
英伟达的AI太强了!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
2021年11月9日,英伟达GTC大会顺利开幕!相信不少同学已经看到了刷屏的"Toy-Me"虚拟形象。本文将重点带大家回顾一下这次GTC大会上NVIDIA的一些AI前沿技术。
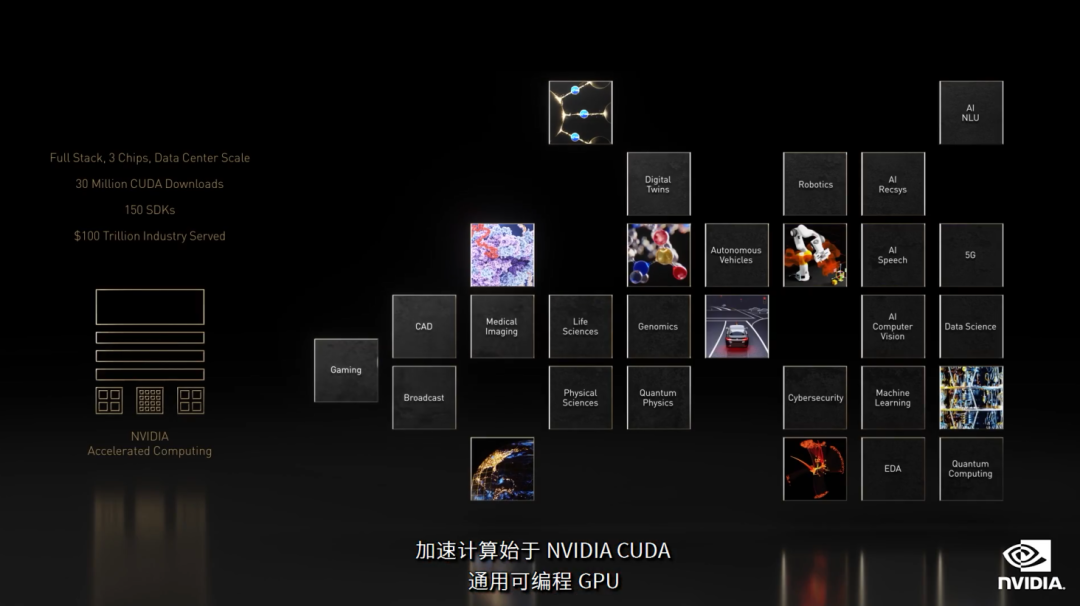
今年 GTC 上一共推出65个全新的以及更新的SDK,信息量相当之大。先看看下面这张图,这才是"真·全栈"AI生态系统。
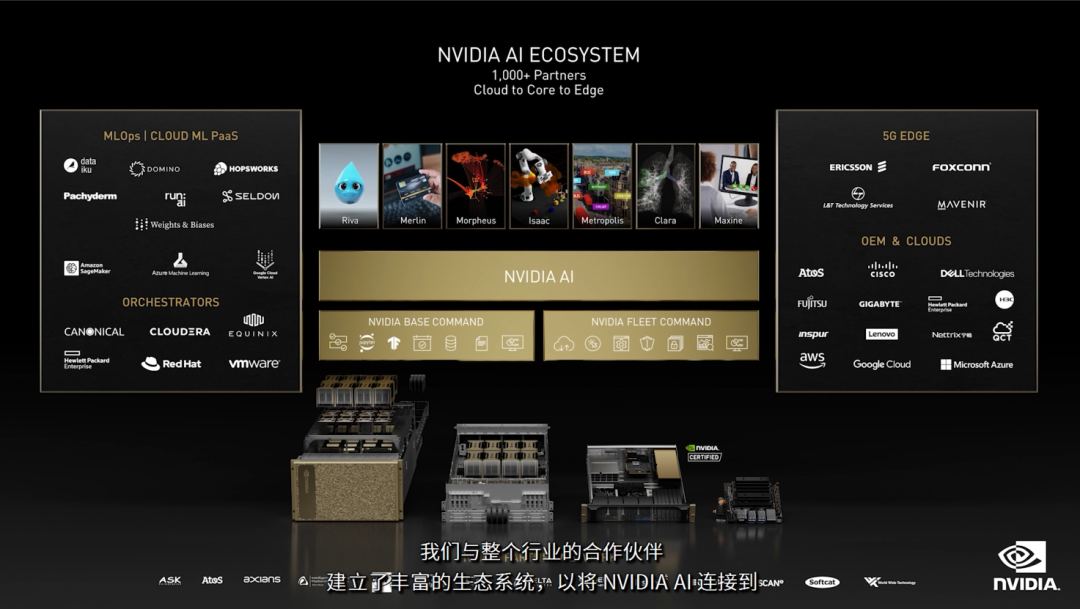
回到GTC大会,初始映入眼帘的还是那个熟悉的厨房~

随后不久,便播放了一段"i am ai"的短片,快速展示了NVIDIA的落地应用和技术实力。

NeMo Megatron 加速大型语言模型开发
NVIDIA NeMo Megatron 是基于Megatron而开发的项目。其中Megatron是一个基于PyTorch的框架,用于训练基于Transformer架构的大型语言模型。
NeMo Megatron 让训练具有数万亿参数的大型语言模型(LLM)变得可能,而且据我了解,目前市面上鲜有这样支持大型语言模型的训练框架,这个实实在在的"利好"各大企业,特别是资源受限的情况下。不管你的语言模型多么复杂,经过NeMo Megatron 优化,可以极大提高训练的效率。解决训练难题后,便可以迁移到对话式AI(比如聊天机器人)等应用,进一步提升产业自动化效率。
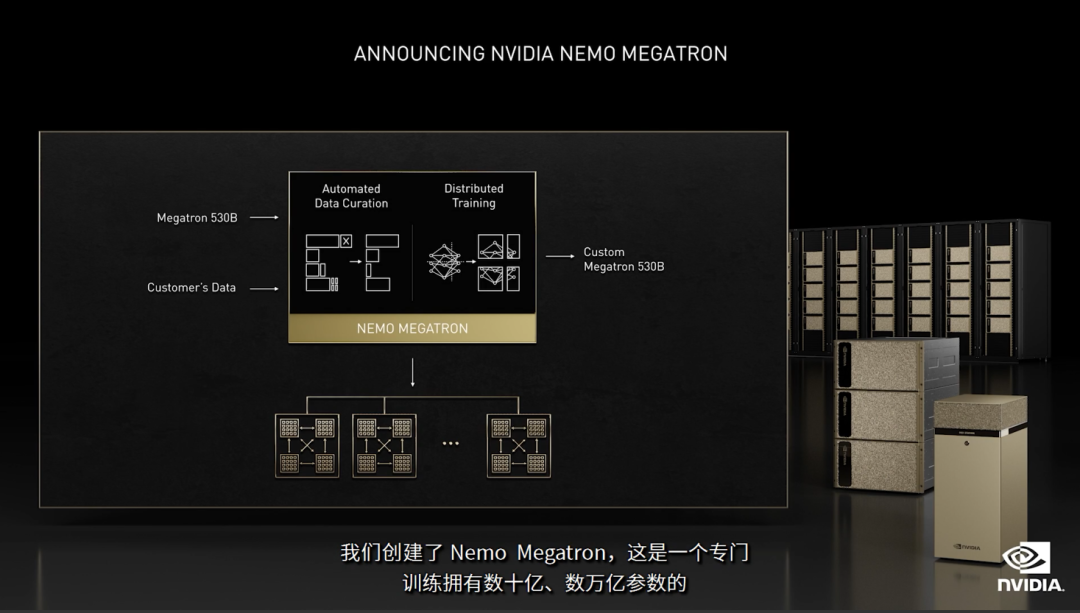
比如可以训练前不久发布的"5300亿参数的「威震天-图灵」"的Megatron 530B。Megatron 530B 又称为Megatron-Turing (MT-NLP),其是英伟达和微软共同推出的目前世界上最大的可定制语言模型。

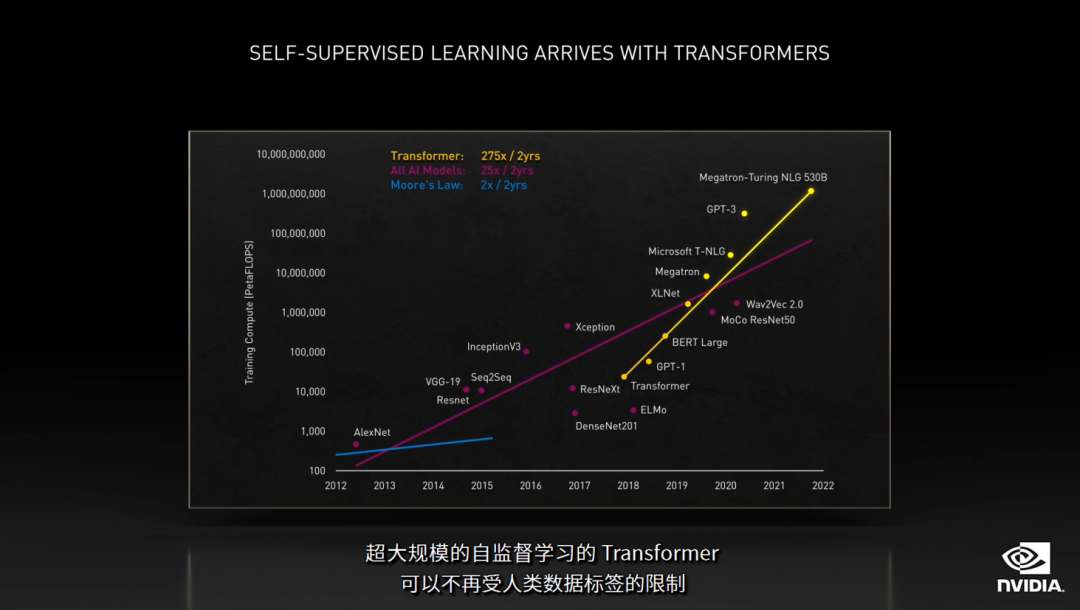
聊到语言模型,就不得不提近几年大火的Transformer!而NVIDIA专门针对Transformer架构的模型进行了分析和训练优化,使得训练大型语言模型变得可能。

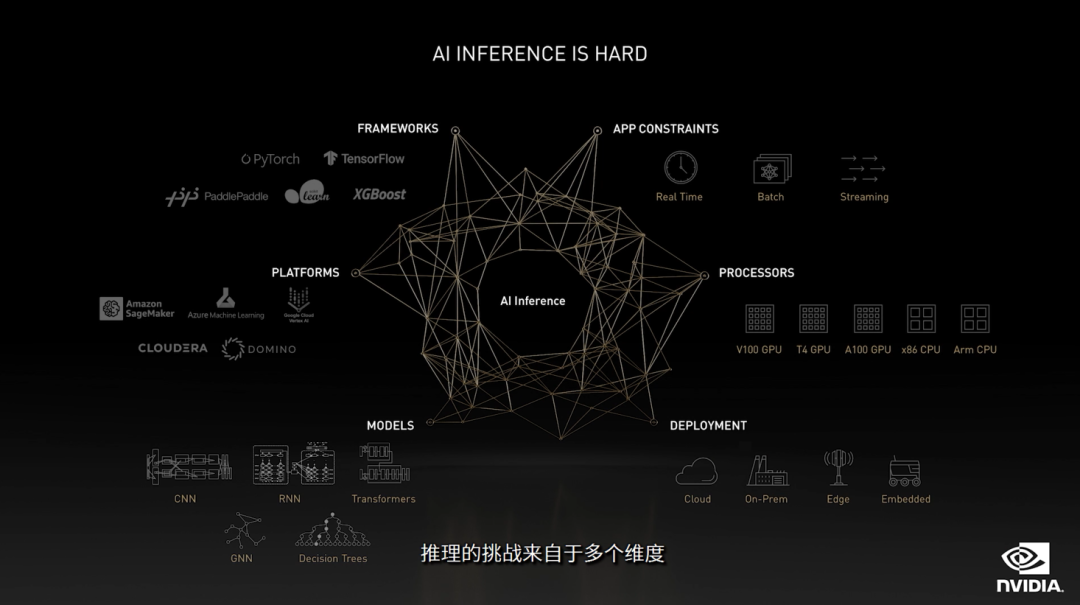
NVIDIA AI 推理平台重大更新
模型训练好了,当然就需要推理部署用起来(一条龙服务)。推理响应速度越快,所带来的效益就越大,因此各大厂商都一直致力于加快模型推理,而NVIDIA在这一方面更是做到极致。
英伟达创建了世界上第一个分布式推理引擎:NVIDIA Triton,可以为所有AI模型、框架提供跨平台推理。

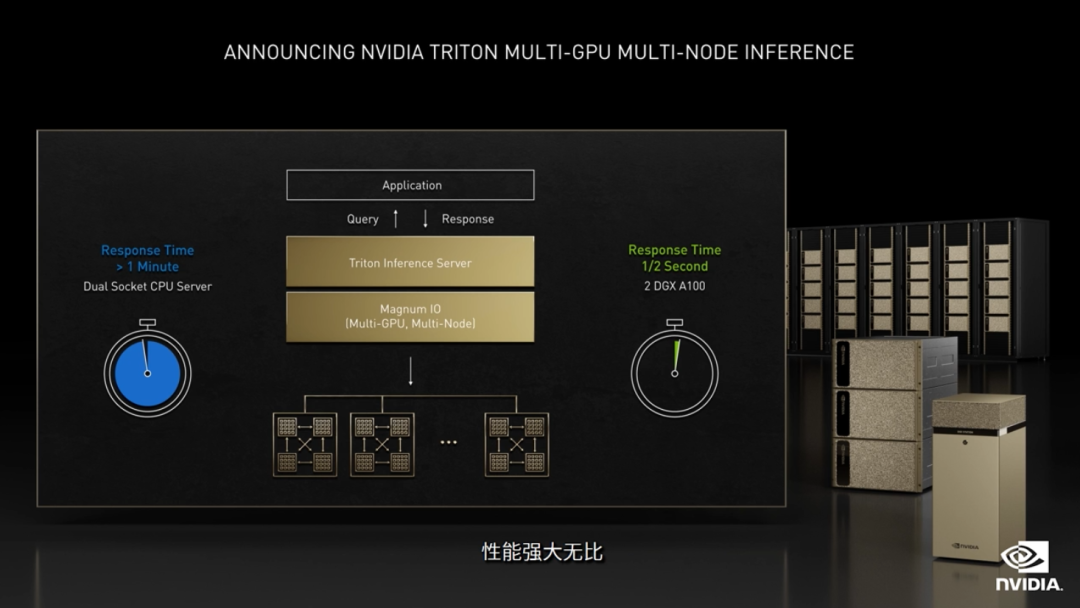
这次GTC大会上发布了Triton推理服务器的重大更新,其中包括:Triton 模型分析器、多 GPU 多节点功能(支持基于Transformer的大规模语言模型,例如Megatron 530B)、RAPIDS FIL和Amazon SageMaker 集成等等。
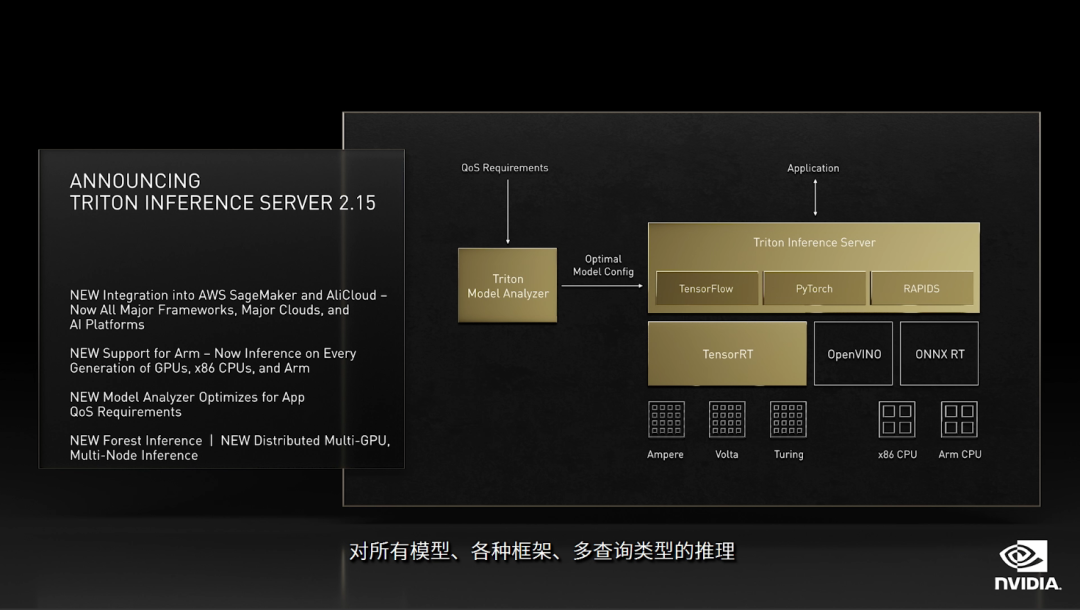
有意思的是Triton推理服务器可以自动为模型选择最佳配置,这个实在太方便了。而且它不仅支持深度学习模型,还支持传统机器学习模型,比如随机森林和梯度提升树。虽然DL大火,但很多经典ML模型应用依然广泛,所以显得Triton非常实用。同时还支持PyTorch、TensorFlow等多种深度学习框架,大大降低用户的迁移成本和维护成本。
实际拿Megatron 530B来举例,通过Triton推理服务器,Megatron 530B能够在两个NVIDIA DGX系统上运行,将处理时间从CPU服务器上的1分钟以上缩短到半秒,使得实时应用部署大型语言模型成为可能。
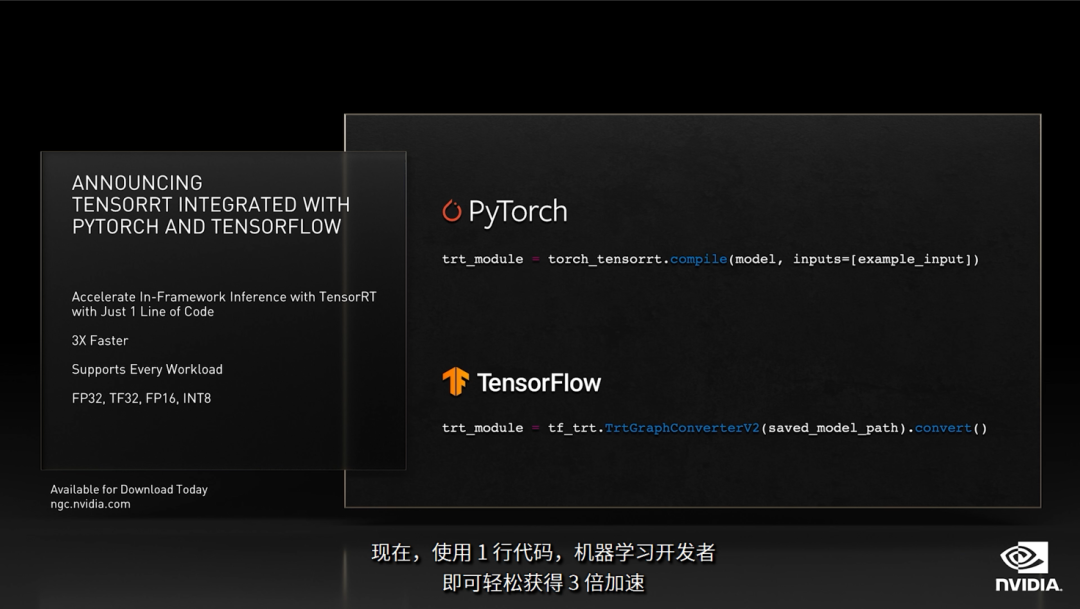
除了Triton外,这次发布还包含对NVIDIA TensorRT的更新。实际做过AI模型部署的同学,应该会对TensorRT比较熟悉了,其主要是为NVIDIA GPU上的高性能推理提供运行时优化。目前该最新版本是TensorRT 8.2。

TensorRT 已经与TensorFlow、PyTorch集成,只需一行代码就能提供比框架内推理快3倍的性能。这使得开发人员采用极为简化的工作流程就可以体会TensorRT的强大功能。

除了上述软件更新之外,NVIDIA还推出了NVIDIA A2 Tensor Core GPU,这是一款用于边缘AI推理的低功耗、小尺寸的加速器,其推理性能比CPU高出20倍。

NVIDIA Riva 新增定制语音功能
NVIDIA Riva 定制语音是NVIDIA Riva 语音 AI 软件的一项功能,它提供了强大的功能:使用少量数据即可在数小时内开发富有表现力的定制语音。在GTC大会上,有一段Riva定制语音的演示,展示了只需30分钟的数据就能创造出类似人类的新的声音。


Riva还通过Project Tokkio、DRIVE Concierge和Project Maxine在Omniverse Avatar中得以展现。
在我看来,NVIDIA Riva定制语音的落地应用会相当广泛,比如目前大火的虚拟形象(如虚拟偶像、虚拟主播等)就相当依赖这种技术。而且可以帮助公司、学校甚至个人打造属于自己的"专属声音",比如帮助公司的聊天机器人(语音版)"真人化"。
值得提醒一下:在GTC上,有二十多场专注于对话式AI的演讲,包括Hugging Face、Snap、T-Mobile等公司的演讲。演讲主题涉及开发和整合GPU加速的语音和语言AI应用等方面最先进的算法、工具、挑战以及效果等。
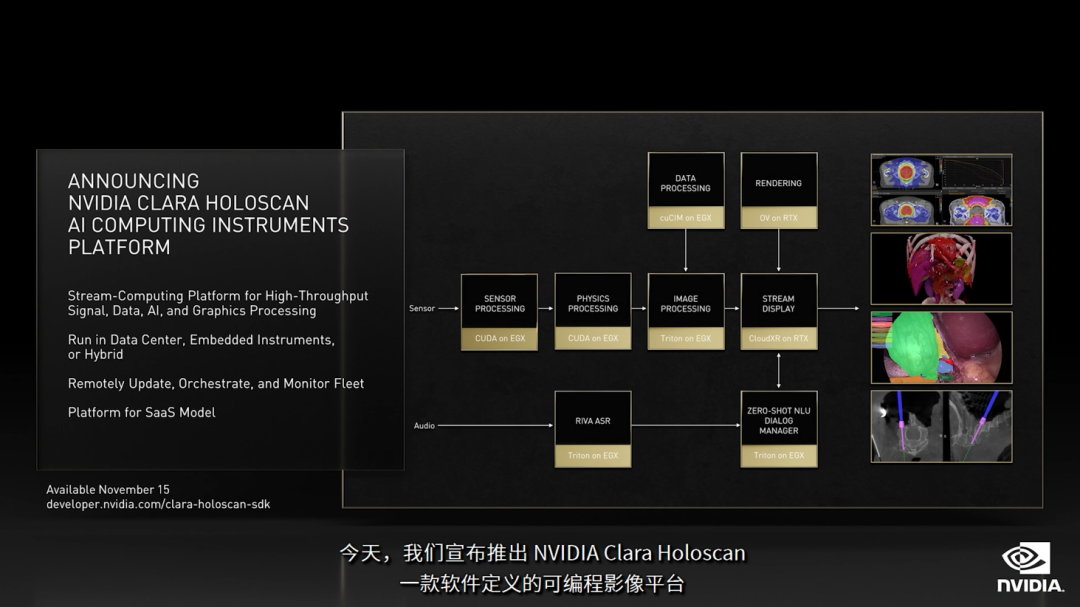
Clara Holoscan 医疗健康行业的新计算平台
NVIDIA Clara Holoscan是英伟达推出的第三个机器人平台,即:医疗健康行业的新计算平台。基于NVIDIA AGX Orin打造,能为可扩展、软件定义、端到端流媒体数据处理的医疗设备提供所需的计算基础设施。
Clara Holoscan 是一个性能强大的可编程影像平台,目前已具有医学图像分割、2D/3D医学数据可视化、手动/语音交互式操作、智能诊断等功能。我看了下面的演示视频,感到十分惊艳。Clara Holoscan这个平台和医疗设备厂家深入合作,一定可以促进AI医疗领域发展,为医疗专业人员提供更好的诊断工具,在分析病人病情、机器人辅助手术等方面提供帮助。

作为可扩展的体系架构,Clara Holoscan 能够从医疗设备扩展到NVIDIA 认证边缘服务器,再到数据中心或云中的NVIDIA DGX 系统。开发者可通过此平台,按需在其医疗设备中充分添加或减少计算和输入/输出功能,从而平衡延迟、成本、空间、性能和带宽的需求。
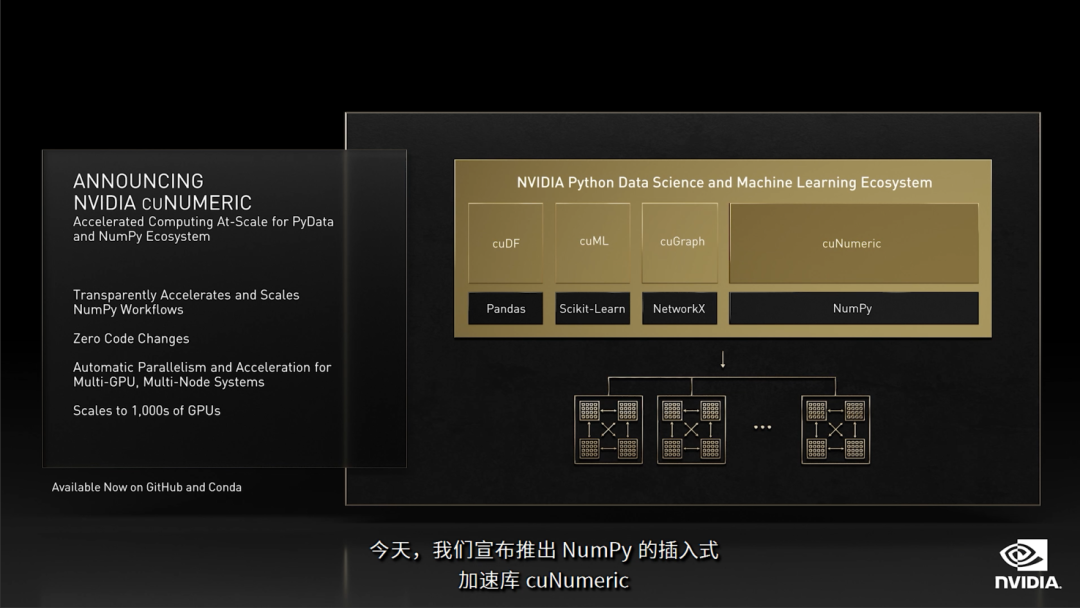
cuNumeric
在本次GTC大会上,我还看到一个可以快速访问使用的"神器":cuNumeric,也许可以帮助你加快当前项目代码中的Numpy部分计算。
Numpy是我们经常用的Python的扩展程序库,而NVIDIA正式推出针对Numpy的插入式加速库cuNumeric。无需更改代码!从单一GPU扩展到多GPU,扩展到多节点集群,进而扩展到世界上最大超级计算机。
而且在GTC上还看到一个数据:过去15年里,CUDA下载量高达3000万次!而仅去年下载量就突破700万次!不得不感叹:这得帮助打造多少款落地应用呀,CUDA YYDS!
GTC大会上还有很多精彩内容,比如"元宇宙"十足的Omniverse Avatars、重磅发布的Jetson AGX Orin、NVIDIA Quantum-2网络平台、在自动驾驶领域的成果展示等,以及刷屏的"Toy-Me"虚拟形象:

强烈推荐学习!如果你未能第一时间参加GTC大会,想了解更多的AI前沿技术和应用,则可以扫描或者点击阅读原文,即可观看录播视频~
扫码观看GTC大会视频
🌟点击阅读原文,也可快速观看大会视频!