大家好,我是武哥。这是《吃透 MQ 系列》的第三篇,有关 Kafka 的架构设计。
这篇文章将带着大家参透:到底什么是 Kafka 架构设计的任督二脉?把握住了这个关键点,我相信你将能更好地理解 Kafka 的架构设计,进而顺藤摸瓜地掌握 Kafka 的核心技术方案。废话不多说了,开始发车。
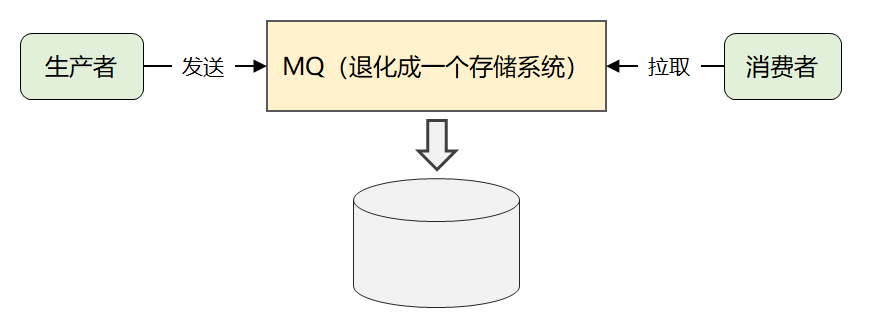
1、Kafka 为实时日志流而生,要处理的并发和数据量非常大。可见,Kafka 本身就是一个高并发系统,它必然会遇到高并发场景下典型的三高挑战:高性能、高可用和高扩展。2、为了简化实现的复杂度,Kafka 最终采用了很巧妙的消息模型:它将所有消息进行了持久化存储,让消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 进行拉取即可。最终 Kafka 将自己退化成了一个「存储系统」。因此,海量消息的存储问题就是 Kafka 架构设计中的最大技术难点。下面我们再接着分析下:Kafka 究竟是如何解决存储问题的?面对海量数据,单机的存储容量和读写性能肯定有限,大家很容易想到一种存储方案:对数据进行分片存储。这种方案在我们实际工作中也非常常见:1、比如数据库设计中,当单表的数据量达到几千万或者上亿时,我们会将它拆分成多个库或者多张表。2、比如缓存设计中,当单个 Redis 实例的数据量达到几十个 G 引发性能瓶颈时,我们会将单机架构改成分片集群架构。类似的拆分思想在 HDFS、ElasticSearch 等中间件中都能看到。Kafka 也不例外,它同样采用了这种水平拆分方案。在 Kafka 的术语中,拆分后的数据子集叫做 Partition(分区),各个分区的数据合集即全量数据。我们再来看下 Kafka 中的 Partition 具体是如何工作的?举一个很形象的例子,如果我们把「Kafka」类比成「高速公路」:1、当大家听到京广高速的时候,知道这是一条从北京到广州的高速路,这是逻辑上的叫法,可以理解成 Kafka 中的 Topic(主题)。2、一条高速路通常会有多个车道进行分流,每个车道上的车都是通往一个目的地的(属于同一个Topic),这里所说的车道便是 Partition。这样,一条消息的流转路径就如下图所示,先走主题路由,然后走分区路由,最终决定这条消息该发往哪个分区。
