
Pandas 表格样式设置指南,看这一篇就够了!
Pandas 表格样式设置指南
最近这些年,Python在数据分析以及人工智能领域是越来越火。
这离不开pandas、numpy、sklearn、TensorFlow、PyTorch等数据科学包,尤其是 Pandas,几乎是每一个从事Python数据科学相关的同学都绕不过去的。
Pandas是一种高效的数据处理库,它以 dataframe 和 series 为基本数据类型,呈现出类似excel的二维数据。
在 Jupyter 中(jupyter notebook 或者 jupyter lab),可以对数据表格按照条件进行个性化的设置,方便形象的查看和使用数据。
Pandas提供了 DataFrame.style 属性,它会返回 Styler对象,用于数据样式的设置。
基于 Pandas提供的方法,本文主要内容概括如下:
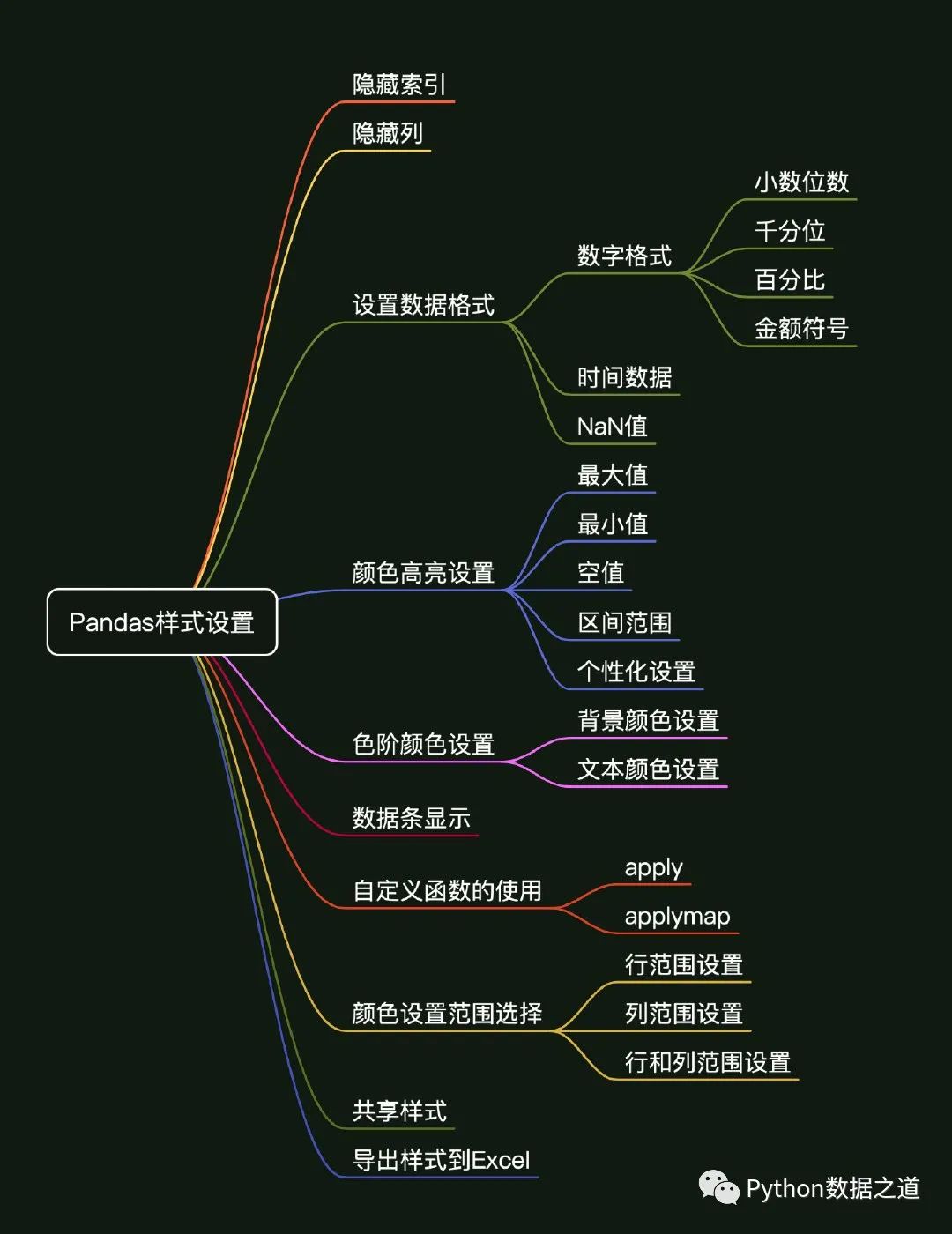
01 环境准备
使用环境
本次使用的环境如下:
MacOS系统 Python 3.8 Jupyter Notebook
Pandas 和 Numpy 的版本为:
pandas version:1.3.0rc1
numpy version:1.19.2
首先导入 pandas 和 numpy 库,这次咱们本次需要用到的两个 Python 库,如下:
import pandas as pd
import numpy as np
print(f'pandas version:{pd.__version__}')
print(f'numpy version:{np.__version__}')
数据准备
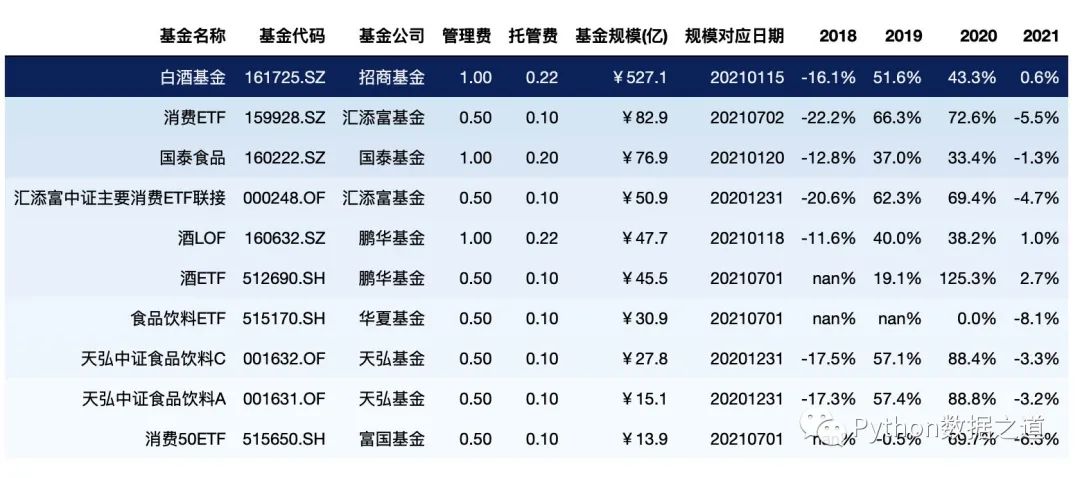
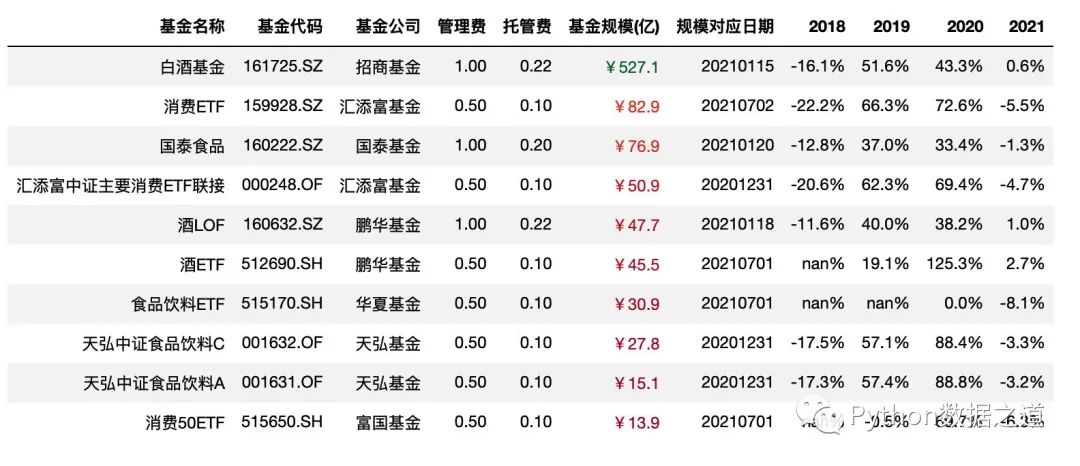
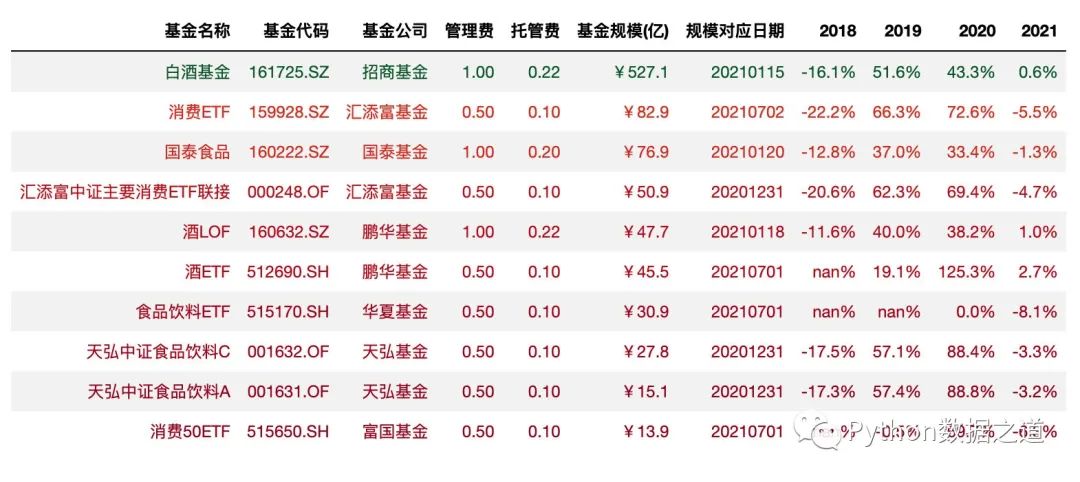
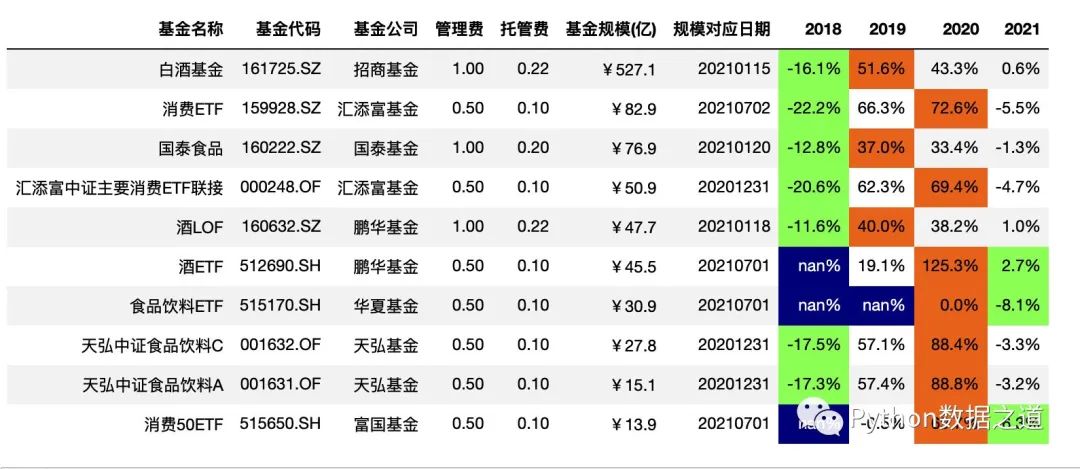
本次咱们使用的两份数据是关于主动基金以及消费行业指数基金的数据,本次演示用的数据仅为展示Pandas图表美化功能,对投资没有参考建议哈。
数据文件在文末有获取方式。
数据1
消费行业指数基金相关的数据,导入如下:
df_consume = pd.read_csv('./data/fund_consume.csv',index_col=0,parse_dates=['上任日期','规模对应日期'])
df_consume = df_consume.sort_values('基金规模(亿)',ascending=False).head(10)
df_consume = df_consume.reset_index(drop=True)
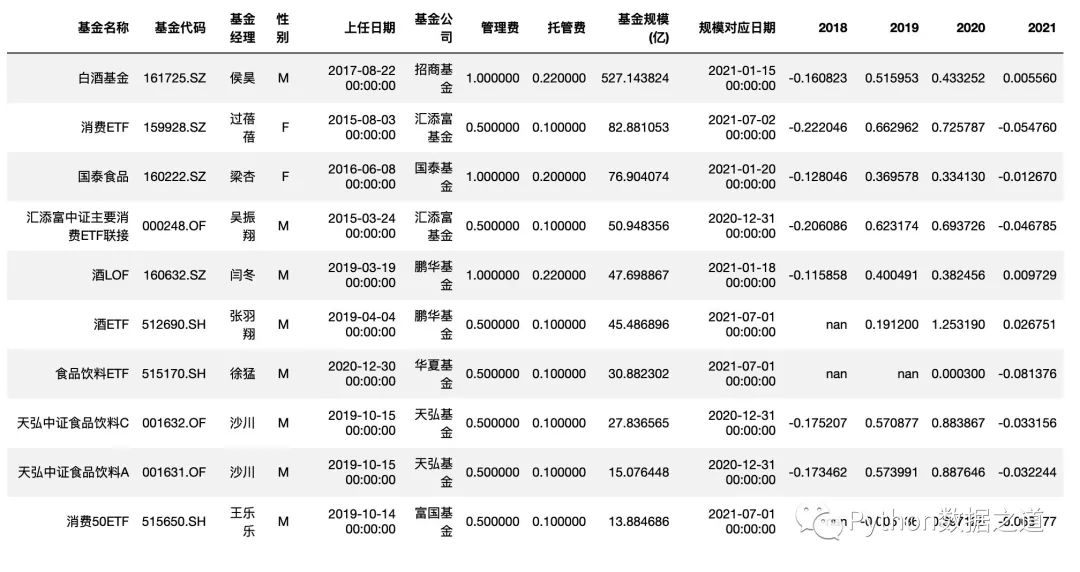
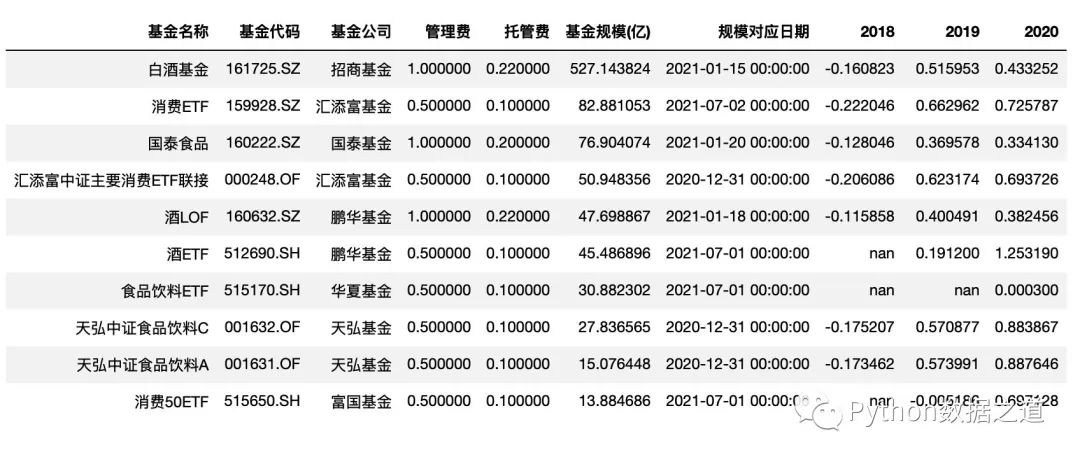
df_consume
数据2
主动基金数据,导入如下:
df_fund = pd.read_csv('./data/fund-analysis.csv',index_col=0,parse_dates=['上任日期','规模对应日期'])
df_fund = df_fund.sort_values('基金规模(亿)',ascending=False).head(10)
df_fund = df_fund.reset_index(drop=True)
df_fund.head(2)
文章中主要使用第一份数据。
02 隐藏索引
用 hide_index() 方法可以选择隐藏索引,代码如下:
df_consume.style.hide_index()
