
多模态中NLP和CV的融合方式汇总
点击上方,选择星标或置顶,每天给你送干货!
多种不同的信息源(不同的信息形式)中获取信息表达
表示(Multimodal Representation)的意思,比如shift旋转尺寸不变形,图像中研究出的一种表示
表示的冗余问题
不同的信号,有的象征性信号,有波信号,什么样的表示方式方便多模态模型提取信息
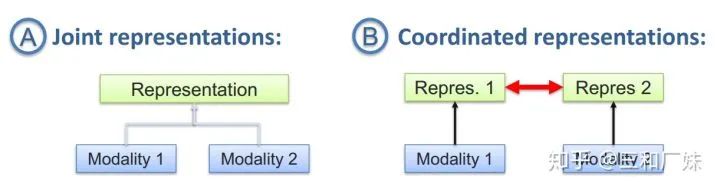
联合表示将多个模态的信息一起映射到一个统一的多模态向量空间
协同表示负责将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束。
信号的映射,比如给一个图像,将图像翻译成文字,文字翻译成图像,信息转化成统一形式后来应用
方式,这里就跟专门研究翻译的领域是重叠,基于实例的翻译,涉及到检索,字典(规则)等,基于生成方法如生成翻译的内容
多模态对齐定义为从两个或多个模态中查找实例子组件之间的关系和对应,研究不同的信号如何对齐(比如给电影,找出剧本中哪一段)
对齐方式,有专门研究对齐的领域,主要两种,显示对齐(比如时间维度上就是显示对齐的),隐式对齐(比如语言的翻译就不是位置对位置)
比如情感分析中语气和语句的融合等
这个最难也是被研究最多的领域,比如音节和唇语头像怎么融合,本笔记主要写融合方式
给定一张图片(视频)和一个与该图片相关的自然语言问题,计算机能产生一个正确的回答。这是文本QA和Image Captioning的结合,一般会涉及到图像内容上的推理,看起来更炫酷(不是指逻辑,就就指直观感受)。
Joint embedding approaches,只是直接从源头编码的角度开始融合信息,这也很自然的联想到最简单粗暴的方式就是把文本和图像的embedding直接拼接(ps:粗暴拼接这种方式很work),Billiner Fusion 最常用了,Fusion届的LR
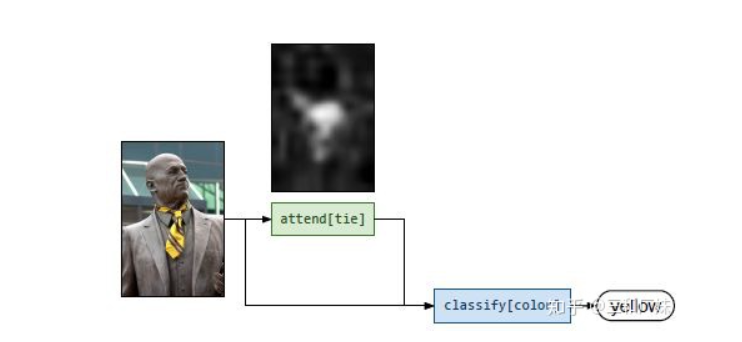
Attention mechanisms,很多VQA的问题都在attention上做文章,attention本身也是一个提取信息的动作,自从attention is all you need后,大家对attention的应用可以说是花式了,本文后面专门介绍CVPR2019的几篇
Compositional Models,这种方式解决问题的思路是分模块而治之,各模块分别处理不同的功能,然后通过模块的组装推理得出结果




作者:三和厂妹
三和,一个城市边缘贫瘠人群的栖息地。厂妹,在社会劳动中寻找价值的初心青年。目前在平安科技AI研究院做算法,主要感兴趣方向包括对话系统,知识图谱,文本搜索,推荐系统。三和什么都没有,厂妹也无知,所以每一个任务都是全新的开始。
知乎ID:三和厂妹

参考
Neural Module Networks
