
MYSQL最朴素的监控方式
一、连接数(Connects)
最大使用连接数:show status like ‘Max_used_connections’
当前打开的连接数:show status like ‘Threads_connected’
二、缓存(bufferCache)
未从缓冲池读取的次数:show status like ‘Innodb_buffer_pool_reads’
从缓冲池读取:show status like ‘Innodb_buffer_pool_read_requests’
缓冲池的总页数:show status like ‘Innodb_buffer_pool_pages_total’
缓冲池空闲页数:show status like ‘Innodb_buffer_pool_pages_free’
缓存命中率计算:(1-Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests)*100%
缓存池使用率为:((Innodb_buffer_pool_pages_total-Innodb_buffer_pool_pages_free)/Innodb_buffer_pool_pages_total)*100%
三、锁(lock)
锁等待个数:show status like ‘Innodb_row_lock_waits’
平均每次锁等待时间:show status like ‘Innodb_row_lock_time_avg’
查看是否存在表锁:show open TABLES where in_use>0;有数据代表存在锁表,空为无表锁
四、SQL
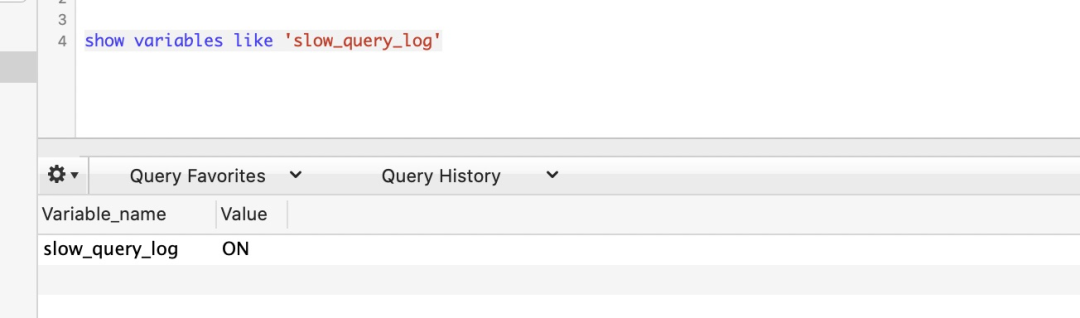
查看 mysql 开关是否打开:show variables like ‘slow_query_log’,ON 为开启状态,如果为 OFF,set global slow_query_log=1 进行开启。
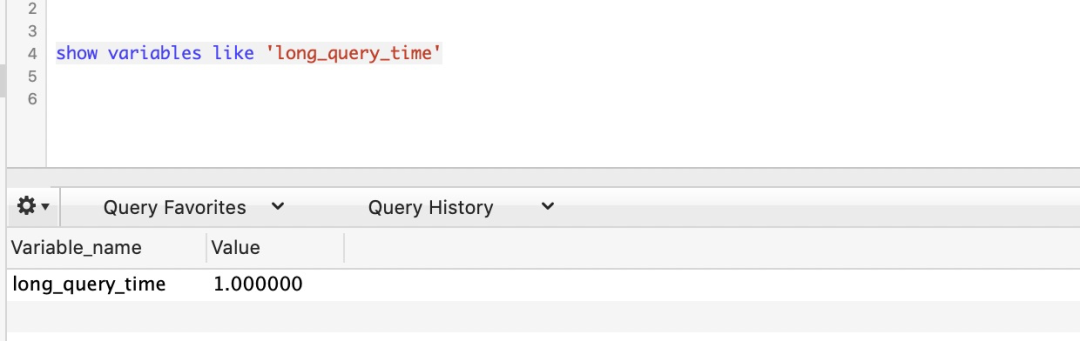
查看 mysql 阈值:show variables like ‘long_query_time’,根据页面传递阈值参数,修改阈值 set global long_query_time=0.1
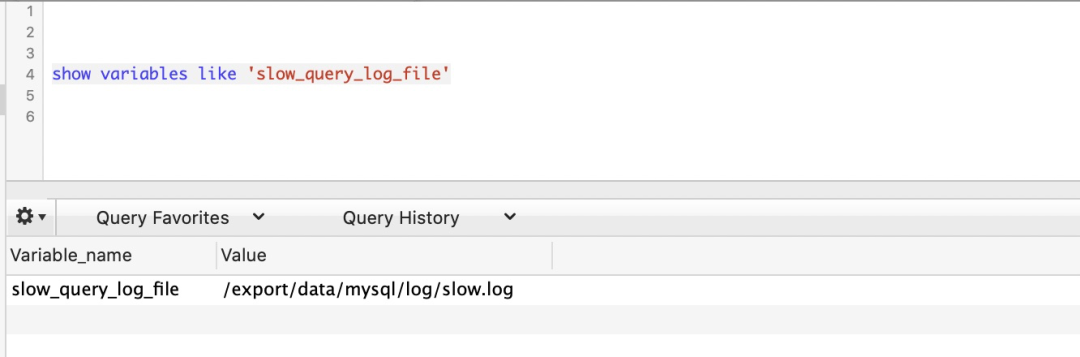
查看 mysql 慢 sql 目录:show variables like ‘slow_query_log_file’
格式化慢 sql 日志:mysqldumpslow -s at -t 10 /export/data/mysql/log/slow.log
注:此语句通过 jdbc 执行不了,属于命令行执行。
意思为:显示出耗时最长的 10 个 SQL 语句执行信息,10 可以修改为 TOP 个数。显示的信息为:执行次数、平均执行时间、SQL 语句。
