。本小节将介绍新架构如何在选型与设计上解决上述提到的问题。
Kafka引擎在读写行为上具有如下特性:
数据的消费频率随时间变化,越久远的数据消费频率越低。
每个分区(Partition)只有Leader提供读写服务。
对于一个客户端而言,消费行为是线性的,数据并不会重复消费。
下文给出了两种备选方案,下面将对两种方案给出我们的选取依据与架构决策。
备选方案一:基于操作系统内核层实现
目前开源的缓存技术有FlashCache、BCache、DM-Cache、OpenCAS等,其中BCache和DM-Cache已经集成到Linux中,但对内核版本有要求,受限于内核版本,我们仅能选用FlashCache/OpenCAS。
如下图所示,FlashCache以及OpenCAS二者的核心设计思路类似,两种架构的核心理论依据为“数据局部性”原理,将SSD与HDD按照相同的粒度拆成固定的管理单元,之后将SSD上的空间映射到多块HDD层的设备上(逻辑映射or物理映射)。在访问流程上,与CPU访问高速缓存和主存的流程类似,首先尝试访问Cache层,如果出现CacheMiss,则会访问HDD层,同时根据数据局部性原理,这部分数据将回写到Cache层。如果Cache空间已满,会通过LRU策略替换部分数据。

FlashCache/OpenCAS提供了四种缓存策略:WriteThrough、WriteBack、WriteAround、WriteOnly。由于第四种不做读缓存,这里我们只看前三种。
写入:
WriteThrough:数据写操作在写入SSD的同时会写入到后端存储。
WriteBack:数据写操作仅写入SSD即返回,由缓存策略flush到后台存储。
WriteAround:数据写入操作直接写入后端存储,同时SSD对应的缓存会失效。
读取:
WriteThrough/WriteBack/WriteAround:首先读取SSD,命中不了的将再次读取后端存储,并数据会被刷入到SSD缓存中。

更多详细实现细节,极大可参见这二者的官方文档:
FlashCache
OpenCAS
备选方案二:Kafka应用内部实现
上文提到的第一类备选方案中,核心的理论依据“数据局部性”原理与Kafka的读写特性并不能完全吻合,“数据回刷”这一特性依然会引入缓存空间污染问题。同时,上述架构基于LRU的淘汰策略也与Kafka读写特性存在矛盾,在多Consumer并发消费时,LRU淘汰策略可能会误淘汰掉一些近实时数据,导致实时消费作业出现性能抖动。
可见,备选方案一并不能完全解决当前Kafka的痛点,需要从应用内部进行改造。整体设计思路如下,将数据按照时间维度分布在不同的设备中,近实时部分的数据缓存在SSD中,这样当出现PageCache竞争时,实时消费作业从SSD中读取数据,保证实时作业不会受到延迟消费作业影响。下图展示了基于应用层实现的架构处理读请求的流程:

当消费请求到达Kafka Broker时,Kafka Broker直接根据其维护的消息偏移量(Offset)和设备的关系从对应的设备中获取数据并返回,并且在读请求中并不会将HDD中读取的数据回刷到SSD,防止出现缓存污染。同时访问路径明确,不会由于Cache Miss而产生的额外访问开销。
下表对不同候选方案进行了更加详细的对比:
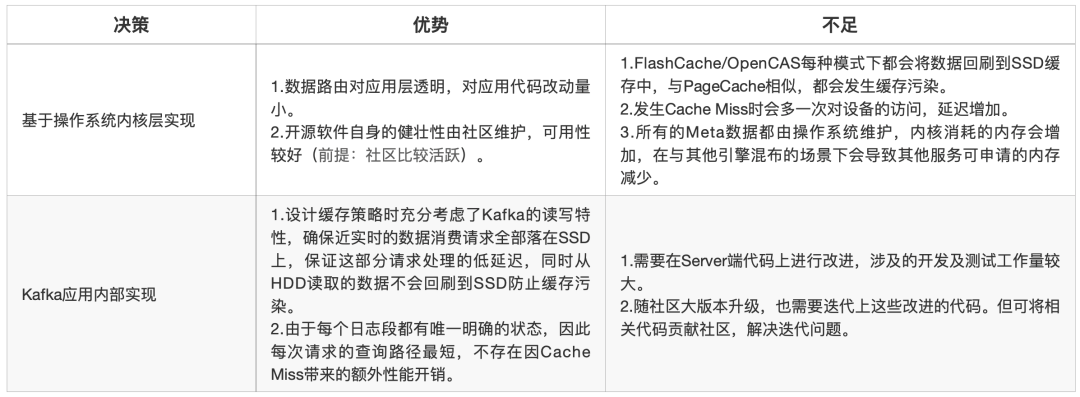
最终,结合与Kafka读写特性的匹配度,整体工作量等因素综合考虑,我们采用Kafka应用层实现这一方案,因为该方案更贴近Kafka本身读写特性,能更加彻底地解决Kafka的痛点。
新架构设计
概述
根据上文对Kafka读写特性的分析,我们给出应用层基于SSD的缓存架构的设计目标:
数据按时间维度分布在不同的设备上,近实时数据分布在SSD上,随时间的推移淘汰到HDD上。
Leader分区中所有数据均写入SSD中。
从HDD中读取的数据不回刷到SSD中。
依据上述目标,我们给出应用层基于SSD的Kafka缓存架构实现:
Kafka中一个Partition由若干LogSegment构成,每个LogSegment包含两个索引文件以及日志消息文件。一个Partition的若干LogSegment按Offset(相对时间)维度有序排列。

根据上一小节的设计思路,我们首先将不同的LogSegment标记为不同的状态,如图所示(图中上半部分)按照时间维度分为OnlyCache、Cached以及WithoutCache三种常驻状态。而三种状态的转换以及新架构对读写操作的处理如图中下半部分所示,其中标记为OnlyCached状态的LogSegment只存储在SSD上,后台线程会定期将Inactive(没有写流量)的LogSegment同步到SSD上,完成同步的LogSegment被标记为Cached状态。
最后,后台线程将会定期检测SSD上的使用空间,当空间达到阈值时,后台线程将会按照时间维度将距离现在最久的LogSegment从SSD中移除,这部分LogSegment会被标记为WithoutCache状态。
对于写请求而言,写入请求依然首先将数据写入到PageCache中,满足阈值条件后将会刷入SSD。对于读请求(当PageCache未获取到数据时),如果读取的offset对应的LogSegment的状态为Cached或OnlyCache,则数据从SSD返回(图中LC2-LC1以及RC1),如果状态为WithoutCache,则从HDD返回(图中LC1)。
对于Follower副本的数据同步,可根据Topic对延迟以及稳定性的要求,通过配置决定写入到SSD还是HDD。
关键优化点
上文介绍了基于SSD的Kafka应用层缓存架构的设计概要以及核心设计思路,包括读写流程、内部状态管理以及新增后台线程功能等。本小节将介绍该方案的关键优化点,这些优化点均与服务的性能息息相关。主要包括LogSegment同步以及Append刷盘策略优化,下面将分别进行介绍。
LogSegment同步
LogSegment同步是指将SSD上的数据同步到HDD上的过程,该机制在设计时主要有以下两个关键点:
同步的方式:同步方式决定了HDD上对SSD数据的可见时效性,从而会影响故障恢复以及LogSegment清理的及时性。
同步限速:LogSegment同步过程中通过限速机制来防止同步过程中对正常读写请求造成影响
同步方式
关于LogSegment的同步方式,我们给出了三种备选方案,下表列举了三种方案的介绍以及各自的优缺点:
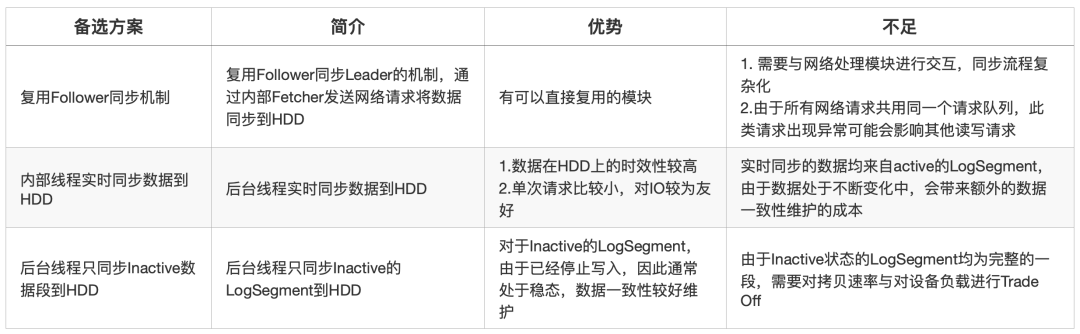
最终,我们对一致性维护代价、实现复杂度等因素综合考虑,选择了后台同步Inactive的LogSegment的方式。
同步限速
LogSegment同步行为本质上是设备间的数据传输,会同时在两个设备上产生额外的读写流量,占用对应设备的读写带宽。同时,由于我们选择了同步Inactive部分的数据,需要进行整段的同步。如果在同步过程中不加以限制会对服务整体延迟造成较大的影响,主要表现在下面两个方面:
从单盘性能角度,由于SSD的性能远高于HDD,因此在数据传输时,HDD写入带宽会被写满,此时其他的读写请求会出现毛刺,如果此时有延迟消费从HDD上读取数据或者Follower正在同步数据到HDD上,会造成服务抖动。
从单机部署的角度,单机会部署2块SSD与10块HDD,因此在同步过程中,1块SSD需要承受5块HDD的写入量,因此SSD同样会在同步过程中出现性能毛刺,影响正常的请求响应延迟。
基于上述两点,我们需要在LogSegment同步过程中增加限速机制,总体的限速原则为在不影响正常读写请求延迟的情况下尽可能快速地进行同步。因为同步速度过慢会导致SSD数据无法被及时清理而最终被写满。同时为了可以灵活调整,该配置也被设置为单Broker粒度的配置参数。
日志追加刷盘策略优化
除了同步问题,数据写入过程中的刷盘机制同样影响服务的读写延迟。该机制的设计不仅会影响新架构的性能,对原生Kafka同样会产生影响。
下图展示了单次写入请求的处理流程:

在Produce请求处理流程中,首先根据当前LogSegment的位置与请求中的数据信息确定是否需要滚动日志段,随后将请求中的数据写入到PageCache中,更新LEO以及统计信息,最后根据统计信息确定是否需要触发刷盘操作,如果需要则通过fileChannel.force强制刷盘,否则请求直接返回。
在整个流程中,除日志滚动与刷盘操作外,其他操作均为内存操作,不会带来性能问题。日志滚动涉及文件系统的操作,目前,Kafka中提供了日志滚动的扰动参数,防止多个Segment同时触发滚动操作给文件系统带来压力。针对日志刷盘操作,目前Kafka给出的机制是以固定消息条数触发强制刷盘(目前线上为50000),该机制只能保证在入流量一定时,消息会以相同的频率刷盘,但无法限制每次刷入磁盘的数据量,对磁盘的负载无法提供有效的限制。
如下图所示,为某磁盘在午高峰时间段write_bytes的瞬时值,在午高峰时间段,由于写入流量的上升,在刷盘过程中会产生大量的毛刺,而毛刺的值几乎接近磁盘最大的写入带宽,这会使读写请求延迟发生抖动。

针对该问题,我们修改了刷盘的机制,将原本的按条数限制修改为按实际刷盘的速率限制,对于单个Segment,刷盘速率限制为2MB/s。该值考虑了线上实际的平均消息大小,如果设置过小,对于单条消息较大的Topic会过于频繁的进行刷新,在流量较高时反而会加重平均延迟。目前该机制已在线上小范围灰度,右图展示了灰度后同时间段对应的write_bytes指标,可以看到相比左图,数据刷盘速率较灰度前明显平滑,最高速率仅为40MB/s左右。
对于SSD新缓存架构,同样存在上述问题,因此在新架构中,在刷盘操作中同样对刷盘速率进行了限制。
方案测试
测试目标
验证基于应用层的SSD缓存架构能够避免实时作业受到延迟作业的影响。
验证相比基于操作系统内核层实现的缓存层架构,基于应用层的SSD架构在不同流量下读写延迟更低。
测试场景描述
构建4个集群:新架构集群、普通HDD集群、FlashCache集群、OpenCAS集群。
每个集群3个节点。
固定写入流量,比较读、写耗时。
延迟消费设置:只消费相对当前时间10~150分钟的数据(超过PageCache的承载区域,不超过SSD的承载区域)。
测试内容及重点关注指标
Case1: 仅有延迟消费时,观察集群的生产和消费性能。
重点关注的指标:写耗时、读耗时,通过这2个指标体现出读写延迟。
命中率指标:HDD读取量、HDD读取占比(HDD读取量/读取总量)、SSD读取命中率,通过这3个指标体现出SSD缓存的命中率。
Case2: 存在延迟消费时,观察实时消费的性能。
重点指标:实时作业的SLA(服务质量)的5个不同时间区域的占比情况。
测试结果
从单Broker请求延迟角度看:
在刷盘机制优化前,SSD新缓存架构在所有场景下,较其他方案都具有明显优势。

刷盘机制优化后,其余方案在延迟上服务质量有提升,在较小流量下由于Flush机制的优化,新架构与其他方案的优势变小。当单节点写入流量较大时(大于170MB)优势明显。

从延迟作业对实时作业的影响方面看:
新缓存架构在测试所涉及的所有场景中,延迟作业都不会对实时作业产生影响,符合预期。

总结与未来展望
Kafka在美团数据平台承担统一的数据缓存和分发的角色,针对目前由于PageCache互相污染、进而引发PageCache竞争导致实时作业被延迟作业影响的痛点,我们基于SSD自研了Kafka的应用层缓存架构。本文主要介绍Kafka新架构的设计思路以及与其他开源方案的对比。与普通集群相比,新缓存架构具备非常明显的优势:
降低读写耗时:比起普通集群,新架构集群读写耗时降低80%。
实时消费不受延迟消费的影响:比起普通集群,新架构集群实时读写性能稳定,不受延时消费的影响。
目前,这套缓存架构优已经验证完成,正在灰度阶段,未来也优先部署到高优集群。其中涉及的代码也将提交给Kafka社区,作为对社区的回馈,也欢迎大家跟我们一起交流。
作者简介
世吉,仕禄,均为美团数据平台工程师。