
JavaScript 内存详解 & 分析指南
前言
JavaScript 诞生于 1995 年,最初被设计用于网页内的表单验证。
这些年来 JavaScript 成长飞速,生态圈日益壮大,成为了最受程序员欢迎的开发语言之一。并且现在的 JavaScript 不再局限于网页端,已经扩展到了桌面端、移动端以及服务端。
随着大前端时代的到来,使用 JavaScript 的开发者越来越多,但是许多开发者都只停留在“会用”这个层面,而对于这门语言并没有更多的了解。
如果想要成为一名更好的 JavaScript 开发者,理解内存是一个不可忽略的关键点。
📖 本文主要包含两大部分:
JavaScript 内存详解 JavaScript 内存分析指南
看完这篇文章后,相信你会对 JavaScript 的内存有比较全面的了解,并且能够拥有独自进行内存分析的能力。
🧐 话不多说,我们开始吧!
文章篇幅较长,除去代码也有 12000 字左右,需要一定的时间来阅读,但是我保证你所花费的时间都是值得的。
正文
内存(memory)
什么是内存(What is memory)
相信大家都对内存有一定的了解,我就不从盘古开天辟地开始讲了,稍微提一下。
首先,任何应用程序想要运行都离不开内存。
另外,我们提到的内存在不同的层面上有着不同的含义。
💻 硬件层面(Hardware)
在硬件层面上,内存指的是随机存取存储器。
内存是计算机重要组成部分,用来储存应用运行所需要的各种数据,CPU 能够直接与内存交换数据,保证应用能够流畅运行。
一般来说,在计算机的组成中主要有两种随机存取存储器:高速缓存(Cache)和主存储器(Main memory)。
高速缓存通常直接集成在 CPU 内部,离我们比较远,所以更多时候我们提到的(硬件)内存都是主存储器。
💡 随机存取存储器(Random Access Memory,RAM)
随机存取存储器分为静态随机存取存储器(Static Random Access Memory,SRAM)和动态随机存取存储器(Dynamic Random Access Memory,DRAM)两大类。
在速度上 SRAM 要远快于 DRAM,而 SRAM 的速度仅次于 CPU 内部的寄存器。
在现代计算机中,高速缓存使用的是 SRAM,而主存储器使用的是 DRAM。
💡 主存储器(Main memory,主存)
虽然高速缓存的速度很快,但是其存储容量很小,小到几 KB 最大也才几十 MB,根本不足以储存应用运行的数据。
我们需要一种存储容量与速度适中的存储部件,让我们在保证性能的情况下,能够同时运行几十甚至上百个应用,这也就是主存的作用。
计算机中的主存其实就是我们平时说的内存条(硬件)。
硬件内存不是我们今天的主题,所以就说这么多,想要深入了解的话可以根据上面提到关键词进行搜索。
🧩 软件层面(Software)
在软件层面上,内存通常指的是操作系统从主存中划分(抽象)出来的内存空间。
此时内存又可以分为两类:栈内存和堆内存。
接下来我将围绕 JavaScript 这门语言来对内存进行讲解。
在后面的文章中所提到的内存均指软件层面上的内存。
栈与堆(Stack & Heap)
栈内存(Stack memory)
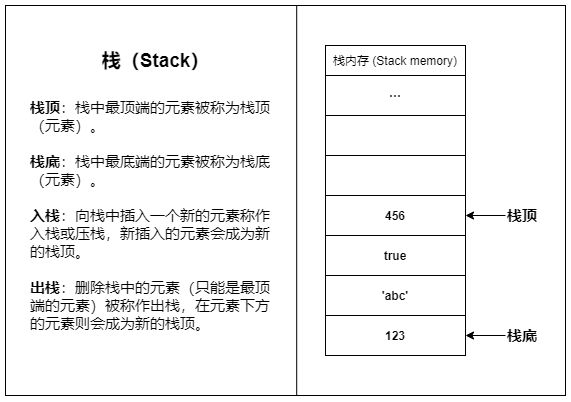
💡 栈(Stack)
栈是一种常见的数据结构,栈只允许在结构的一端操作数据,所有数据都遵循后进先出(Last-In First-Out,LIFO)的原则。
现实生活中最贴切的的例子就是羽毛球桶,通常我们只通过球桶的一侧来进行存取,最先放进去的羽毛球只能最后被取出,而最后放进去的则会最先被取出。
栈内存之所以叫做栈内存,是因为栈内存使用了栈的结构。
栈内存是一段连续的内存空间,得益于栈结构的简单直接,栈内存的访问和操作速度都非常快。
栈内存的容量较小,主要用于存放函数调用信息和变量等数据,大量的内存分配操作会导致栈溢出(Stack overflow)。
栈内存的数据储存基本都是临时性的,数据会在使用完之后立即被回收(如函数内创建的局部变量在函数返回后就会被回收)。
简单来说:栈内存适合存放生命周期短、占用空间小且固定的数据。
💡 栈内存的大小
栈内存由操作系统直接管理,所以栈内存的大小也由操作系统决定。
通常来说,每一条线程(Thread)都会有独立的栈内存空间,Windows 给每条线程分配的栈内存默认大小为 1MB。
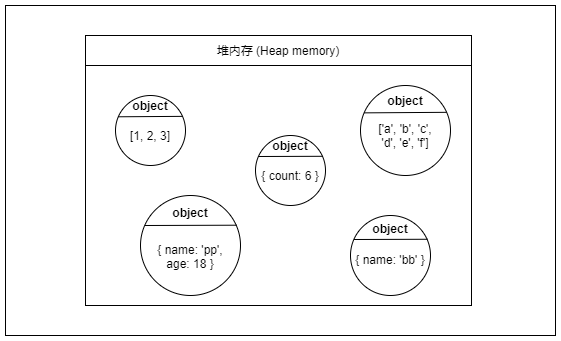
堆内存(Heap memory)
💡 堆(Heap)
堆也是一种常见的数据结构,但是不在本文讨论范围内,就不多说了。
堆内存虽然名字里有个“堆”字,但是它和数据结构中的堆没半毛钱关系,就只是撞了名罢了。
堆内存是一大片内存空间,堆内存的分配是动态且不连续的,程序可以按需申请堆内存空间,但是访问速度要比栈内存慢不少。
堆内存里的数据可以长时间存在,无用的数据需要程序主动去回收,如果大量无用数据占用内存就会造成内存泄露(Memory leak)。
简单来说:堆内存适合存放生命周期长,占用空间较大或占用空间不固定的数据。
💡 堆内存的上限
在 Node.js 中,堆内存默认上限在 64 位系统中约为 1.4 GB,在 32 位系统中约为 0.7 GB。
而在 Chrome 浏览器中,每个标签页的内存上限约为 4 GB(64 位系统)和 1 GB(32 位系统)。
💡 进程、线程与堆内存
通常来说,一个进程(Process)只会有一个堆内存,同一进程下的多个线程会共享同一个堆内存。
在 Chrome 浏览器中,一般情况下每个标签页都有单独的进程,不过在某些情况下也会出现多个标签页共享一个进程的情况。
函数调用(Function calling)
明白了栈内存与堆内存是什么后,现在让我们看看当一个函数被调用时,栈内存和堆内存会发生什么变化。
当函数被调用时,会将函数推入栈内存中,生成一个栈帧(Stack frame),栈帧可以理解为由函数的返回地址、参数和局部变量组成的一个块;当函数调用另一个函数时,又会将另一个函数也推入栈内存中,周而复始;直到最后一个函数返回,便从栈顶开始将栈内存中的元素逐个弹出,直到栈内存中不再有元素时则此次调用结束。
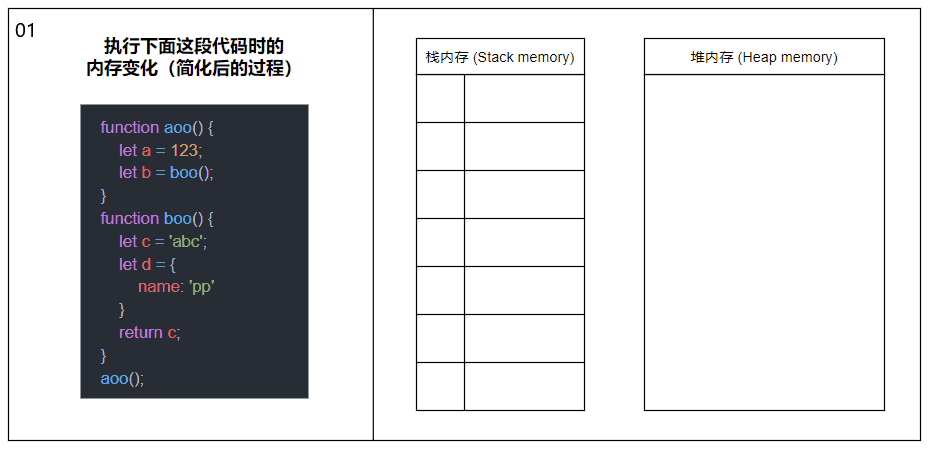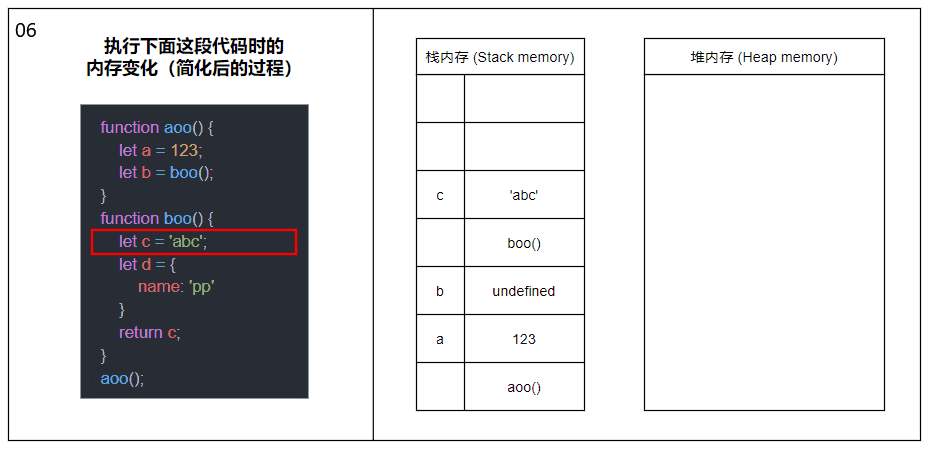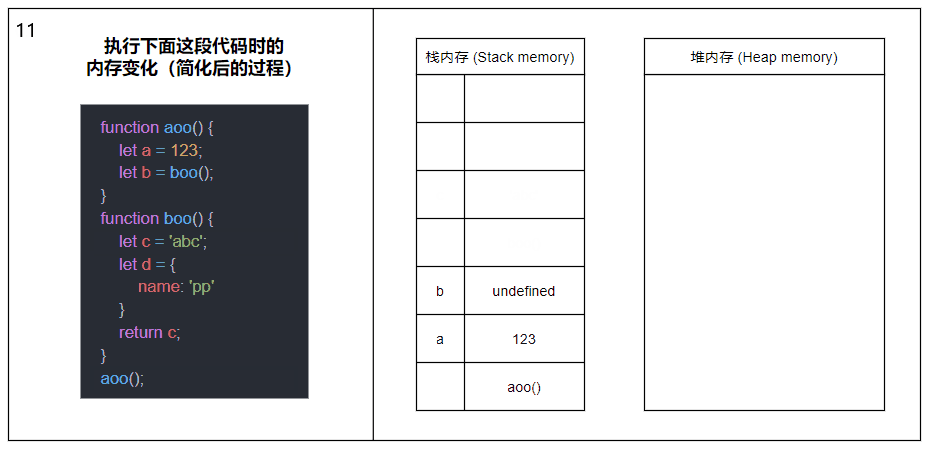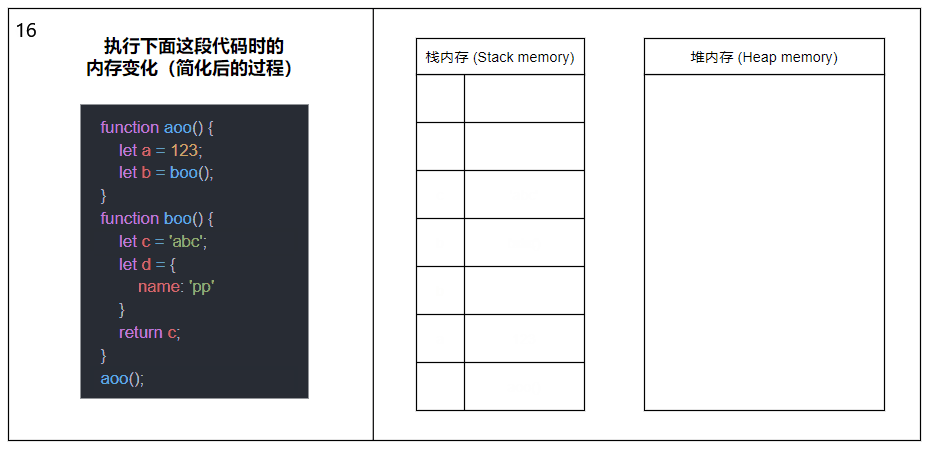
上图中的内容经过了简化,剥离了栈帧和各种指针的概念,主要展示函数调用以及内存分配的大概过程。
在同一线程下(JavaScript 是单线程的),所有被执行的函数以及函数的参数和局部变量都会被推入到同一个栈内存中,这也就是大量递归会导致栈溢出(Stack overflow)的原因。
关于图中涉及到的函数内部变量内存分配的详情请接着往下看。
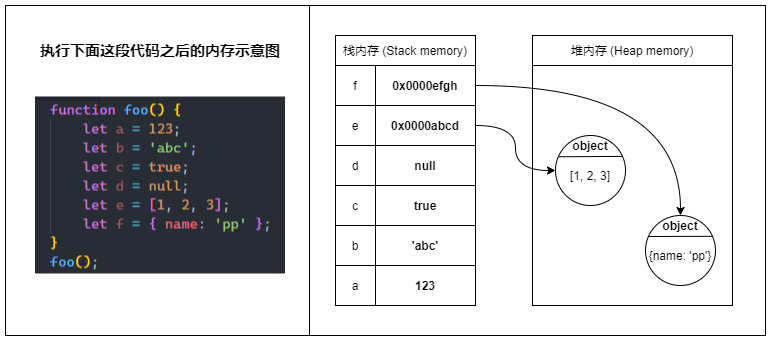
储存变量(Store variables)
当 JavaScript 程序运行时,在非全局作用域中产生的局部变量均储存在栈内存中。
但是,只有原始类型的变量是真正地把值储存在栈内存中。
而引用类型的变量只在栈内存中储存一个引用(reference),这个引用指向堆内存里的真正的值。
💡 原始类型(Primitive type)
原始类型又称基本类型,包括
string、number、bigint、boolean、undefined、null和symbol(ES6 新增)。原始类型的值被称为原始值(Primitive value)。
补充:虽然
typeof null返回的是'object',但是null真的不是对象,会出现这样的结果其实是 JavaScript 的一个 Bug~
💡 引用类型(Reference type)
除了原始类型外,其余类型都属于引用类型,包括
Object、Array、Function、Date、RegExp、String、Number、Boolean等等...实际上
Object是最基本的引用类型,其他引用类型均继承自Object。也就是说,所有引用类型的值实际上都是对象。引用类型的值被称为引用值(Reference value)。
🎃 简单来说
在多数情况下,原始类型的数据储存在栈内存,而引用类型的数据(对象)则储存在堆内存。
特别注意(Attention)
全局变量以及被闭包引用的变量(即使是原始类型)均储存在堆内存中。
🌐 全局变量(Global variables)
在全局作用域下创建的所有变量都会成为全局对象(如 window 对象)的属性,也就是全局变量。
而全局对象储存在堆内存中,所以全局变量必然也会储存在堆内存中。
不要问我为什么全局对象储存在堆内存中,一会我翻脸了啊!