效果如下:
03 隐藏列
用 hide_columns() 方法可以选择隐藏一列或者多列,代码如下:
df_consume.style.hide_index().hide_columns(['性别','基金经理','上任日期','2021'])
效果如下:
04 设置数据格式
在设置数据格式之前,需要注意下,所在列的数值的数据类型应该为数字格式,如果包含字符串、时间或者其他非数字格式,则会报错。
可以用 DataFrame.dtypes 属性来查看数据格式。
df_consume.dtypes
格式如下:
基金名称 object
基金代码 object
基金经理 object
性别 object
上任日期 datetime64[ns]
基金公司 object
管理费 float64
托管费 float64
基金规模(亿) float64
规模对应日期 datetime64[ns]
2018 float64
2019 float64
2020 float64
2021 float64
dtype: object
从上面来看,数据格式主要包括字符串、数字和时间这三种常见的类型,此外,空值(NaN,NaT等)也是我们需要处理的数据类型之一。
对于字符串类型,一般不要进行格式设置;
对于数字类型,是格式设置用的最多的,包括设置小数的位数、千分位、百分数形式、金额类型等;
对于时间类型,经常会需要转换为字符串类型进行显示;
对于空值,可以通过
na_rep参数来设置显示内容;
Pandas 中可以通过 style.format() 函数来对数据格式进行设置。
format_dict = {'基金规模(亿)': '¥{0:.1f}',
'管理费': '{0:.2f}',
'托管费': '{0:.2f}',
'规模对应日期':lambda x: "{}".format(x.strftime('%Y%m%d')),
'2018': '{0:.1%}',
'2019': '{0:.1%}',
'2020': '{0:.1%}',
'2021': '{0:.1%}'
}
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期','2021'])\
.format(format_dict)
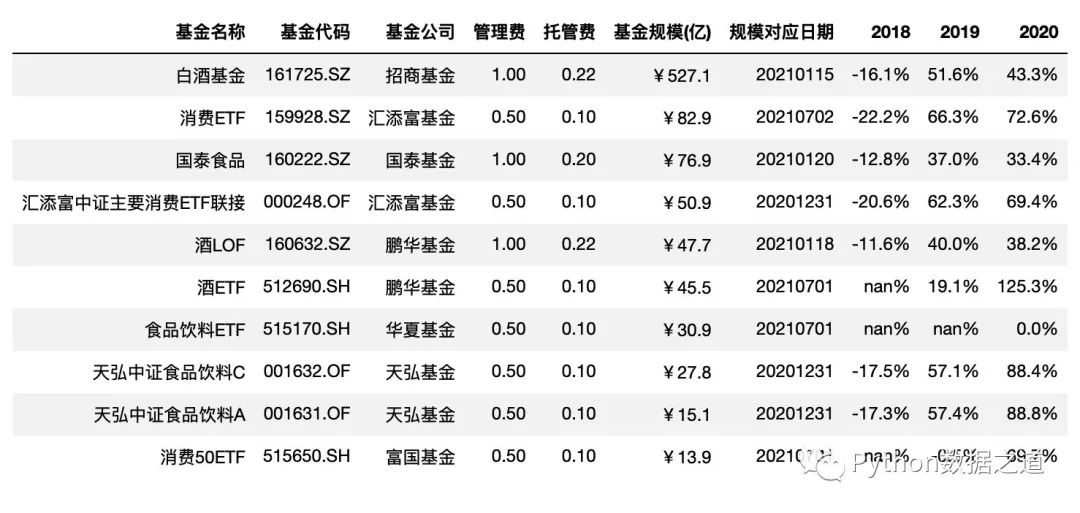
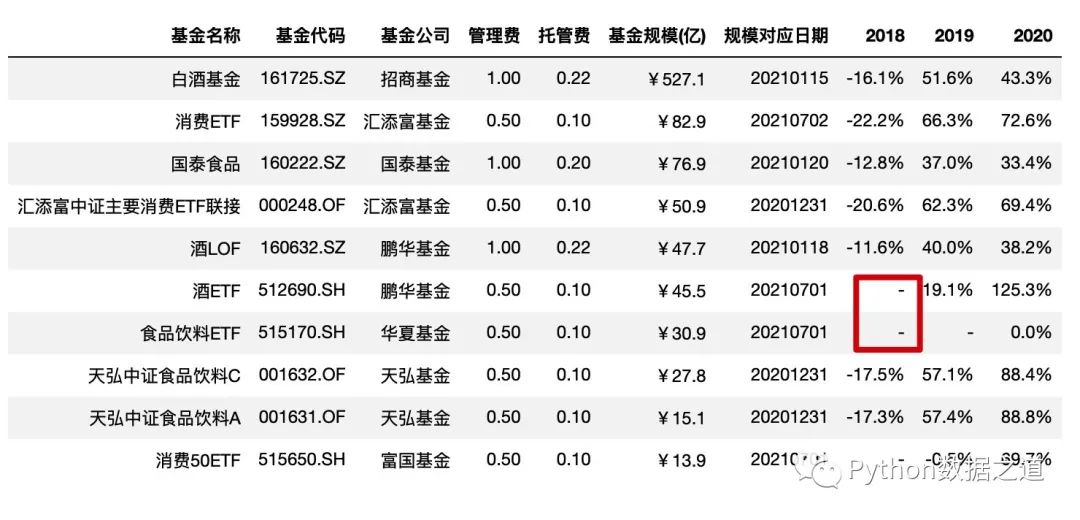
空值设置
使用 na_rep 设置空值的显示,一般可以用 -、/、MISSING 等来表示:
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期','2021'])\
.format(format_dict,na_rep='-')
05 颜色高亮设置
对于最大值、最小值、NaN等各类值的颜色高亮设置,pandas 已经有专门的函数来处理,配合 axis 参数可以对行或者列进行应用:
highlight_max() highlight_min() highlight_null() highlight_between()
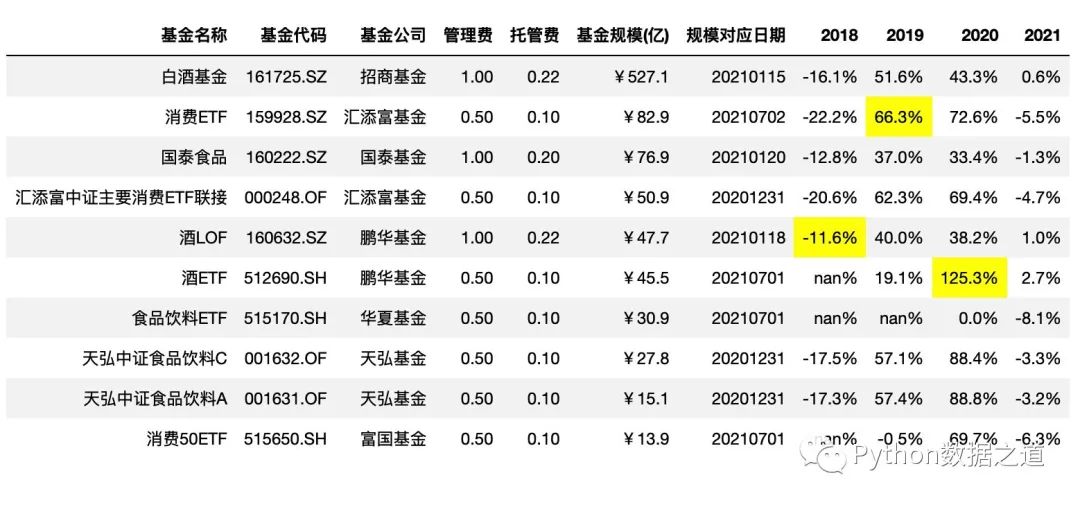
highlight_max
通过 highlight_max()来高亮最大值,其中 axis=0 是按列进行统计:
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_max(axis=0,subset=['2018','2019','2020'])
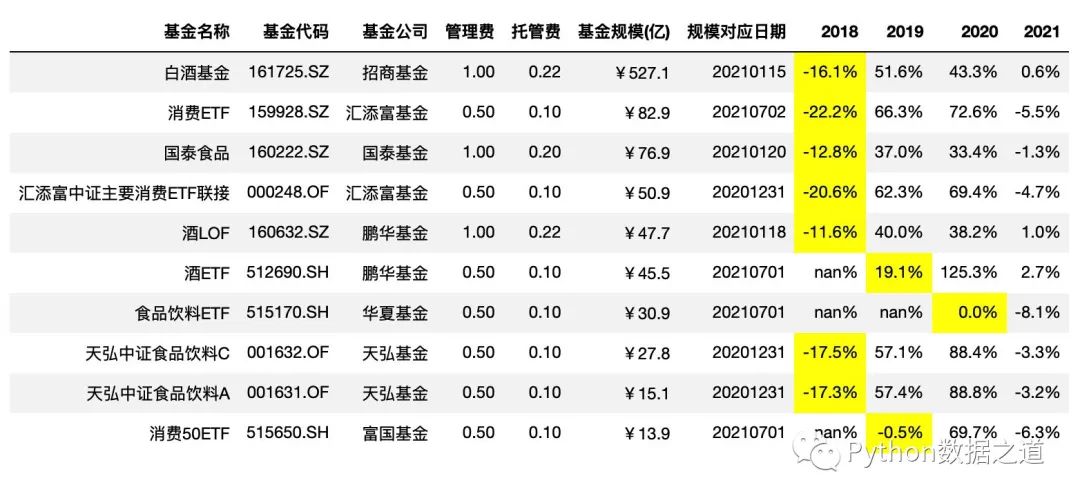
highlight_min
