
NVM原生数据库技术解读
为让更多数据库从业者了解数据库领域最新研究成果,熟悉行业前沿发展趋势,腾讯云数据库计划举办系列“DB · 洞见”活动,打造数据库技术交流平台,邀请学界及腾讯技术大咖,解读数据库基础技术创新趋势,分享数据库技术创新成果。
今天为大家带来“DB · 洞见”系列活动第一期的部分内容,由中国人民大学信息学院计算机科学与技术系主任柴云鹏教授解读NVM原生数据库技术,以下是分享实录:
NVM原生数据库概述
今天我分享的主题为“NVM原生数据库技术”,内容分三个部分,主要涉及到下面这五篇VLDB 2021的论文。首先我先来介绍下NVM原生数据库整体的情况。
 1.1 NVM原生数据库发展状况
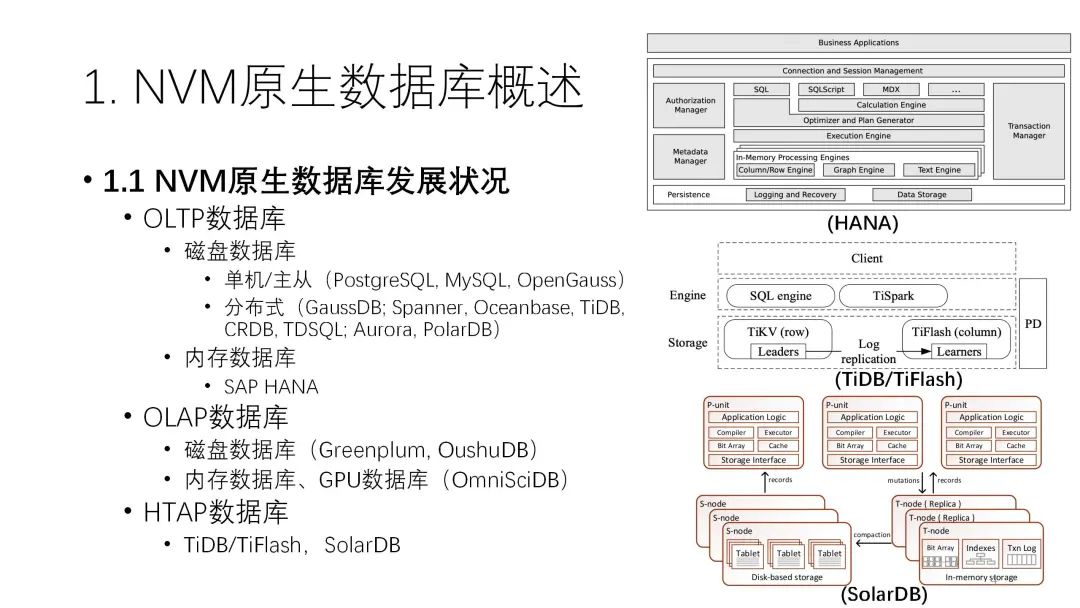
1.1 NVM原生数据库发展状况现有的数据库系统可以分成OLTP数据库、OLAP数据库和HTAP数据库。
OLAP数据库传统上一直是以磁盘数据库为主,即使到现在很多地方都以SSD为主,但还是采用磁盘数据库技术。从早期的单机架构发展到分布式,从主从到现在的存算分离,磁盘数据库发展出了很多优秀数据库产品,是发展的最快的领域。另外一个分支则是比较高端的内存数据库或一体机,比较典型的就是HANA系统。磁盘数据库和内存数据库的产品区分很明确,定位的场景、价格、容量各方面差距都很大。
OLAP数据库方面也是类似的情况,因为大数据分析的量比较大,还是以磁盘数据库为主。少部分的内存或者GPU数据库速度比较快,但数据规模特别小,所以实际上使用范围也不是特别大。HTAP数据库也一样,传统上也是分磁盘和内存两种介质。
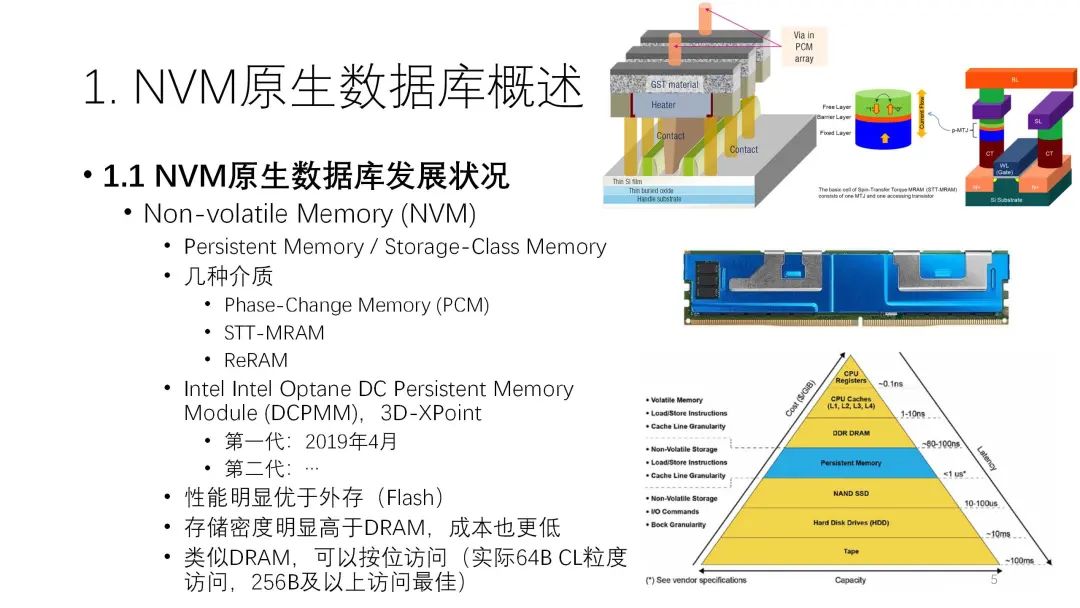
NVM即非易失内存是近年来新出现的介质。严格来说,NVM指的不是一种介质,而是一系列的介质,包括PCM相变存储器、STT-MRAM、ReRAM忆阻器等,这些介质之间也有很大的差别。NVM产品真正推出是在2019年,由英特尔公司研发,目前已经有了第二代产品。
NVM从性质上看介于磁盘和内存两者之间,性能明显优于外存,存储密度高于DRAM,成本也更低。此外,它还类似于DRAM,可以按位访问,最小的粒度一般还是256B。
NVM这种介质如果后续逐渐成熟,对整个数据库产品会有很大的意义。基于现在的内存数据库或者重新定制NVM原生的数据库,它可以达到内存数据库的性能,而且可以扩展内存空间,达到一个数量级左右,同时也可以帮助OLTP、OLAP、或者HTAP数据库降低成本,数据规模也可以上得去,做得更实用。
但它也带来了很多挑战。首先,因为NVM是一个全新的东西,它既像内存又像外存,可以当成内存去用,但现在不能直接的保持持久化,必须要加额外的汇编指令,如果把它当成外存又好像浪费了它的某些属性,这种情况下怎么去用它就是一个问题。其次,数据库传统当中各个核心模块的技术研究了几十年,如果应用到NVM上就有很多模块需要重新设计。最后,这些年新出的存储性硬件的特性都很强,但NVM介质还存在很多问题,要如何去适应硬件的特性也是个问题。
 目前对于NVM的研究还处于模块化阶段,还不够完善,还没有真正比较大规模、比较实用的产品出现,当前的研究主要集中在以下几个方面:
目前对于NVM的研究还处于模块化阶段,还不够完善,还没有真正比较大规模、比较实用的产品出现,当前的研究主要集中在以下几个方面:首先是最流行的NVM索引研究,在NVM设备出来之前就已经有人在研究了。索引里又可分为几种:第一种是比较快速的Hash索引,但是它不支持范围查询,所以数据库里一般还是有序索引比较多;第二种是基于B-Tree的索引;第三种是基于前缀树的索引;第四种是基于LSM Tree即日志结构合并树的索引,很多人认为从原理上讲它不是很适合NVM,但因为LSM Tree确实有自己的优势,比如说写操作比较好、访问连续、利于压缩,同时NVM的特性又没有想象中那么接近于内存,它的连续和随机写之间差别比较大,所以慢慢很多人也开始研究LSM Tree的NVM化,就是把SSD/NVM都加到这里面,做成一个更大容量但性能比SLM Tree引擎好很多的索引;最后一种是混合索引,即用DRAM加上NVM,它们之间的配合可能是多个索引,也可能是拼接索引,虽然这方面的研究不是特别主流,但因为DRAM性能远远好于NVM,因此混合还是有意义的。
其次是空间的分配,因为NVM和DRAM有很大差别,它多了一个空间分配。再者是日志和恢复,因为NVM本身是关于持久化的,所以NVM的按位访问,它的一种介质既可以持久化,又可以非持久化,这就会带来很大差别。最后是缓冲区。
 1.2 NVM硬件特性:现在与未来
1.2 NVM硬件特性:现在与未来这部分主要是借助VLDB的这篇论文来介绍现在的NVM产品,以及畅想未来的NVM产品的特性。首先我们先来了解下目前NVM的硬件特性,这些都是业界认可的。
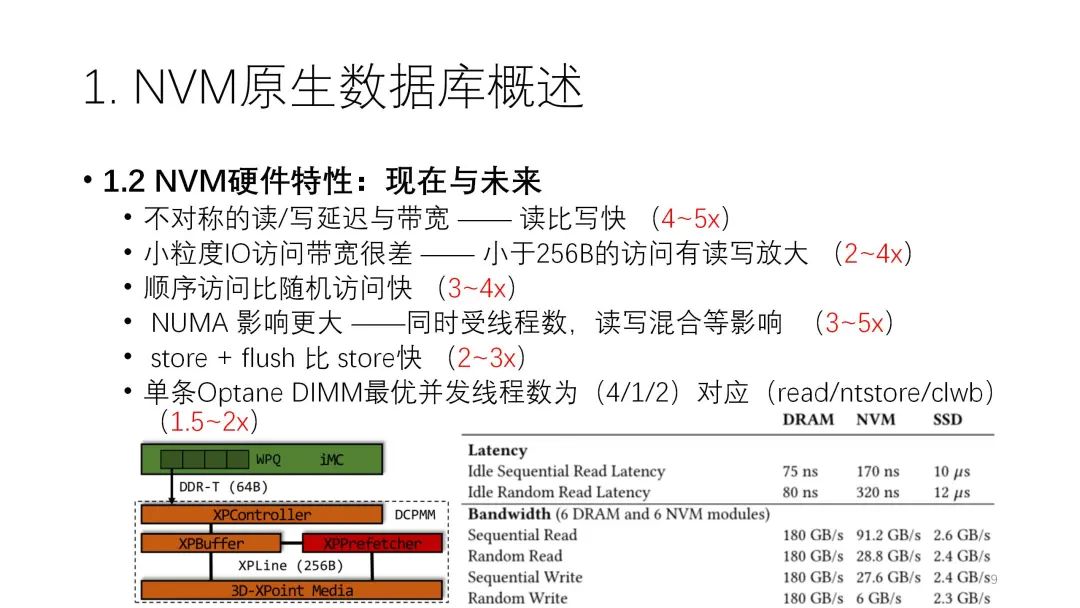 下面我们就这篇论文来详细分析。该论文总结了NVM硬件的七个特征,并简单介绍了它的特征以及主要原因,还有适用哪几类NVM的类型。
下面我们就这篇论文来详细分析。该论文总结了NVM硬件的七个特征,并简单介绍了它的特征以及主要原因,还有适用哪几类NVM的类型。注:下图中的C1指的是比较早的NVM硬件,上面的介质还是DRAM,只是加了电池或电容。C2、C3是假想的,即假设某些产品用了一些cache和预取器,在这种情况下看各个特征是不是对每一类都适用。C4指的是英特尔已经推出的产品。

前两类都是读写不平衡,store指的是持久化的store,它的延迟和带宽都不匹配。首要的原因是介质的影响,我们现在用的3D XPoint或者PCM实际上就是读快写慢。此外,在延迟方面也和CPU的缓存有很大的关系。
在带宽方面,除了介质的原因外,控制器相关的征用对一些资源也有影响。在数据DRAM中,读的带宽能到76G/s,写的带宽能到42G/s,两者有一定差别,但不是很大。但到了NVM,读是30G/s,写大概是8G/s,差别就比较大。在读写差异这一点上,NVM比内存放大很多,是2.5倍和5.2倍的差别。

 从访问粒度来看,从小到大,性能带宽应该是逐渐提高的,到256B之后基本逐渐比较稳定,但是到4K一般会有下滑,再后面就基本比较稳定。到4K比较差的原因是内部有interleave。一般情况下,一个CPU可以放6条NVM,它会做interleave即并行化,这个力度是4K。如果都是4K,很多访问可能就会在各个通道上负载不均衡,从而导致性能有一定下滑。
从访问粒度来看,从小到大,性能带宽应该是逐渐提高的,到256B之后基本逐渐比较稳定,但是到4K一般会有下滑,再后面就基本比较稳定。到4K比较差的原因是内部有interleave。一般情况下,一个CPU可以放6条NVM,它会做interleave即并行化,这个力度是4K。如果都是4K,很多访问可能就会在各个通道上负载不均衡,从而导致性能有一定下滑。 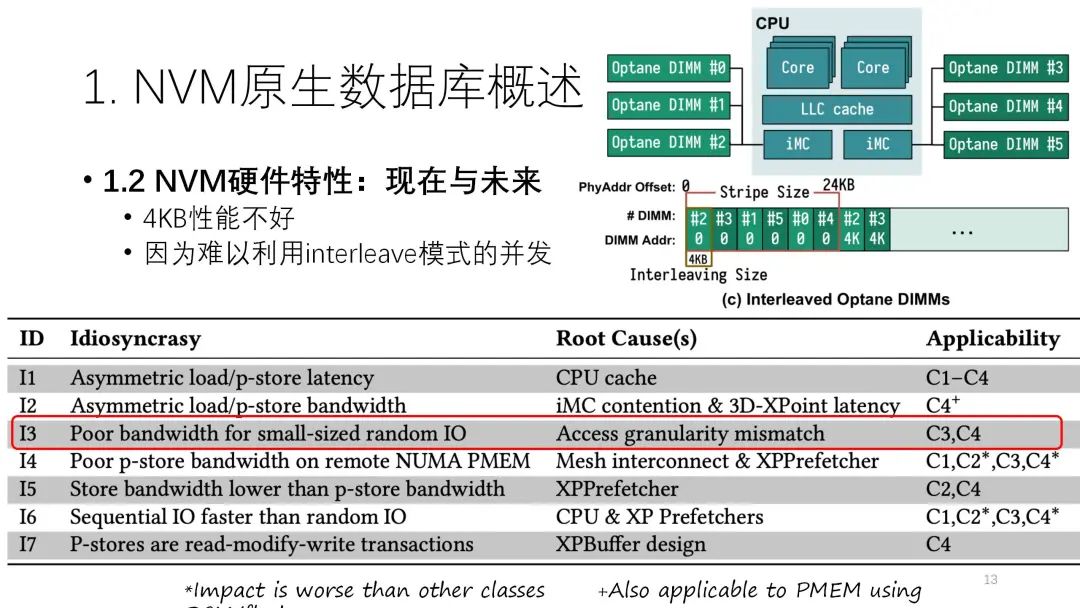 第四类就是NUMA影响更大。下图的测试中,上面是内存的NUMA访问和普通访问之间的性能差异,下面则是NVM的NUMA访问和普通访问之间的性能差异。绿色表示差异不大,颜色越深越蓝说明差异越大。从图上看,NVM的NUMA访问明显更差。原因则和NVM之间的连接以及预取器有关。
第四类就是NUMA影响更大。下图的测试中,上面是内存的NUMA访问和普通访问之间的性能差异,下面则是NVM的NUMA访问和普通访问之间的性能差异。绿色表示差异不大,颜色越深越蓝说明差异越大。从图上看,NVM的NUMA访问明显更差。原因则和NVM之间的连接以及预取器有关。
 第五类是有时store的带宽比持久化的p-spore还要小。
第五类是有时store的带宽比持久化的p-spore还要小。

第六类是连续访问和随机访问比较快。
最后一类是NVM的并发度有较大的限制。内存能够支持的并发数量比较大,它的性能比较好。但是NVM就不同,读和写的并发度并不一致。
 这篇文章也给了部分建议:避免持久化的写,适度的、按照硬件特征的并发,避免特别小的I/O,要限制NUMA访问,尽量避免随机I/O和避免transactions等。但是要在实际系统中去用好这些NVM的特性也并非容易。
这篇文章也给了部分建议:避免持久化的写,适度的、按照硬件特征的并发,避免特别小的I/O,要限制NUMA访问,尽量避免随机I/O和避免transactions等。但是要在实际系统中去用好这些NVM的特性也并非容易。 
NVM原生数据库核心技术
2.1 NVM索引技术
索引方面的研究是最多的,最主流的是基于B+树、B树或前缀树这种树型结构的有序索引,这个对数据库来说可能更重要些。
NVM索引技术的研究前几年做得比较多,大体的研究思路是:树形结构里,最下面一层放到NVM里,前面的中间节点放在DRAM,这样可以减少一些NVM的写入,恢复的时候可以通过最下面一层再把上面一层恢复出来,利用这些减少写来提升性能。
这篇论文实际上是对NVM内存上的哈希索引做了一个比较全面的测评,他选了六种比较常见的、比较新的结构,分别是Level Hash、Clevel Hash、CCEH、Dash、PCLHT、SOFT六个索引。接下来我们先介绍下这六种技术。

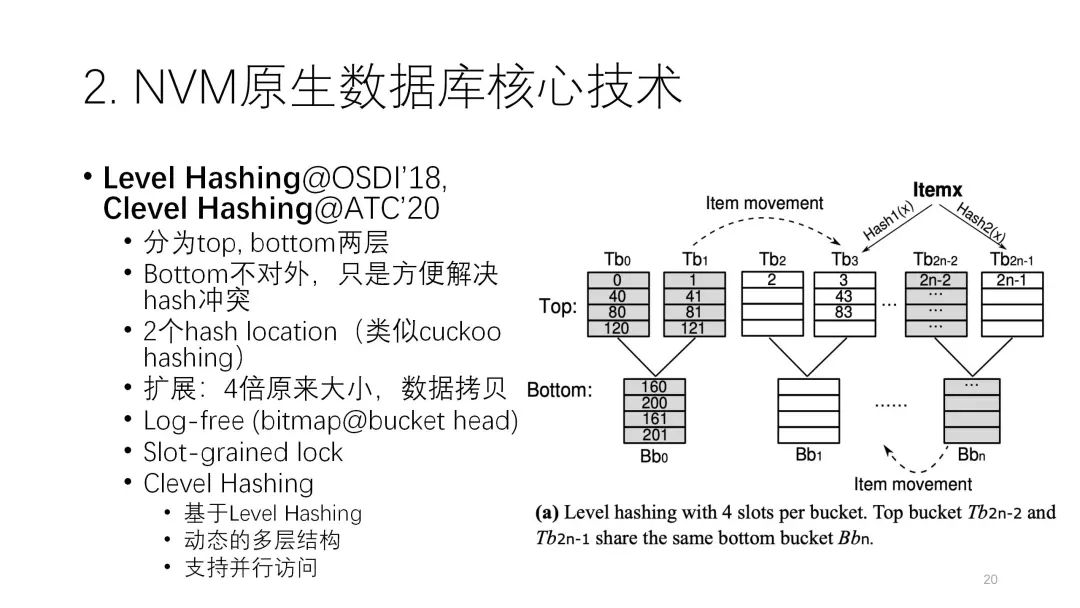
首先,Level Hash和Clevel Hash实际上是一个系列工作,最大的特征是减少和解决哈希冲突。最上面这一层是正常的桶,每两个后面可以加一个bottom层的桶,这个的好处在于,一开始下面的桶是空的,一旦冲突了就可以利用下面的桶往里放。因为冲突的情况不是特别频繁,所以它的容量比上面正常TOP层的要少一半,关键是左右两个分支都可以共用这样的结构。这就从空间利用上和减小哈希冲突的开销上起到了trade off的作用。
Clevel Hash也是类似的,可能是更深层次和动态决定的多层结构。上面也用了哈希,有两个哈希尽可能的减少冲突,涉及了log-free这种slot级别的锁来优化它。
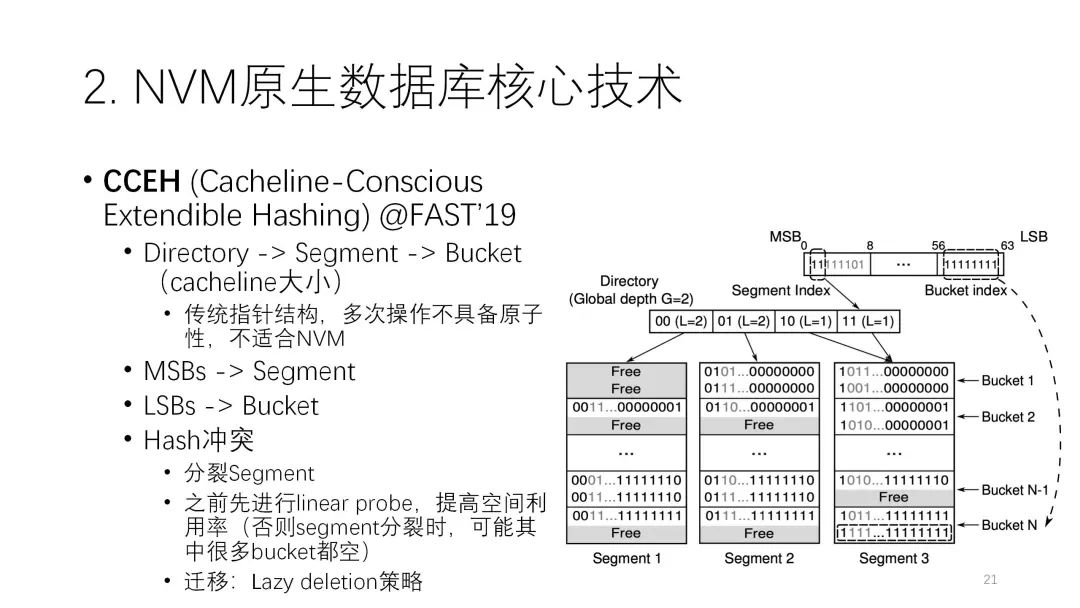
 第三个CCEH是FAST19的研究,是Cache Line相关的可扩展的索引。传统上这种Extendible Hash 已经有比较多的研究,它的架构都是有目录,再连到下面的数据。但这种传统结构的指针比较多,而指针在NVM上并不是很友好。指针的更新是比较小粒度的随机写,可能数据量不大,但对NVM的开销比较大,所以传统结构不太适合NVM。因此它做了一个比较大的改进,改成了一个更简单的结构,就是三层的结构,directory、segment、bucket。下图中大的是segment,里面一行行的是一个个的bucket,每个Key里通过最前面的这部分来确定是哪个segment,通过后面来确定bucket。
