
Pandas数据分析小技巧系列 第二集
三步加星标
你好!我是 zhenguo
已推Pandas数据分析小技巧系列第一集,今天第二集,往下阅读前可以先星标:Python与算法社区,只有这样才会第一时间收到我的推送。
明天就是2020-12-1,祝你年底一切顺利!
小技巧6:如何快速找出 DataFrame 所有列 null 值个数?
实际使用的数据,null 值在所难免。如何快速找出 DataFrame 所有列的 null 值个数?
使用 Pandas 能非常方便实现,只需下面一行代码:
data.isnull().sum()
data.isnull(): 逐行逐元素查找元素值是否为 null.
.sum(): 默认在 axis 为 0 上完成一次 reduce 求和。
上手实际数据,使用这个小技巧,很爽。
读取泰坦尼克预测生死的数据集
data = pd.read_csv('titanicdataset-traincsv/train.csv')
结果:

检查 null 值:
data.isnull().sum()
结果:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
Age 列 177 个 null 值
Cabin 列 687 个 null 值
Embarked 列 2 个 null 值
小技巧7:如何用 Pandas 快速生成时间序列数据?
与时间序列相关的问题,平时还是挺常见的。
介绍一个小技巧,使用 pd.util.testing.makeTimeDataFrame
只需要一行代码,便能生成一个 index 为时间序列的 DataFrame:
import pandas as pd
pd.util.testing.makeTimeDataFrame(10)
结果:
A B C D
2000-01-03 0.932776 -1.509302 0.285825 0.941729
2000-01-04 0.565230 -1.598449 -0.786274 -0.221476
2000-01-05 -0.152743 -0.392053 -0.127415 0.841907