📦 闭包(Closures)
在函数(局部作用域)内创建的变量均为局部变量。
当一个局部变量被当前函数之外的其他函数所引用(也就是发生了逃逸),此时这个局部变量就不能随着当前函数的返回而被回收,那么这个变量就必须储存在堆内存中。
而这里的“其他函数”就是我们说的闭包,就如下面这个例子:
function getCounter() {
let count = 0;
function counter() {
return ++count;
}
return counter;
}
// closure 是一个闭包函数
// 变量 count 发生了逃逸
let closure = getCounter();
closure(); // 1
closure(); // 2
closure(); // 3
闭包是一个非常重要且常用的概念,许多编程语言里都有闭包这个概念。这里就不详细介绍了,贴一篇阮一峰大佬的文章。
学习 JavaScript 闭包:http://www.ruanyifeng.com/blog/2009/08/learning_javascript_closures.html
💡 逃逸分析(Escape Analysis)
实际上,JavaScript 引擎会通过逃逸分析来决定变量是要储存在栈内存还是堆内存中。
简单来说,逃逸分析是一种用来分析变量的作用域的机制。
不可变与可变(Immutable and Mutable)
栈内存中会储存两种变量数据:原始值和对象引用。
不仅类型不同,它们在栈内存中的具体表现也不太一样。
原始值(Primitive values)
🚫 Primitive values are immutable!
前面有说到:原始类型的数据(原始值)直接储存在栈内存中。
⑴ 当我们定义一个原始类型变量的时候,JavaScript 会在栈内存中激活一块内存来储存变量的值(原始值)。
⑵ 当我们更改原始类型变量的值时,实际上会再激活一块新的内存来储存新的值,并将变量指向新的内存空间,而不是改变原来那块内存里的值。
⑶ 当我们将一个原始类型变量赋值给另一个新的变量(也就是复制变量)时,也是会再激活一块新的内存,并将源变量内存里的值复制一份到新的内存里。
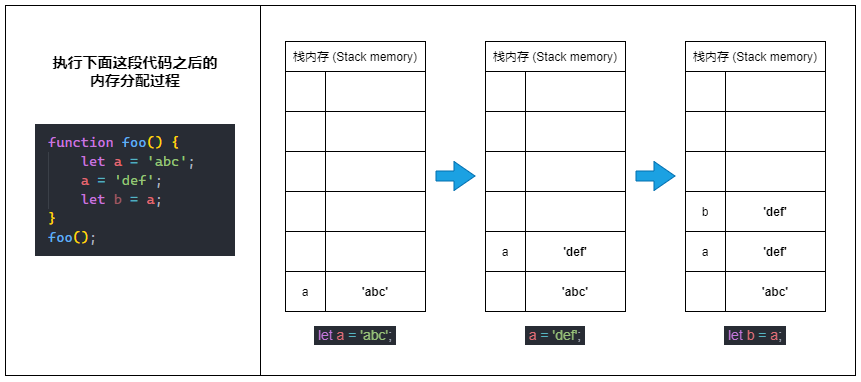
🤠 总之就是:栈内存中的原始值一旦确定就不能被更改(不可变的)。
原始值的比较(Comparison)
当我们比较原始类型的变量时,会直接比较栈内存中的值,只要值相等那么它们就相等。
let a = '123';
let b = '123';
let c = '110';
let d = 123;
console.log(a === b); // true
console.log(a === c); // false
console.log(a === d); // false
对象引用(Object references)
🧩 Object references are mutable!
前面也有说到:引用类型的变量在栈内存中储存的只是一个指向堆内存的引用。
⑴ 当我们定义一个引用类型的变量时,JavaScript 会先在堆内存中找到一块合适的地方来储存对象,并激活一块栈内存来储存对象的引用(堆内存地址),最后将变量指向这块栈内存。
💡 所以当我们通过变量访问对象时,实际的访问过程应该是:
变量 -> 栈内存中的引用 -> 堆内存中的值
⑵ 当我们把引用类型变量赋值给另一个变量时,会将源变量指向的栈内存中的对象引用复制到新变量的栈内存中,所以实际上只是复制了个对象引用,并没有在堆内存中生成一份新的对象。
⑶ 而当我们给引用类型变量分配为一个新的对象时,则会直接修改变量指向的栈内存中的引用,新的引用指向堆内存中新的对象。
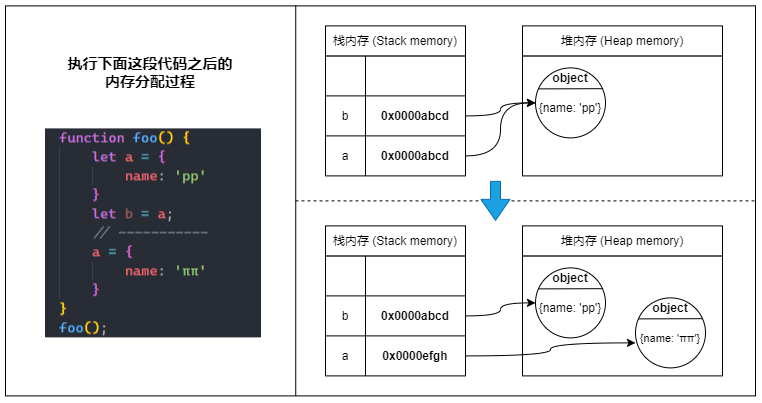
🤠 总之就是:栈内存中的对象引用是可以被更改的(可变的)。
对象的比较(Comparison)
所有引用类型的值实际上都是对象。
当我们比较引用类型的变量时,实际上是在比较栈内存中的引用,只有引用相同时变量才相等。
即使是看起来完全一样的两个引用类型变量,只要他们的引用的不是同一个值,那么他们就是不一样。
// 两个变量指向的是两个不同的引用
// 虽然这两个对象看起来完全一样
// 但它们确确实实是不同的对象实例
let a = { name: 'pp' }
let b = { name: 'pp' }
console.log(a === b); // false
// 直接赋值的方式复制的是对象的引用
let c = a;
console.log(a === c); // true
对象的深拷贝(Deep copy)
当我们搞明白引用类型变量在内存中的表现时,就能清楚地理解为什么浅拷贝对象是不可靠的。
在浅拷贝中,简单的赋值只会复制对象的引用,实际上新变量和源变量引用的都是同一个对象,修改时也是修改的同一个对象,这显然不是我们想要的。
想要真正的复制一个对象,就必须新建一个对象,将源对象的属性复制过去;如果遇到引用类型的属性,那就再新建一个对象,继续复制...
此时我们就需要借助递归来实现多层次对象的复制,这也就是我们说的深拷贝。
对于任何引用类型的变量,都应该使用深拷贝来复制,除非你很确定你的目的就是复制一个引用。
内存生命周期(Memory life cycle)
通常来说,所有应用程序的内存生命周期都是基本一致的:
分配 -> 使用 -> 释放
当我们使用高级语言编写程序时,往往不会涉及到内存的分配与释放操作,因为分配与释放均已经在底层语言中实现了。
对于 JavaScript 程序来说,内存的分配与释放是由 JavaScript 引擎自动完成的(目前的 JavaScript 引擎基本都是使用 C++ 或 C 编写的)。
但是这不意味着我们就不需要在乎内存管理,了解内存的更多细节可以帮助我们写出性能更好,稳定性更高的代码。
垃圾回收(Garbage collection)
垃圾回收即我们常说的 GC(Garbage collection),也就是清除内存中不再需要的数据,释放内存空间。
由于栈内存由操作系统直接管理,所以当我们提到 GC 时指的都是堆内存的垃圾回收。
基本上现在的浏览器的 JavaScript 引擎(如 V8 和 SpiderMonkey)都实现了垃圾回收机制,引擎中的垃圾回收器(Garbage collector)会定期进行垃圾回收。
📢 紧急补课
在我们继续之前,必须先了解“可达性”和“内存泄露”这两个概念:
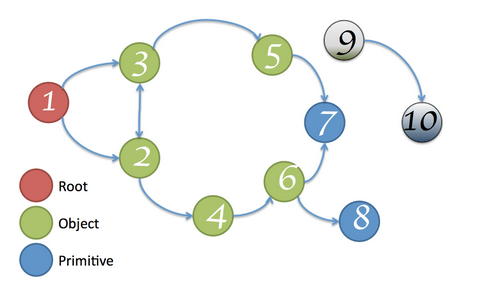
💡 可达性(Reachability)
在 JavaScript 中,可达性指的是一个变量是否能够直接或间接通过全局对象访问到,如果可以那么该变量就是可达的(Reachable),否则就是不可达的(Unreachable)。
可达与不可达 上图中的节点 9 和节点 10 均无法通过节点 1(根节点)直接或间接访问,所以它们都是不可达的,可以被安全地回收。
💡 内存泄漏(Memory leak)
内存泄露指的是程序运行时由于某种原因未能释放那些不再使用的内存,造成内存空间的浪费。
轻微的内存泄漏或许不太会对程序造成什么影响,但是一旦泄露变严重,就会开始影响程序的性能,甚至导致程序的崩溃。
垃圾回收算法(Algorithms)
垃圾回收的基本思路很简单:确定哪个变量不会再使用,然后释放它占用的内存。
实际上,在回收过程中想要确定一个变量是否还有用并不简单。
直到现在也还没有一个真正完美的垃圾回收算法,接下来介绍 3 种最广为人知的垃圾回收算法。
标记-清除(Mark-and-Sweep)
标记清除算法是目前最常用的垃圾收集算法之一。
从该算法的名字上就可以看出,算法的关键就是标记与清除。
标记指的是标记变量的状态的过程,标记变量的具体方法有很多种,但是基本理念是相似的。
对于标记算法我们不需要知道所有细节,只需明白标记的基本原理即可。
需要注意的是,这个算法的效率不算高,同时会引起内存碎片化的问题。
🌰 举个栗子
当一个变量进入执行上下文时,它就会被标记为“处于上下文中”;而当变量离开执行上下文时,则会被标记为“已离开上下文”。
💡 执行上下文(Execution context)
执行上下文是 JavaScript 中非常重要的概念,简单来说的是代码执行的环境。
如果你现在对于执行上下文还不是很了解,我强烈建议你抽空专门去学习下!!!
垃圾回收器将定期扫描内存中的所有变量,将处于上下文中以及被处于上下文中的变量引用的变量的标记去除,将其余变量标记为“待删除”。
随后,垃圾回收器会清除所有带有“待删除”标记的变量,并释放它们所占用的内存。
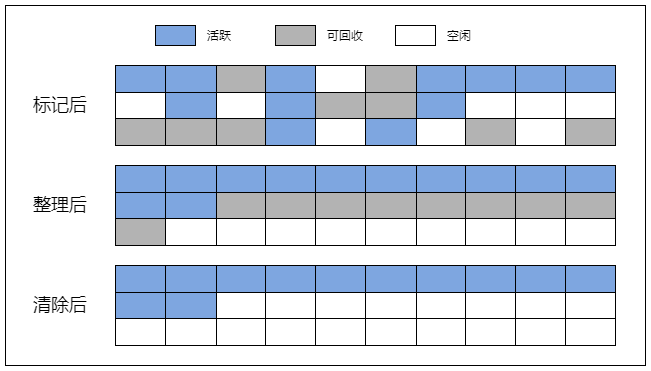
标记-整理(Mark-Compact)
准确来说,Compact 应译为紧凑、压缩,但是在这里我觉得用“整理”更为贴切。
标记整理算法也是常用的垃圾收集算法之一。
使用标记整理算法可以解决内存碎片化的问题(通过整理),提高内存空间的可用性。
但是,该算法的标记阶段比较耗时,可能会堵塞主线程,导致程序长时间处于无响应状态。
虽然算法的名字上只有标记和整理,但这个算法通常有 3 个阶段,即标记、整理与清除。
🌰 以 V8 的标记整理算法为例
① 首先,在标记阶段,垃圾回收器会从全局对象(根)开始,一层一层往下查询,直到标记完所有活跃的对象,那么剩下的未被标记的对象就是不可达的了。
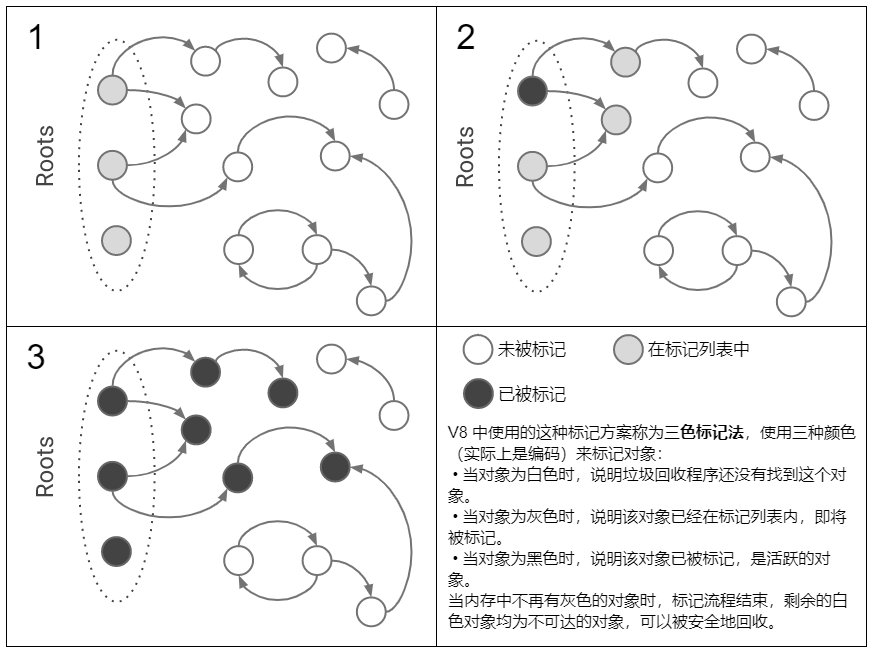
② 然后是整理阶段(碎片整理),垃圾回收器会将活跃的(被标记了的)对象往内存空间的一端移动,这个过程可能会改变内存中的对象的内存地址。
③ 最后来到清除阶段,垃圾回收器会将边界后面(也就是最后一个活跃的对象后面)的对象清除,并释放它们占用的内存空间。
引用计数(Reference counting)
引用计数算法是基于“引用计数”实现的垃圾回收算法,这是最初级但已经被弃用的垃圾回收算法。
引用计数算法需要 JavaScript 引擎在程序运行时记录每个变量被引用的次数,随后根据引用的次数来判断变量是否能够被回收。
虽然垃圾回收已不再使用引用计数算法,但是引用计数技术仍非常有用!