第三个CCEH是FAST19的研究,是Cache Line相关的可扩展的索引。传统上这种Extendible Hash 已经有比较多的研究,它的架构都是有目录,再连到下面的数据。但这种传统结构的指针比较多,而指针在NVM上并不是很友好。指针的更新是比较小粒度的随机写,可能数据量不大,但对NVM的开销比较大,所以传统结构不太适合NVM。因此它做了一个比较大的改进,改成了一个更简单的结构,就是三层的结构,directory、segment、bucket。下图中大的是segment,里面一行行的是一个个的bucket,每个Key里通过最前面的这部分来确定是哪个segment,通过后面来确定bucket。它解决哈希冲突的最原始版本就是,当冲突时把segment翻倍,再扩大一个segment,这样第二个冲突就可以写到后面新的segment里,这种叫Extendible,它可以很灵活地扩展哈希表的空间。但如果直接用也会产生问题,为了一个bucket冲突去扩展segment,那这个segment上下会有很多空置,平均算下来空间利用率很低。所以这里也做了一些改进,先去做探索,尽可能提高segment里的空间利用率,实在不行再去做扩展,也有一些lazy的策略减少开销。
 第四个Dash是VLDB2020的研究,基本结构和CCEH相似,但它针对CCEH空间利用率较低的问题做了改进,主要是三个技术:第一个是Balanced insert,指每次插入的位置实际上有多个选择,这样就降低了冲突的概率;第二个是Displacement,指如果b和b+1这两个都满了,就可以调整,这样就减少一些冲突;第三个是Stash,指最后有两个隐藏的空间,如果这个segment实在是调不开,那就可以利用隐藏的空间存,这在一定程度上也可以减少segment再扩展的频率,每个segment可以相对压得更实一点,提高空间利用率,后面的实验结果也可以看出,它这方面比CCEH强。
第四个Dash是VLDB2020的研究,基本结构和CCEH相似,但它针对CCEH空间利用率较低的问题做了改进,主要是三个技术:第一个是Balanced insert,指每次插入的位置实际上有多个选择,这样就降低了冲突的概率;第二个是Displacement,指如果b和b+1这两个都满了,就可以调整,这样就减少一些冲突;第三个是Stash,指最后有两个隐藏的空间,如果这个segment实在是调不开,那就可以利用隐藏的空间存,这在一定程度上也可以减少segment再扩展的频率,每个segment可以相对压得更实一点,提高空间利用率,后面的实验结果也可以看出,它这方面比CCEH强。 
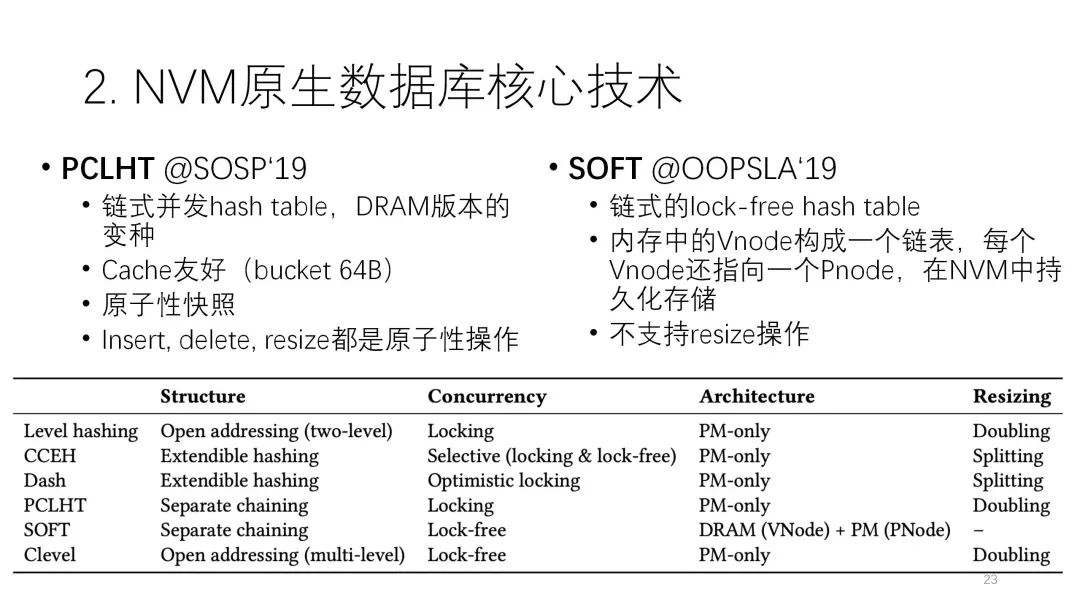
最后两个都是链式的哈希表。PCLHT是链式的并发哈希,它原来有DRAM的版本,后面做了NVM的改进,包括对cache的友好,原则性的访问等等。SOFT的特点是,有VM的部分,也有NVM的部分,它的数据在这两边都会存。
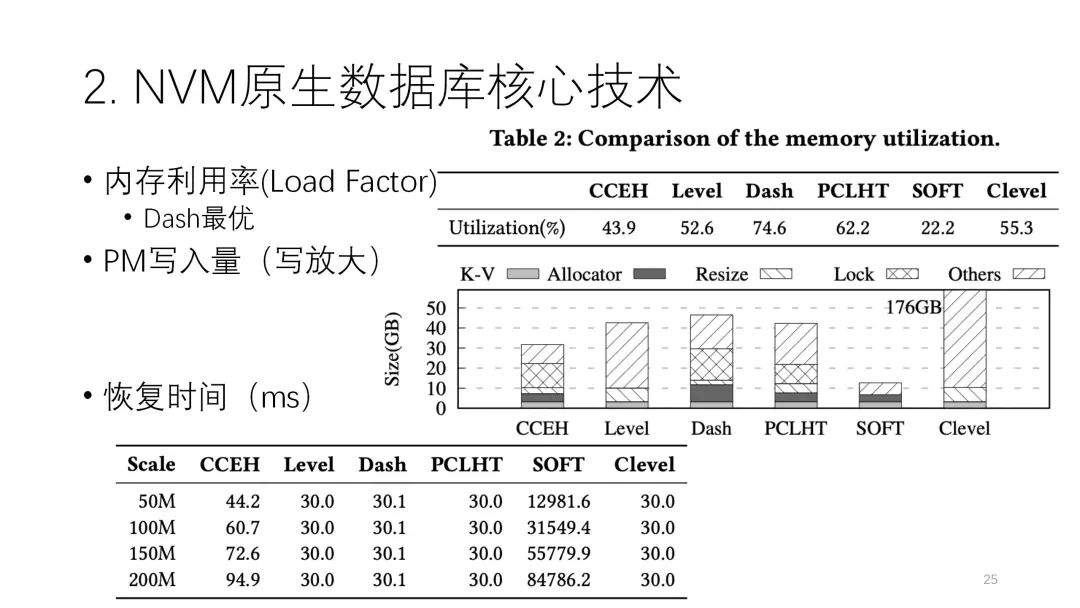
 下图是这篇论文测评结果。从图中可以看出,左边是Uniform分布,左边是倾斜分布,中间这两个是读和写的情况。读的操作里,这几个索引都不错,但还是链式的PCLHT,它的性能是相对比较好,在这里面比较突出。写的方面是SOFT,CCEH比较好。写的性能影响到PM的写放大,每个索引和原始的写操作比起来,写放大都很多,写放大的多少直接影响到它的性能,包括resize,整体来看还是这个各种情况下相对比较好,像CCEH、Dash这些确实是优秀的。
下图是这篇论文测评结果。从图中可以看出,左边是Uniform分布,左边是倾斜分布,中间这两个是读和写的情况。读的操作里,这几个索引都不错,但还是链式的PCLHT,它的性能是相对比较好,在这里面比较突出。写的方面是SOFT,CCEH比较好。写的性能影响到PM的写放大,每个索引和原始的写操作比起来,写放大都很多,写放大的多少直接影响到它的性能,包括resize,整体来看还是这个各种情况下相对比较好,像CCEH、Dash这些确实是优秀的。 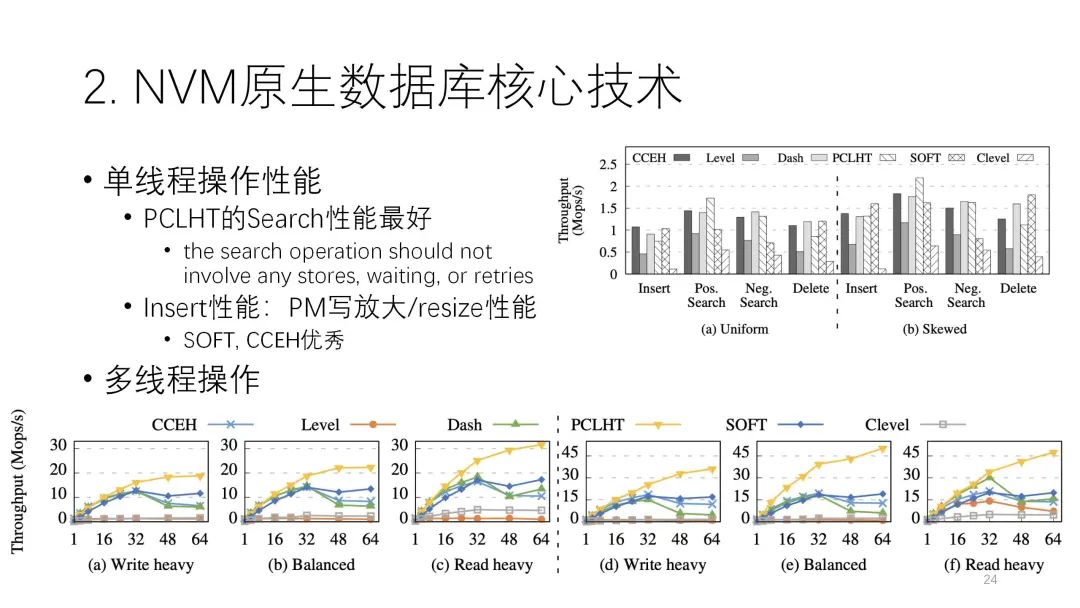
下图中这个值代表内存利用率。Dash也是基于CCEH做了空间的改进,确实是最优。中间这个图是它的PM写放大,最下面这个灰色的是它原始的写入,其他的都是放大出来的,所以可以很清楚地看到谁放大得比较多,像SOFT、CCEH这两个写放大比较少,所以它的性能确实是比较好。
在恢复时间上这几个都差不多,只有SOFT有点差,这方面是它典型的劣势,且SOFT没办法扩展,现在还不是特别实用,但其他几个索引还是不错的。
 这篇文章也总结了以下经验,这些不一定局限在哈希,在更大的范围内都是有效的。
这篇文章也总结了以下经验,这些不一定局限在哈希,在更大的范围内都是有效的。  2.2 NVM日志技术
2.2 NVM日志技术第二部分介绍日志技术。日志传统上采用的是WAL,它的好处有很多,首要的是可以更好地利用buffer。我们写入设备主要是连续写,性能还是不错的,但缺点是数据和日志要写两遍,这个会有一定的开销。
这方面之前比较经典的研究是VLDB 2016 的WBL,它和WAL是相反的两种很典型的技术。它最大的诉求是只写一遍。为了达到这个目标,它把日志缩得很小,只有一些元信息和时间信息,而数据不用放到日志里。数据再读完后直接写到下面持久化的设备里,上面是volatile,下面是durable,它实际上是写完buffer之后先写数据,但是是以MVCC的方式去写。当一个数要提交的时候,必须保证是写到数据表里,这时数据才能提交。这样的话,写放大明显减少了,带来更大的好处是,因为数据不在日志里,是在表里,不用扫数据,也不用去重构,所以它的回来时间可以忽略不计,速度达到上百倍的提升。
今天介绍的这两篇论文,实际上在事务、日志和恢复这方面都是沿着WBL的思路,但也会有一些新的东西。
 陈世敏老师团队的这篇论文,主要针对的是:假设用NVM构建OLTP数据库,实际上会面临三个比较大的性能挑战。
陈世敏老师团队的这篇论文,主要针对的是:假设用NVM构建OLTP数据库,实际上会面临三个比较大的性能挑战。第一个是元数据要进行频繁的修改,尤其是在事务执行过程中为了进行闭环控制,需要有很多元数据的修改。传统上我们会把元数据持久化保存到持久化设备中,比如说NVM里,带来的小粒度随机写是很多的,这个是很大的性能开销。第二个是WAL的数据、日志写两遍的问题。第三个则是WAL的空间分配有其特殊的问题。
DRAM的空间分配之所以简单,是因为当DRAM真正宕机去恢复的时候,实际上系统是从空的开始,只需要从日志里构建内存的东西就行。但是在NVM里,它的数据是非易失的,所以当它重启后,里面的数据是直接去用的,而不是播放一遍日志去重建,所以这时每个分配出来的空间到底用没用,一定要把元数据弄清楚,不然就会出现空间的泄露或者是不一致。
 接下来这篇论文总结了NVM数据库的四种架构:
接下来这篇论文总结了NVM数据库的四种架构:第一种是基于传统的内存数据库扩展,比如用部分NVM空间去扩展这些内存的空间,因为NVM可以当成易失的模式,还有一部分NVM当成非易失的模式,用来存日志,这是一个简单又典型的思路,也能基于现有的内存数据库的代码进行继承和修改。
但是它有两个缺点:第一个缺点是有三份重复写,除了传统WAL和checkpoint这两部分外,volatile的NVM也充当DRAM的角色,但是它的写实际上要比DRAM要慢,所以一个数据可能先要写到这边,然后再写到日志里,它的写放大会更严重。第二个缺点是数据规模在增大的时候,DRAM起的作用会越来越小,主要还是NVM来起作用,所以它的性能会随着使用下降,由NVM来去制约。