2000-01-06 1.321998 -0.927537 0.205666 -0.041110
2000-01-07 0.324359 1.512743 0.553633 0.392068
2000-01-10 -0.566780 0.201565 -0.801172 -1.165768
2000-01-11 -0.259348 -0.035893 -1.363496 0.475600
2000-01-12 -0.341700 -1.438874 -0.260598 -0.283653
2000-01-13 -1.085183 0.286239 2.475605 -1.068053
2000-01-14 -0.057128 -0.602625 0.461550 0.033472
时间序列的间隔还能配置,默认的 A B C D 四列也支持配置。
import numpy as np
df = pd.DataFrame(np.random.randint(1,1000,size=(10,3)),
columns = ['商品编码','商品销量','商品库存'])
df.index = pd.util.testing.makeDateIndex(10,freq='H')
结果:
商品编码 商品销量 商品库存
2000-01-01 00:00:00 99 264 98
2000-01-01 01:00:00 294 406 827
2000-01-01 02:00:00 89 221 931
2000-01-01 03:00:00 962 153 956
2000-01-01 04:00:00 538 46 374
2000-01-01 05:00:00 226 973 750
2000-01-01 06:00:00 193 866 7
2000-01-01 07:00:00 300 129 474
2000-01-01 08:00:00 966 372 835
2000-01-01 09:00:00 687 493 910
小技巧8:如何重新排序 DataFrame 的列?
某些场景需要重新排序 DataFrame 的列,如下 DataFrame:
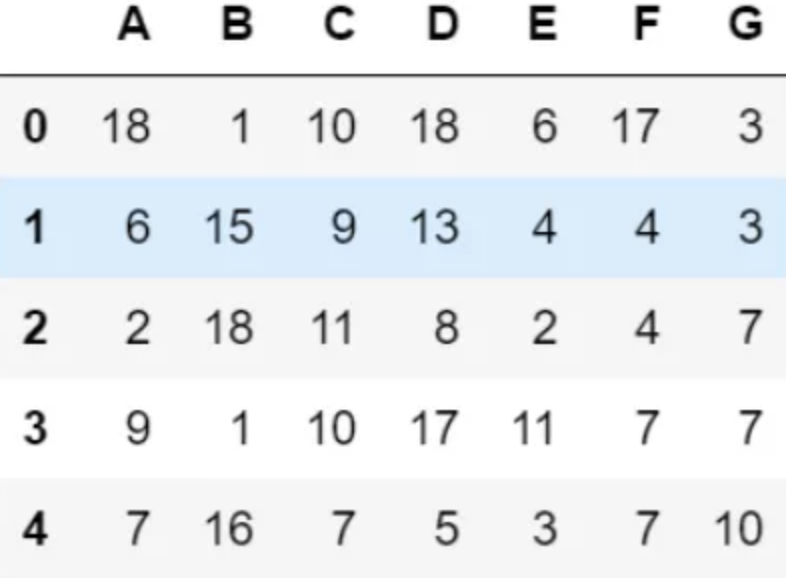