通过 highlight_min()来高亮最小值,其中 axis=1 是按行进行统计:
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_min(axis=1,subset=['2018','2019','2020'])
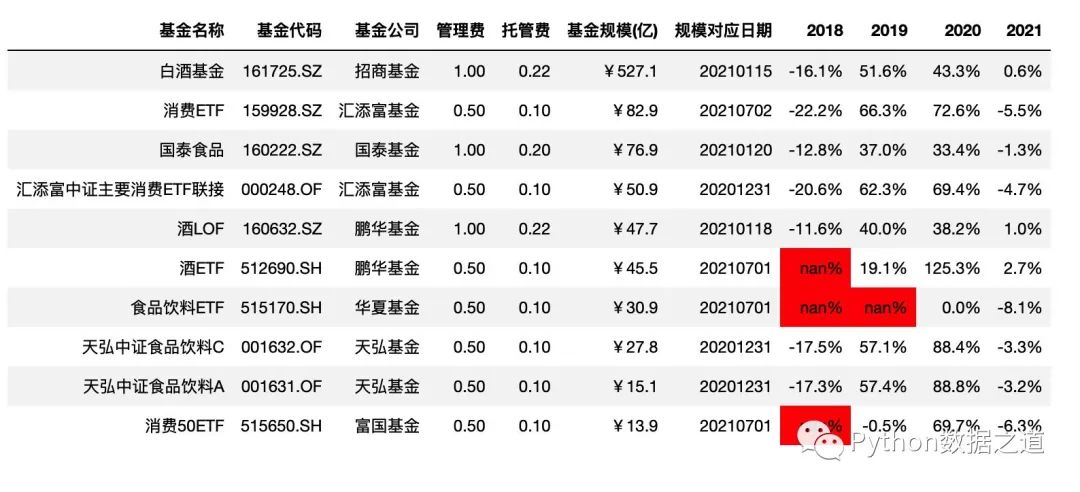
highlight_null
通过 highlight_null()来高亮空值(NaN值)
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_null()
效果如下:
highlight_between
highlight_between() 函数,对处于范围内的数据进行高亮显示。
highlight_between() 函数的使用参数如下:
Styler.highlight_between(subset=None, color='yellow', axis=0, left=None, right=None, inclusive='both', props=None)
highlight_between() 函数,对处于范围内的数据进行高亮显示,通过 left 和 right 参数来设置两边的范围。
需要注意下,highlight_between() 函数从 pandas 1.3.0版本开始才有,旧的版本可能不能使用哦。
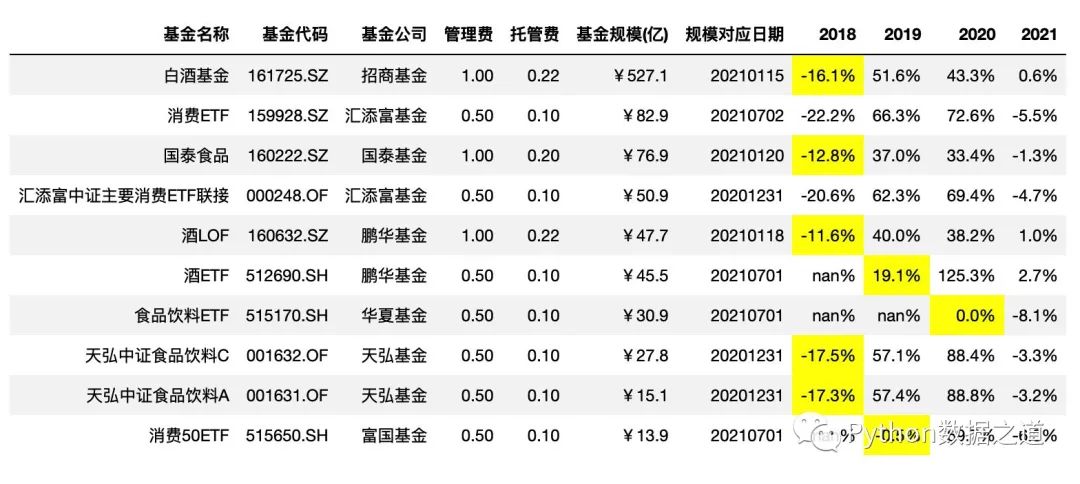
下面示例中 对2018年至2020年的年度涨跌幅度 -20%~+20% 范围内的数据进行高亮标注.
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_between(left=-0.2,right=0.2,subset=['2018','2019','2020'])
效果如下:
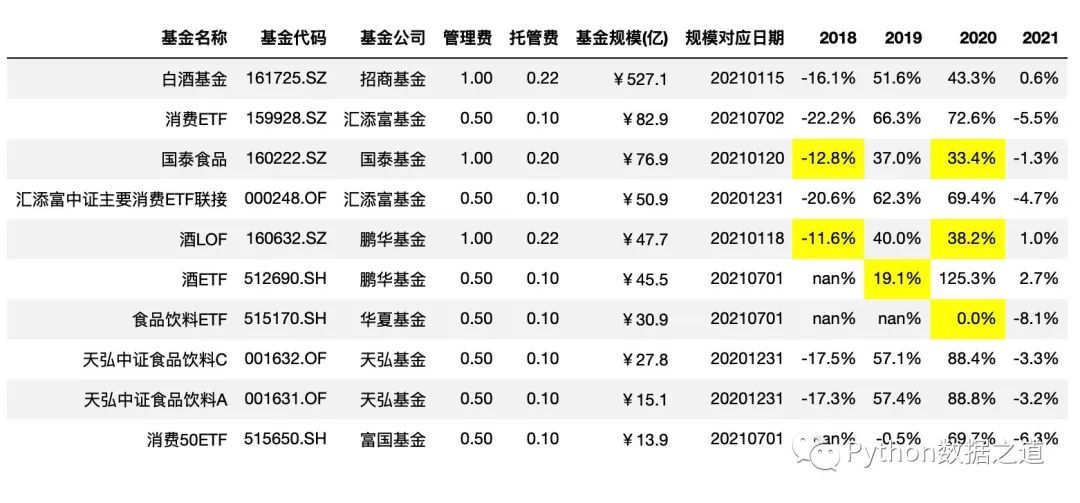
也可以分别对不同年度的不同涨跌范围进行设置,比如下面示例中:
2018年的年度涨跌幅度 -15%~+0%范围;2019年的年度涨跌幅度 0%~20%%范围;2020年的年度涨跌幅度 0%~40%范围。
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_between(left=[-0.15,0,0],right=[0,0.2,0.4],subset=['2018','2019','2020'],axis=1)
效果如下:
个性化设置
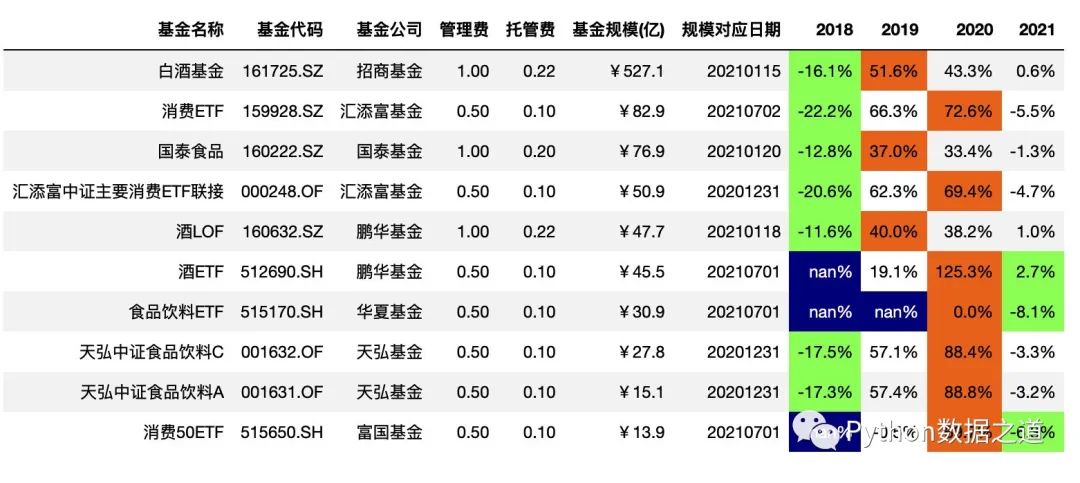
highlight_max()、highlight_min()、highlight_null() 等函数的默认颜色设置,我们不一定满意,可以通过 props 参数来进行修改。
字体颜色和背景颜色设置
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_min(axis=1,subset=['2018','2019','2020','2021'],props='color:black;background-color:#99ff66')\
.highlight_max(axis=1,subset=['2018','2019','2020','2021'],props='color:black;background-color:#ee7621')\
.highlight_null(props='color:white;background-color:darkblue')
效果如下:
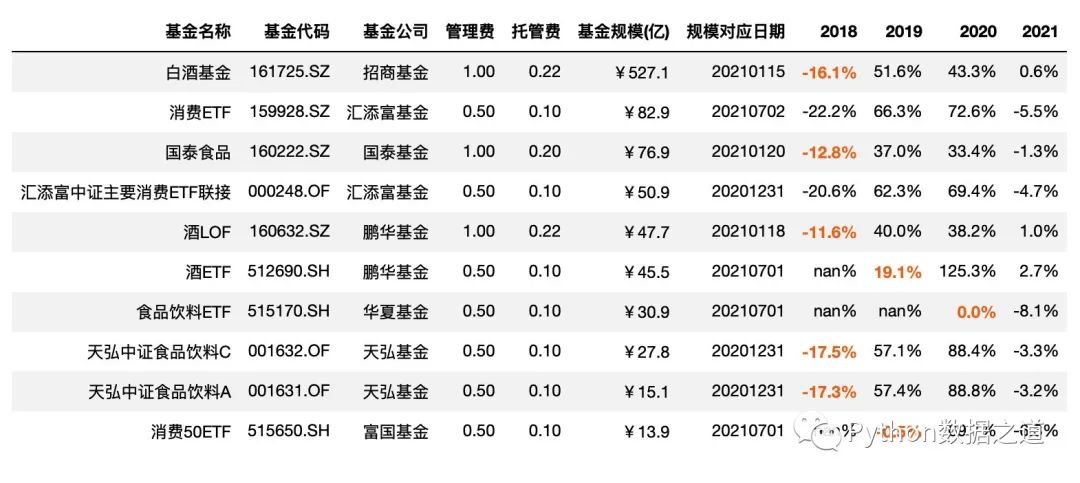
字体加粗以及字体颜色设置