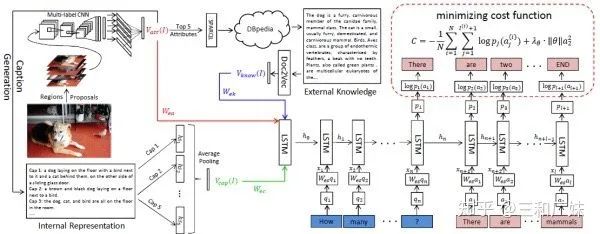
Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources
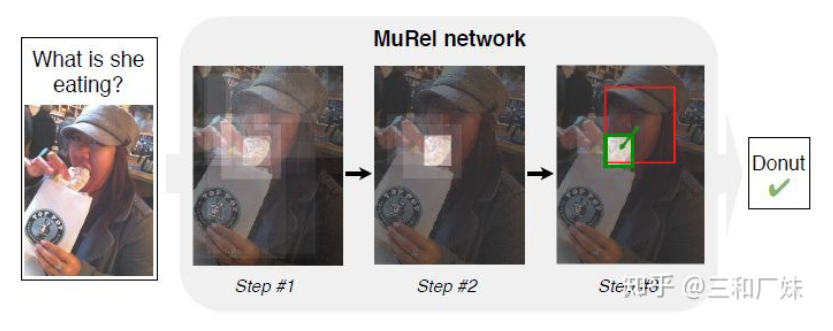
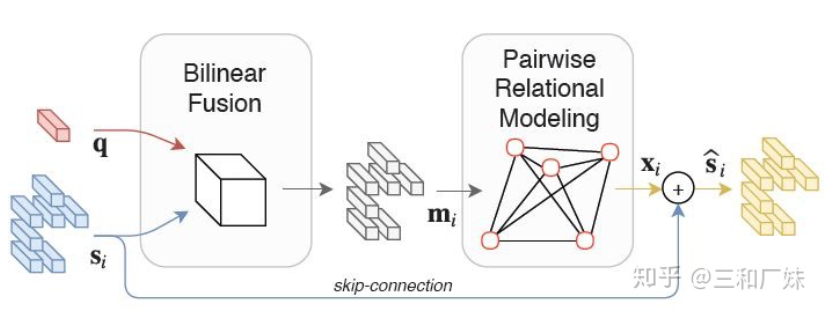
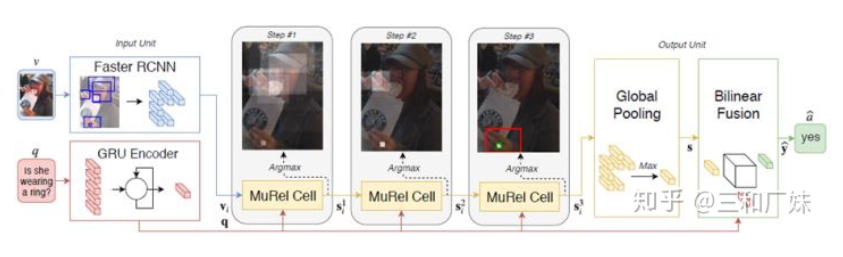
MUREL: Multimodal Relational Reasoning for Visual Question Answering
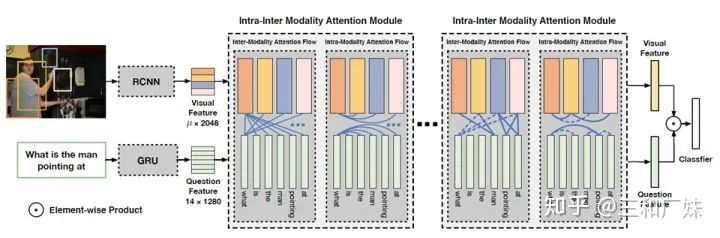
Dynamic Fusion with Intra- and Inter- Modality Attention Flow for Visual Question Answering
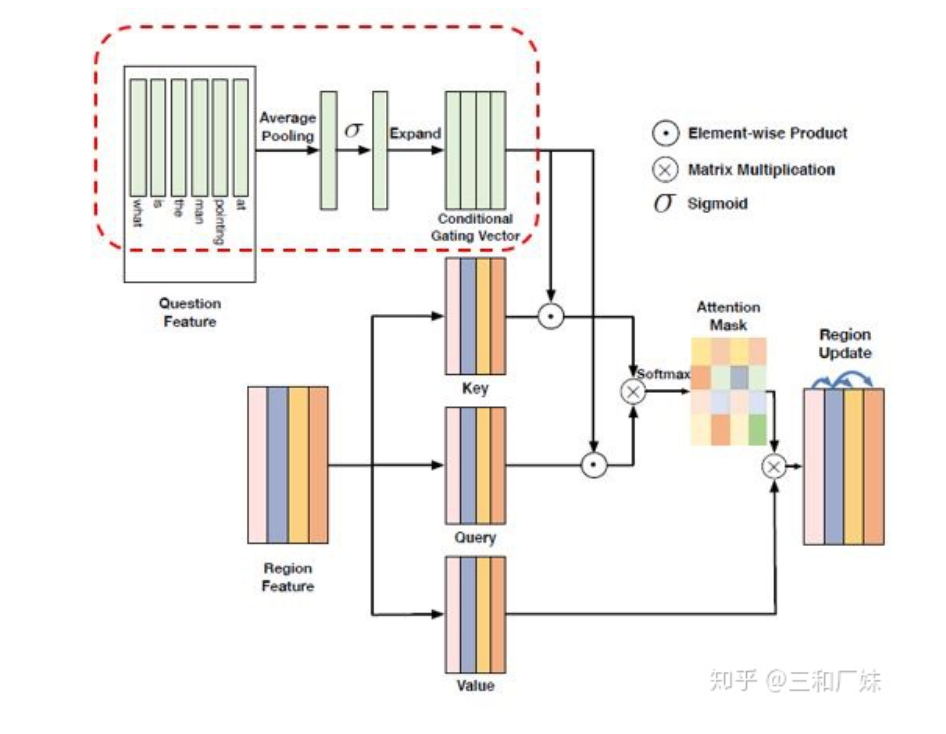
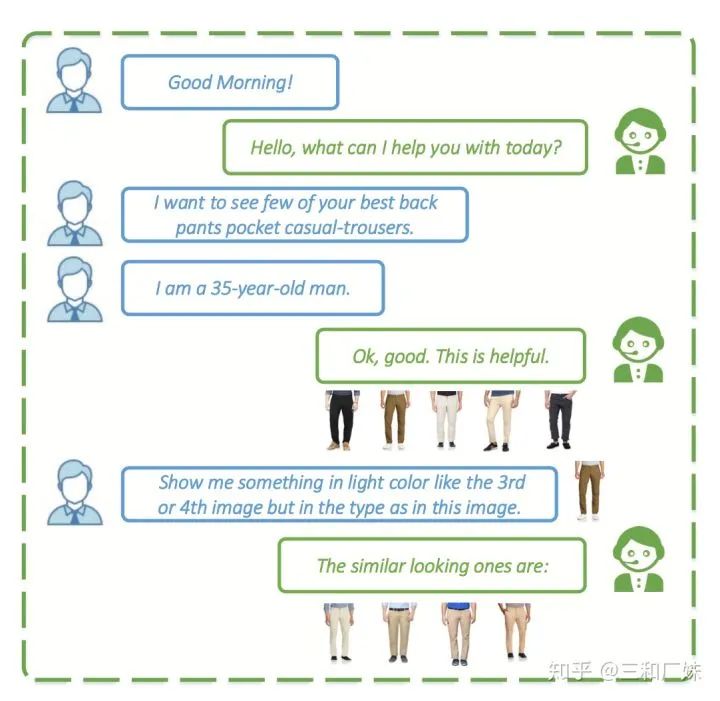
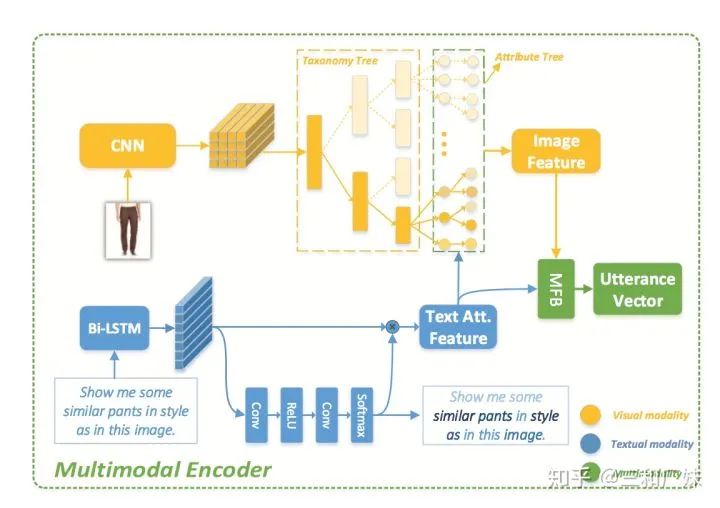
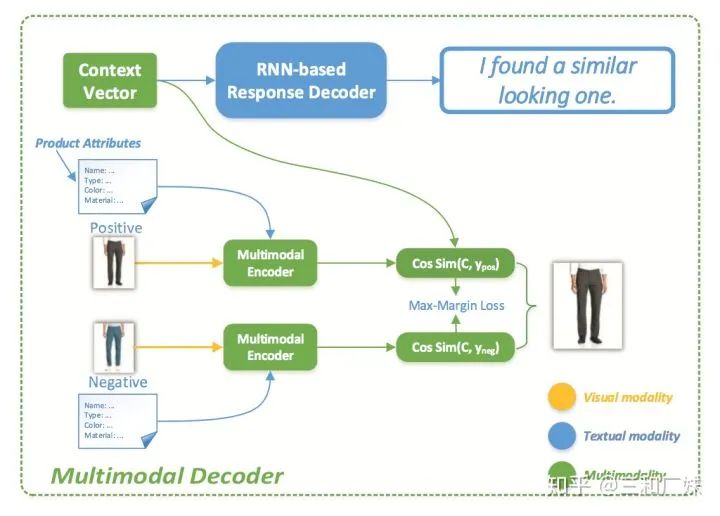
User Atention-guided Multimodal Dialog Systems
整理不易,还望给个在看!