如何将列快速变为:
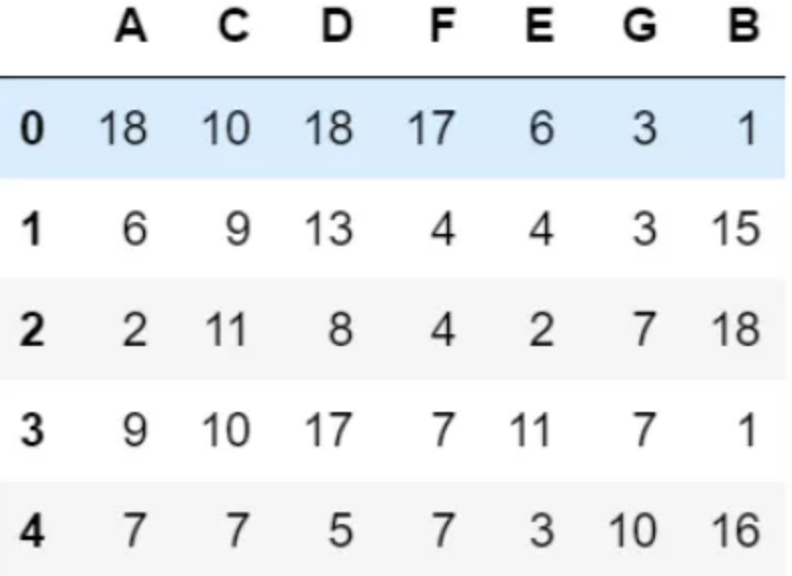
下面给出 2 种简便的小技巧。先构造数据:
df = pd.DataFrame(np.random.randint(0,20,size=(5,7)) \
,columns=list('ABCDEFG'))
df
方法1,直接了当:
df2 = df[["A", "C", "D", "F", "E", "G", "B"]]
df2
结果:
方法2,也了解下:
cols = df.columns[[0, 2 , 3, 5, 4, 6, 1]]
df3 = df[cols]
df3
也能得到方法1的结果。
小技巧9:如何完成数据下采样,调整步长由小时为天?
步长为小时的时间序列数据,有没有小技巧,快速完成下采样,采集成按天的数据呢?
先生成测试数据:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(1,10,size=(240,3)), \
columns = ['商品编码','商品销量','商品库存'])
df.index = pd.util.testing.makeDateIndex(240,freq='H')
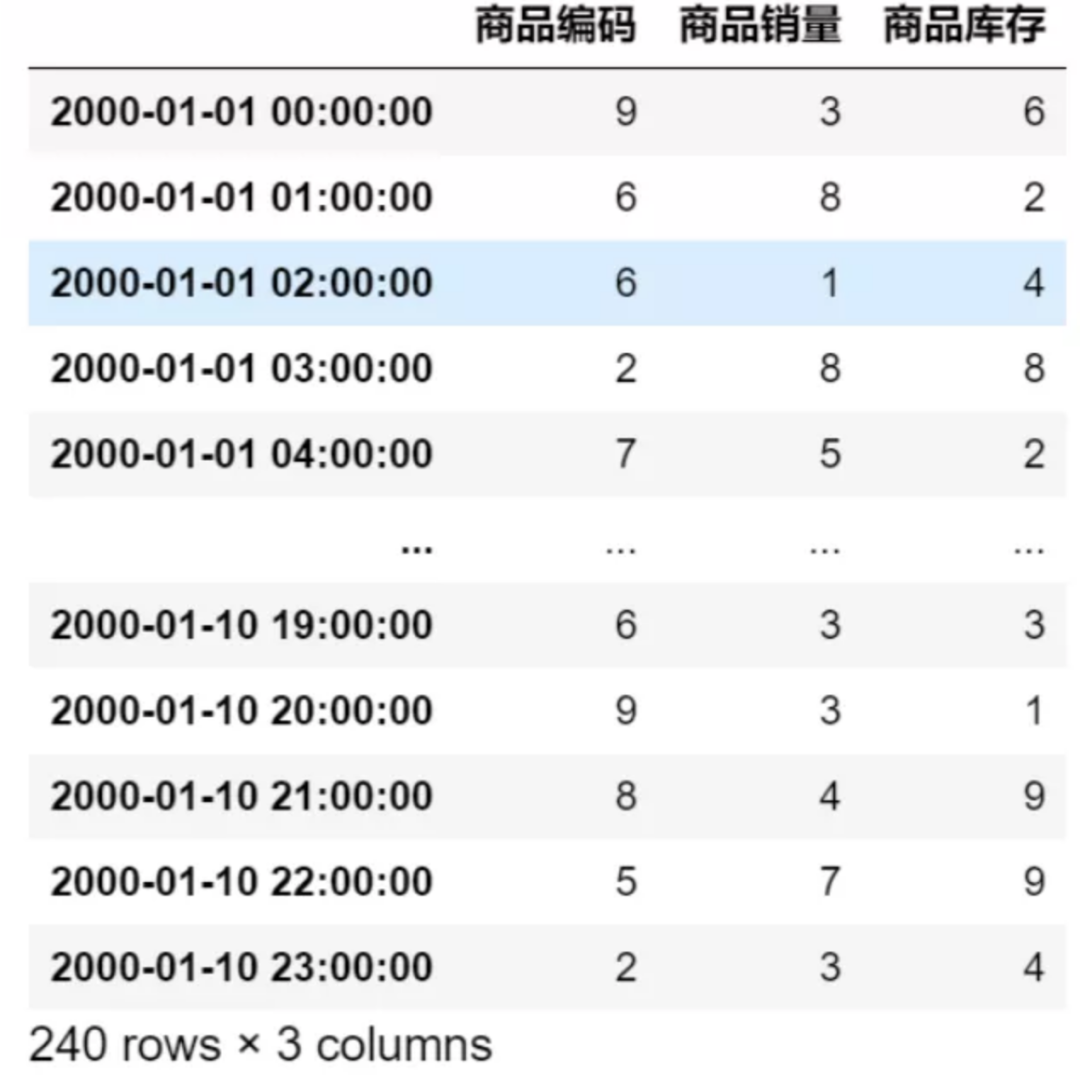
df
生成 240 行步长为小时间隔的数据:
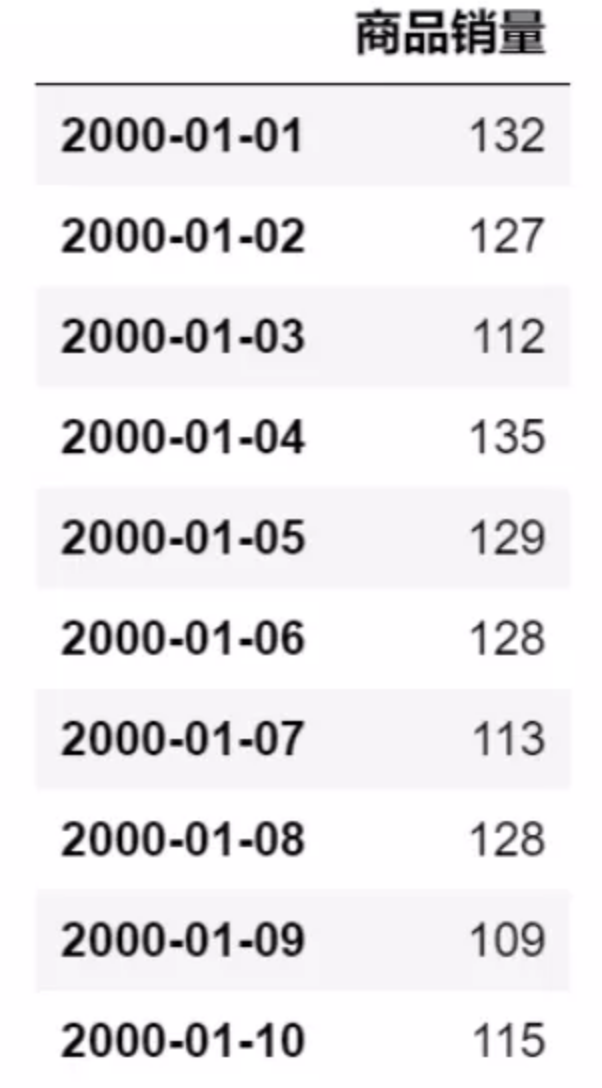
小技巧,使用 resample 方法,合并为天(D)
day_df = df.resample("D")["商品销量"].sum().to_frame()
day_df
结果如下,10行,240小时,正好为 10 days:
看到这儿了,别走开哈,下面是惊喜时刻。承蒙出版社老朋友的厚爱,赠送给 Python与算法社区《趣学Python算法 100 例》5 本:

算法源于生活,又可以改变生活。本书专为Python+算法初学者量身打造!详解100个趣味编程算法实例,内容涵盖Python编程的基础知识和常用算法,是初学算法设计与实现的极佳选择,详情点击下面图片: