
利用pandas模块处理百家姓数据
说在前面
“百家姓数据分析”程序功能相对复杂,涉及函数多,因此需要教师对pandas模块和DataFrame对象做简单介绍和示例演示,并为示例代码提供充分的注释,以帮助学生顺利理解示例代码;采用小组合作学习,将问题分解,每组同学只需完成其中一个任务,学有余力的同学可以完成多个任务。这样既明确了基本任务,使每一位同学都参与进来,又实现了分层教学的目标。

利用pandas模块处理百家姓数据
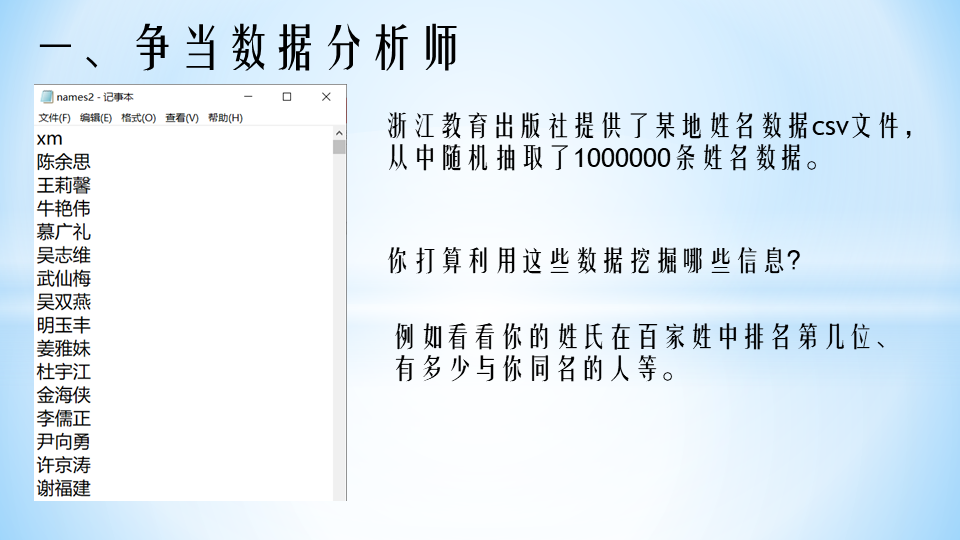
已有素材:浙江教育出版社(https://zjjy.zjcbcm.com/)提供了某地姓名数据csv文件,从中随机抽取了1000000条姓名数据。


学生活动1
教师讲解
初识DataFrame对象。


学生活动2
活动2: 拆分姓名。

#!/usr/bin/python3# 文件名: 百家姓处理之拆分姓氏# 作者:巧若拙# 时间:2021-11-14import pandas as pd'''函数功能:读取csv文件并拆分名字,如果是复姓,则按照复姓处理。函数名:split_name(file_name)参数表:file_name -- 存储了姓名信息的csv文件。返回值:返回包含了姓氏、名字和人数列的DataFrame对象。'''def split_name(file_name):# 定义复姓 listfx = ['欧阳','太史','端木','上官','司马','东方','独孤','南宫','万俟','闻人','夏侯','诸葛','尉迟','公羊','赫连','澹台','皇甫','宗政','濮阳','公冶','太叔','申屠','公孙','慕容','仲孙','钟离','长孙','宇文','司徒','鲜于','司空','闾丘','子车','亓官','司寇','巫马','公西','颛孙','壤驷','公良','漆雕','乐正','宰父','谷梁','拓跋','夹谷','轩辕','令狐','段干','百里','呼延','东郭','南门','羊舌','微生','公户','公玉','公仪','梁丘','公仲','公上','公门','公山','公坚','左丘','公伯','西门','公祖','第五','公乘']xm, xing, ming = [], [], [] #分别用来存储姓名、姓氏和名字with open(file_name, 'r', encoding='utf-8') as file: #打开文件读取数据for name in file: # 取姓、名,如果是复姓,则按照复姓处理name = name.strip() #去除两侧空格和回车符xm.append(name) #存储姓名if name[0:2] in fx:p = 2else:p = 第1空xing.append(name[:p]) #存储姓氏第2空 #存储名字#使用字典构造包含了姓名、姓氏和名字列的DataFrame对象(不含标题)data = {第3空}return pd.DataFrame(data)#设置中英文字符对齐,以改善输出格式pd.set_option('display.unicode.ambiguous_as_wide', True)pd.set_option('display.unicode.east_asian_width', True)#直接读取文件到DataFrame对象file_name = 'names2.csv' #存储百家姓数据的文件df = pd.read_csv(file_name)print(df)print("#" * 50)#读取csv文件并拆分名字,如果是复姓,则按照复姓处理df = split_name(file_name)print(df)
学生活动3
活动3: 统计和分析数据。

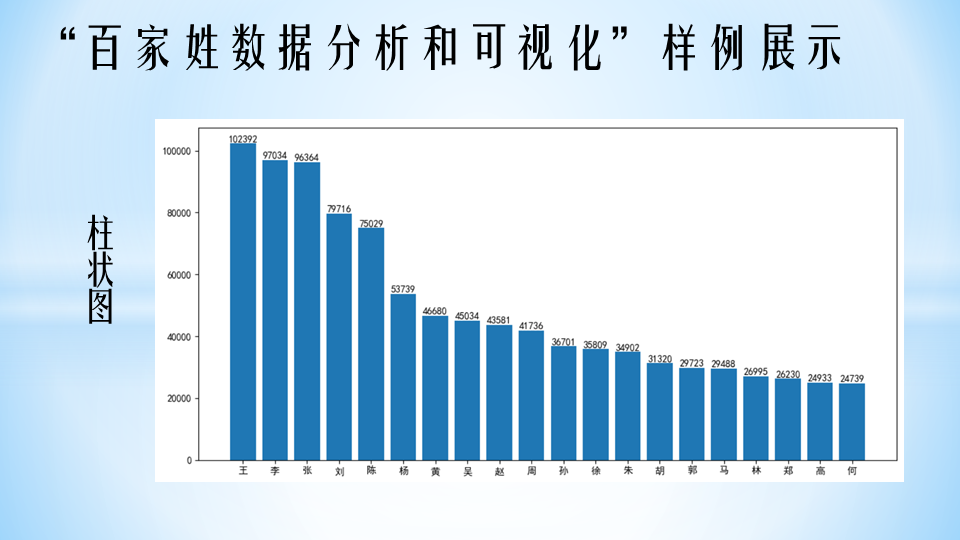
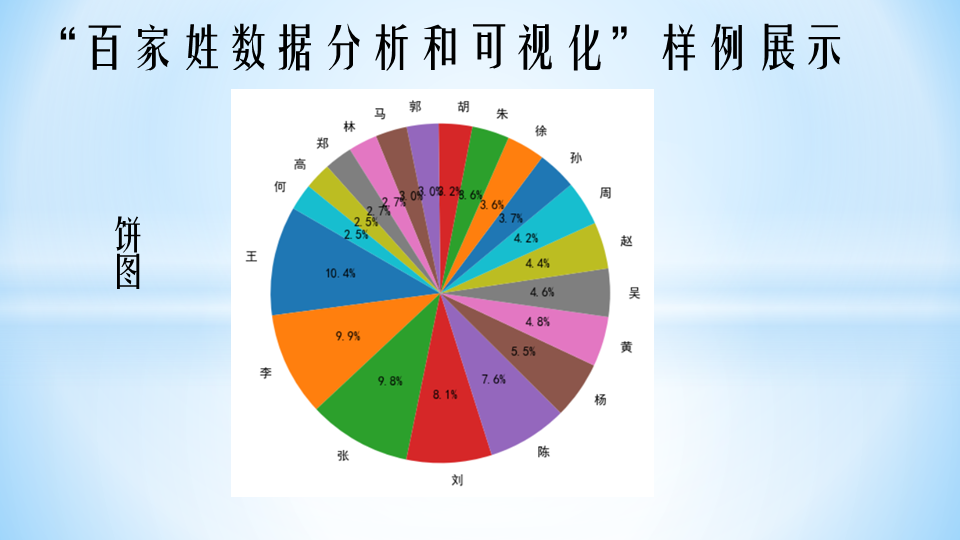
#!/usr/bin/python3# 文件名: 使用pandas处理百家姓数据# 作者:巧若拙# 时间:2021-11-14import pandas as pddef split_name(file_name):pass #代码略#设置中英文字符对齐,以改善输出格式pd.set_option('display.unicode.ambiguous_as_wide', True)pd.set_option('display.unicode.east_asian_width', True) #中英文字符对齐file_name = 'names2.csv' #存储百家姓数据的文件df = split_name(file_name)#读取csv文件并拆分名字,如果是复姓,则按照复姓处理print(df)print("#" * 50)#输出所有和你同名的人ming = '建国'print(df[df['名字']==ming])print("#" * 50)#问题1:输出和你同姓的人数?xing = '梁'print(第4空)print("#" * 50)#按“姓氏”分组计数,根据人数排名,并增加“排名”列xing_df = df.groupby('姓氏').count()xing_df['排名'] = xing_df['名字'].rank(ascending=False)#问题2:看看你的姓氏排名第几位?print(xing_df.loc[['赵','钱','孙','李']]) #输出赵钱孙李的排名print("#" * 50)n = 10#问题3:输出前n个最常见的姓氏?print("输出前n个最常见的姓氏:")xing_df = 第5空 # 按关键词“姓氏”分组计数xing_df.sort_values('姓名', ascending=False, inplace=True) #根据人数降序排序print(xing_df[:n])print("#" * 50)#输出前n个最常见的名字print("输出前n个最常见的名字:")ming_df = df.groupby('名字').count() #按关键词“名字”分组计数ming_df.sort_values('姓名', ascending=False, inplace=True) #根据人数降序排序print(ming_df[:n])print("#" * 50)#问题4:输出前n个最常见的复姓?print("输出前n个最常见的复姓:")xing_df = 第6空 #挑选出所有的复姓xing_df = xing_df.groupby('姓氏').count() #按关键词分组计数xing_df.sort_values('姓名', ascending=False, inplace=True) #根据人数降序排序print(xing_df[:n])print("#" * 50)#输出前n个最常见的双名print("输出前n个最常见的双名:")ming_df = df[df['名字'].str.len()==2] #挑选出所有的双名ming_df = ming_df.groupby('名字').count() #按关键词分组计数ming_df.sort_values('姓名', ascending=False, inplace=True) #根据人数降序排序print(ming_df[:n])
教师总结
总结和期望。

需要本文PPT、源代码和课后练习答案的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
相关优秀文章:
评论