其中分区路由可以简单理解成一个 Hash 函数,生产者在发送消息时,完全可以自定义这个函数来决定分区规则。如果分区规则设定合理,所有消息将均匀地分配到不同的分区中。通过这样两层关系,最终在 Topic 之下,就有了一个新的划分单位:Partition。先通过 Topic 对消息进行逻辑分类,然后通过 Partition 进一步做物理分片,最终多个 Partition 又会均匀地分布在集群中的每台机器上,从而很好地解决了存储的扩展性问题。
因此,Partition 是 Kafka 最基本的部署单元。本文之所以将 Partition 称作 Kafka 架构设计的任督二脉,基于下面两点原因:
1、Partition 是存储的关键所在,MQ「一发一存一消费」的核心流程必然围绕它展开。
2、Kafka 高并发设计中最难的三高问题都能和 Partition 关联起来。
因此,以 Partition 作为根,能很自然地联想出 Kafka 架构设计中的各个知识点,形成可靠的知识体系。下面,请大家继续跟着我的思路,以 Partition 为线索,对 Kafka 的宏观架构进行解析。接下来,我们再看看 Partition 的分布式能力究竟是如何实现的?它又是怎么和 Kafka 的整体架构关联起来的?前面讲过 Partition 是 Topic 之下的一个划分单位,它是 Kafka 最基本的部署单元,它将决定 Kafka 集群的组织方式。假设现在有两个 Topic,每个 Topic 都设置了两个 Partition,如果 Kafka 集群是两台机器,部署架构将会是下面这样:
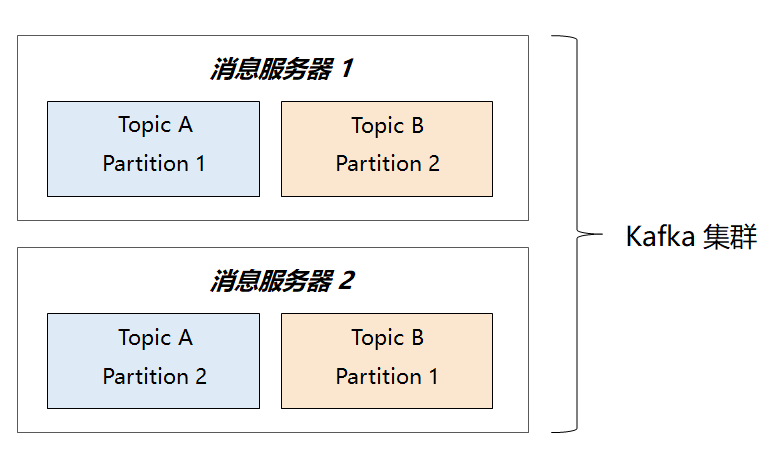
可以看到:同一个 Topic 的两个 Partition 分布在不同的消息服务器上,能做到消息的分布式存储了。但是对于 Kafka 这个高并发系统来说,仅存储可扩展还不够,消息的拉取也必须并行才行,否则会遇到极大的性能瓶颈。那我们再看看消费端,它又是如何跟 Partition 结合并做到并行处理的?从消费者来看,首先要满足两个基本诉求:
1、广播消费能力:同一个 Topic 可以被多个消费者订阅,一条消息能够被消费多次。
2、集群消费能力:当消费者本身也是集群时,每一条消息只能分发给集群中的一个消费者进行处理。
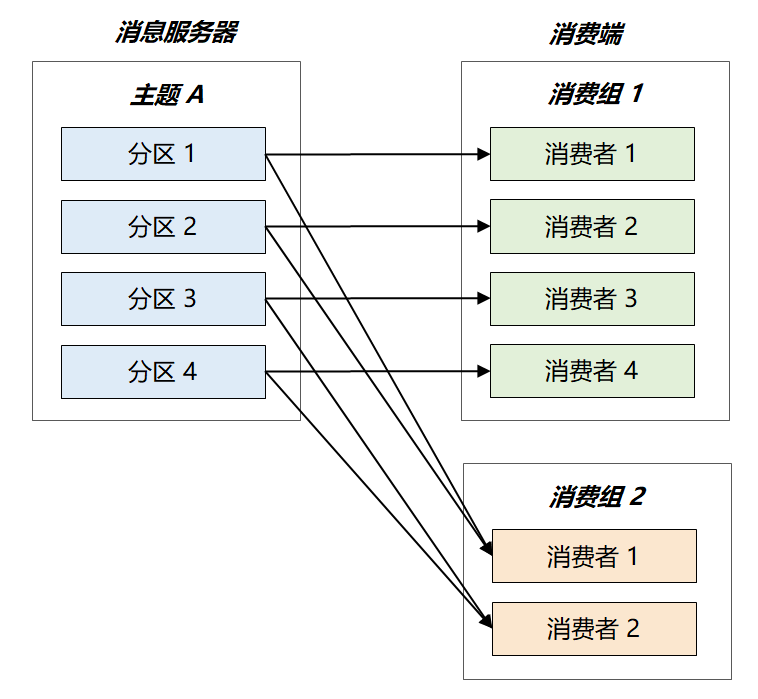
为了满足这两点要求,Kafka 引出了消费组的概念,每个消费者都有一个对应的消费组,组间进行广播消费,组内进行集群消费。此外,Kafka 还限定了:每个 Partition 只能由消费组中的一个消费者进行消费。最终的消费关系如下图所示:假设主题 A 共有 4 个分区,消费组 2 只有两个消费者,最终这两个消费组将平分整个负载,各自消费两个分区的消息。
如果要加快消息的处理速度,该如何做呢?也很简单,向消费组 2 中增加新的消费者即可,Kafka 将以 Partition 为单位重新做负载均衡。当增加到 4 个消费者时,每个消费者仅需处理 1 个 Partition,处理速度将提升两倍。
到这里,存储可扩展、消息并行处理这两个难题都解决了。但是高并发架构设计上,还遗留了一个很重要的问题:那就是高可用设计。在 Kafka 集群中,每台机器都存储了一些 Partition,一旦某台机器宕机,上面的数据不就丢失了吗?此时,你一定会想到对消息进行持久化存储,但是持久化只能解决一部分问题,它只能确保机器重启后,历史数据不丢失。但在机器恢复之前,这部分数据将一直无法访问。这对于高并发系统来说,是无法忍受的。所以 Kafka 必须具备故障转移能力才行,当某台机器宕机后仍然能保证服务可用。
如果大家去分析任何一个高可靠的分布式系统,比如 ElasticSearch、Redis Cluster,其实它们都有一套多副本的冗余机制。
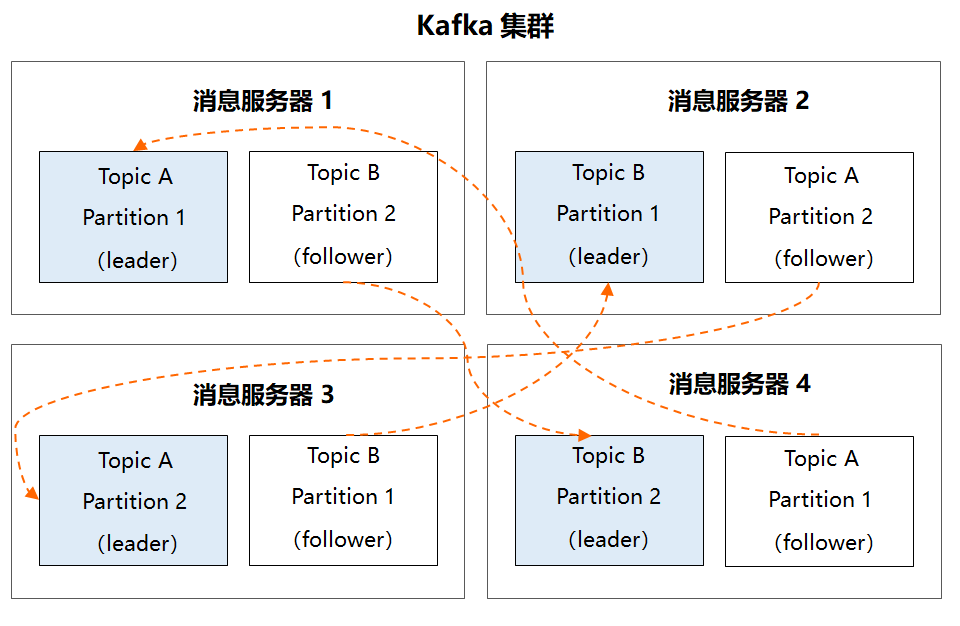
没错,Kafka 正是通过 Partition 的多副本机制解决了高可用问题。在 Kafka 集群中,每个 Partition 都有多个副本,同一分区的不同副本中保存的是相同的消息。副本之间是 “一主多从” 的关系,其中 leader 副本负责读写请求,follower 副本只负责和 leader 副本同步消息,当 leader 副本发生故障时,它才有机会被选举成新的 leader 副本并对外提供服务,否则一直是待命状态。
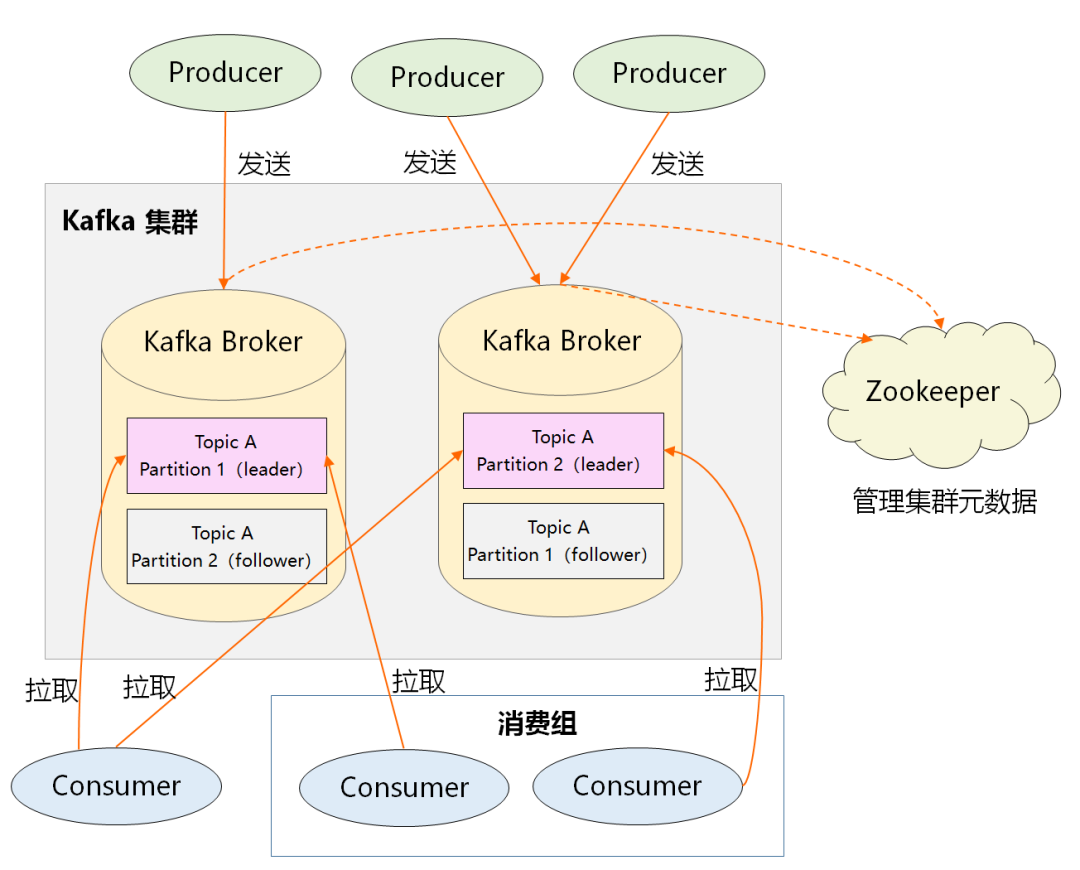
现在,我假设 Kafka 集群中有 4 台服务器,主题 A 和主题 B 都有两个 Partition,且每个 Partition 各有两个副本,那最终的多副本架构将如下图所示:很显然,这个集群中任何一台机器宕机,都不会影响 Kafka 的可用性,数据仍然是完整的。理解了上面这些内容,最后我们再反过来看下 Kafka 的整体架构:1、Producer:生产者,负责创建消息,然后投递到 Kafka 集群中,投递时需要指定消息所属的 Topic,同时确定好发往哪个 Partition。2、Consumer:消费者,会根据它所订阅的 Topic 以及所属的消费组,决定从哪些 Partition 中拉取消息。3、Broker:消息服务器,可水平扩展,负责分区管理、消息的持久化、故障自动转移等。4、Zookeeper:负责集群的元数据管理等功能,比如集群中有哪些 broker 节点以及 Topic,每个 Topic 又有哪些 Partition 等。很显然,在 Kafka 整体架构中,Partition 是发送消息、存储消息、消费消息的纽带。吃透了它,再去理解整体架构,脉络会更加清晰。本文以 Partition 为切入点,从宏观角度解析了 Kafka 的整体架构,再简单总结下本文的内容:1、Kafka 通过巧妙的模型设计,将自己退化成一个海量消息的存储系统。2、为了解决存储的扩展性问题,Kafka 对数据进行了水平拆分,引出了 Partition(分区),这是 Kafka 部署的基本单元,同时也是 Kafka 并发处理的最小粒度。3、对于一个高并发系统来说,还需要做到高可用,Kafka 通过 Partition 的多副本冗余机制进行故障转移,确保了高可靠。希望这篇文章能让大家摆脱死记硬背的模式,先找到一个支点,再去推敲 Kafka 架构设计的来龙去脉,知其所以然。下篇文章将从微观角度切入,深入分析 Kafka 的设计原理,我们下期见!
大家在看:
编程高手是如何练成的?
---------- END ----------
大家好,我是武哥,前亚马逊工程师,现知名独角兽技术总监,持续分享个人的成长收获,关注我一定能提升你的视野,让我们一起进阶吧!