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_between(left=-0.2,right=0.2,subset=['2018','2019','2020'],props='font-weight:bold;color:#ee7621')
效果如下:
类似的个性化设置,在本文后续内容中也是适用的。
06 色阶颜色设置
背景色阶颜色设置
使用 background_gradient() 函数可以对背景颜色进行设置。
该函数的参数如下:
Styler.background_gradient(cmap='PuBu', low=0, high=0, axis=0, subset=None, text_color_threshold=0.408, vmin=None, vmax=None, gmap=None)
使用如下:
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.background_gradient(cmap='Blues')
效果如下:
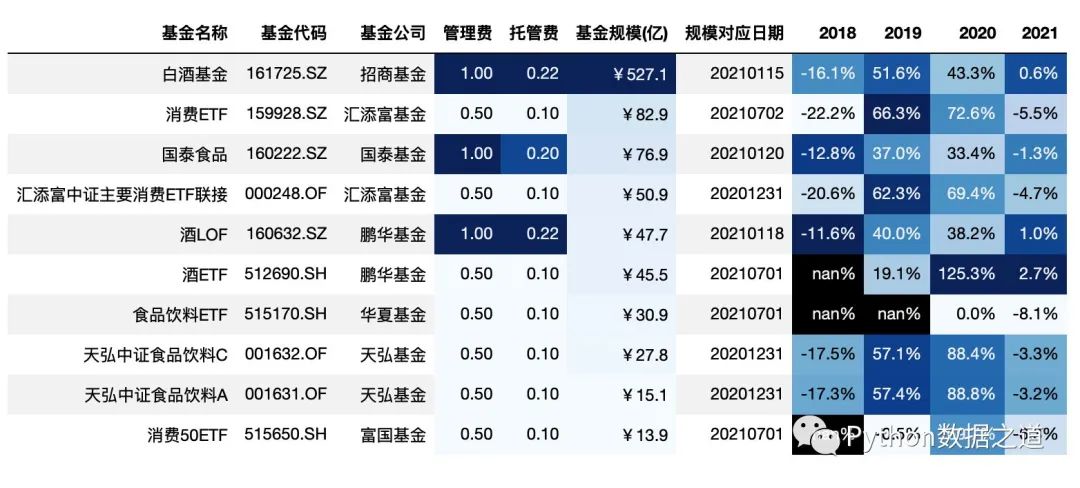
如果不对 subset 进行设置,background_gradient 函数将默认对所有数值类型的列进行背景颜色标注。
对 subset 进行设置后,可以选择特定的列或特定的范围进行背景颜色的设置。
# 对基金规模以色阶颜色进行标注
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.background_gradient(subset=['基金规模(亿)'],cmap='Blues')
效果如下:
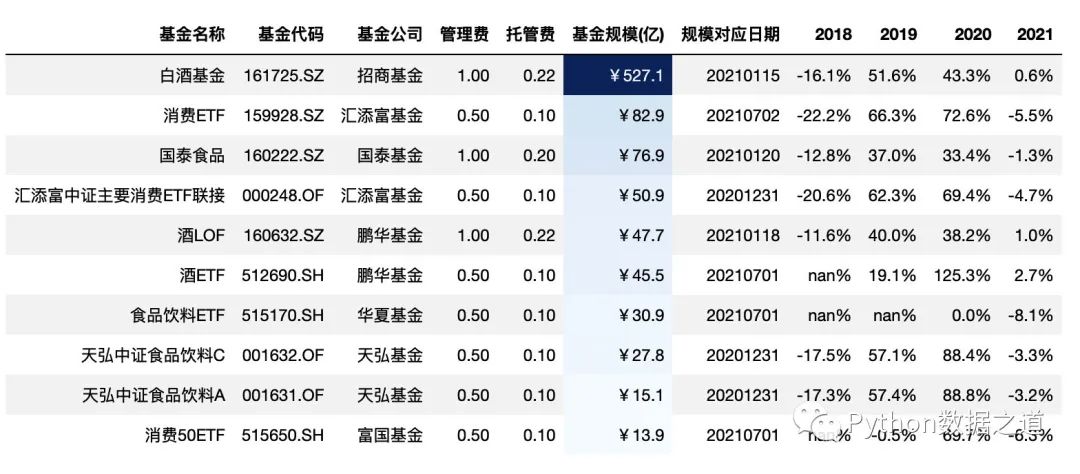
此外,可以通过对 low 和 high 值的设置,可以来调节背景颜色的范围,low 和 high 分别是压缩 低端和高端的颜色范围,其数值范围一般是 0~1 ,各位可以调试下。
# 对基金规模以色阶颜色进行标注
# 通过对 low 和 high 值的设置,可以来调节背景颜色的范围
# low 和 high 分别是压缩 低端和高端的颜色范围,其数值范围一般是 0~1 ,各位可以调试下
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.background_gradient(subset=['基金规模(亿)'],cmap='Blues',low=0.3,high=0.9)
效果如下:
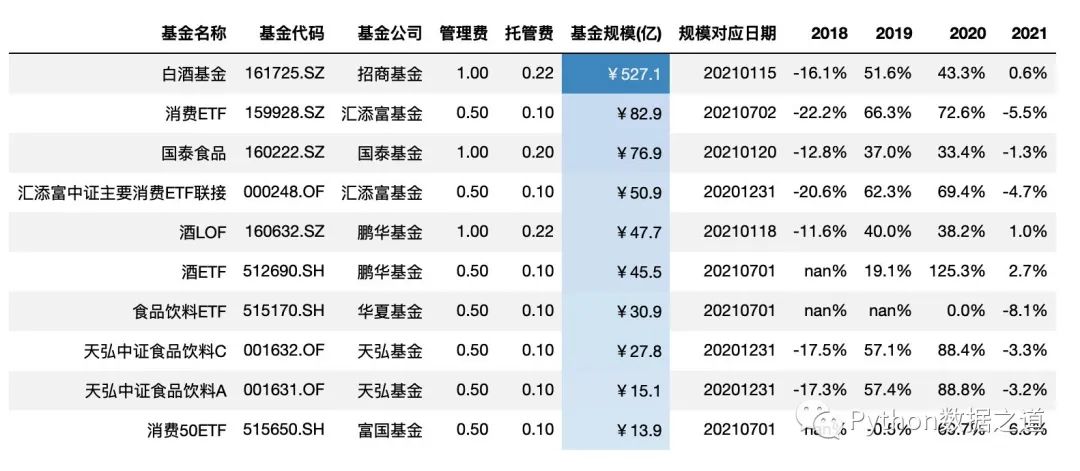
当数据范围比较大时,可以通过设置 vmin 和 vmax 来设置最小和最大的颜色的设置起始点。
比如下面,基金规模在20亿以下的,颜色最浅,规模70亿以上的,颜色最深,20~70亿之间的,颜色渐变。
# 对基金规模以色阶颜色进行标注
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.background_gradient(subset=['基金规模(亿)'],cmap='Blues',vmin=20,vmax=70)
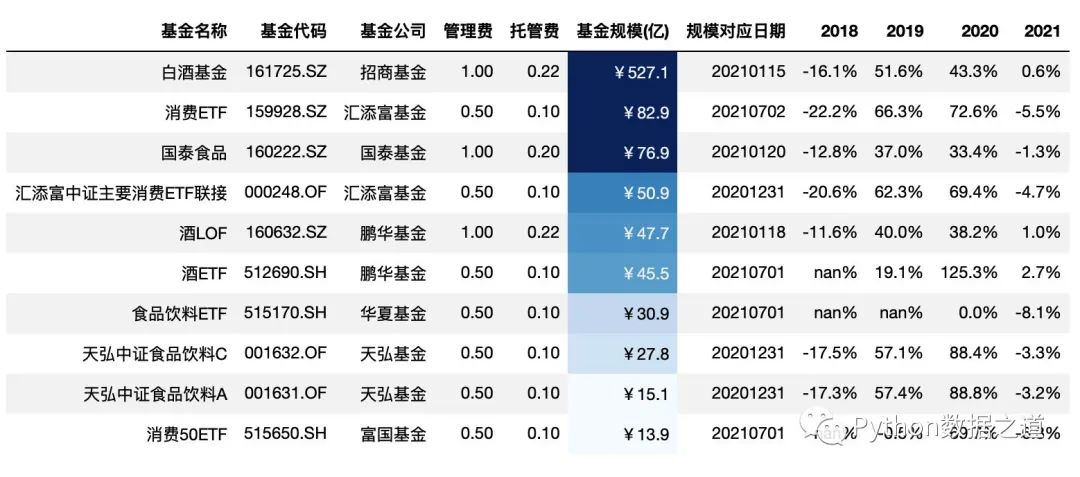
通过 gmap 的设置,可以方便的按照某列的值,对行进行全部的背景设置
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.background_gradient(cmap='Blues',gmap=df_consume['基金规模(亿)'])
效果如下:
gmap 还可以以矩阵的形式对数据进行样式设置,如下:
df_gmap = df_consume.loc[:2,['基金名称','管理费','基金规模(亿)','2020']]
gmap = np.array([[1,2,3], [2,3,4], [3,4,5]]) # 3*3 矩阵,后面需要进行颜色设置的形状也需要是 3*3,需要保持一致
df_gmap.style.background_gradient(axis=None, gmap=gmap,
cmap='Blues', subset=['管理费','基金规模(亿)','2020']
)
效果如下:
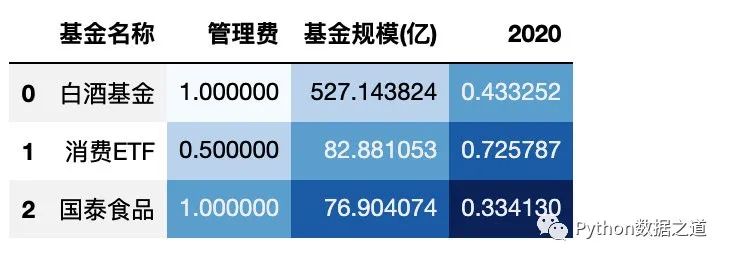
上面 gmap 是 3*3 矩阵,后面需要进行颜色设置的形状也需要是 3*3,需要保持一致。
需要注意的是 颜色设置是根据 gmap中的值来设置颜色深浅的,而不是根据 DataFrame 中的数值来的。
这个在某些特定的情况下可能会用到。
文本色阶颜色设置
类似于背景色阶颜色设置,文本也是可以进行颜色设置的。
使用 text_gradient() 函数可以实现这个功能,其参数如下:
Styler.text_gradient(cmap='PuBu', low=0, high=0, axis=0, subset=None, vmin=None, vmax=None, gmap=None)
text_gradient() 函数的用法跟 background_gradient() 函数的用法基本是一样的。
下面演示两个使用案例,其他的用法参考 background_gradient() 函数。
某列的文本色阶显示
# 对基金规模以色阶颜色进行标注
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.text_gradient(subset=['基金规模(亿)'],cmap='RdYlGn')
效果如下:
全部表格的文本色阶显示
# 通过 `gmap` 的设置,可以方便的按照某列的值,对行进行全部的文本颜色设置
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.text_gradient(cmap='RdYlGn',gmap=df_consume['基金规模(亿)'])
效果如下:
07 数据条显示
数据条的显示方式,可以同时在数据表格里对数据进行可视化显示,这个功能咱们在 Excel 里也是经常用到的。
在 pandas 中,可以使用 DataFrame.style.bar() 函数来实现这个功能,其参数如下:
Styler.bar(subset=None, axis=0, color='#d65f5f', width=100, align='left', vmin=None, vmax=None)
示例代码如下:
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.bar(subset=['基金规模(亿)','2018','2021'],color=['#99ff66','#ee7621'])
效果如下:
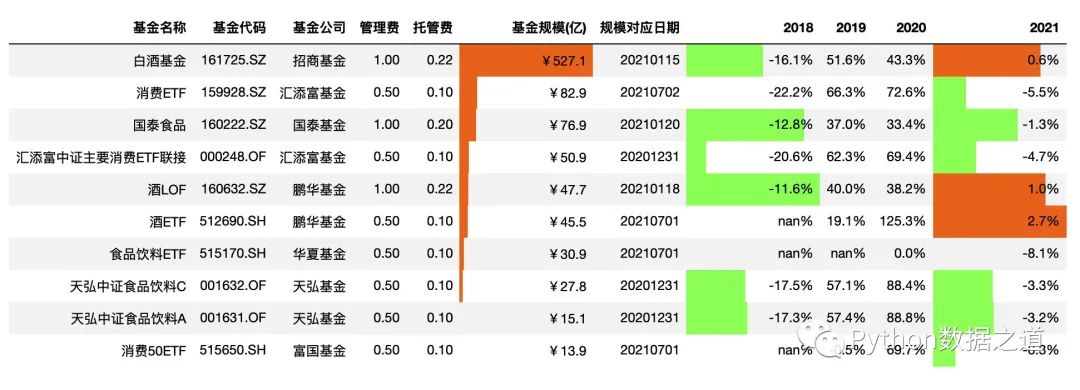
设置对其方式
上面这个可视化效果,对于正负数值的区别,看起来总是有点别扭。
可以通过设置 aligh 参数的值来控制显示方式:
left: 最小值从单元格的左侧开始。
zero: 零值位于单元格的中心。
mid: 单元格的中心在(max-min)/ 2,或者如果值全为负(正),则零对齐于单元格的右(左)。
将显示设置为 mid 后,符合大部分人的视觉审美观,代码如下:
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期'])\
.format(format_dict)\
.bar(subset=['基金规模(亿)','2018','2021'],color=['#99ff66','#ee7621'],align='mid')
效果如下:
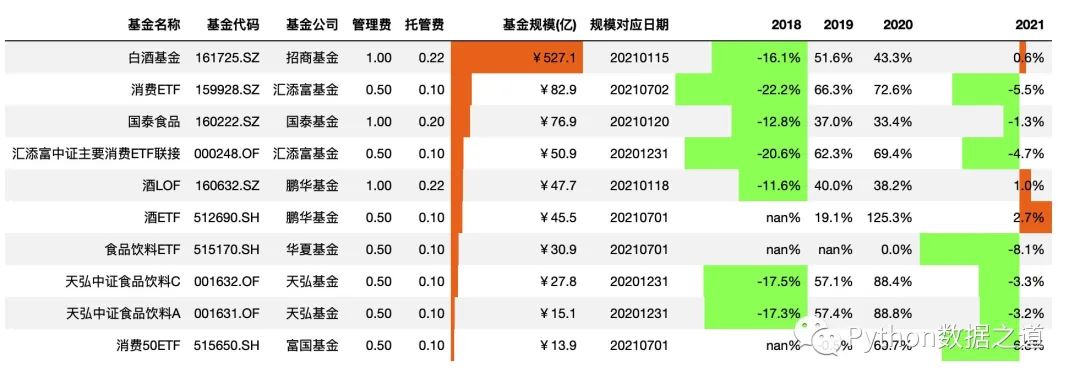
关于颜色设置,color=['#99ff66','#ee7621'], color可以设置为单个颜色,所有的数据只显示同一个颜色,也可以设置为包含两个元素的list或tuple形式,左边的颜色标注负数值,右边的颜色标注正数值。
08 自定义函数的使用
通过 apply 和 applymap 函数,用户可以使用自定义函数来进行样式设置。
其中:
apply通过axis参数,每一次将一列或一行或整个表传递到DataFrame中。对于按列使用 axis=0, 按行使用 axis=1, 整个表使用 axis=None。applymap作用于范围内的每个元素。
apply
先自定义了函数max_value(),用来找到符合条件的最大值,apply 使用的示例代码如下:
按列设置样式
def max_value(x, color='red'):
return np.where(x == np.nanmax(x.to_numpy()), f"color: {color};background-color:yellow", None)
# axis =0 ,按列设置样式
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.apply(max_value,axis=0,subset=['2018','2019','2020','2021'])
效果如下:
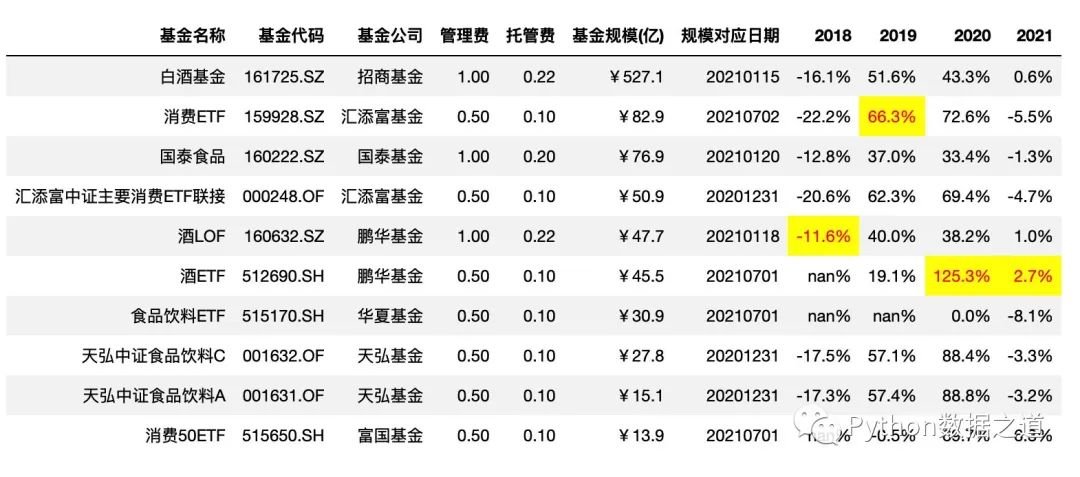
按行设置样式
# axis =1 ,按行设置样式
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.apply(max_value,axis=1,subset=['2018','2019','2020','2021'])
效果如下:
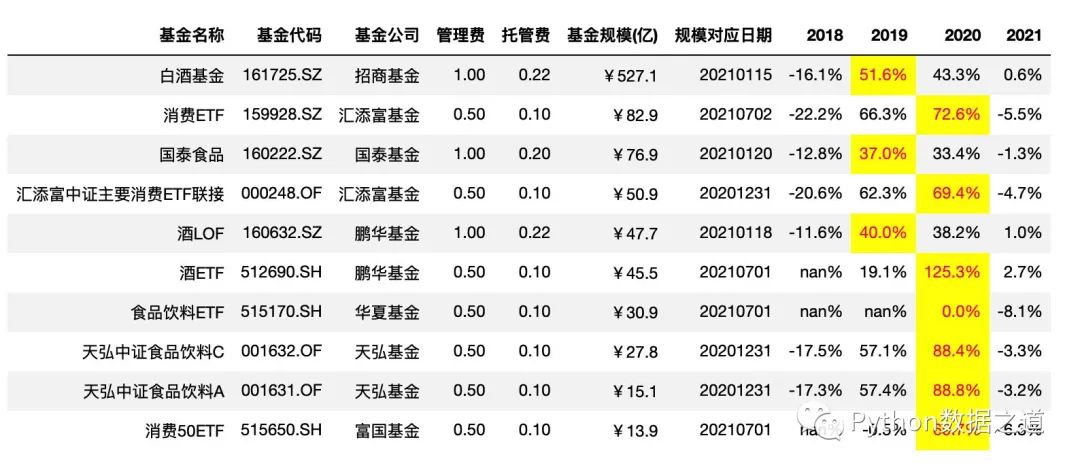
按整个表格设置样式
按整个表格设置样式时,需要注意的是,整个表格的数据类型需要是一样的,不然会报错。
示例代码如下:
# axis = None ,按整个表格设置样式
# 注意,整个表格的数据类型需要是一样的,不然会报错
df_consume_1 = df_consume[['2018','2019','2020','2021']]
# df_consume_1
df_consume_1.style.hide_index().apply(max_value,axis=None)
效果如下:
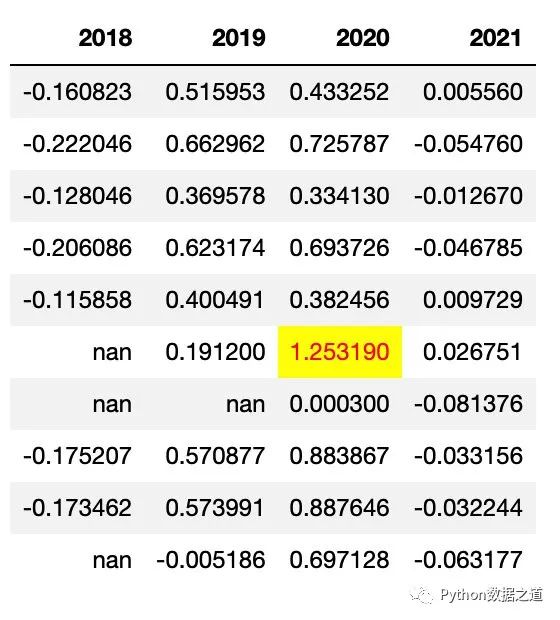
applymap
继续上面的数据表格,我们来自定义一个函数,对于基金的年度涨跌幅情况,年度上涨以橙色背景标注,下跌以绿色背景标注,NaN值以灰色背景标注。
由于 applymap 是作用于每个元素的,因此该函数不需要 axis 这个参数来进行设置,示例代码如下:
def color_returns(val):
if val >=0:
color = '#EE7621' # light red
elif val <0:
color = '#99ff66' # light green '#99ff66'
else:
color = '#FFFAFA' # ligth gray
return f'background-color: {color}'
