
阿里面试官:为什么MySQL数据库索引选择使用B+树而不是跳表?
二叉查找树
(1)二叉树简介:
二叉查找树也称为有序二叉查找树,满足二叉查找树的一般性质,是指一棵空树具有如下性质:
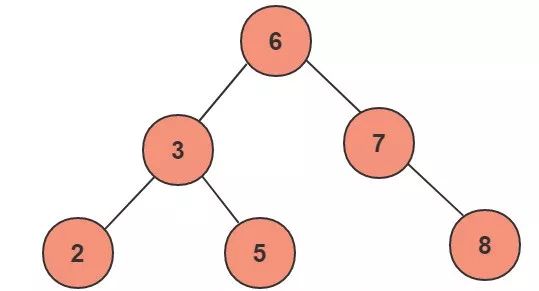
(2)局限性及应用
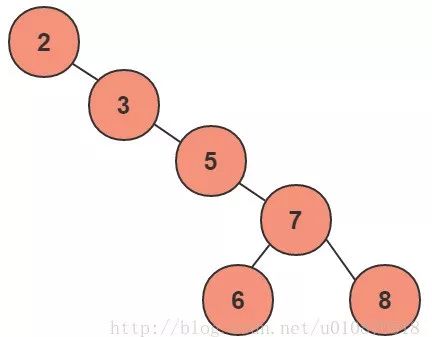
大家看上图,如果我们的根节点选择是最小或者最大的数,那么二叉查找树就完全退化成了线性结构。上图中的平均查找次数为(1+2+3+4+5+5)/6=3.16次,和顺序查找差不多。显然这个二叉树的查询效率就很低,因此若想最大性能的构造一个二叉查找树,需要这个二叉树是平衡的(这里的平衡从一个显著的特点可以看出这一棵树的高度比上一个输的高度要大,在相同节点的情况下也就是不平衡),从而引出了一个新的定义-平衡二叉树AVL。
AVL树
(1)简介

从上面是一个普通的平衡二叉树,这张图我们可以看出,任意节点的左右子树的平衡因子差值都不会大于1。
(3)应用
1、Windows NT内核中广泛存在;
红黑树
(1)简介
(2)性质
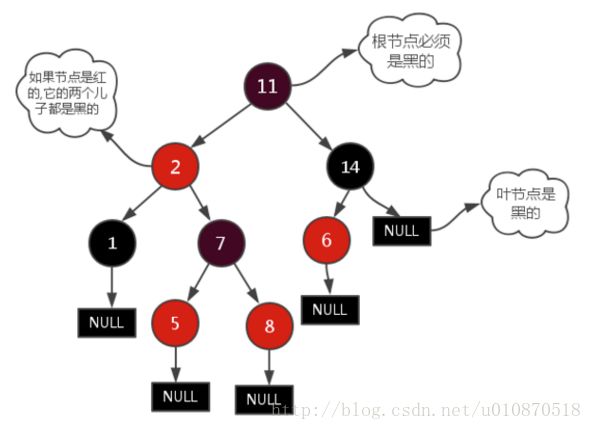
(3)应用
2、著名的Linux进程调度Completely Fair Scheduler,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间;
3、IO多路复用epoll的实现采用红黑树组织管理sockfd,以支持快速的增删改查;
4、Nginx中用红黑树管理timer,因为红黑树是有序的,可以很快的得到距离当前最小的定时器;
5、Java中TreeMap的实现;
B/B+树
说了上述的三种树:二叉查找树、AVL和红黑树,似乎我们还没有摸到MySQL为什么要使用B+树作为索引的实现,不要急,接下来我们就先探讨一下什么是B树。
(1)简介
(2)B树的性质
2、根结点的儿子数为[2, M];
3、除根结点以外的非叶子结点的儿子数为[M/2, M];
4、每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5、非叶子结点的关键字个数=指向儿子的指针个数-1;
6、非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7、非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8、所有叶子结点位于同一层;

这里只是一个简单的B树,在实际中B树节点中关键字很多的,上面的图中比如35节点,35代表一个key(索引),而小黑块代表的是这个key所指向的内容在内存中实际的存储位置,是一个指针。
B+树
(1)简介
B+树是应文件系统所需而产生的一种B树的变形树(文件的目录一级一级索引,只有最底层的叶子节点(文件)保存数据)非叶子节点只保存索引,不保存实际的数据,数据都保存在叶子节点中,这不就是文件系统文件的查找吗?
所有的非叶子节点都可以看成索引部分!
(2)B+树的性质(下面提到的都是和B树不相同的性质)
2、非叶子节点的子树指针p[i],指向关键字值属于[k[i],k[i+1]]的子树.(B树是开区间,也就是说B树不允许关键字重复,B+树允许重复);
3、为所有叶子节点增加一个链指针;
4、所有关键字都在叶子节点出现(稠密索引). (且链表中的关键字恰好是有序的);
5、非叶子节点相当于是叶子节点的索引(稀疏索引),叶子节点相当于是存储(关键字)数据的数据层;
6、更适合于文件系统;

非叶子节点(比如5,28,65)只是一个key(索引),实际的数据存在叶子节点上(5,8,9)才是真正的数据或指向真实数据的指针。
(3)应用
B/B+树性能分析
n个节点的平衡二叉树的高度为H(即logn),而n个节点的B/B+树的高度为logt((n+1)/2)+1;
若要作为内存中的查找表,B树却不一定比平衡二叉树好,尤其当m较大时更是如此。因为查找操作CPU的时间在B-树上是O(mlogtn)=O(lgn(m/lgt)),而m/lgt>1;所以m较大时O(mlogtn)比平衡二叉树的操作时间大得多。因此在内存中使用B树必须取较小的m。(通常取最小值m=3,此时B-树中每个内部结点可以有2或3个孩子,这种3阶的B-树称为2-3树)。
为什么说B+树比B树更适合数据库索引?
1、 B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
2、B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
PS:我在知乎上看到有人是这样说的,我感觉说的也挺有道理的:
B+树的原理,基本上讲完了,限于篇幅,关于MySQL为啥不用跳表?而Redis钟情于跳表?咱们下篇再来讲述。
正文结束
1.不认命,从10年流水线工人,到谷歌上班的程序媛,一位湖南妹子的励志故事
5.37岁程序员被裁,120天没找到工作,无奈去小公司,结果懵了...