🌰 举个栗子
注意:垃圾回收不是即使生效的!但是在下面的例子中我们将假设回收是立即生效的,这样会更好理解~
// 下面我将 name 属性为 ππ 的对象简称为 ππ
// 而 name 属性为 pp 的对象则简称为 pp
// ππ 的引用:1,pp 的引用:1
let a = {
name: 'ππ',
z: {
name: 'pp'
}
}
// b 和 a 都指向 ππ
// ππ 的引用:2,pp 的引用:1
let b = a;
// x 和 a.z 都指向 pp
// ππ 的引用:2,pp 的引用:2
let x = a.z;
// 现在只有 b 还指向 ππ
// ππ 的引用:1,pp 的引用:2
a = null;
// 现在 ππ 没有任何引用了,可以被回收了
// 在 ππ 被回收后,pp 的引用也会相应减少
// ππ 的引用:0,pp 的引用:1
b = null;
// 现在 pp 也可以被回收了
// ππ 的引用:0,pp 的引用:0
x = null;
// 哦豁,这下全完了!
🔄 循环引用(Circular references)
引用计数算法看似很美好,但是它有一个致命的缺点,就是无法处理循环引用的情况。
在下方的例子中,当 foo() 函数执行完毕之后,对象 a 与 b 都已经离开了作用域,理论上它们都应该能够被回收才对。
但是由于它们互相引用了对方,所以垃圾回收器就认为他们都还在被引用着,导致它们哥俩永远都不会被回收,这就造成了内存泄露。
function foo() {
let a = { o: null };
let b = { o: null };
a.o = b;
b.o = a;
}
foo();
// 即使 foo 函数已经执行完毕
// 对象 a 和 b 均已离开函数作用域
// 但是 a 和 b 还在互相引用
// 那么它们这辈子都不会被回收了
// Oops!内存泄露了!
V8 中的垃圾回收(GC in V8)
8️⃣ V8
V8 是一个由 Google 开源的用 C++ 编写的高性能 JavaScript 引擎。
V8 是目前最流行的 JavaScript 引擎之一,我们熟知的 Chrome 浏览器和 Node.js 等软件都在使用 V8。
在 V8 的内存管理机制中,把堆内存(Heap memory)划分成了多个区域。
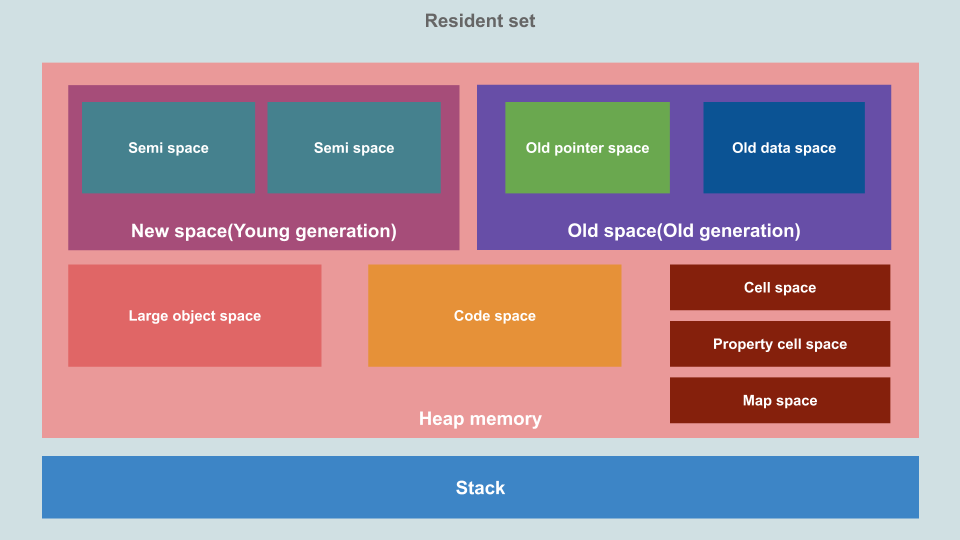
这里我们只关注这两个区域:
New Space(新空间):又称 Young generation(新世代),用于储存新生成的对象,由 Minor GC 进行管理。 Old Space(旧空间):又称 Old generation(旧世代),用于储存那些在两次 GC 后仍然存活的对象,由 Major GC 进行管理。
也就是说,只要 New Space 里的对象熬过了两次 GC,就会被转移到 Old Space,变成老油条。
🧹 双管齐下
V8 内部实现了两个垃圾回收器:
Minor GC(副 GC):它还有个名字叫做 Scavenger(清道夫),具体使用的是 Cheney's Algorithm(Cheney 算法)。 Major GC(主 GC):使用的是文章前面提到的 Mark-Compact Algorithm(标记-整理算法)。
储存在 New Space 里的新生对象大多都只是临时使用的,而且 New Space 的容量比较小,为了保持内存的可用率,Minor GC 会频繁地运行。
而 Old Space 里的对象存活时间都比较长,所以 Major GC 没那么勤快,这一定程度地降低了频繁 GC 带来的性能损耗。
💥 加点魔法
我们在上方的“标记整理算法”中有提到这个算法的标记过程非常耗时,所以很容易导致应用长时间无响应。
为了提升用户体验,V8 还实现了一个名为增量标记(Incremental marking)的特性。
增量标记的要点就是把标记工作分成多个小段,夹杂在主线程(Main thread)的 JavaScript 逻辑中,这样就不会长时间阻塞主线程了。
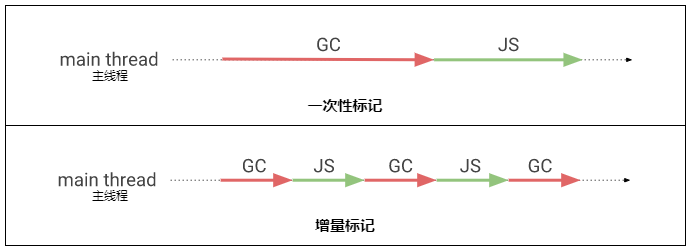
当然增量标记也有代价的,在增量标记过程中所有对象的变化都需要通知垃圾回收器,好让垃圾回收器能够正确地标记那些对象,这里的“通知”也是需要成本的。
另外 V8 中还有使用工作线程(Worker thread)实现的平行标记(Parallel marking)和并行标记(Concurrent marking),这里我就不再细说了~
🤓 总结一下
为了提升性能和用户体验,V8 内部做了非常非常多的“骚操作”,本文提到的都只是冰山一角,但足以让我五体投地佩服连连!
总之就是非常 Amazing 啊~
内存管理(Memory management)
或者说是:内存优化(Memory optimization)?
虽然我们写代码的时候一般不会直接接触内存管理,但是有一些注意事项可以让我们避免引起内存问题,甚至提升代码的性能。
全局变量(Global variable)
全局变量的访问速度远不及局部变量,应尽量避免定义非必要的全局变量。
在我们实际的项目开发中,难免会需要去定义一些全局变量,但是我们必须谨慎使用全局变量。
因为全局变量永远都是可达的,所以全局变量永远不会被回收。
🌐 还记得“可达性”这个概念吗?
因为全局变量直接挂载在全局对象上,也就是说全局变量永远都可以通过全局对象直接访问。
所以全局变量永远都是可达的,而可达的变量永远都不会被回收。
🤨 应该怎么做?
当一个全局变量不再需要用到时,记得解除其引用(置空),好让垃圾回收器可以释放这部分内存。
// 全局变量不会被回收
window.me = {
name: '吴彦祖',
speak: function() {
console.log(`我是${this.name}`);
}
};
window.me.speak();
// 解除引用后才可以被回收
window.me = null;
隐藏类(HiddenClass)
实际上的隐藏类远比本文所提到的复杂,但是今天的主角不是它,所以我们点到为止。
在 V8 内部有一个叫做“隐藏类”的机制,主要用于提升对象(Object)的性能。
V8 里的每一个 JS 对象(JS Objects)都会关联一个隐藏类,隐藏类里面储存了对象的形状(特征)和属性名称到属性的映射等信息。
隐藏类内记录了每个属性的内存偏移(Memory offset),后续访问属性的时候就可以快速定位到对应属性的内存位置,从而提升对象属性的访问速度。
在我们创建对象时,拥有完全相同的特征(相同属性且相同顺序)的对象可以共享同一个隐藏类。
🤯 再想象一下
我们可以把隐藏类想象成工业生产中使用的模具,有了模具之后,产品的生产效率得到了很大的提升。
但是如果我们更改了产品的形状,那么原来的模具就不能用了,又需要制作新的模具才行。
🌰 举个栗子
在 Chrome 浏览器 Devtools 的 Console 面板中执行以下代码:
// 对象 A
let objectA = {
id: 'A',
name: '吴彦祖'
};
// 对象 B
let objectB = {
id: 'B',
name: '彭于晏'
};
// 对象 C
let objectC = {
id: 'C',
name: '刘德华',
gender: '男'
};
// 对象 A 和 B 拥有完全相同的特征
// 所以它们可以使用同一个隐藏类
// good!
随后在 Memory 面板打一个堆快照,通过堆快照中的 Comparison 视图可以快速找到上面创建的 3 个对象:
注:关于如何查看内存中的对象将会在文章的第二大部分中进行讲解,现在让我们专注于隐藏类。

在上图中可以很清楚地看到对象 A 和 B 确实使用了同一个隐藏类。
而对象 C 因为多了一个 gender 属性,所以不能和前面两个对象共享隐藏类。
🧀 动态增删对象属性
一般情况下,当我们动态修改对象的特征(增删属性)时,V8 会为该对象分配一个能用的隐藏类或者创建一个新的隐藏类(新的分支)。
例如动态地给对象增加一个新的属性:
注:这种操作被称为“先创建再补充(ready-fire-aim)”。
// 增加 gender 属性
objectB.gender = '男';
// 对象 B 的特征发生了变化
// 多了一个原本没有的 gender 属性
// 导致对象 B 不能再与 A 共享隐藏类
// bad!
动态删除(delete)对象的属性也会导致同样的结果:
// 删除 name 属性
delete objectB.name;
// A:我们不一样!
// bad!
不过,添加数组索引属性(Array-indexed properties)并不会有影响:
其实就是用整数作为属性名,此时 V8 会另外处理。
// 增加 1 属性
objectB[1] = '数字组引属性';
// 不影响共享隐藏类
// so far so good!
🙄 那问题来了
说了这么多,隐藏类看起来确实可以提升性能,那它和内存又有什么关系呢?
实际上,隐藏类也需要占用内存空间,这其实就是一种用空间换时间的机制。
如果由于动态增删对象属性而创建了大量隐藏类和分支,结果就是会浪费不少内存空间。
🌰 举个栗子
创建 1000 个拥有相同属性的对象,内存中只会多出 1 个隐藏类。
而创建 1000 个属性信息完全不同的对象,内存中就会多出 1000 个隐藏类。
🤔 应该怎么做?
所以,我们要尽量避免动态增删对象属性操作,应该在构造函数内就一次性声明所有需要用到的属性。
如果确实不再需要某个属性,我们可以将属性的值设为 null,如下:
// 将 age 属性置空
objectB.age = null;
// still good!
另外,相同名称的属性尽量按照相同的顺序来声明,可以尽可能地让更多对象共享相同的隐藏类。
即使遇到不能共享隐藏类的情况,也至少可以减少隐藏类分支的产生。
其实动态增删对象属性所引起的性能问题更为关键,但因本文篇幅有限,就不再展开了。
闭包(Closure)
前面有提到:被闭包引用的变量储存在堆内存中。
这里我们再重点关注一下闭包中的内存问题,还是前面的例子:
function getCounter() {
let count = 0;
function counter() {
return ++count;
}
return counter;
}
// closure 是一个闭包函数
let closure = getCounter();
closure(); // 1
closure(); // 2
closure(); // 3
现在只要我们一直持有变量(函数) closure,那么变量 count 就不会被释放。
或许你还没有发现风险所在,不如让我们试想变量 count 不是一个数字,而是一个巨大的数组,一但这样的闭包多了,那对于内存来说就是灾难。
// 我将这个作品称为:闭包炸弹
function closureBomb() {
const handsomeBoys = [];
setInterval(() => {
for (let i = 0; i < 100; i++) {
handsomeBoys.push(
{ name: '陈皮皮', rank: 0 },
{ name: ' 你 ', rank: 1 },
{ name: '吴彦祖', rank: 2 },
{ name: '彭于晏', rank: 3 },
{ name: '刘德华', rank: 4 },
{ name: '郭富城', rank: 5 }
);
}
}, 100);
}
closureBomb();
// 即将毁灭世界
// 💣 🌍 💥 💨
🤔 应该怎么做?
所以,我们必须避免滥用闭包,并且谨慎使用闭包!
当不再需要时记得解除闭包函数的引用,让闭包函数以及引用的变量能够被回收。
closure = null;
// 变量 count 终于得救了
如何分析内存(Analyze)
说了这么多,那我们应该如何查看并分析程序运行时的内存情况呢?
“工欲善其事,必先利其器。”
对于 Web 前端项目来说,分析内存的最佳工具非 Memory 莫属!
这里的 Memory 指的是 DevTools 中的一个工具,为了避免混淆,下面我会用“Memory 面板”或”内存面板“代称。
🔧 DevTools(开发者工具)
DevTools 是浏览器里内置的一套用于 Web 开发和调试的工具。
使用 Chromuim 内核的浏览器都带有 DevTools,个人推荐使用 Chrome 或者 Edge(新)。
Memory in Devtools(内存面板)
在我们切换到 Memory 面板后,会看到以下界面(注意标注):
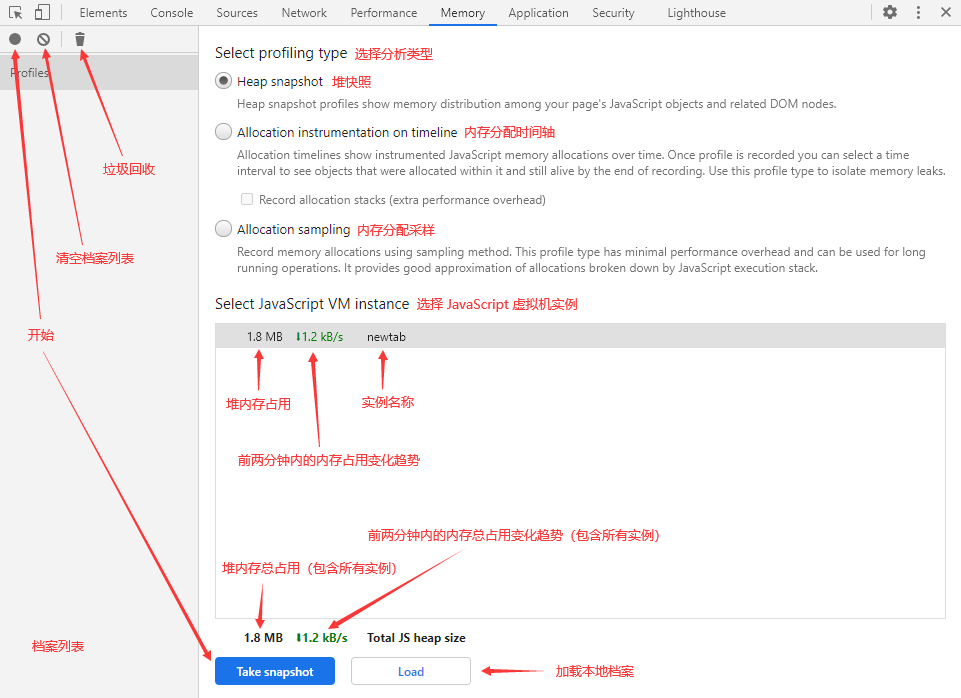
在这个面板中,我们可以通过 3 种方式来记录内存情况:
Heap snapshot:堆快照 Allocation instrumentation on timeline:内存分配时间轴 Allocation sampling:内存分配采样
小贴士:点击面板左上角的 Collect garbage 按钮(垃圾桶图标)可以主动触发垃圾回收。
🤓 在正式开始分析内存之前,让我们先学习几个重要的概念:
💡 Shallow Size(浅层大小)
浅层大小指的是当前对象自身占用的内存大小。
浅层大小不包含自身引用的对象。
💡 Retained Size(保留大小)
保留大小指的是当前对象被 GC 回收后总共能够释放的内存大小。
换句话说,也就是当前对象自身大小加上对象直接或间接引用的其他对象的大小总和。
需要注意的是,保留大小不包含那些除了被当前对象引用之外还被全局对象直接或间接引用的对象。
Heap snapshot(堆快照)

堆快照可以记录页面当前时刻的 JS 对象以及 DOM 节点的内存分配情况。
🚀 如何开始
点击页面底部的 Take snapshot 按钮或者左上角的 ⚫ 按钮即可打一个堆快照,片刻之后就会自动展示结果。
在堆快照结果页面中,我们可以使用 4 种不同的视图来观察内存情况:
Summary:摘要视图 Comparison:比较视图 Containment:包含视图 Statistics:统计视图
默认显示 Summary 视图。
Summary(摘要视图)
摘要视图根据 Constructor(构造函数)来将对象进行分组,我们可以在 Class filter(类过滤器)中输入构造函数名称来快速筛选对象。
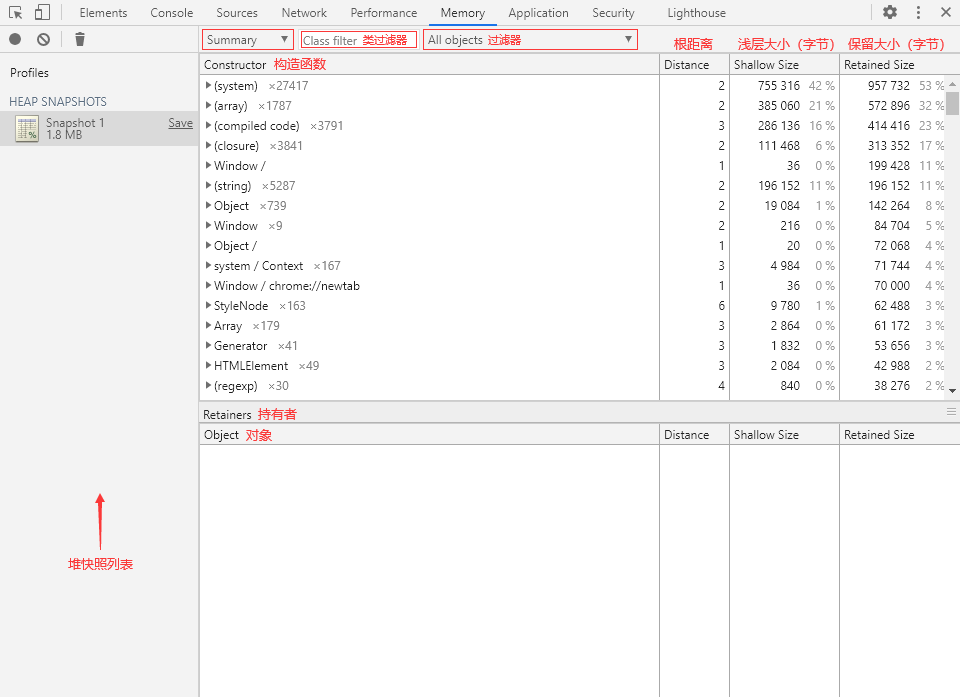
页面中的几个关键词:
Constructor:构造函数。 Distance:(根)距离,对象与 GC 根之间的最短距离。 Shallow Size:浅层大小,单位:Bytes(字节)。 Retained Size:保留大小,单位:Bytes(字节)。 Retainers:持有者,也就是直接引用目标对象的变量。
📌 Retainers(持有者)
Retainers 栏在旧版的 Devtools 里叫做 Object's retaining tree(对象保留树)。
Retainers 下的对象也展开为树形结构,方便我们进行引用溯源。
在视图中的构造函数列表中,有一些用“()”包裹的条目:
(compiled code):已编译的代码。 (closure):闭包函数。 (array, string, number, symbol, regexp):对应类型( Array、String、Number、Symbol、RegExp)的数据。(concatenated string):使用 concat()函数拼接而成的字符串。(sliced string):使用 slice()、substring()等函数进行边缘切割的字符串。(system):系统(引擎)产生的对象,如 V8 创建的 HiddenClasses(隐藏类)和 DescriptorArrays(描述符数组)等数据。
💡 DescriptorArrays(描述符数组)
描述符数组主要包含对象的属性名信息,是隐藏类的重要组成部分。
不过描述符数组内不会包含整数索引属性。
而其余没有用“()”包裹的则为全局属性和 GC 根。
另外,每个对象后面都会有一串“@”开头的数字,这是对象在内存中的唯一 ID。
小贴士:按下快捷键 Ctrl/Command + F 展示搜索栏,输入名称或 ID 即可快速查找目标对象。
💪 实践一下:实例化一个对象
① 切换到 Console 面板,执行以下代码来实例化一个对象:
function TestClass() {
this.number = 123;
this.string = 'abc';
this.boolean = true;
this.symbol = Symbol('test');
this.undefined = undefined;
this.null = null;
this.object = { name: 'pp' };
this.array = [1, 2, 3];
this.getSet = {
_value: 0,
get value() {
return this._value;
},
set value(v) {
this._value = v;
}
};
}
let testObject = new TestClass();
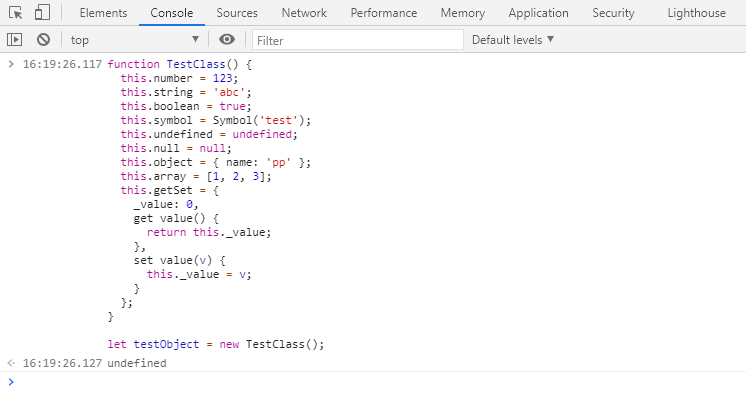
② 回到 Memory 面板,打一个堆快照,在 Class filter 中输入“TestClass”:
可以看到内存中有一个 TestClass 的实例,该实例的浅层大小为 80 字节,保留大小为 876 字节。

🤔 注意到了吗?
堆快照中的
TestClass实例的属性中少了一个名为number属性,这是因为堆快照不会捕捉数字属性。
💪 实践一下:创建一个字符串
① 切换到 Console 面板,执行以下代码来创建一个字符串:
// 这是一个全局变量
let testString = '我是吴彦祖';
② 回到 Memory 面板,打一个堆快照,打开搜索栏(Ctrl/Command + F)并输入“我是吴彦祖”:
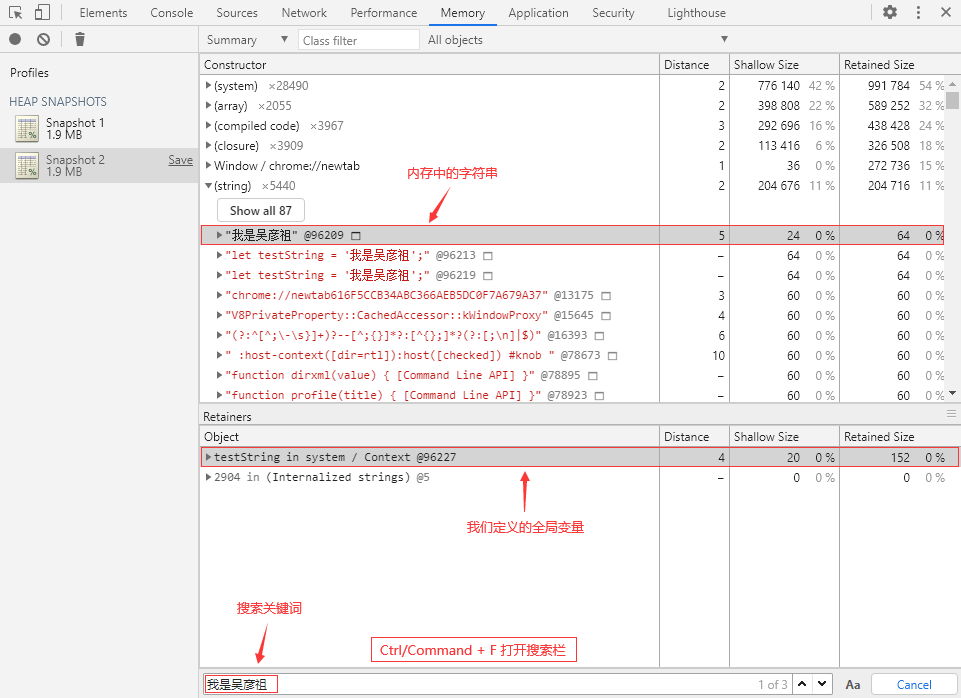
Comparison(比较视图)
只有同时存在 2 个或以上的堆快照时才会出现 Comparison 选项。
比较视图用于展示两个堆快照之间的差异。
使用比较视图可以让我们快速得知在执行某个操作后的内存变化情况(如新增或减少对象)。
通过多个快照的对比还可以让我们快速判断并定位内存泄漏。
文章前面提到隐藏类的时候,就是使用了比较视图来快速查找新创建的对象。
💪 实践一下
① 新建一个无痕(匿名)标签页并切换到 Memory 面板,打一个堆快照 Snapshot 1。
💡 为什么是无痕标签页?
普通标签页会受到浏览器扩展或者其他脚本影响,内存占用不稳定。
使用无痕窗口的标签页可以保证页面的内存相对纯净且稳定,有利于我们进行对比。
另外,建议打开窗口一段之间之后再开始测试,这样内存会比较稳定(控制变量)。
② 切换到 Console 面板,执行以下代码来实例化一个 Foo 对象:
function Foo() {
this.name = 'pp';
this.age = 18;
}
let foo = new Foo();
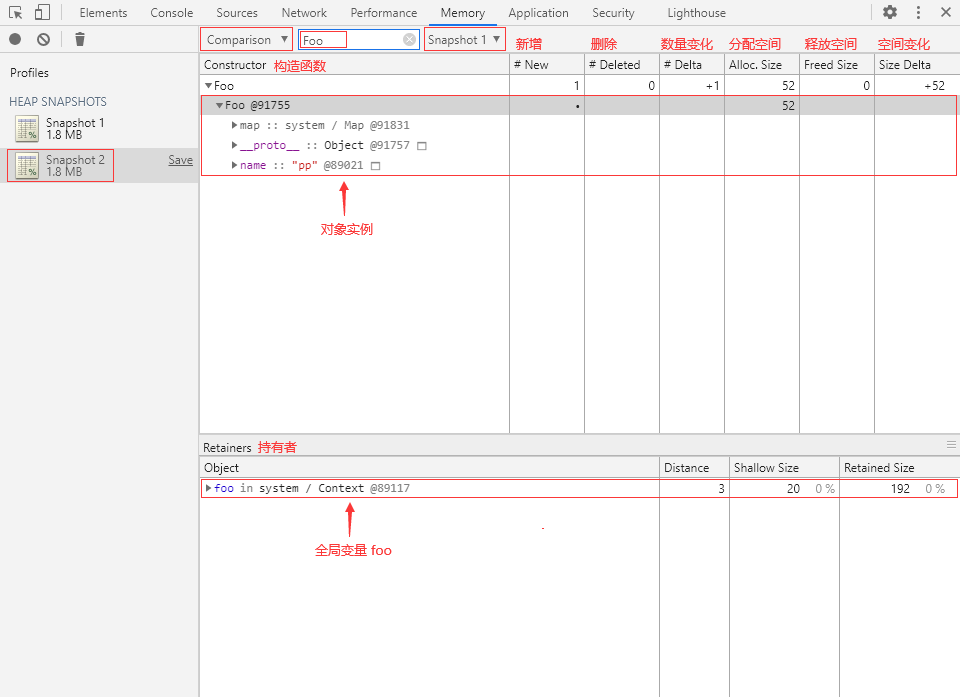
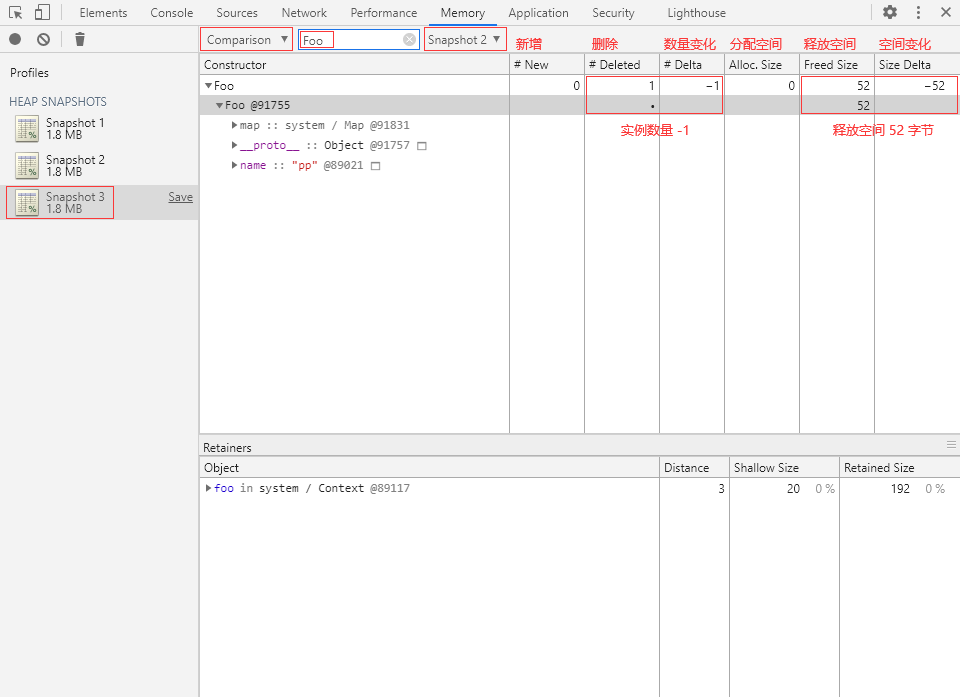
③ 回到 Memory 面板,再打一个堆快照 Snapshot 2,切换到 Comparison 视图,选择 Snapshot 1 作为 Base snapshot(基本快照),在 Class filter 中输入“Foo”:
可以看到内存中新增了一个 Foo 对象实例,分配了 52 字节内存空间,该实例的引用持有者为变量 foo。
④ 再次切换到 Console 面板,执行以下代码来解除变量 foo 的引用:
// 解除对象的引用
foo = null;
⑤ 再回到 Memory 面板,打一个堆快照 Snapshot 3,选择 Snapshot 2 作为 Base snapshot,在 Class filter 中输入“Foo”:
内存中的 Foo 对象实例已经被删除,释放了 52 字节的内存空间。
Containment(包含视图)
包含视图就是程序对象结构的“鸟瞰图(Bird's eye view)”,允许我们通过全局对象出发,一层一层往下探索,从而了解内存的详细情况。
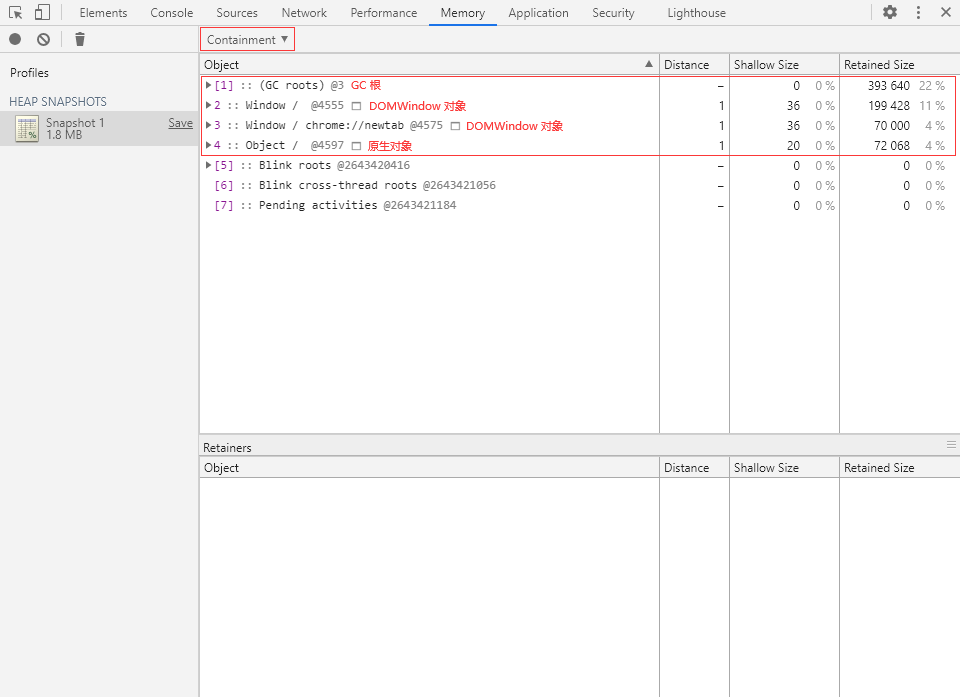
包含视图中有以下几种全局对象:
GC roots(GC 根)
GC roots 就是 JavaScript 虚拟机的垃圾回收中实际使用的根节点。
GC 根可以由 Built-in object maps(内置对象映射)、Symbol tables(符号表)、VM thread stacks(VM 线程堆栈)、Compilation caches(编译缓存)、Handle scopes(句柄作用域)和 Global handles(全局句柄)等组成。
DOMWindow objects(DOMWindow 对象)
DOMWindow objects 指的是由宿主环境(浏览器)提供的顶级对象,也就是 JavaScript 代码中的全局对象 window,每个标签页都有自己的 window 对象(即使是同一窗口)。
Native objects(原生对象)
Native objects 指的是那些基于 ECMAScript 标准实现的内置对象,包括 Object、Function、Array、String、Boolean、Number、Date、RegExp、Math 等对象。
💪 实践一下
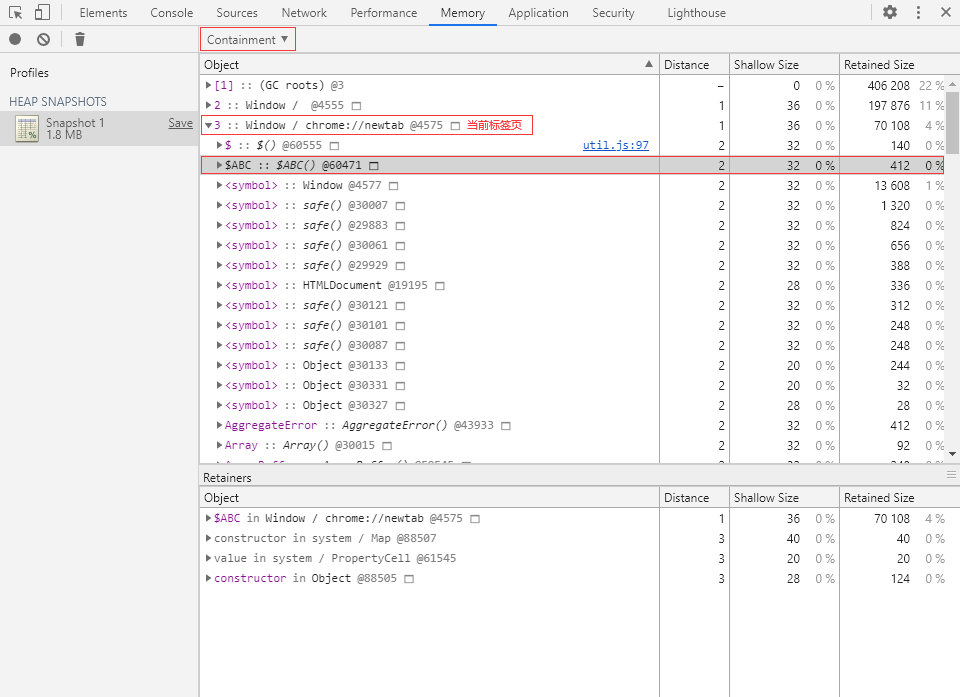
① 切换到 Console 面板,执行以下代码来创建一个构造函数 $ABC:
构造函数命名前面加个 $ 是因为这样排序的时候可以排在前面,方便找。
function $ABC() {
this.name = 'pp';
}
② 切换到 Memory 面板,打一个堆快照,切换为 Containment 视图:
在当前标签页的全局对象下就可以找到我们刚刚创建的构造函数 $ABC。
Statistics(统计视图)
统计视图可以很直观地展示内存整体分配情况。
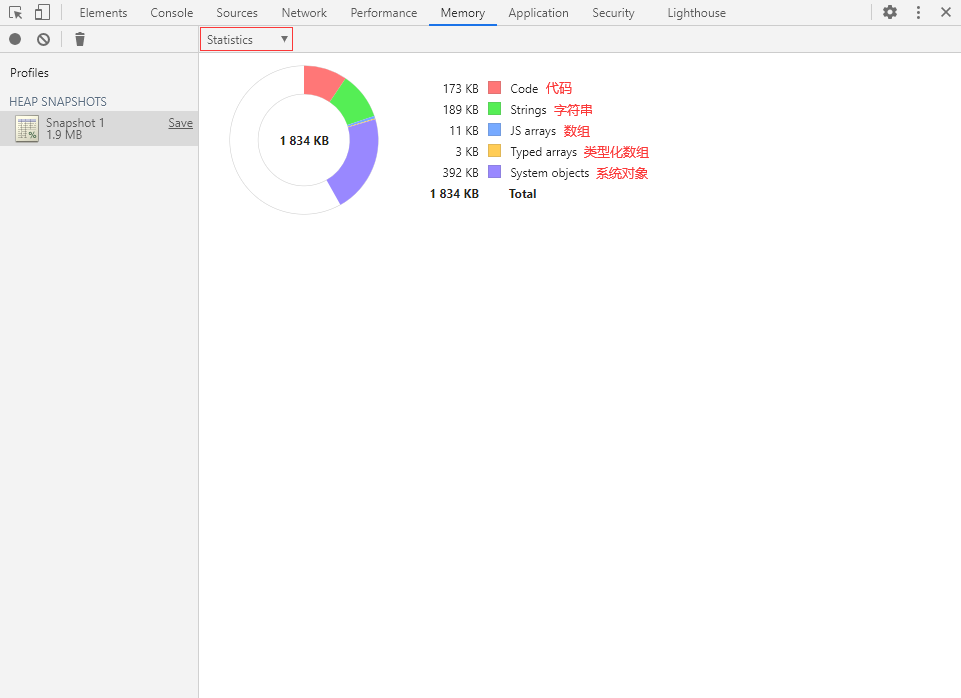
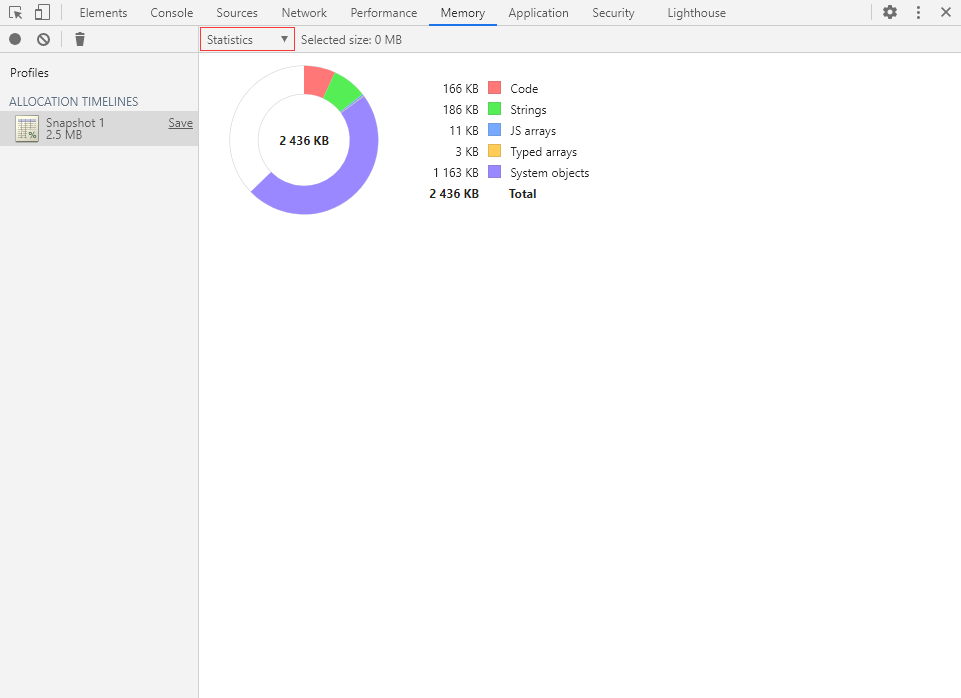
在该视图里的空心饼图中共有 6 种颜色,各含义分别为:
红色:Code(代码) 绿色:Strings(字符串) 蓝色:JS arrays(数组) 橙色:Typed arrays(类型化数组) 紫色:System objects(系统对象) 白色:空闲内存
Allocation instrumentation on timeline(分配时间轴)
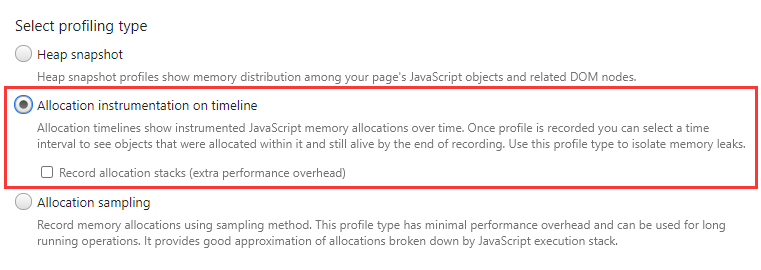
在一段时间内持续地记录内存分配(约每 50 毫秒打一张堆快照),记录完成后可以选择查看任意时间段的内存分配详情。
另外还可以勾选同时记录分配堆栈(Allocation stacks),也就是记录调用堆栈,不过这会产生额外的性能消耗。
🚀 如何开始
点击页面底部的 Start 按钮或者左上角的 ⚫ 按钮即可开始记录,记录过程中点击左上角的 🔴 按钮来结束记录,片刻之后就会自动展示结果。
💪 操作一下
① 打开 Memory 面板,开始记录分配时间轴。
② 切换到 Console 面板,执行以下代码:
代码效果:每隔 1 秒钟创建 100 个对象,共创建 1000 个对象。
console.log('测试开始');
let objects = [];
let handler = setInterval(() => {
// 每秒创建 100 个对象
for (let i = 0; i < 100; i++) {
const name = `n${objects.length}`;
const value = `v${objects.length}`;
objects.push({ [name]: value});
}
console.log(`对象数量:${objects.length}`);
// 达到 1000 个后停止
if (objects.length >= 1000) {
clearInterval(handler);
console.log('测试结束');
}
}, 1000);
😈 又是一个细节
不知道你有没有发现,在上面的代码中,我干了一件坏事。
在 for 循环创建对象时,会根据对象数组当前长度生成一个唯一的属性名和属性值。
这样一来 V8 就无法对这些对象进行优化,方便我们进行测试。
另外,如果直接使用对象数组的长度作为属性名会有惊喜~
③ 静静等待 10 秒钟,控制台会打印出“测试结束”。
④ 切换回 Memory 面板,停止记录,片刻之后会自动进入结果页面。
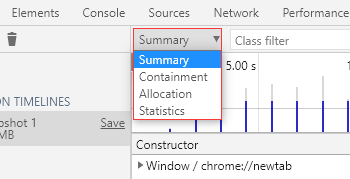
分配时间轴结果页有 4 种视图:
Summary:摘要视图 Containment:包含视图 Allocation:分配视图 Statistics:统计视图
默认显示 Summary 视图。
Summary(摘要视图)
看起来和堆快照的摘要视图很相似,主要是页面上方多了一条横向的时间轴(Timeline)。
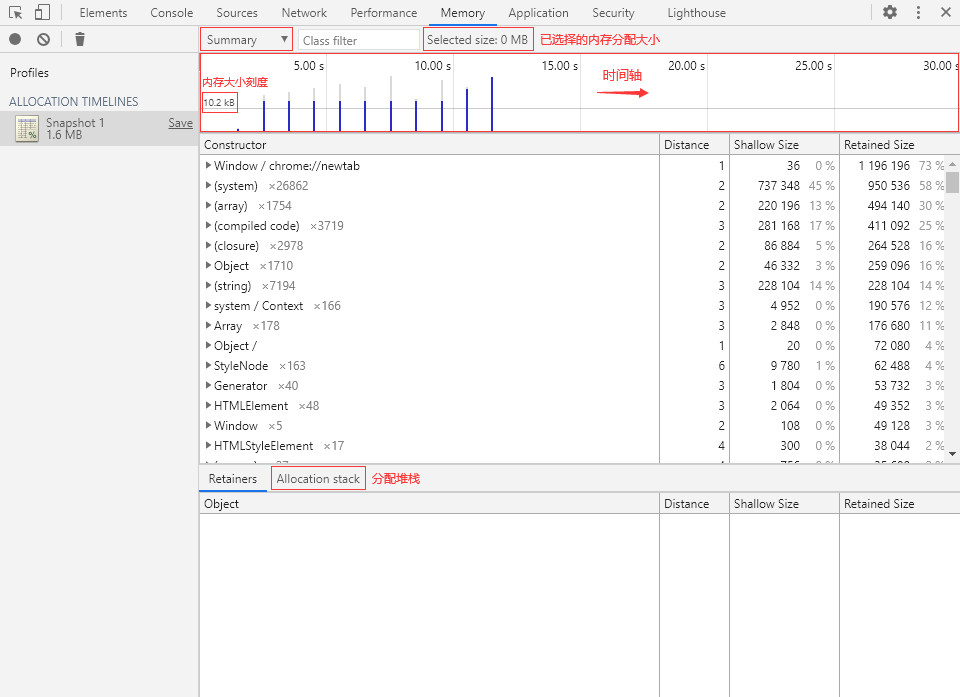
🧭 时间轴
时间轴中主要的 3 种线:
细横线:内存分配大小刻度线 蓝色竖线:表示内存在对应时刻被分配,最后仍然活跃 灰色竖线:表示内存在对应时刻被分配,但最后被回收
时间轴的几个操作:
鼠标移动到时间轴内任意位置,点击左键或长按左键并拖动即可选择一段时间 鼠标拖动时间段框上方的方块可以对已选择的时间段进行调整 鼠标移到已选择的时间段框内部,滑动滚轮可以调整时间范围 鼠标移到已选择的时间段框两旁,滑动滚轮即可调整时间段 双击鼠标左键即可取消选择
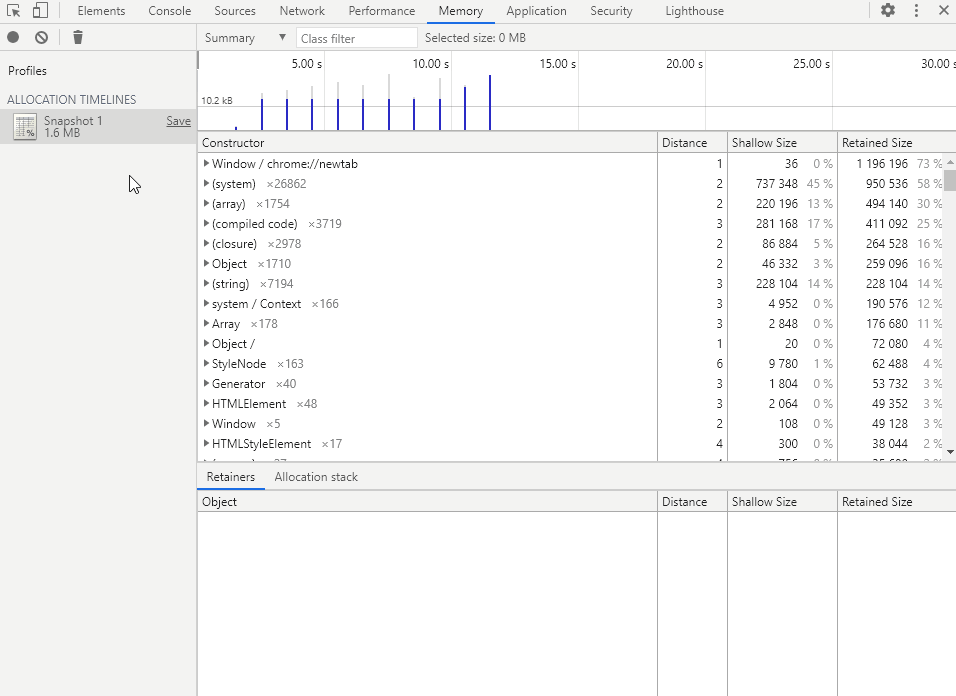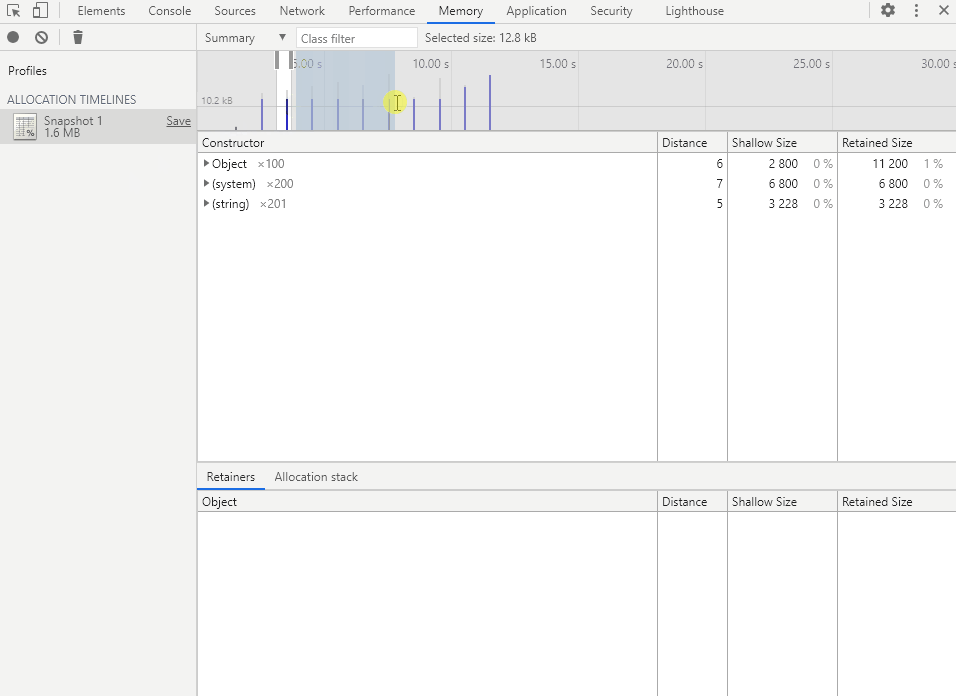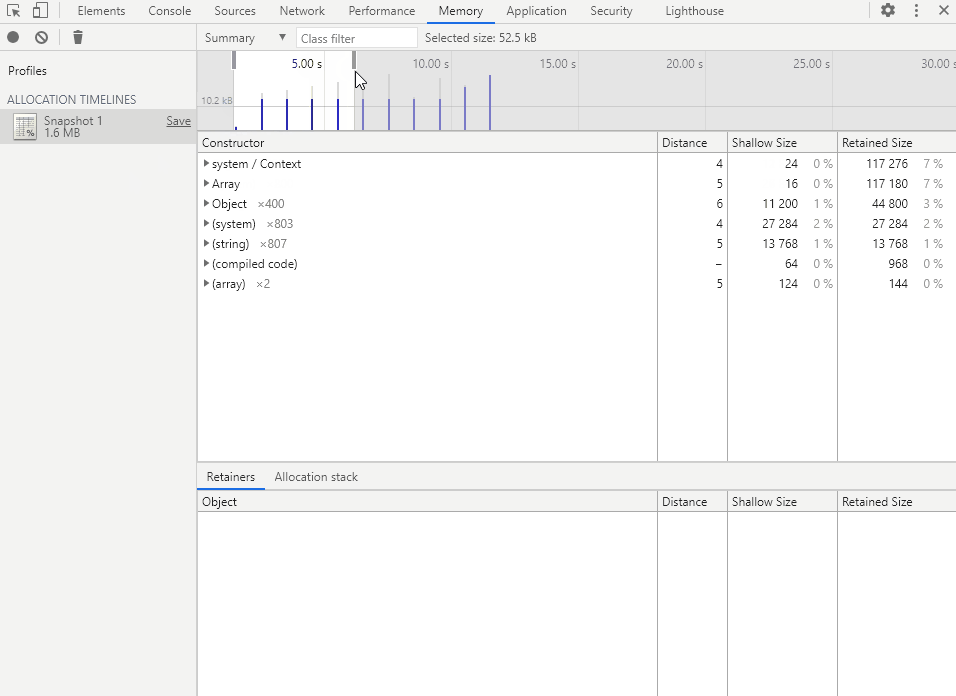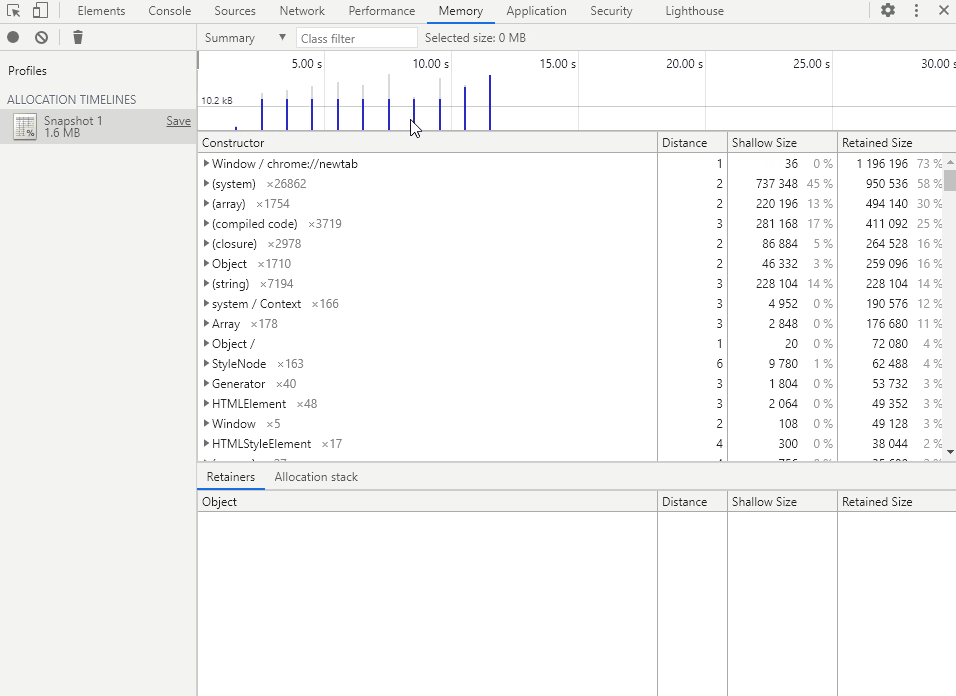
在时间轴中选择要查看的时间段,即可得到该段时间的内存分配详情。
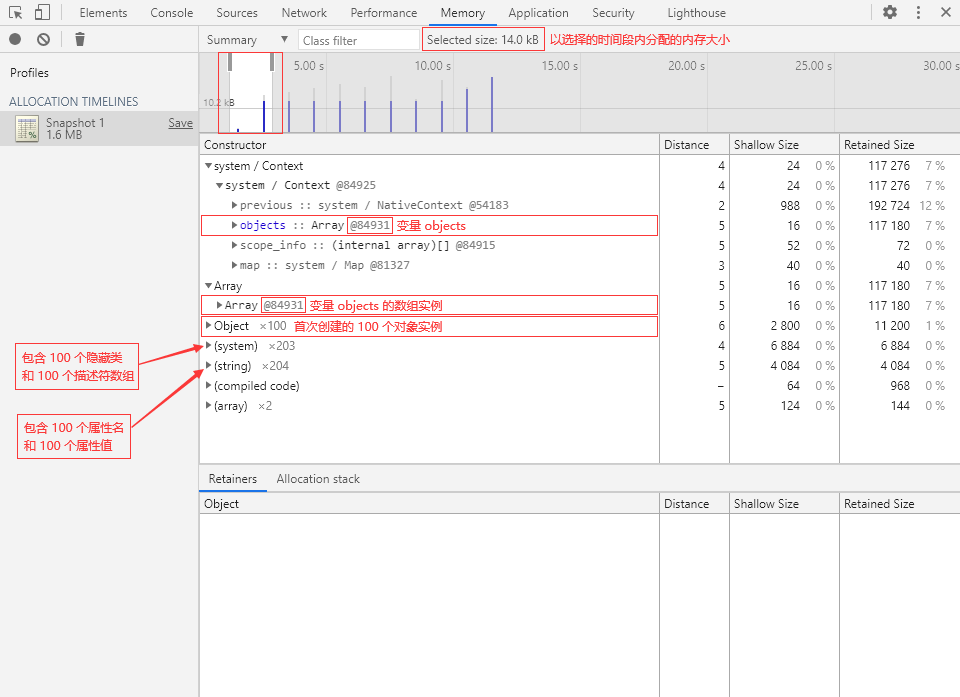
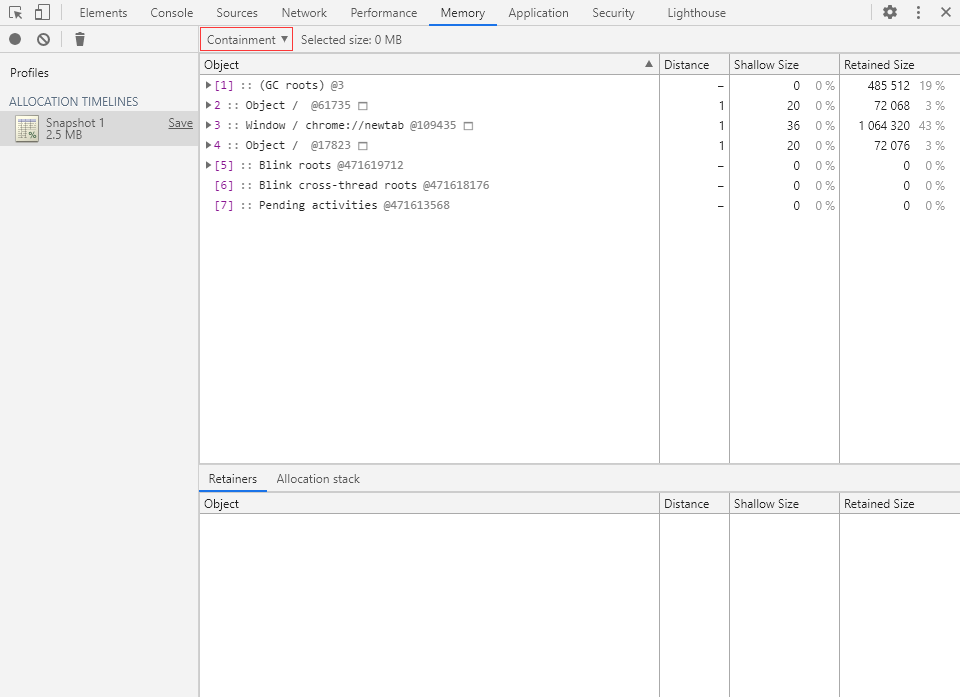
Containment(包含视图)
分配时间轴的包含视图与堆快照的包含视图是一样的,这里就不再重复介绍了。
Allocation(分配视图)
对不起各位,这玩意儿我也不知道有啥用...
打开就直接报错,我:喵喵喵?
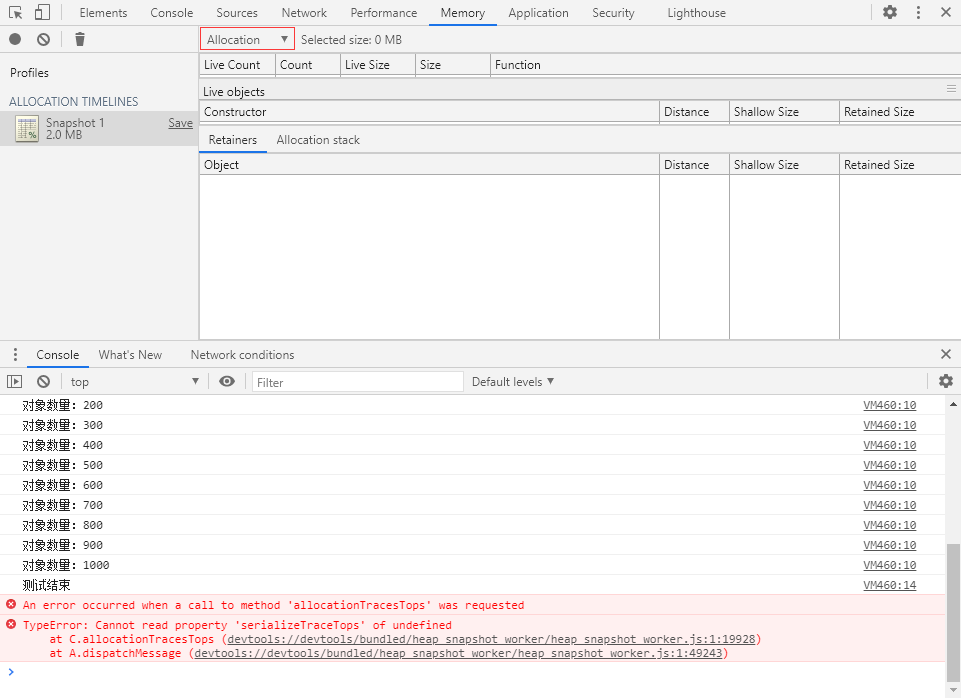
是不是因为没人用这玩意儿,所以没人发现有问题...
Statistics(统计视图)
分配时间轴的统计视图与堆快照的统计视图也是一样的,不再赘述。
Allocation sampling(分配采样)

Memory 面板上的简介:使用采样方法记录内存分配。这种分析方式的性能开销最小,可以用于长时间的记录。
好家伙,这个简介有够模糊,说了跟没说似的,很有精神!
我在官方文档里没有找到任何关于分配采样的介绍,Google 上也几乎没有与之有关的信息。所以以下内容仅为个人实践得出的结果,如有不对的地方欢迎各位指出!
简单来说,通过分配采样我们可以很直观地看到代码中的每个函数(API)所分配的内存大小。
由于是采样的方式,所以结果并非百分百准确,即使每次执行相同的操作也可能会有不同的结果,但是足以让我们了解内存分配的大体情况。
✍ 如何开始
点击页面底部的 Start 按钮或者左上角的 ⚫ 按钮即可开始记录,记录过程中点击左上角的 🔴 按钮来结束记录,片刻之后就会自动展示结果。
💪 操作一下
① 打开 Memory 面板,开始记录分配采样。
② 切换到 Console 面板,执行以下代码:
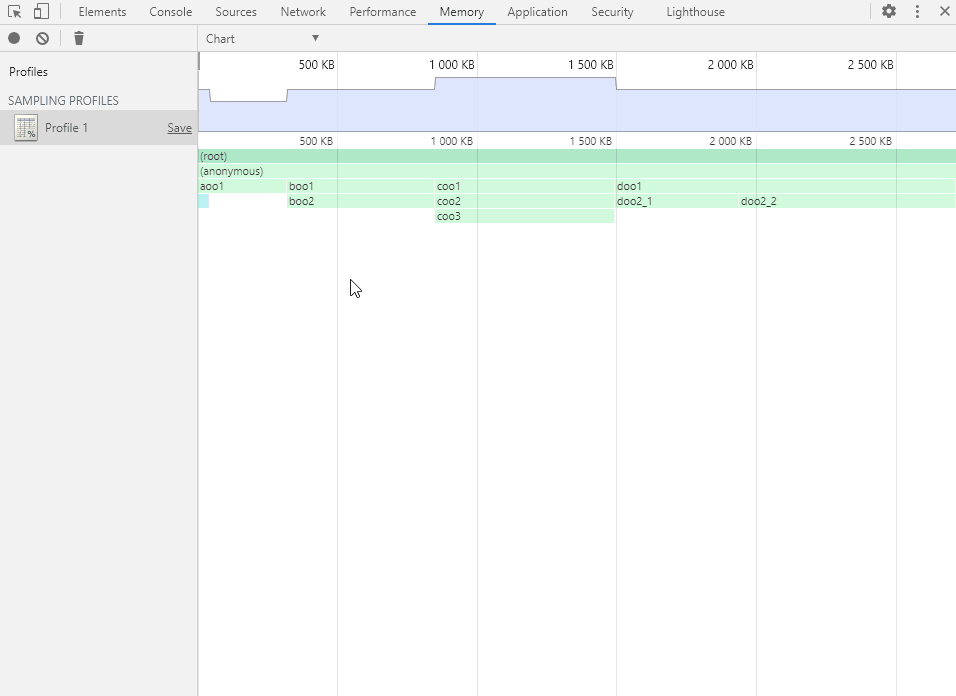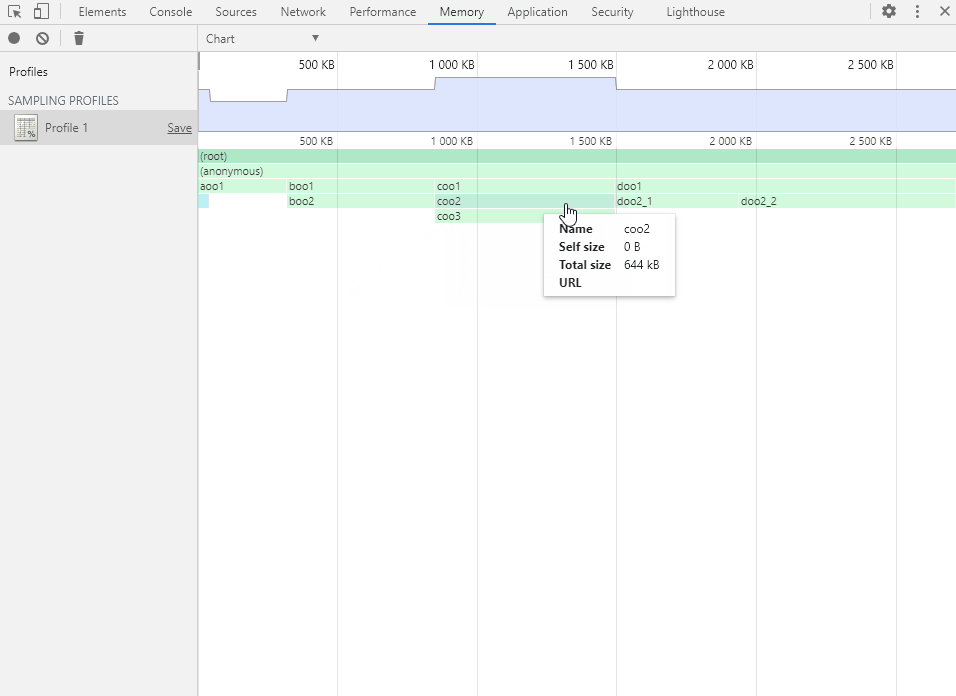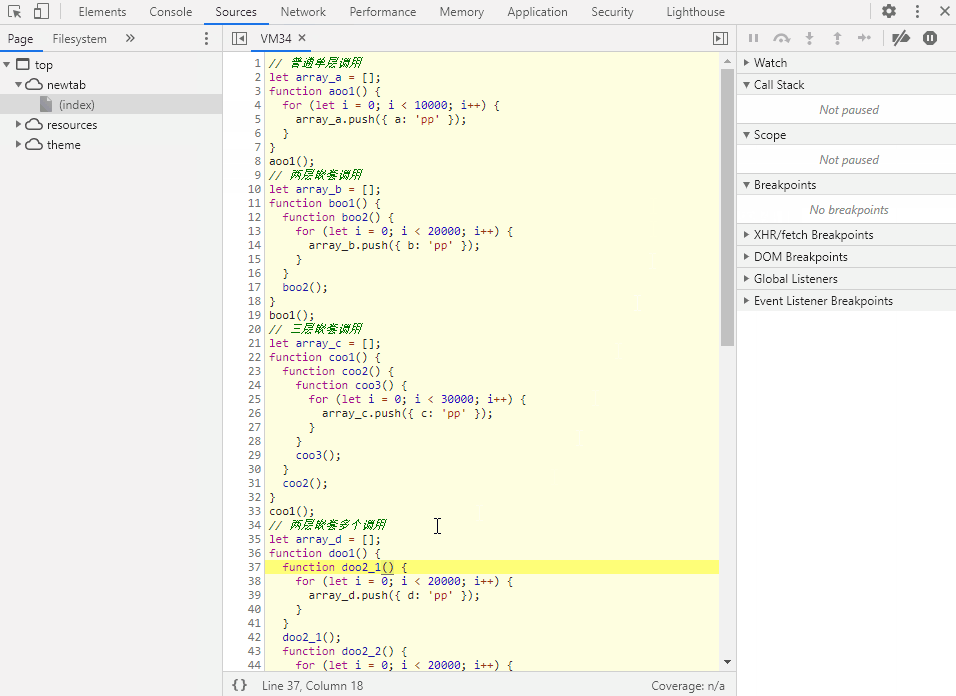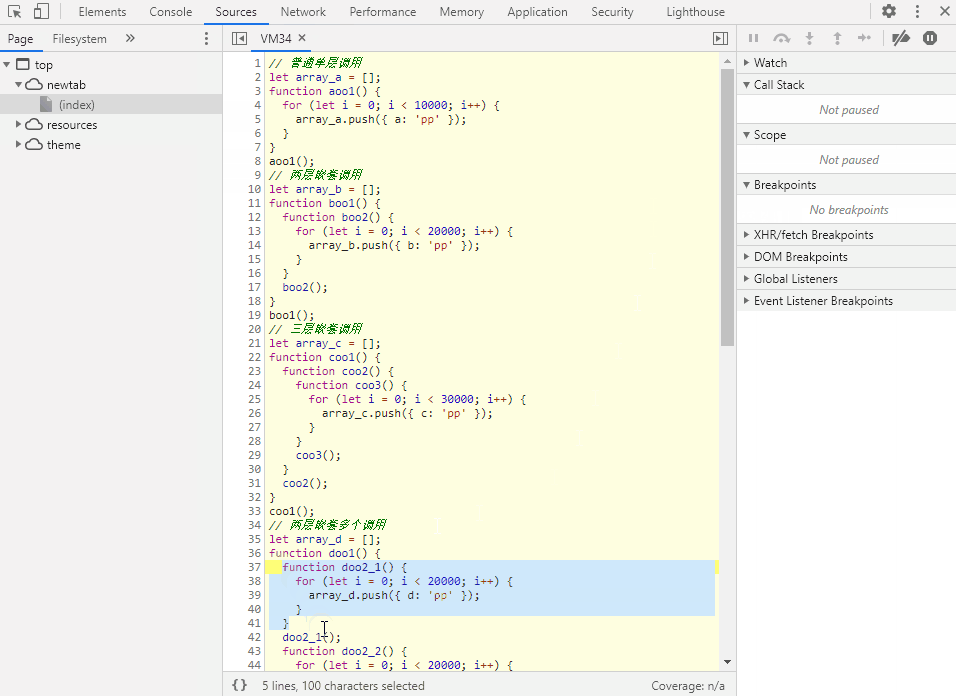
代码看起来有点长,其实就是 4 个函数分别以不同的方式往数组里面添加对象。
// 普通单层调用
let array_a = [];
function aoo1() {
for (let i = 0; i < 10000; i++) {
array_a.push({ a: 'pp' });
}
}
aoo1();
// 两层嵌套调用
let array_b = [];
function boo1() {
function boo2() {
for (let i = 0; i < 20000; i++) {
array_b.push({ b: 'pp' });
}
}
boo2();
}
boo1();
// 三层嵌套调用
let array_c = [];
function coo1() {
function coo2() {
function coo3() {
for (let i = 0; i < 30000; i++) {
array_c.push({ c: 'pp' });
}
}
coo3();
}
coo2();
}
coo1();
// 两层嵌套多个调用
let array_d = [];
function doo1() {
function doo2_1() {
for (let i = 0; i < 20000; i++) {
array_d.push({ d: 'pp' });
}
}
doo2_1();
function doo2_2() {
for (let i = 0; i < 20000; i++) {
array_d.push({ d: 'pp' });
}
}
doo2_2();
}
doo1();
③ 切换回 Memory 面板,停止记录,片刻之后会自动进入结果页面。
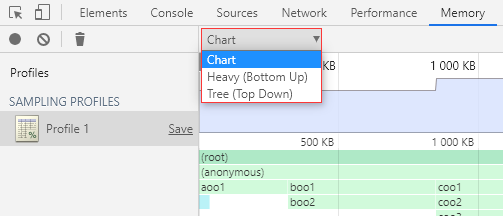
分配采样结果页有 3 种视图可选:
Chart:图表视图 Heavy (Bottom Up):扁平视图(调用层级自下而上) Tree (Top Down):树状视图(调用层级自上而下)
这个 Heavy 我真的不知道该怎么翻译,所以我就按照具体表现来命名了。
默认会显示 Chart 视图。
Chart(图表视图)
Chart 视图以图形化的表格形式展现各个函数的内存分配详情,可以选择精确到内存分配的不同阶段(以内存分配的大小为轴)。

鼠标左键点击、拖动和双击以操作内存分配阶段轴(和时间轴一样),选择要查看的阶段范围。
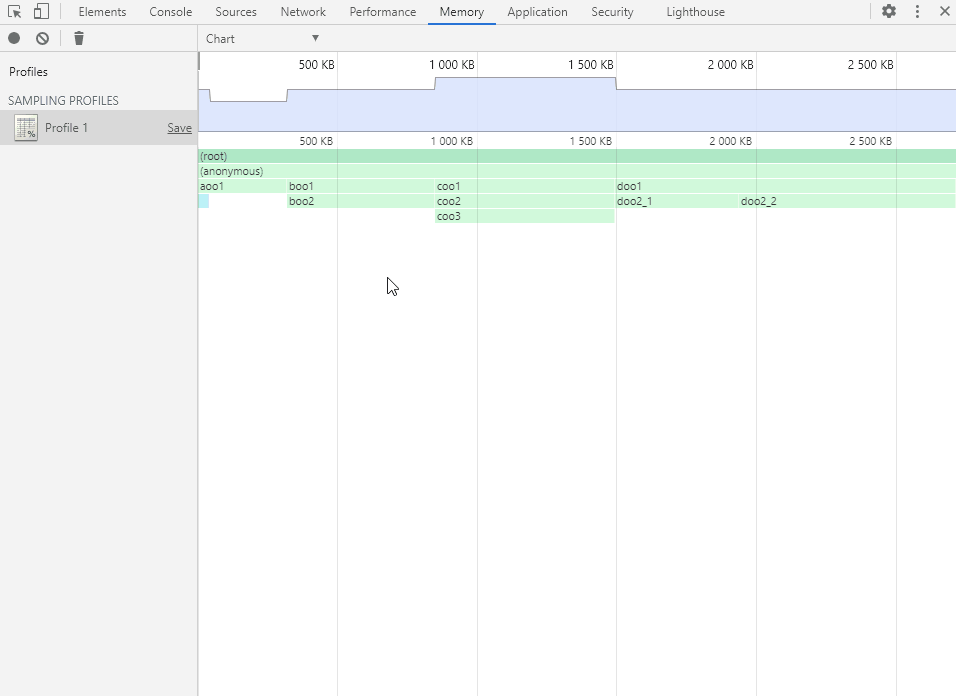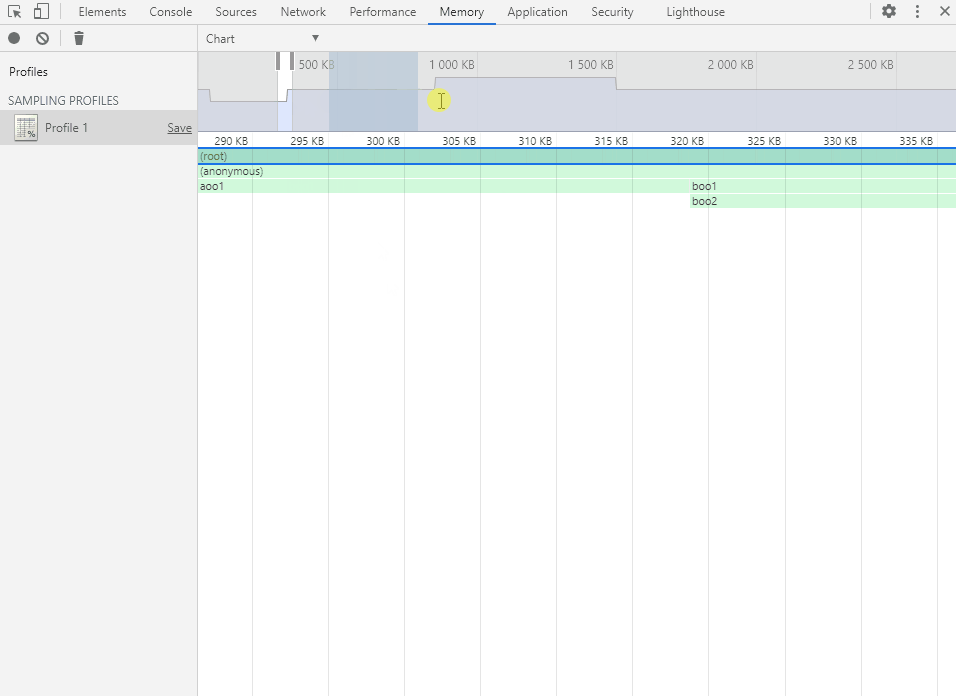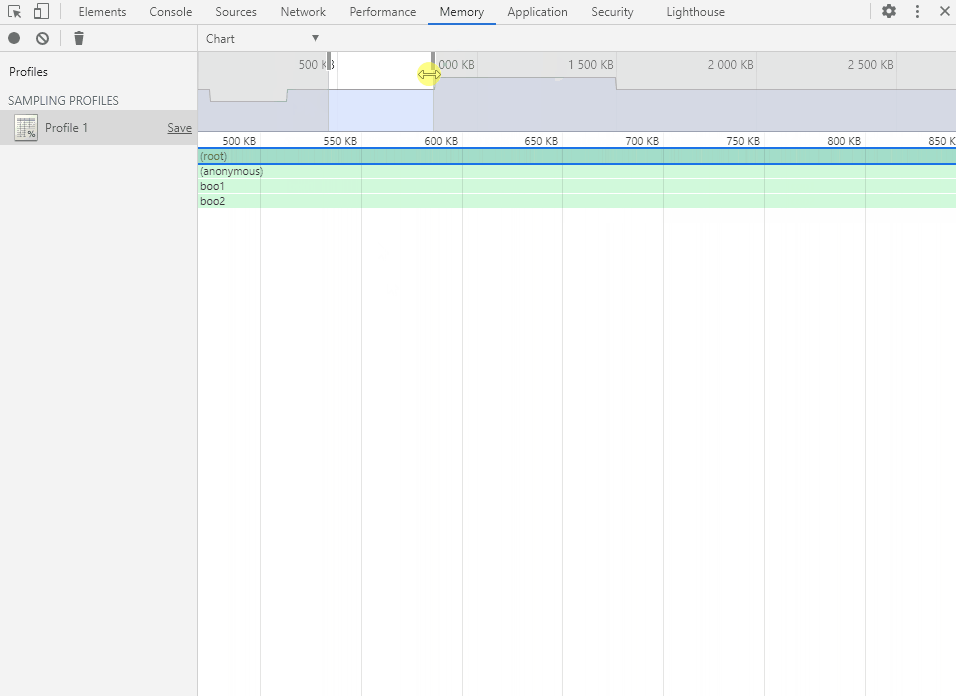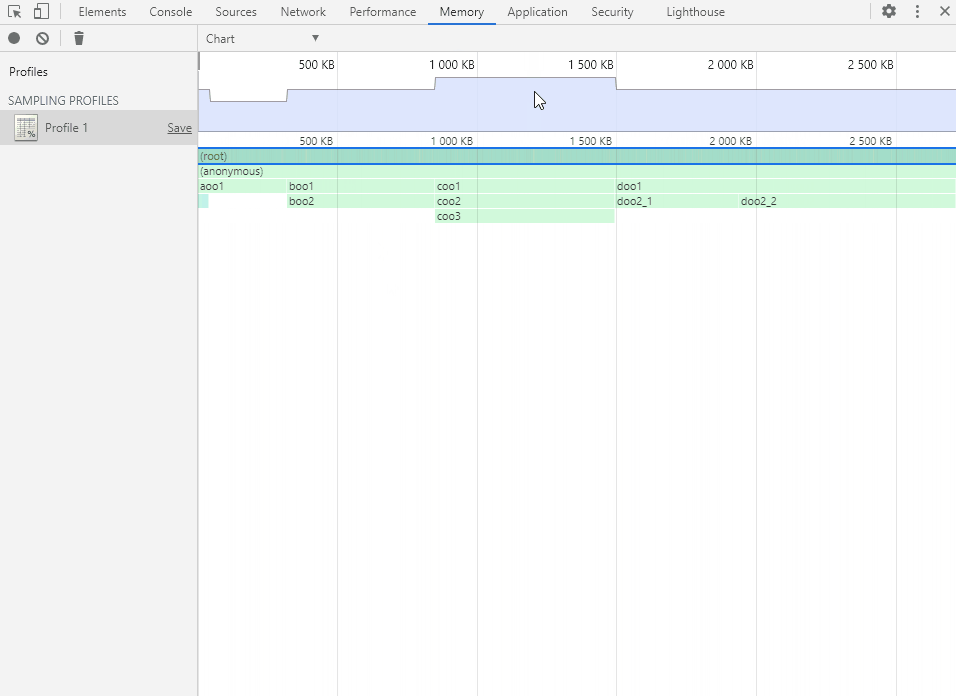
将鼠标移动到函数方块上会显示函数的内存分配详情。
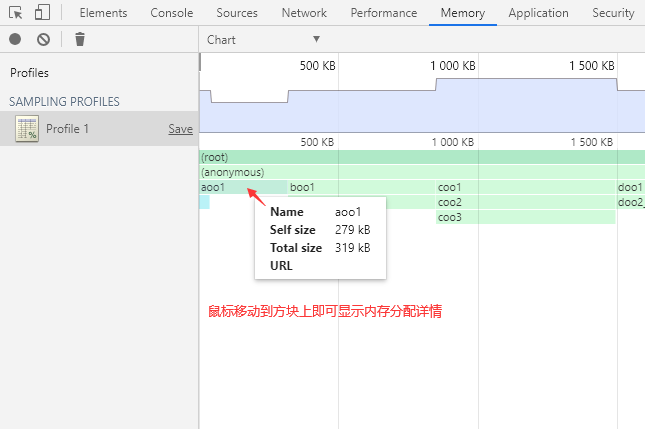
鼠标左键点击函数方块可以跳转到相应代码。
Heavy(扁平视图)
Heavy 视图将函数调用层级压平,函数将以独立的个体形式展现。另外也可以展开调用层级,不过是自下而上的结构,也就是一个反向的函数调用过程。
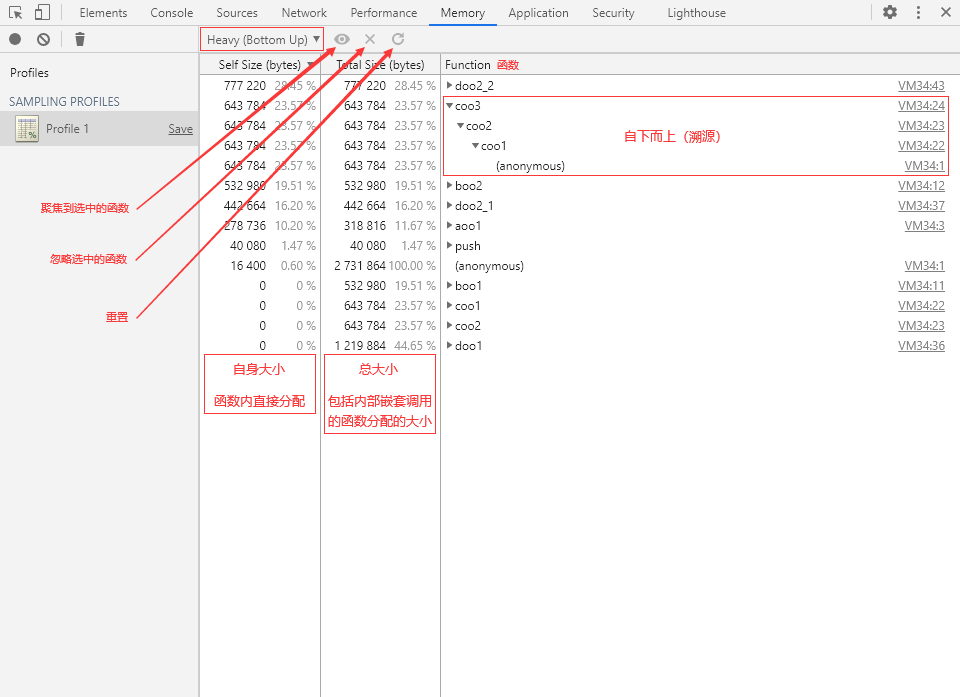
视图中的两种 Size(大小):
Self Size:自身大小,指的是在函数内部直接分配的内存空间大小。 Total Size:总大小,指的是函数总共分配的内存空间大小,也就是包括函数内部嵌套调用的其他函数所分配的大小。
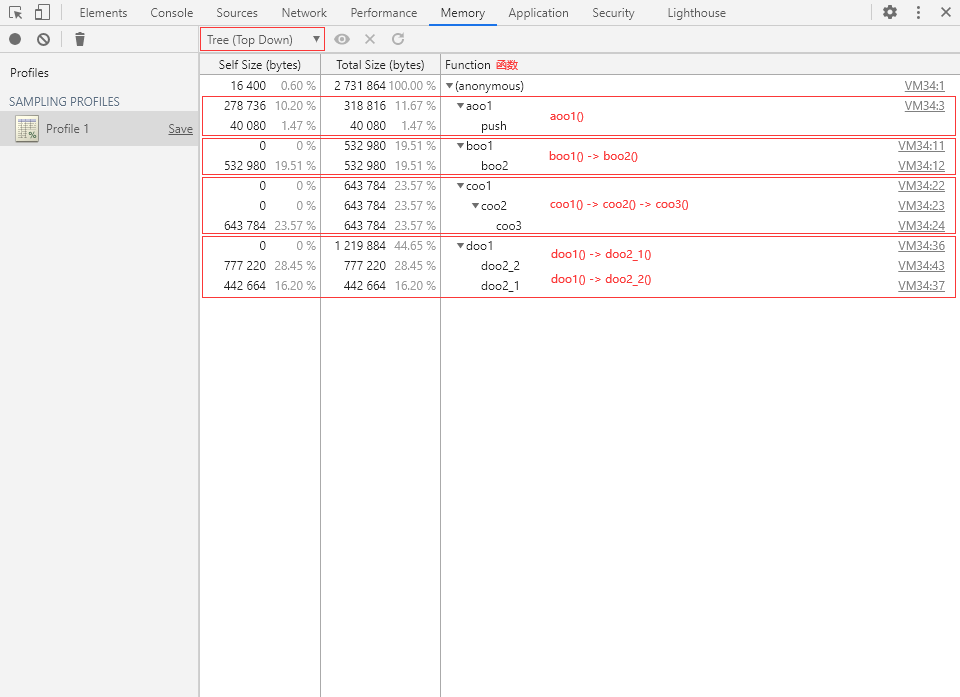
Tree(树状视图)
Tree 视图以树形结构展现函数调用层级。我们可以从代码执行的源头开始自上而下逐层展开,呈现一个完整的正向的函数调用过程。
参考资料
《JavaScript 高级程序设计(第4版)》
Memory Management:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Management
Visualizing memory management in V8 Engine:https://deepu.tech/memory-management-in-v8/
Trash talk: the Orinoco garbage collector:https://v8.dev/blog/trash-talk
Fast properties in V8:https://v8.dev/blog/fast-properties
Concurrent marking in V8:https://v8.dev/blog/concurrent-marking
Chrome DevTools:https://developers.google.com/web/tools/chrome-devtools
公众号
菜鸟小栈
感谢 Cocos Star Writer 陈皮皮的无私分享!皮皮的个人公众号「菜鸟小栈」专注但不仅限于游戏开发和前端技术分享。每一篇原创都非常用心,欢迎大家点击「阅读关注!