format_dict = {'基金规模(亿)': '¥{0:.1f}',
'管理费': '{0:.2f}',
'托管费': '{0:.2f}',
'规模对应日期':lambda x: "{}".format(x.strftime('%Y%m%d')),
'2018': '{0:.1%}',
'2019': '{0:.1%}',
'2020': '{0:.1%}',
'2021': '{0:.1%}'
}
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.applymap(color_returns,subset=['2018','2019','2020','2021'])
效果如下:
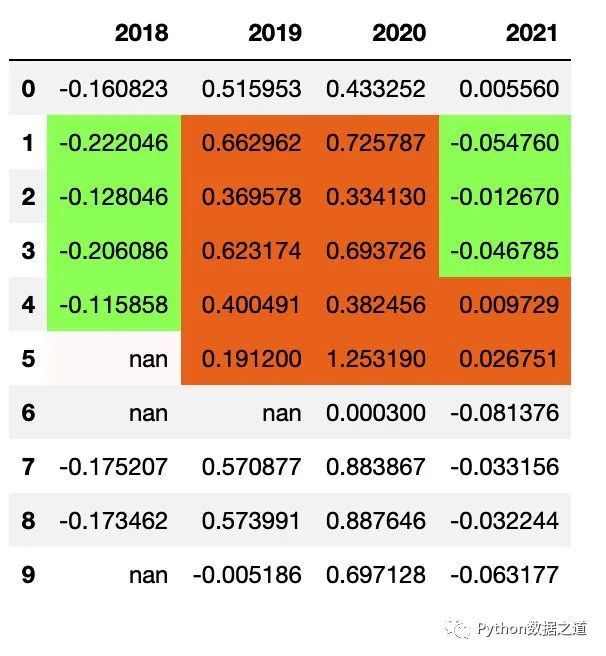
09 颜色设置范围选择
在使用 Style 中的函数对表格数据进行样式设置时,对于有 subset 参数的函数,可以通过设置 行和列的范围来控制需要进行样式设置的区域。
对行(row)进行范围设置
df_consume_1.style.applymap(color_returns,subset=pd.IndexSlice[1:5,])
效果如下:
对列(column)进行范围设置
df_consume_1.style.applymap(color_returns,subset=['2019','2020'])
效果如下:
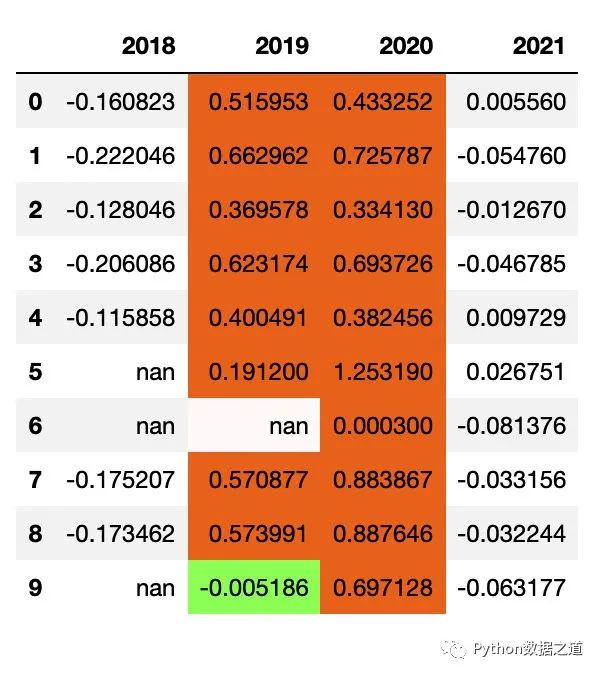
对行和列同时进行范围设置
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.applymap(color_returns,subset=pd.IndexSlice[1:5,['2018','2019','2020']])
效果如下:
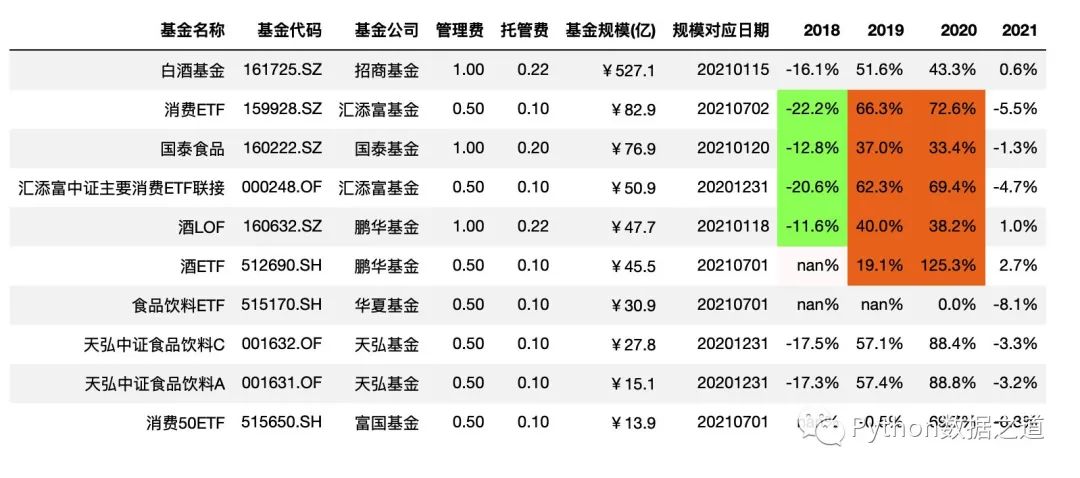
10 共享样式
对于pandas 中样式设置后的共享复用,目前支持通过 Styler.export() 导出样式,然后通过 Styler.use() 来使用导出的样式。
不过经过阳哥的测试,简单的样式导出与使用是可以的。但稍微复杂一些的情况,目前的pandas版本是不太好用的。
简单样式
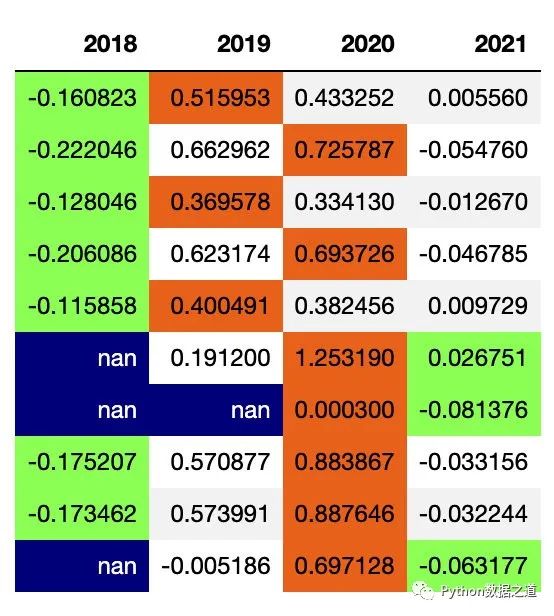
示例如下,先保存当前样式:
df_consume_1 = df_consume[['2018','2019','2020','2021']]
# df_consume_1
style1 = df_consume_1.style.hide_index()\
.highlight_min(axis=1,subset=['2018','2019','2020','2021'],props='color:black;background-color:#99ff66')\
.highlight_max(axis=1,subset=['2018','2019','2020','2021'],props='color:black;background-color:#ee7621')\
.highlight_null(props='color:white;background-color:darkblue')
style1
保存的样式的效果如下:
使用保存的样式:
df_fund_1 = df_fund[['2018','2019','2020','2021']]
df_fund_1.style.use(style1.export())
效果如下:
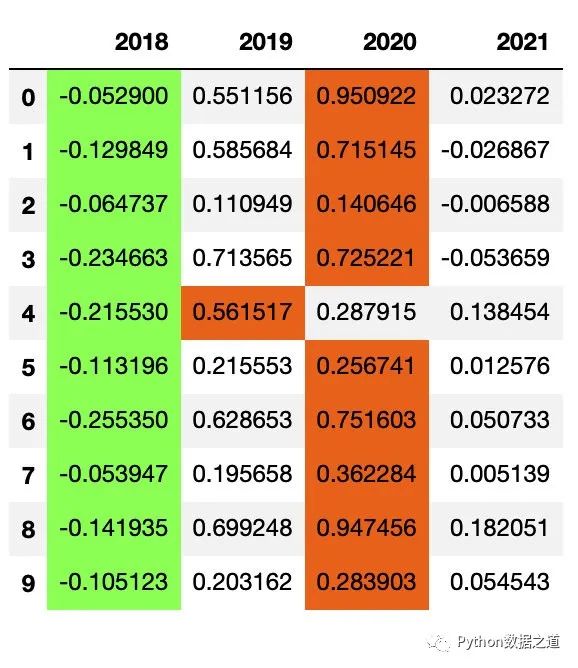
由于后面的数据表格是没有空值的,所以两者的样式实际是一样的。
复杂样式
当样式设置较多时,比如同时隐藏索引、隐藏列、设置数据格式、高亮特定值等,这个时候有些操作在导出后使用时并没有效果。
测试如下,先保存样式:
style3 = df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_min(axis=1,subset=['2018','2019','2020','2021'],props='color:black;background-color:#99ff66')\
.highlight_max(axis=1,subset=['2018','2019','2020','2021'],props='color:black;background-color:#ee7621')\
.highlight_null(props='color:white;background-color:darkblue')
style3
保存样式的效果如下:
使用保存的样式:
df_fund.style.use(style3.export())
效果如下:
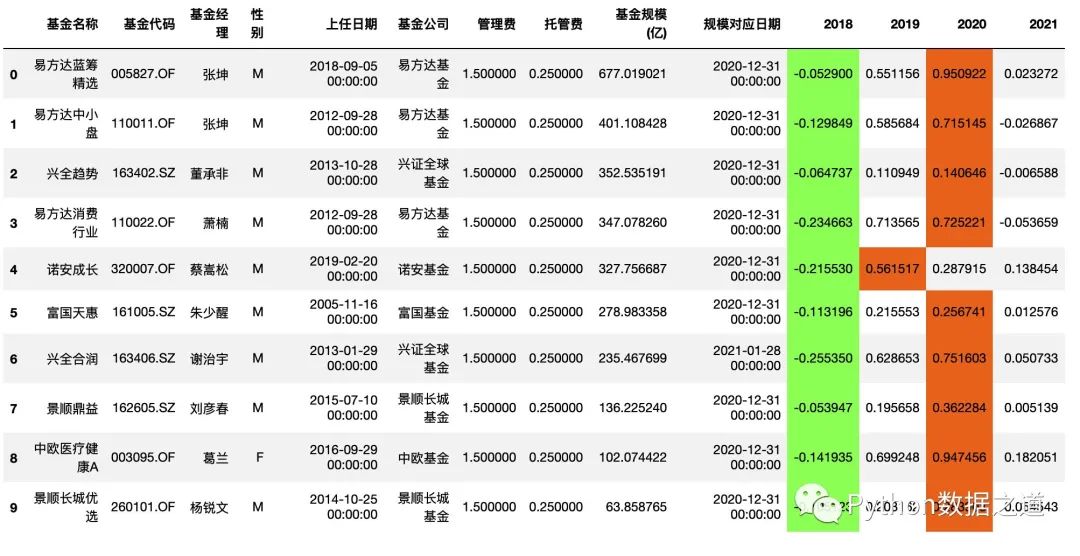
从上面来看,我们希望的样式效果,并没有很好的实现。
所以,针对较为复杂的样式,还是乖乖的复制代码使用吧。
11 导出样式到Excel
导出样式到 Excel 中,这个功能还是比较实用的。
DataFrames 使用 OpenPyXL 或XlsxWriter 引擎可以将样式导出到 Excel 工作表。
不过,这个功能目前也还是处于不断完善过程中,估计有时候有些内容会没有效果。
大家可以在使用过程中来发现其中的一些问题。
来看一个案例:
df_consume.style.hide_index()\
.hide_columns(['性别','基金经理','上任日期',])\
.format(format_dict)\
.highlight_min(axis=1,subset=['2018','2019','2020','2021'],props='color:black;background-color:#99ff66')\
.highlight_max(axis=1,subset=['2018','2019','2020','2021'],props='color:black;background-color:#ee7621')\
.highlight_null(props='color:white;background-color:darkblue')\
.to_excel('style_export.xlsx',engine = 'openpyxl')
上面的案例内容导出到 excel 后,我从 excel 中打开查看了下效果如下:
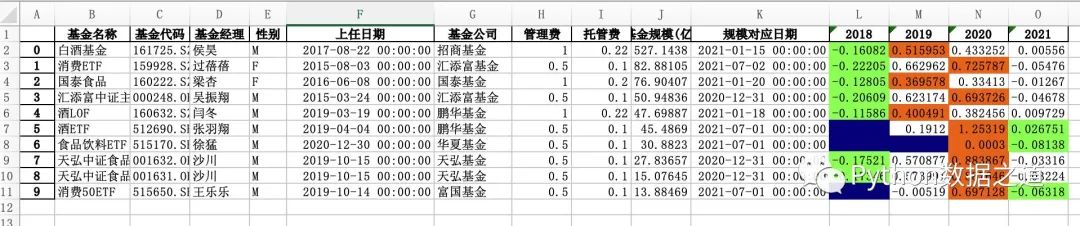
可以看出,跟共享样式里有些相同的问题,比如隐藏索引、隐藏列、设置数据格式等效果并没有实现。
12 总结
以上是 Pandas 表格样式设置内容的汇总,应该是汇集了大部分使用功能。
关于 Pandas 表格样式设置的使用心得,欢迎大家来交流哈。
原创不易,大家读完顺手点下右下角的 “在看”,就是最大的鼓励和支持了。
参考文档
https://pandas.pydata.org/pandas-docs/stable/user_guide/style.html
https://pandas.pydata.org/docs/reference/api/pandas.io.formats.style.Styler.html
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【神秘礼包获取方式】