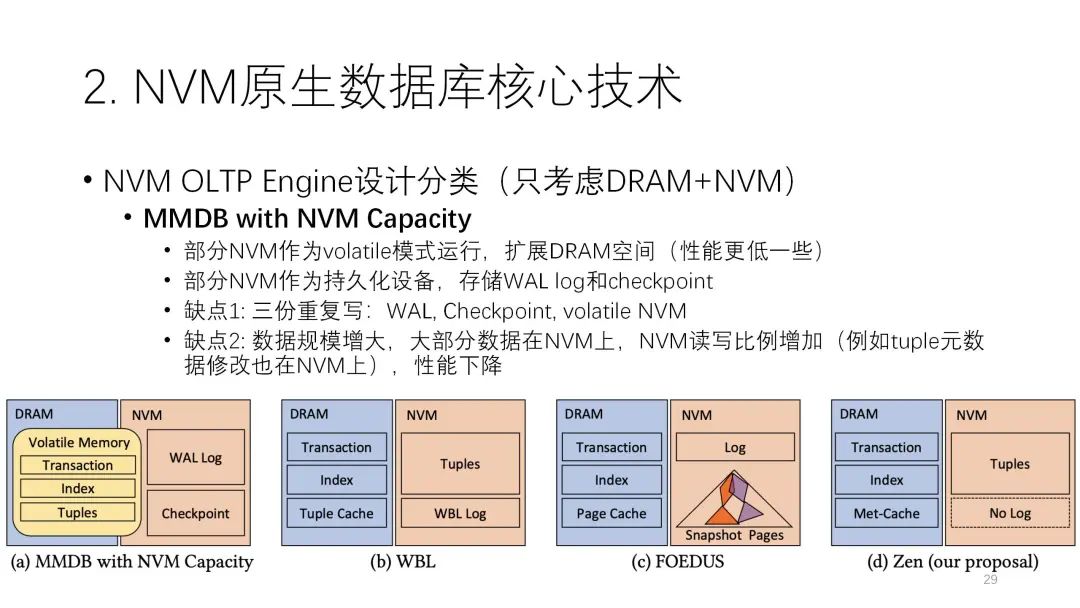 第二种是WBL,它基本上没什么日志,主要都是在数据里。
第二种是WBL,它基本上没什么日志,主要都是在数据里。第三种是WAL,每一个数据有两个指针,一个指向内存里的page cache,一个指向NVM当中的快照,cache有的就从这读,没有的从快照里读,从日志的角度看还是WAL,但它的性能相对是比较差的。
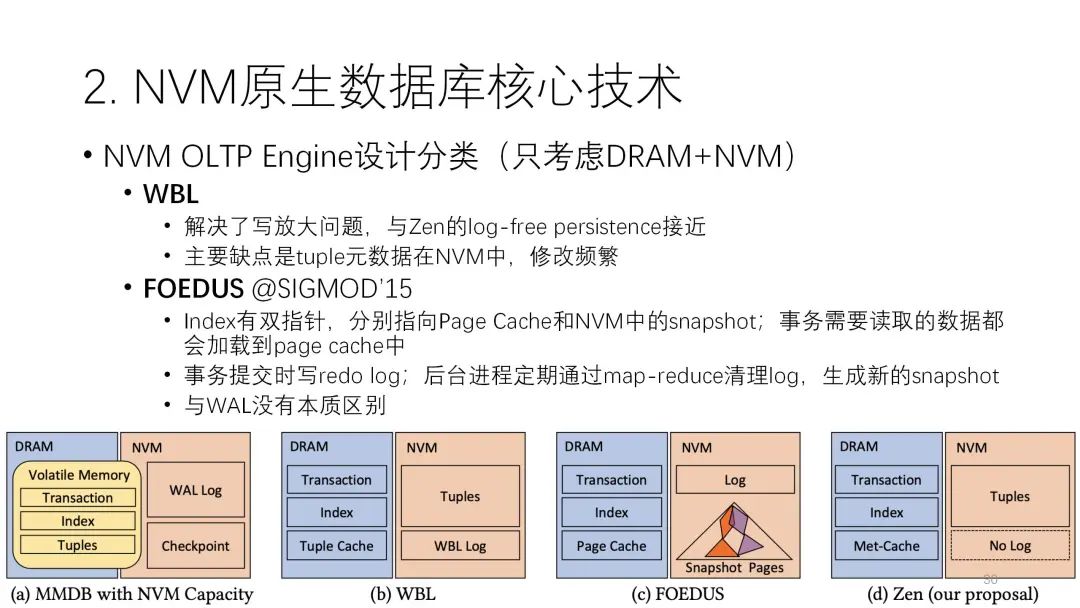 第四种是论文提出来的架构,和WBL架构有些接近。接下来我将介绍它的几个技术。
第四种是论文提出来的架构,和WBL架构有些接近。接下来我将介绍它的几个技术。第一个重要的技术是matcache in DRAM,就是要尽可能的把DRAM的性能用好。它存储的形式是:DRAM的索引不持久化,全在DRAM里,很多元数据也都在这里面,包括分配器的元数据,尽量把内存的空间用完,全都用做缓存,NVM里只存少量的元数据还有正常的表。前面说的tuple的元数据在控制过程中用到的元数据的修改,实际上都可以在内存里进行,这样性能就会好很多,可以减少很多NVM的写入。
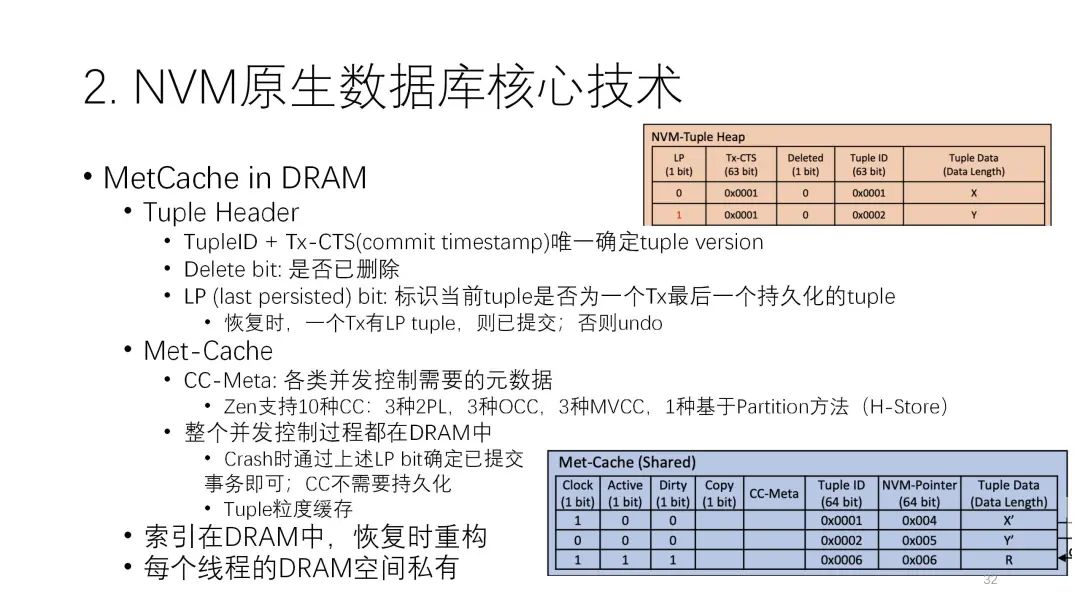 第二个重要的技术是在每一条NVM的进入里都有一个LP bit,它可能是0或者1,其作用很重要。当一个事务在提交时有多条记录,但前面的每一条都是0,只有到最后一条时它的LP bit才是1。这样的好处是,当中间突然宕机的时候,如果发现这个事务号只有0没有1,说明这个事务没有完成,那这条数据就可以忽略不计了。但如果发现这条事务有1,那说明前面的都写完了,自然这个事务就是一个已经完成的事务,恢复时就可以把这个当成是一个提交的事务去做。通过这样的机制就做成了log-free的结构。
第二个重要的技术是在每一条NVM的进入里都有一个LP bit,它可能是0或者1,其作用很重要。当一个事务在提交时有多条记录,但前面的每一条都是0,只有到最后一条时它的LP bit才是1。这样的好处是,当中间突然宕机的时候,如果发现这个事务号只有0没有1,说明这个事务没有完成,那这条数据就可以忽略不计了。但如果发现这条事务有1,那说明前面的都写完了,自然这个事务就是一个已经完成的事务,恢复时就可以把这个当成是一个提交的事务去做。通过这样的机制就做成了log-free的结构。
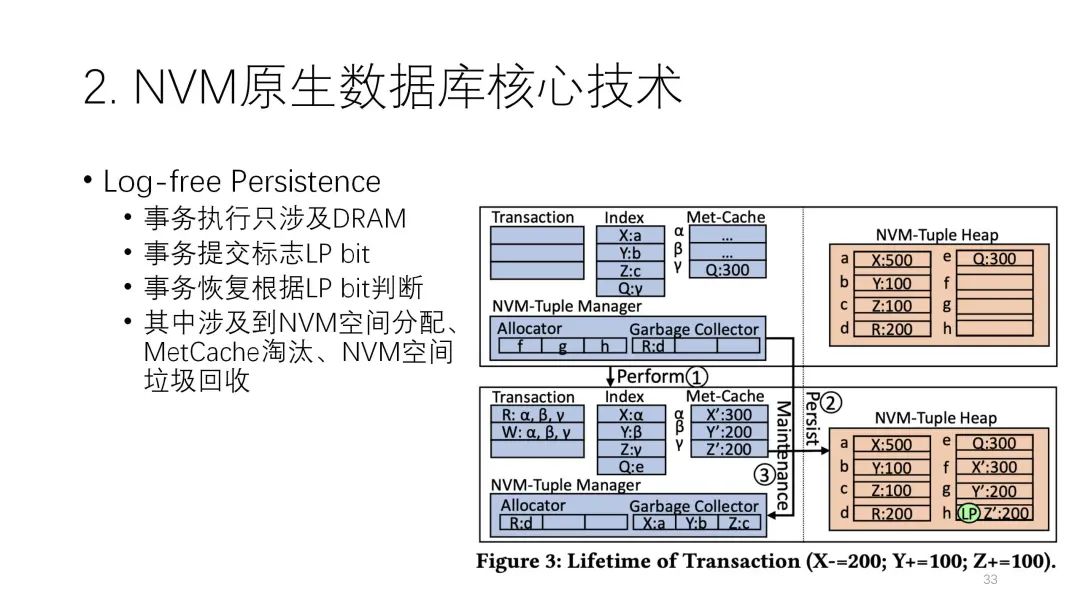 第三个重要的技术是空间管理。它分了两层,一个是配置级别的,按照固定大小来分。另一个则是按照Tuple来分,且Tuple实际上不需要在NVM里保存元数据,用DRAM就行,起来时都依靠恢复去做。
第三个重要的技术是空间管理。它分了两层,一个是配置级别的,按照固定大小来分。另一个则是按照Tuple来分,且Tuple实际上不需要在NVM里保存元数据,用DRAM就行,起来时都依靠恢复去做。  实际上论文提出的Zen架构在本质上有点像交换。它在恢复时做的事情比较多,要扫描整个数据,并且扫一遍还不行,必须扫一遍多。但是WBL技术可以做到基本不用扫数据,它实际上也是一种交换。下图种绿色的是Zen,它的性能基本上都是最好的。
实际上论文提出的Zen架构在本质上有点像交换。它在恢复时做的事情比较多,要扫描整个数据,并且扫一遍还不行,必须扫一遍多。但是WBL技术可以做到基本不用扫数据,它实际上也是一种交换。下图种绿色的是Zen,它的性能基本上都是最好的。 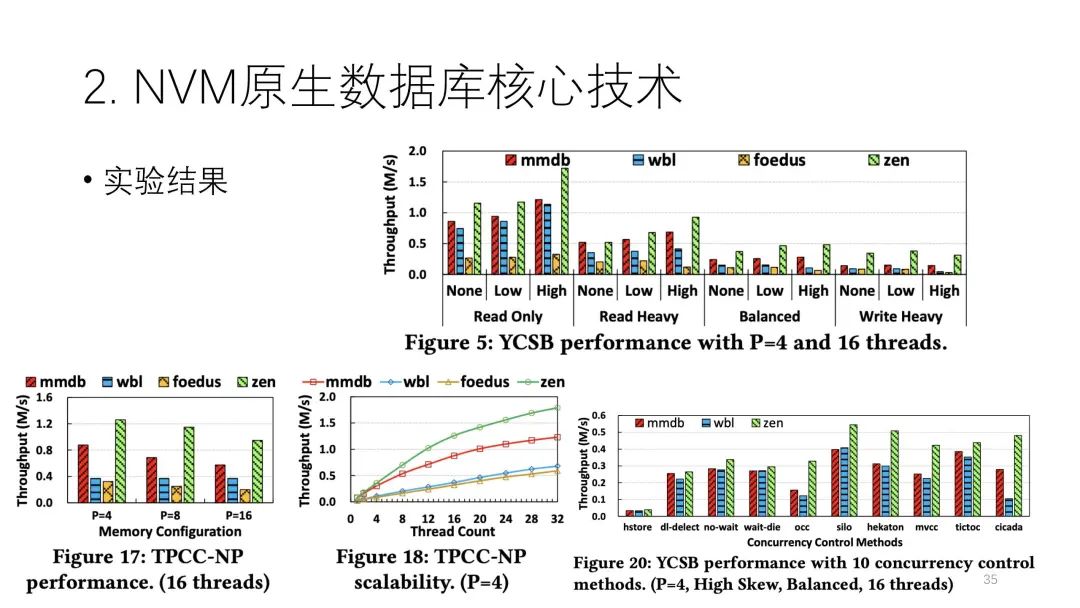
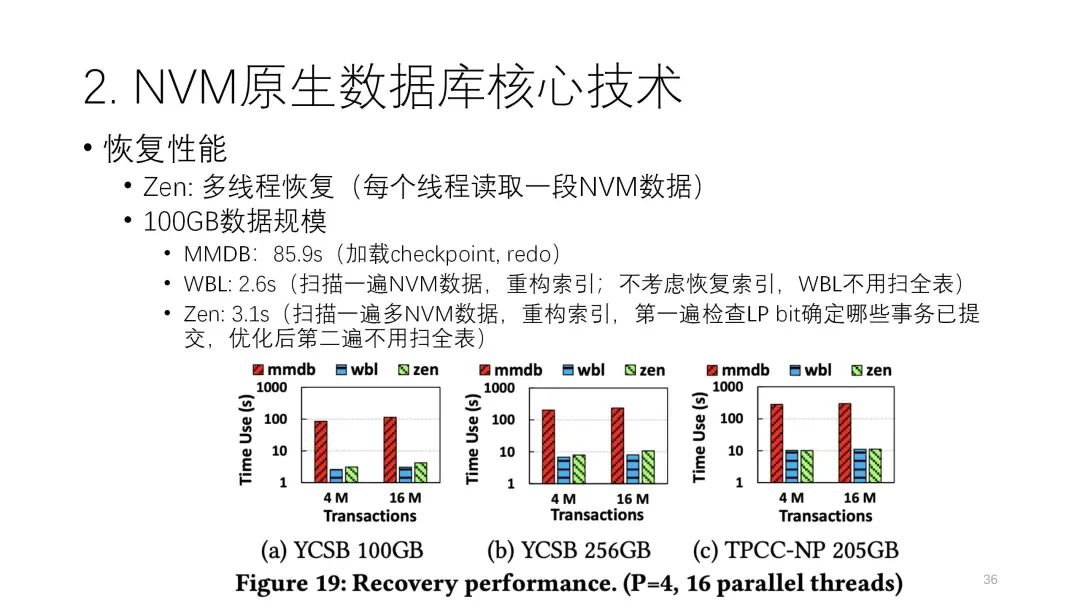
