
CVPR22 Oral|MLP进军底层视觉!谷歌提出MAXIM模型刷榜多个图像处理任务,代码已开源

极市导读
本文介绍谷歌在CVPR 2022工作MAXIM:最新的基于 MLP的UNet型骨干网络,同时实现了全局、局部感受野,并且可以在线性复杂度下直接应用在高分辨图片上,具有“全卷积”特性,可以即插即用,代码和模型均已开源。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
你是否厌倦了最新的Transformer/MLP模型的「不灵活性」和「高空间复杂度」?
你是否对最新的Transformer/MLP模型无法自适应的应用在「不同分辨率」感到无奈?
来试试 「MAXIM 」模型吧!最新的基于 MLP的UNet型骨干网络,同时实现了「全局」「局部」感受野,并且可以在「线性复杂度」下直接应用在「高分辨图片」上,具有「“全卷积”」特性,可以「即插即用」!代码和模型均已开源!_家人们,你还在等什么呢?!_
太长不看(TL;DR)
提出了通用的图像修复/增强任务骨干网络 MAXIM,第一次把最近爆火的 「MLP」[1]应用在底层视觉,在五大图像处理任务(去噪,去模糊,去雨,去雾,增强)超过10个数据集达到SOTA性能; 提出一个「即插即用」的多轴门限MLP模块(Multi-Axis gMLP block),实现了线性复杂度下的全局 / 局部的空间信息交互,解决了MLP/Transformer无法处理不同分辨率图片的痛点[2],并且具有全卷积[3]特性,为底层视觉任务量身定做,也可以应用在其他的密集预测任务(留给未来填坑); 提出另一个「即插即用」的交叉门控模块(Cross-Gating MLP block),可以无痛替代交叉注意力机制,并且同样在线性复杂度享有全局 / 局部感受野和全卷积特性。
论文地址:https://arxiv.org/abs/2201.02973
代码/模型/实验结果:https://github.com/google-research/maxim
中文视频讲解:https://youtu.be/gpUrUJwZxRQ(非常详细,有很多背景介绍,新手友好型)
背景介绍(Introduction)
都2022年了,你还在执著于在「卷积神经网络」中调参内卷吗?
Vision Transformer (ViT)[4]发表才不过一年多,就已经在各大视觉领域「鲨」「疯」「了」!受到 ViT 优雅架构的启发,各种奇技淫巧也应运而生 —— 谷歌大脑提出的MLP-Mixer[5]把 自注意力机制换成MLP,构建一个纯MLP架构,性能威猛!谷歌另一个大脑提出 gMLP 模型[6],构建了门限MLP模块,在视觉和语言建模上均无痛吊打 Transformer!有知乎大V不禁发问:MLP is all you need?[1]

ViT, Mixer, gMLP这些新的视觉骨干网络带领了了一波从根本上区别于传统卷积神经网络(CNN)架构设计的模式转变(paradigm shift),即为「全局模型」(Global Models or Non-Local Networks[7]) —— 我们不再依赖于长期以来人们对二维图像的先验知识(prior):平移不变性和局部依赖;而是无脑使用全局感受野和超大规模数据预训练的「钞能力」[8]。当然另一个ViT的特性是从注意力机制的本身定义而来,即为自适应于输入的动态加权平均,但这里我们主要讨论这些Transformer-like模型的全局交互属性。
全局模型允许在输入的特征图上进行全局空间交互,即每个输出像素是由输入特征的每个点加权而来,需要 次乘法(假设 为空间尺寸)。因此,输出整张大小为 的特征图需要 次乘法操作,这即为注意力机制/Transformer高计算复杂度的由来。但本质上来说,密集感受野的全局模型如 ViT, Mixer, gMLP 都具有平方计算复杂度。 这种没法Scaling up的平方算子是很难作为通用模块来广泛使用在各大视觉任务上的,例如需要在高分辨率上训练/推理的目标检测,语义分割等,甚至对于几乎所有的底层视觉任务如去噪、去模糊、超分、去雨、去雾、去雪、去阴影、去摩尔、去反射、去水印、去马赛克等等等等。。。
虽然但是,不妨也直接用用!华为北大等联手打造的IPT模型第一次把ViT模型应用在多个底层视觉任务,刷新了各大榜单并发表在CVPR 2021[9][10]。虽然性能很好,但IPT使用的全局注意力机制具有一些明显的局限性:(1)需要大量数据预训练(如ImageNet),(2)无法直接在高分辨率图片上进行推理。在实际推理时,往往需要对输入图像进行切块,分别对每个图像块进行推理,然后再进行拼接来还原大图。这种办法往往会导致输出图片中有一些明显的“块状效应”(如下图),同时推理速度也比较慢,限制了其实际落地和部署能力。

这种能在小图像块上训练,并且直接在大图上推理的属性我们称之为“全卷积”(fully-convolutional)[3]。全卷积属性对于底层视觉任务来说至关重要,因为底层视觉如图像修复和增强均需要对图像进行像素级操作,输出图像需和输入图像尺寸一样,无法像图像分类一样先进行resize等操作。很明显,目前的主流全局网络 ViT,Mixer,gMLP都无法很好的解决这个无法自适应于不同图像分辨率的痛点。
他来了,他来了,他披着CNN的外皮来了!
Swin Transformer横空出世,并且一举摘获ICCV 2021 Marr Prize[11]。 Swin的贡献可圈可点,譬如引入了层次化的结构,譬如提出了局部注意力机制(Local/Window attention)来解决计算复杂度问题。但是,重点来了!Swin提出的local attention为底层视觉带来了福音:具有“全卷积 ”属性!其根本原因是 Self-Attention 作用在一个小的 7 x 7 窗口内,而在整个空间内的不同窗口都是共享权重的。如果在更大的尺寸下推理,无非是有更多的窗口罢了。想想看,这玩意儿是不是跟 Strided Convolution 的思想如出一辙?CNN,yyds!
局部注意力作为一个十分自然的受启发于CNN的改进,非常适用于底层视觉任务,因此马不停蹄的就进军各大底层视觉任务。“首当其冲”的两个工作就是 (1)中科大提出的 Uformer [12](CVPR 22)和(2)Luc Van Gool组提出的SwinIR[13] (ICCVW 21),均借鉴或改进了Local Attention的思想,并且应用在多个不同的底层视觉任务,取得了惊人的性能。
但是,Local Attention重新引入了Locality的思想,返璞归真,反而把全局模型中很重要的一个特性「全局交互」给舍弃掉了。我们谦虚地认为Shifted window attention只是对Local Attention做了一个补充,并没有真正解决怎样更高效的进行全局交互的痛点(个人观点,大神请轻喷QAQ。。不过这是本文的研究动机之一)
模型方法(Method)
我们设计了第一个基于MLP的通用底层视觉类UNet骨干网络称之为MAXIM。对比前人的一些底层视觉网络工作,MAXIM具有以下几个优点:
MAXIM 在任意尺寸图片上都具有全局感受野,并且只需要线性复杂度; MAXIM 可以在任意尺寸图片上直接推理,具有“全卷积”属性; MAXIM 平衡了局部和全局算子的使用,使得网络在不需要超大数据集预训练的情况下达到SOTA性能。
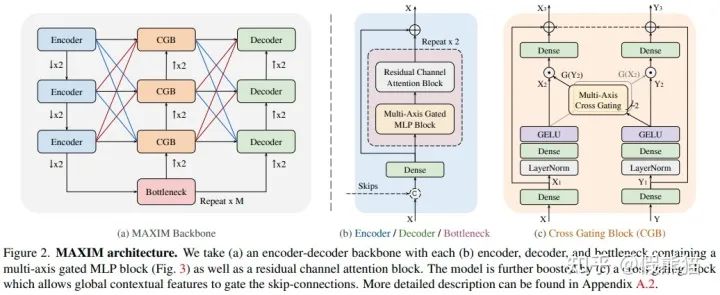
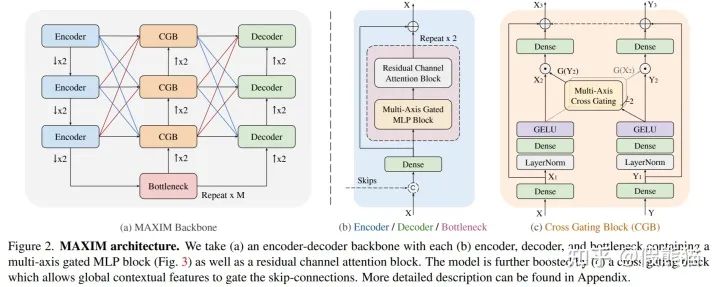
MAXIM骨干网络架构图如上所示,其具有一个对称UNet的基本结构,包含降采样的Encoder模块,最底层的Bottleneck, 和上采样的Decoder模块。其中,每一块Encoder/Decoder/Bottleneck均采用同样的设计如Figure 2(b):多轴门控MLP块(全局交互)和残差卷积通道注意力块(局部交互)。受启发于Attention-UNet[14],我们在UNet的中间层加入了 交叉门控模块(Cross-gating block),使用Bottleneck输出的高阶语义特征来调制编码器到解码器之间的跳跃连接特征。值得注意的是,区别于传统的各种UNet魔改网络,MAXIM骨干中的每一个模块都具有全局/局部感受野,因此具有更大的学习潜力。
魔改一:多轴门控MLP模块
本模型中的核心贡献就是提出的多轴门控MLP模块(Multi-axis gated MLP block),一个即插即用的并行模块,可进行全局/局部的空间交互,并且具有线性复杂度。我们是受启发于 [NeurIPS 21] HiT-GAN[15]中提出的多轴自注意力模块,可在低分辨率特征图上进行有效的全局/局部信息交互,在多个图片生成任务达到SOTA。然而,此多轴非彼多轴,我们要能够使用在高分辨率底层视觉任务上,并且同时需要具有“全卷积”属性。但同时又不想牺牲全局感受野的重要属性,于是乎,魔改开始了:
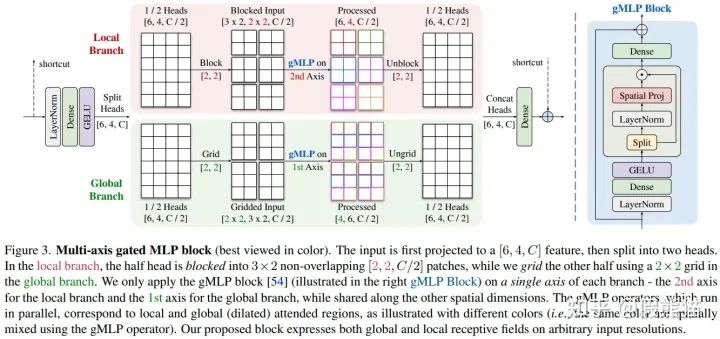
如上图所示,输入的特征首先进行通道映射,然后分成两个头,分别进行全局和局部交互。 其中一半的头进入局部分支(图中红色),我们使用 gMLP 算子在固定的窗口大小内进行局部空间交互;另一半头喂进全局分支(图中绿色),我们同样使用 gMLP 算子在固定的网格位置进行全局(膨胀)空间交互。 值得注意的是,图中的 Block 和 Grid 操作均为窗口划分(和Swin一样), 但Block操作中我们固定【窗口大小】,而在 Grid 操作中我们固定【窗口数量】(or 网格大小)。在两个并行分支结构中,我们每次只对固定维度的坐标进行操作,而在其他坐标都共享参数,从而实现了同时具有“全卷积”属性和全局/局部感受野。由于我们总是使用固定的窗口大小和网格大小,该模块也具有线性计算复杂度 。
魔改二:交叉门控模块
UNet比较经典的魔改网络是Attention-UNet[14],其在对称的跳跃连接中加入了交叉注意力机制来自适应的加权滤波可以通过的特征图。受此启发,我们进行了第二个魔改,提出了【交叉门控模块】,如 Figure 2(c)所示。其设计理念严格遵守多轴门控MLP模块的模范,同样采用多轴全局/局部交互的gMLP模块。唯一的区别是在提取了gMLP算子的空间门权重(gating weights) 后,我们采用了交叉相乘的方式来进行信息交互。例如 是两个不同的输入特征,交叉门控的概念可以简单表示为(具体的公式可以参见文章或代码):
至此,我们提出了第一个可以进行多特征交互的纯纯MLP的交叉门控模块,可以用来进行全局/局部的交叉信息传递和互相调制, 功能上等效于交叉注意力机制,可以无脑即插即用。
魔改三:多阶段多尺度架构
电路图预警!!!电路图预警!!!电路图预警!!!
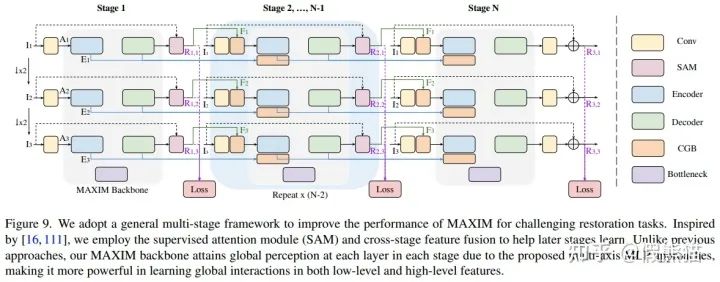
为了平衡性能-计算复杂度,MAXIM采用了一个改进的多阶段网络,并且采用了深度监督策略来监督多阶段多尺度的输出们。本文中针对不同的任务分别使用了2和3阶段网络:MAXIM-2S,MAXIM-3S。虽然MAXIM是多阶段网络,其仍然是可以进行端到端训练而不需要分步或渐进训练。在推理阶段,只需要把最后阶段的最大尺寸输出保留作为最终的结果即可。使用的损失函数是把多个阶段、多个尺度所有的输出和输入计算Charbonnier损失函数和频域变换后的L1损失的加权和,可以表示为:
其中 代表网络在阶段s尺度n的输出图像, 表示尺度n的目标图片(groundtruth)。该多阶段多尺度的设计参考了一些前人工作中的网络设计经验如MPRNet[16],HINet[17],和MIMO-UNet[18]。
[PS] 不得不说此模块是作者至今的唯一遗憾!一直觉得提出的网络结构太复杂了,不够优雅。在作者早期调参时使用单个MAXIM骨干一直没法达到接近SOTA的性能,痛苦、徘徊、迷茫了好久,浪费了很多碳排放。后来才明白了一个经验教训:一定要respect每个领域的domain knowledge,不要轻易怀疑为什么该领域的网络这样那样设计,那都是前辈调参侠们996的血汗成果啊T.T。多阶段网络在比较难的图像修复任务如去模糊和去雨中已经成为了经典架构;同样地,MAXIM在使用了多阶段架构后,性能也立马起飞。令人喜出望外的是,使用多阶段小网络比单阶段大网络的性能与计算量均有很大提升(参见消融实验)!惊不惊喜,意不意外?
实验(Experiments)
实验设置
我们旨在建立一个大一统的骨干网络可以适用于广泛的底层视觉/图像处理任务。因此,我们在五个不同的视觉任务多达 17 个数据集上进行了训练测试。使用的数据集总结如下:
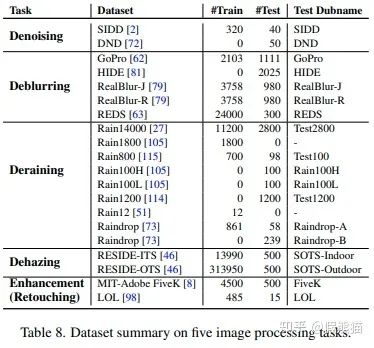
实验结果
量化和视觉的实验结果如下所示。一图胜千言,就不多赘述了。更多的实验结果参见论文的附录部分。
1. 去噪(Denoising) on SIDD, DND 数据集
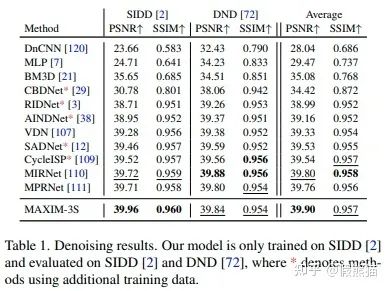

2. 去模糊(Deblurring) on GoPro, HIDE,RealBlur,REDS数据集
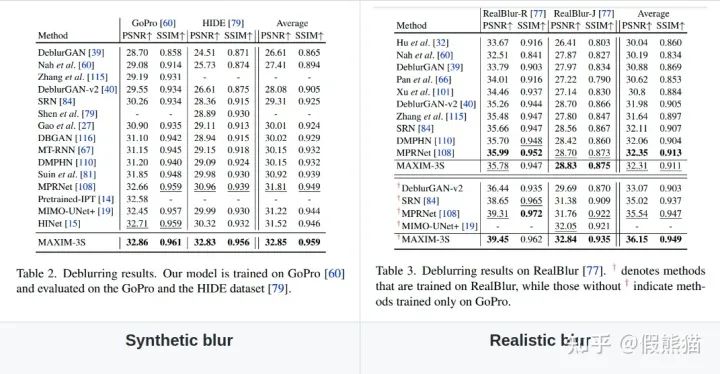

3. 去雨(Deraining)on Rain100L, Rain100H, Test100, Test1200, Test2800, RainDrop数据集
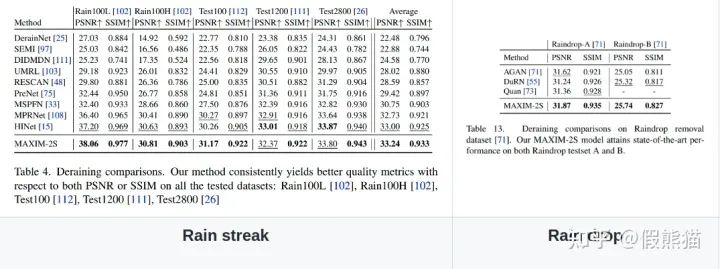
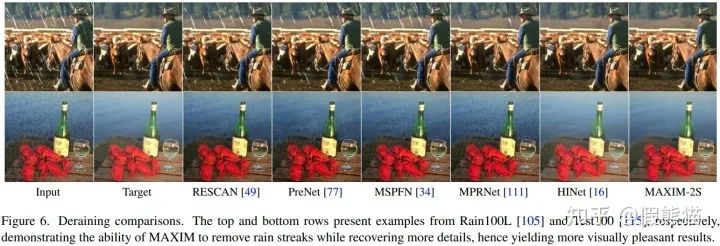

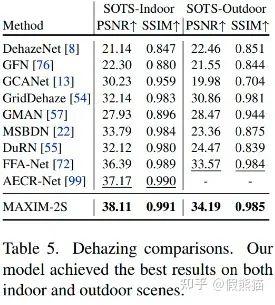
4. 去雾(Dehazing)on RESIDE indoor,outdoor数据集

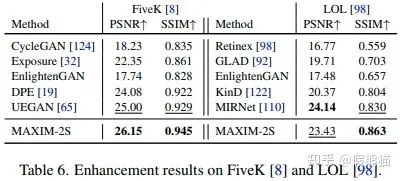
5. (光照)增强(Enhancement)on MIT-Adobe FiveK,LOL数据集


消融实验
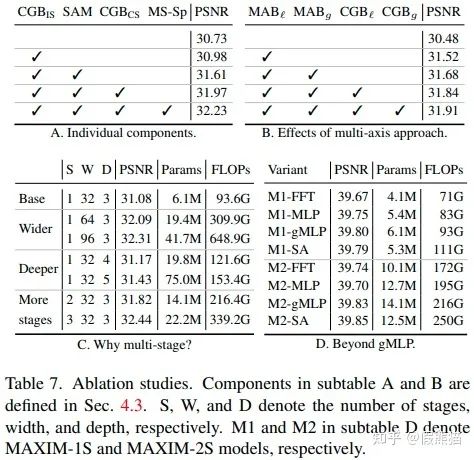
我们做了详尽的消融实验来理解MAXIM网络:
【模块消融】我们发现使用每一个新提出的模块都对最终性能有提升,测试的模块有阶段内和阶段之间的的交叉门限模块,SAM模块,和多尺寸深度监督方法; 本文主要提出了可以适用于高分辨率图片的全局交互MLP网络,那么问题来了:【使用全局有多好】?消融实验B表示局部和全局MLP对网络的提升效果不相上下,合在一起食用效果更佳; 【为什么要使用多阶段?】_实践是检验真理的唯一标准_。我们发现使用多阶段比使用更深、更宽的单个网络的性能提升更加明显,并且参数和计算量也比较平衡; 【通用性】我们提出的多轴并行模块是一个通用办法可以把无法处理不同分辨率的算子转化成局部/全局算子,并且具有线性复杂度和分辨率自适应性。我们尝试了使用自注意力,gMLP,MLP-Mixer,FFT[19]作为不同的空间混合算子,发现使用自注意力和gMLP可以取得最佳的性能而使用Mixer和FFT具有更快的计算速度。
参考
^ab[吐槽] MLP is all you need? https://zhuanlan.zhihu.com/p/370780575 ^CVPR2021提出的Transformer无法直接处理不同分辨率 https://github.com/huawei-noah/Pretrained-IPT/issues/18 ^ab“全卷积”(fully-convolutional):卷积网络天然具有的特性,即可以应用在不同分辨率的图片 https://arxiv.org/abs/1411.4038 ^An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale https://arxiv.org/abs/2010.11929 ^MLP-Mixer: An all-MLP Architecture for Vision https://arxiv.org/abs/2105.01601 ^Pay attention to MLPs https://proceedings.neurips.cc/paper/2021/hash/4cc05b35c2f937c5bd9e7d41d3686fff-Abstract.html ^Non-Local Neural Networks https://openaccess.thecvf.com/content_cvpr_2018/html/Wang_Non-Local_Neural_Networks_CVPR_2018_paper.html ^GPT-3: Money is All You Need https://twitter.com/arankomatsuzaki/status/1270981237805592576?s=20&t=jEDzZJ2KrCIRUYVKL0vW7A ^华为北大等联手打造的Transformer竟在CV领域超过了CNN:多项底层视觉任务达到SOTA https://zhuanlan.zhihu.com/p/328534225 ^IPT CVPR 2021 | 底层视觉预训练Transformer | 华为开源代码解读 https://zhuanlan.zhihu.com/p/384972190 ^如何看待swin transformer成为ICCV2021的 best paper? https://www.zhihu.com/question/492057377 ^Uformer: A General U-Shaped Transformer for Image Restoration https://arxiv.org/abs/2106.03106 ^SwinIR: Image Restoration Using Swin Transformer https://arxiv.org/abs/2108.10257 ^abAttention U-Net: Learning Where to Look for the Pancreas https://arxiv.org/abs/1804.03999 ^Improved Transformer for High-Resolution GANs https://arxiv.org/abs/2106.07631 ^Multi-Stage Progressive Image Restoration https://arxiv.org/abs/2102.02808 ^HINet: Half Instance Normalization Network for Image Restoration https://arxiv.org/abs/2105.06086 ^Rethinking Coarse-to-Fine Approach in Single Image Deblurring https://arxiv.org/abs/2108.05054 ^Global Filter Networks for Image Classification https://arxiv.org/abs/2107.00645
公众号后台回复“画图模板”获取90+深度学习画图模板~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
