爱奇艺大数据生态的实时化建设
点击“开发者技术前线”,选择“星标🔝”
让一部分开发者看到未来
01
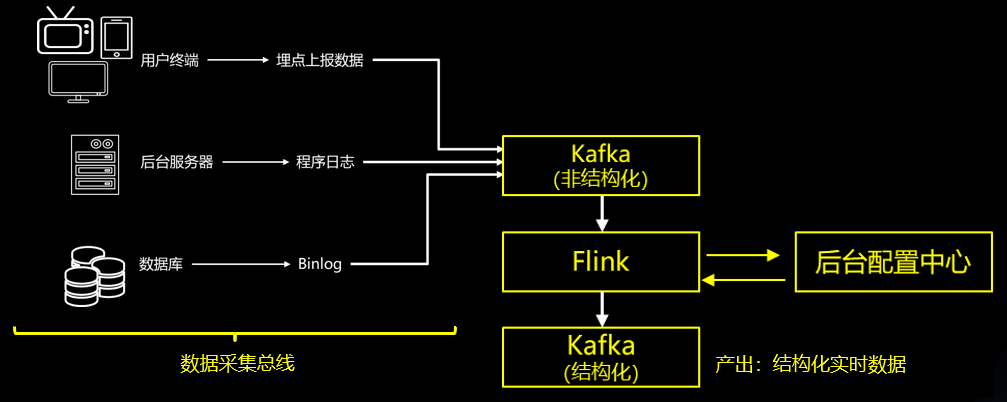
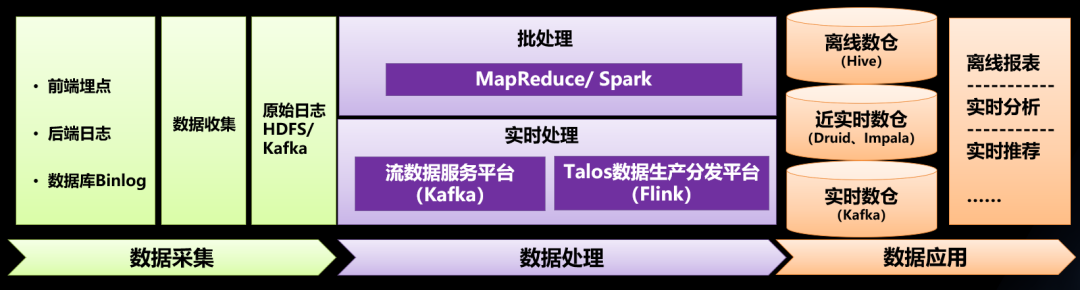
02
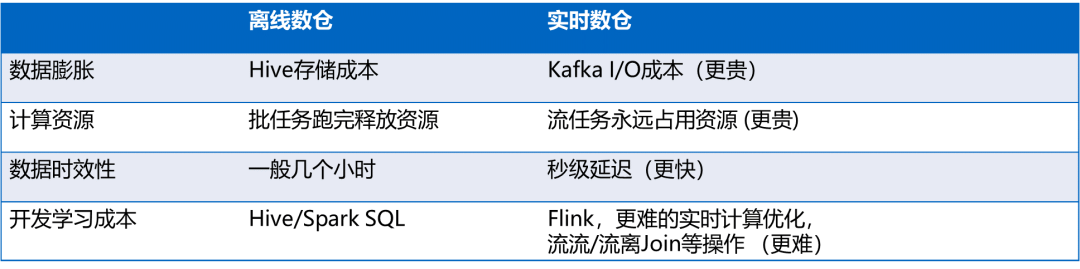
03
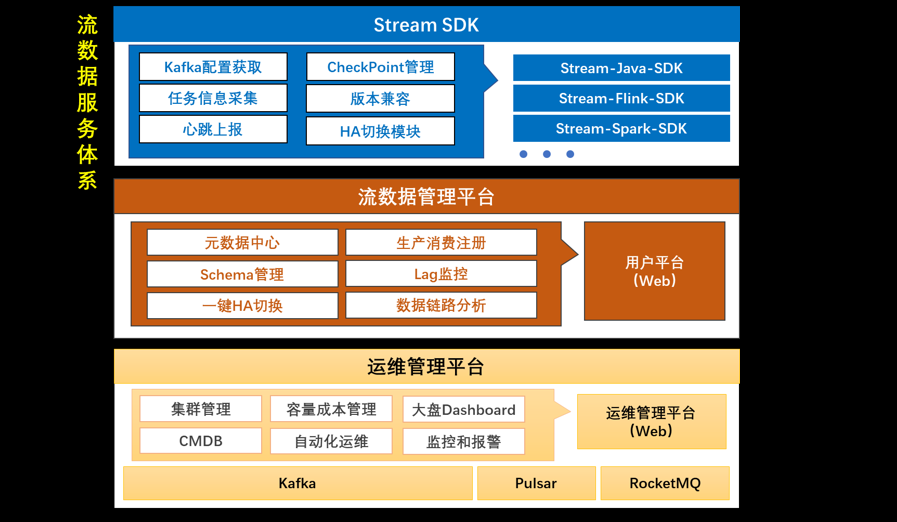
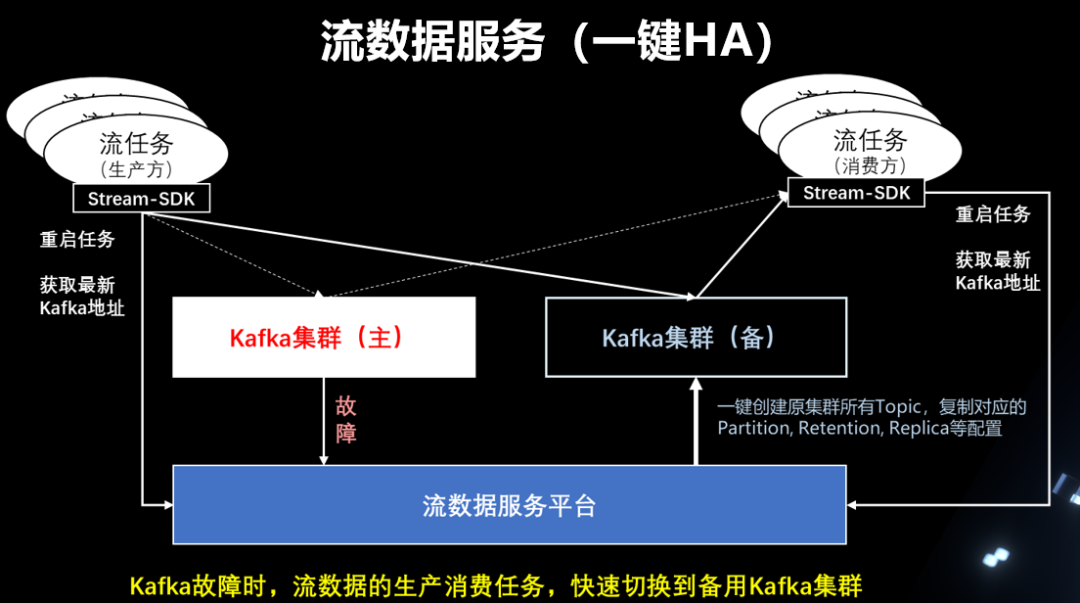
04
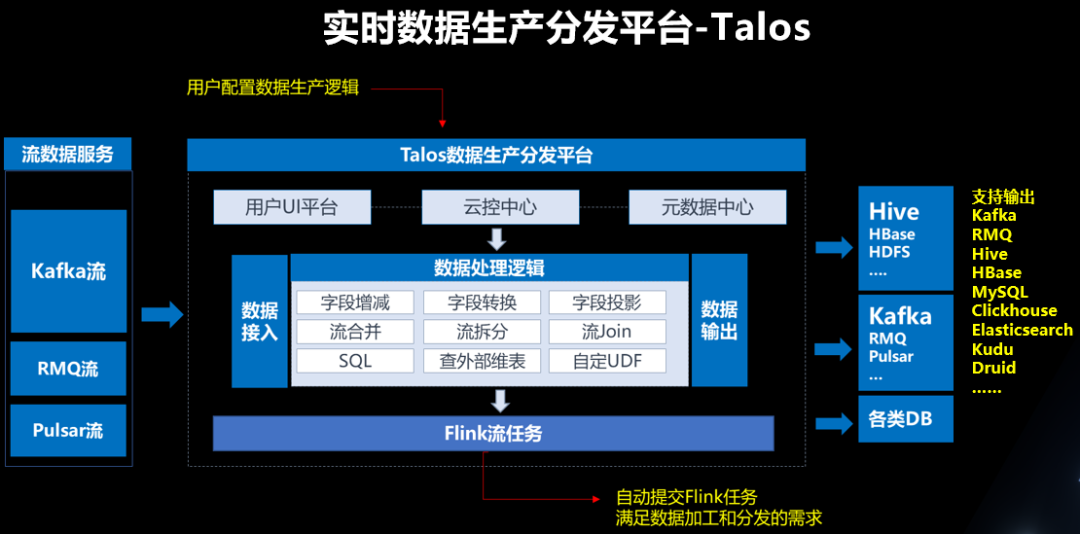
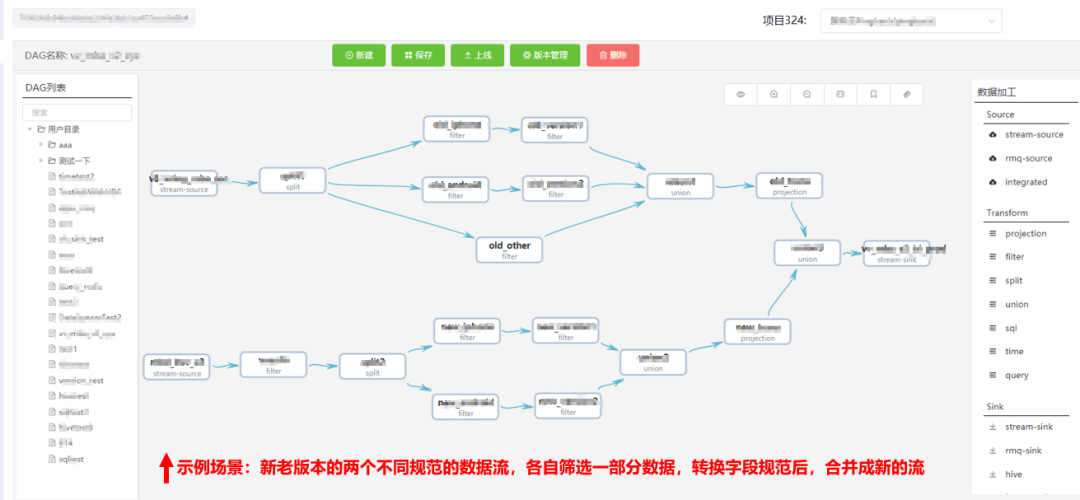
05
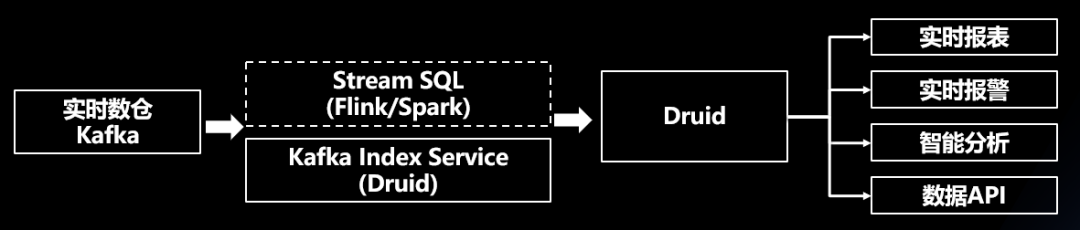
06
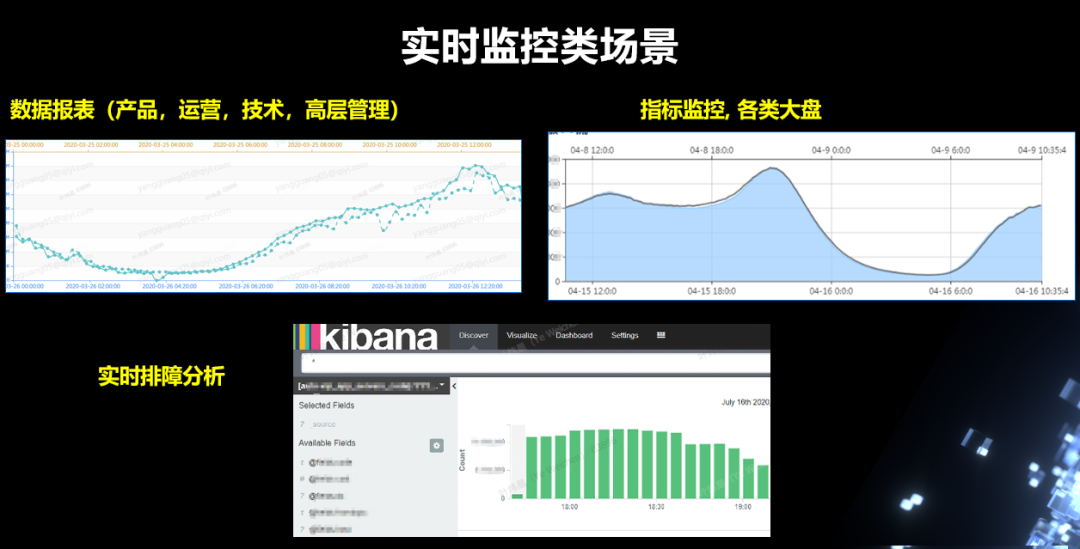

07
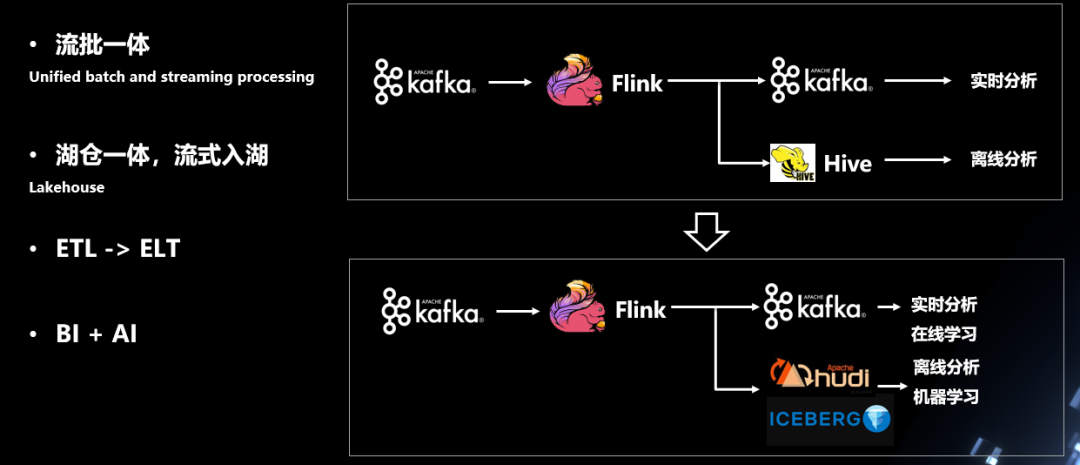
-END- 前线推出学习交流一定要备注:研究/工作方向+地点+学校/公司+昵称(如JAVA+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群 扫码加小编微信,进群和大佬们零距离
评论

点击“开发者技术前线”,选择“星标🔝”
让一部分开发者看到未来
01
02
03
04
05
06
07
-END- 前线推出学习交流一定要备注:研究/工作方向+地点+学校/公司+昵称(如JAVA+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群 扫码加小编微信,进群和大佬们零距离