下图是恢复性能的比较。可以看到第一个方案确实恢复比较差,因为它要去做日志读取,再去做redo,整个过程要80多秒,而后两个方案都是个位数级别。WBL按照它的原则是不需要扫描的,基本上是零点几秒,非常快就能恢复,但因为索引也是要恢复的,也要扫一遍数据,所以也需要几秒的时间。Zen因为它的恢复更复杂些,除了扫一遍数据确定哪些数据提交之后,有一些还要再扫一部分数据,所以它的性能稍慢一点。但这里有个小疑问,论文中的数据规模比较小,如果数据规模更大,把所有的开销都推到恢复,那恢复是否还能做到这样快,这个值得后续探讨。
 第二篇论文也是关于日志方面的,但是并不是数据库层面,而是在LSM-tree层面做日志。实际上LSM-tree在写的时候也有一个日志,也有内存里的buffer。它为了提高性能尽可能地把数据先写到内存里,然后综合competition再去做持久化,再写到下面,但为了保证安全性必须先写日志,写日志的开销实际上就代表了整个性能的高低。这里把NVM加进去之后,它对整个LSM-tree做了较大的改动,最重要的是改成了lock-free结构,性能就很好。
第二篇论文也是关于日志方面的,但是并不是数据库层面,而是在LSM-tree层面做日志。实际上LSM-tree在写的时候也有一个日志,也有内存里的buffer。它为了提高性能尽可能地把数据先写到内存里,然后综合competition再去做持久化,再写到下面,但为了保证安全性必须先写日志,写日志的开销实际上就代表了整个性能的高低。这里把NVM加进去之后,它对整个LSM-tree做了较大的改动,最重要的是改成了lock-free结构,性能就很好。
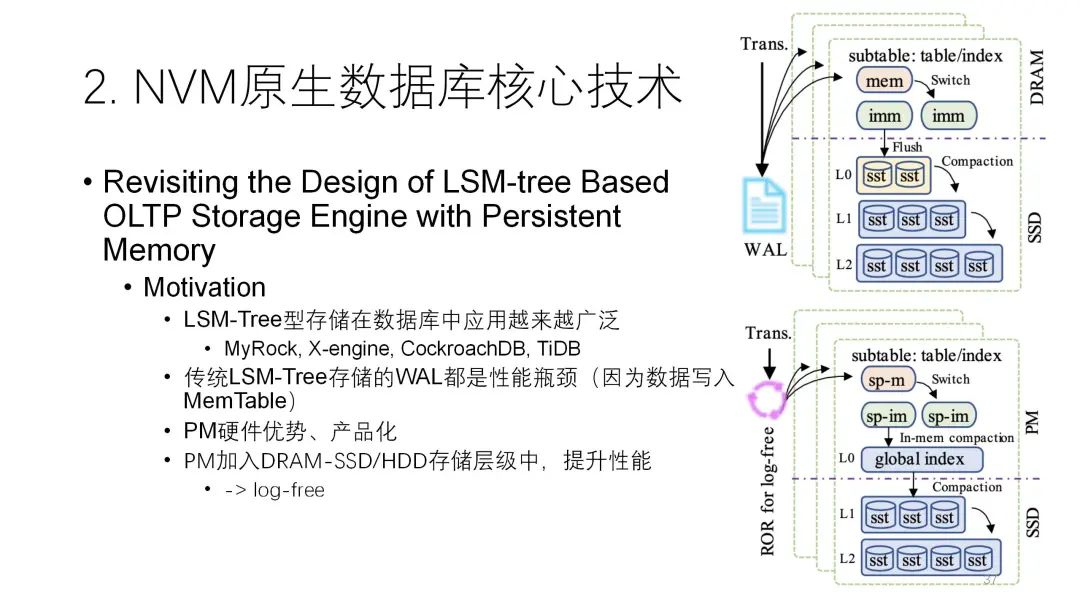 大体的思路是,先把数据写到Chainlog里,在经过 LSM-tree多层次转移的时候,只从逻辑上去做,物理上数据只写一遍就可以了,后面不需要再去写。
大体的思路是,先把数据写到Chainlog里,在经过 LSM-tree多层次转移的时候,只从逻辑上去做,物理上数据只写一遍就可以了,后面不需要再去写。
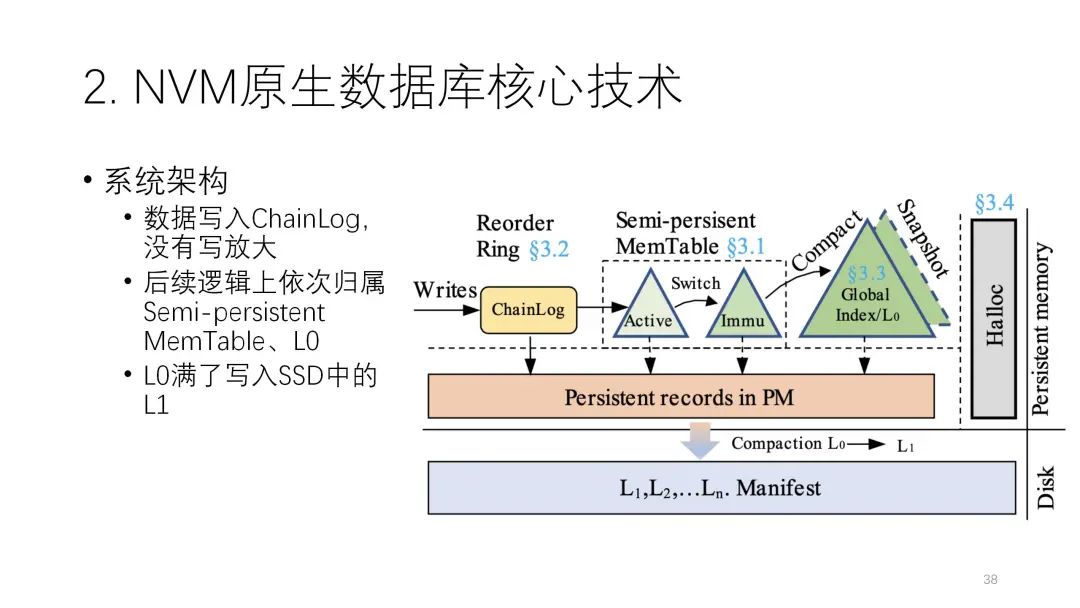
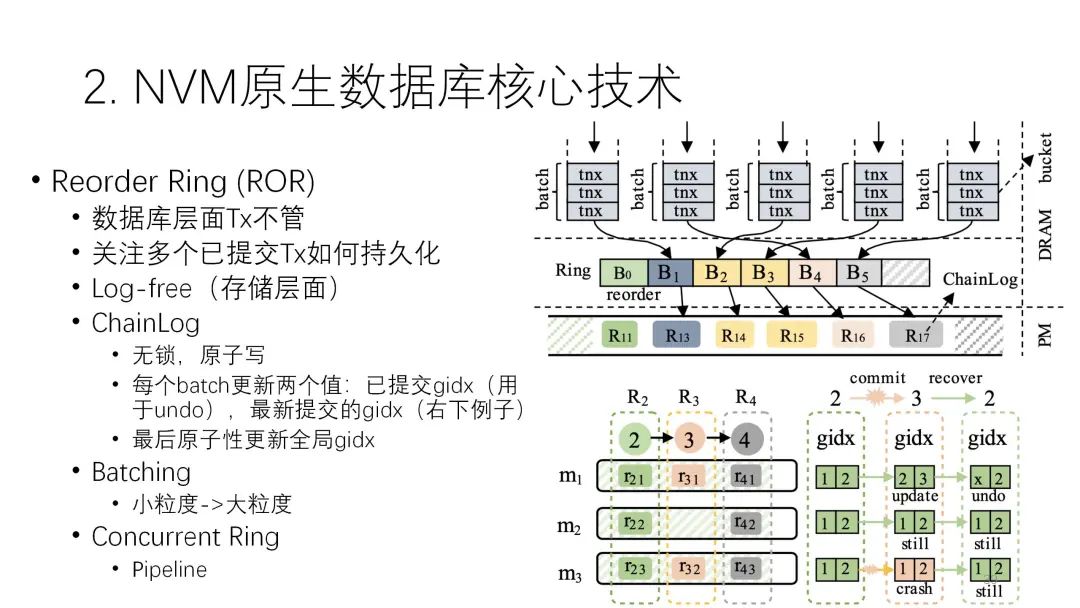
这里和日志最相关的是下面的技术。LSM-tree上可能有很多transaction并行在提交,它关心的是提交的时候怎么持久化。以下图为例,这里有并行大量的持久化,为了让力度更大就会把它变成批次来写,但每一批怎么能做到lock-free呢?它计两个值,两个gidx,1就是1号版本,2是2号版本,3是3号版本。前面的值指的是之前已经提交的正确版本,后面就表示当前正在提交的版本。
在这个例子中,当前是1、2的状态,前两个批次已经都提交了,现在正在提交第3个批次,第3个批次第一个已经提交完了,第二、第三个还没提交完,但是后面这个节点就挂掉了,挂掉之后在恢复的时候,因为这个地方是持久化的,它知道正在做2的过程中出问题了,我们只要回到上一个2就行了,如果前面这失败了,再回滚到前面这个2就可以了,前面这个就不用管了,有一部分更新到3,最后也可以回滚到2,所以不会出问题,而且整个过程是必须要写日志的。
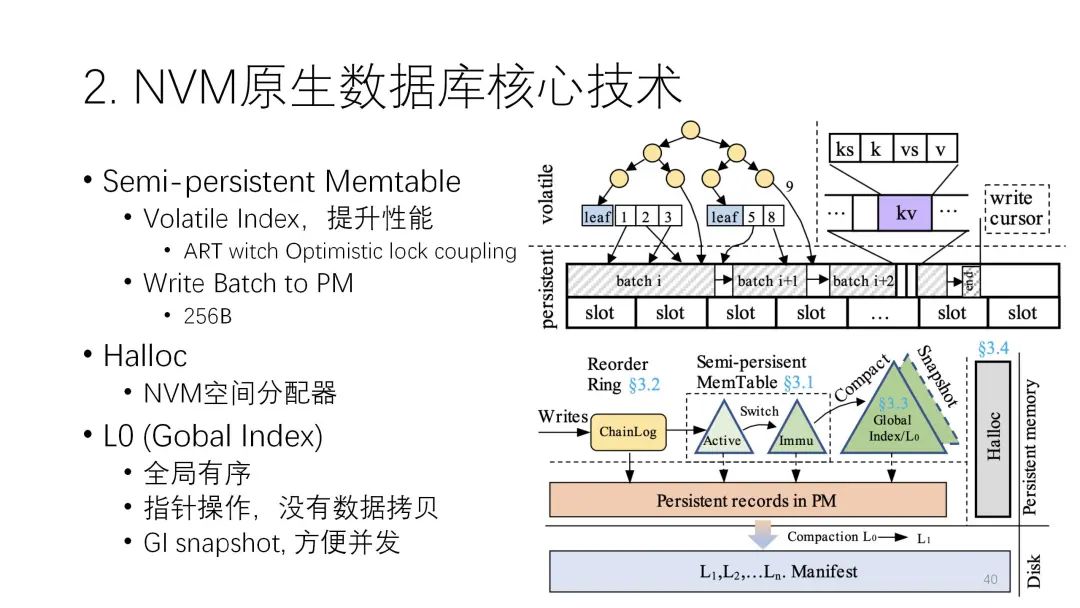
 它的结构上也采用了半持久化,中间的索引部分是易失的,下面的部分是非易失的,这样来减少NVM的操作。
它的结构上也采用了半持久化,中间的索引部分是易失的,下面的部分是非易失的,这样来减少NVM的操作。
 2.3 混合内存技术
2.3 混合内存技术最后要分享的这篇论文,将介绍NVM的混合内存技术。
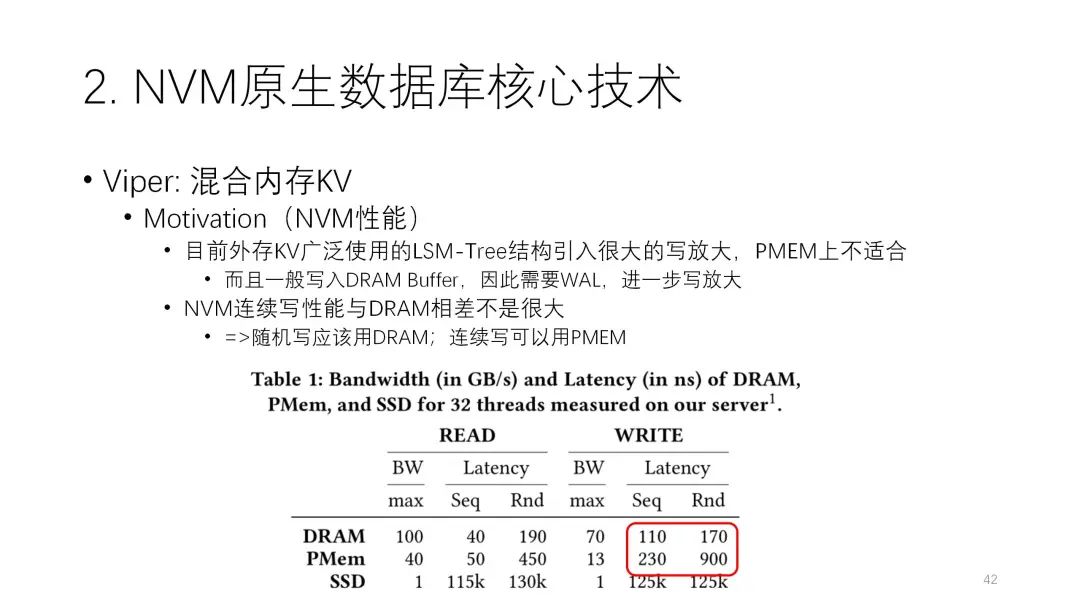