五、statement
insert 数量:show status like ‘Com_insert’
delete 数量:show status like ‘Com_delete’
update 数量:show status like ‘Com_update’
select 数量:show status like ‘Com_select’
六、吞吐(Database throughputs)
发送吞吐量:show status like ‘Bytes_sent’
接收吞吐量:show status like ‘Bytes_received’
总吞吐量:Bytes_sent+Bytes_received
七、数据库参数(serverconfig)
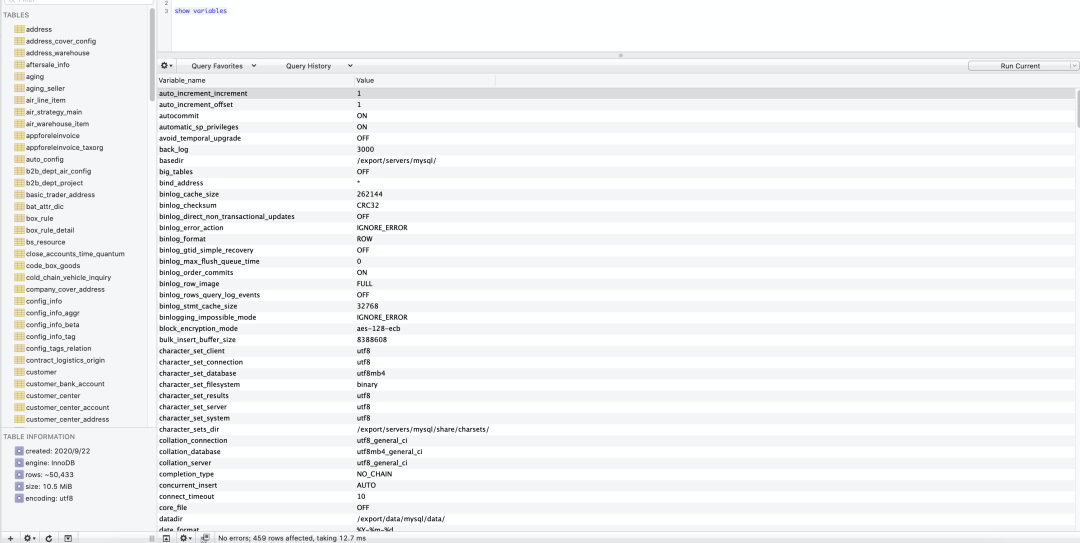
八、慢 SQL
确保打开慢 SQL 开关 slow_query_log
设置慢 SQL 域值 long_query_time
这个 long_query_time 是用来定义慢于多少秒的才算 “慢查询”,注意单位是秒,我通过执行 sql 指令 set long_query_time=1 来设置了 long_query_time 的值为 1, 也就是执行时间超过 1 秒的都算慢查询,如下:
查看慢 SQL 日志路径
通过慢 sql 分析工具 mysqldumpslow 格式化分析慢 SQL 日志
mysqldumpslow 慢查询分析工具,是 mysql 安装后自带的,可以通过./mysqldumpslow —help 查看使用参数说明
取出使用最多的 10 条慢查询
./mysqldumpslow -s c -t 10 /export/data/mysql/log/slow.log取出查询时间最慢的 3 条慢查询
./mysqldumpslow -s t -t 3 /export/data/mysql/log/slow.log
Count: 2 Time=1.5s (3s) Lock=0.00s (0s) Rows=1000.0 (2000), vgos_dba[vgos_dba]@[10.130.229.196]SELECT FROM sms_send WHERE service_id=N GROUP BY content LIMIT N, N
Count:表示该类型的语句执行次数,上图中表示 select 语句执行了 2 次。
Time:表示该类型的语句执行的平均时间(总计时间)
Lock:锁时间 0s。
Rows:单次返回的结果数是 1000 条记录,2 次总共返回 2000 条记录。
1.不使用子查询
SELECT FROM t1 WHERE id (SELECT id FROM t2 WHERE name=’hechunyang’);
子查询在 MySQL5.5 版本里,内部执行计划器是这样执行的:先查外表再匹配内表,而不是先查内表 t2,当外表的数据很大时,查询速度会非常慢。
在 MariaDB10/MySQL5.6 版本里,采用 join 关联方式对其进行了优化,这条 SQL 会自动转换为 SELECT t1. FROM t1 JOIN t2 ON t1.id = t2.id;
但请注意的是:优化只针对 SELECT 有效,对 UPDATE/DELETE 子 查询无效, 生产环境尽量应避免使用子查询。
2.避免函数索引
SELECT FROM t WHERE YEAR(d) >= 2016;
由于 MySQL 不像 Oracle 那样⽀持函数索引,即使 d 字段有索引,也会直接全表扫描。
应改为 > SELECT FROM t WHERE d >= ‘2016-01-01’;
3.用 IN 来替换 OR 低效查询
慢 SELECT FROM t WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30;
高效查询 > SELECT FROM t WHERE LOC_IN IN (10,20,30);
4.LIKE 双百分号无法使用到索引
SELECT FROM t WHERE name LIKE ‘%de%’;
使用 SELECT FROM t WHERE name LIKE ‘de%’;
5.分组统计可以禁止排序
SELECT goods_id,count() FROM t GROUP BY goods_id;
默认情况下,MySQL 对所有 GROUP BY col1,col2… 的字段进⾏排序。如果查询包括 GROUP BY,想要避免排序结果的消耗,则可以指定 ORDER BY NULL 禁止排序。
使用 SELECT goods_id,count () FROM t GROUP BY goods_id ORDER BY NULL;
6.禁止不必要的 ORDER BY 排序
SELECT count(1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id WHERE 1 = 1 ORDER BY u.create_time DESC;
使用 SELECT count (1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id;
九、总结
任何东西不应过重关注其外表,要注重内在的东西,往往绚丽的外表下会有对应的负担和损耗。
mysql 数据库的监控支持通过 SQL 方式从 performance_schema 库中访问对应的表数据,前提是初始化此库并开启监控数据写入。
对于监控而言,不在于手段的多样性,而需要明白监控的本质,以及需要的监控项内容,找到符合自身项目特色的监控方式。
在选择监控工具对 mysql 监控时,需要关注监控工具本身对于数据库服务器的消耗,不要影响到其自身的使用。
原文链接:https://my.oschina.net/u/4090830/blog/5564849
作者:安甲舒
来源:OSCHINA 开源社区