此前很多研究都假设NVM与内存比较接近,因此尽量要用NVM直接去写,不做写放大,避免重复的写,但实际上两者性能差别很大,因此还是要用好NVM。如何让DRAM和cache进行分工协作,就成为了一个很重要的问题,这篇论文就是按照这样的思路来开展研究的。
 这篇论文发现NVM的连续写性能和DRAM相差不大,而随机写差别就比较大,因此建议NVM尽量不要随机写,要用连续写。
这篇论文发现NVM的连续写性能和DRAM相差不大,而随机写差别就比较大,因此建议NVM尽量不要随机写,要用连续写。
 因此整个思路是:在DRAM里采用易失性索引,因为索引有很多小粒度的随机更新,放在NVM里效果肯定不太理想,所以索引干脆放弃,直接放在DRAM里;PMEM里主要是对数据进行持久化的写入,而且尽可能把它组织好之后再连续的写;然后把数据组织成4K对齐,横着最大的是Vblock,小的4K的是Vpage,这样除了数据规整以外还有利于并行度的控制;采用的结构是并行模型,尽可能均匀地分到各个DIMM上,Vblock直接对应下面不同的DIMM通道,因此每个用户写进去后,每个通道上拿到的并行都差不多,尽可能做到均衡,从并行的角度有一定的优化,里面也支持变长和定长的结构。
因此整个思路是:在DRAM里采用易失性索引,因为索引有很多小粒度的随机更新,放在NVM里效果肯定不太理想,所以索引干脆放弃,直接放在DRAM里;PMEM里主要是对数据进行持久化的写入,而且尽可能把它组织好之后再连续的写;然后把数据组织成4K对齐,横着最大的是Vblock,小的4K的是Vpage,这样除了数据规整以外还有利于并行度的控制;采用的结构是并行模型,尽可能均匀地分到各个DIMM上,Vblock直接对应下面不同的DIMM通道,因此每个用户写进去后,每个通道上拿到的并行都差不多,尽可能做到均衡,从并行的角度有一定的优化,里面也支持变长和定长的结构。 这里有一个值得学习的比较通用的小技巧,即如何让NVM的元数据持久化的开销尽可能小。要先写数据,再写元数据,且要保证元数据是8字节内的原子写,这样就不需要WAL。在下面这个例子中,先把数据写进去,写完之后,把beat从0改成1,这个小beat肯定是原子写的。如果前面这个过程挂掉了,这个数据因为beat没有set,我们就知道这个数据没写成功,甚至空间都没有分配出去,那就可以直接下次再用。如果已经写完了1,说明上面肯定是完成的。通过这个技巧可以减少很多开销。

总结与思考
在很长时间内,NVM介质还是明显弱于DRAM。目前只有英特尔公司在做NVM产品,其发展不会很快,迭代的周期也会很长,所以前面介绍的硬件特性可能会长期存在,这也给未来数据库的发展带来了更多的机会。
如果要和内存数据库、磁盘数据库做对比,实际上NVM数据库应该更接近于内存数据库。因此基于内存数据库去改造NVM数据库要更方便,当然也可以是原生的重新设计,这样效果可能会更好。
但NVM数据库和内存数据库虽然接近,实际上两者还是有较大的差别。
一方面,内存数据库的空间是受限的,场景和成本都是它的问题,而NVM数据库在存储力度、成本上有较大的优势,将来可能会应用在很多场景里。另一方面,内存数据库的日志持久化部分也带来较大的性能开销,而NVM数据库在这方面还会有较多的提升空间,即使是从内存数据库优化的角度,也能让内存数据库的性能更好。
 此外从系统设计的角度来看,NVM原生数据库的设计也和内存数据库有很大的区。
此外从系统设计的角度来看,NVM原生数据库的设计也和内存数据库有很大的区。 
﹀
﹀
﹀

解锁数据库前沿技术要点 | 腾讯云数据库DTCC 2021亮点回顾

首例“微服务+国产分布式数据库”架构,TDSQL助力昆山农商行换“心”

数实融合·绽放新机,Techo Day技术回响日邀您“云相聚”
点击阅读原文,了解更多优惠福利!