
动手实现一个 localcache - 设计篇
前言
哈喽,大家好,我是asong。最近想动手写一个localcache练练手,工作这么久了,也看过很多同事实现的本地缓存,都各有所长,自己平时也在思考如何实现一个高性能的本地缓存,接下来我将基于自己的理解实现一版本地缓存,欢迎各位大佬们提出宝贵意见,我会根据意见不断完善的。
本篇主要介绍设计一个本地缓存都要考虑什么点,后续为实现文章,欢迎关注这个系列。
为什么要有本地缓存
随着互联网的普及,用户数和访问量越来越大,这就需要我们的应用支撑更多的并发量,比如某宝的首页流量,大量的用户同时进入首页,对我们的应用服务器和数据库服务器造成的计算也是巨大的,本身数据库访问就占用数据库连接,导致网络开销巨大,在面对如此高的并发量下,数据库就会面临瓶颈,这时就要考虑加缓存,缓存就分为分布式缓存和本地缓存,大多数场景我们使用分布式缓存就可以满足要求,分布式缓存访问速度也很快,但是数据需要跨网络传输,在面对首页这种高并发量级下,对性能要求是很高的,不能放过一点点的性能优化空间,这时我们就可以选择使用本地缓存来提高性能,本地缓存不需要跨网络传输,应用和cache都在同一个进程内部,快速请求,适用于首页这种数据更新频率较低的业务场景。
综上所述,我们往往使用本地缓存后的系统架构是这样的:
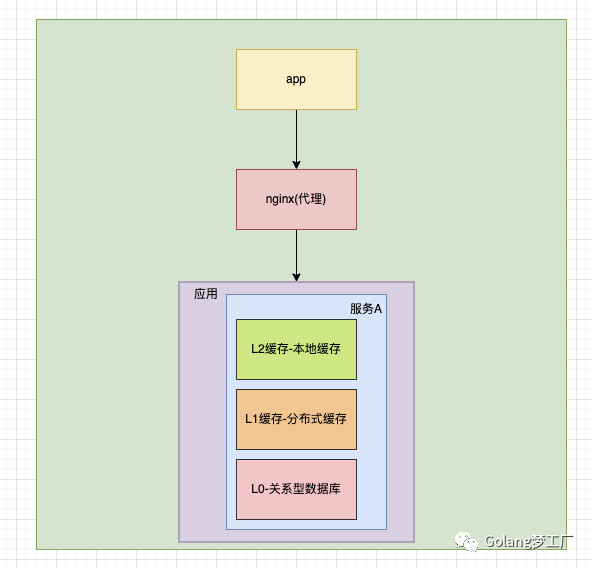
本地缓存虽然带来性能优化,不过也是有一些弊端的,缓存与应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费,使用缓存的是我们程序员自己,我们要根据根据数据类型、业务场景来准确判断使用何种类型的缓存,如何使用这种缓存,以最小的成本最快的效率达到最优的目的。
思考:如何实现一个高性能本地缓存
数据结构
第一步我们就要考虑数据该怎样存储;数据的查找效率要高,首先我们就想到了哈希表,哈希表的查找效率高,时间复杂度为O(1),可以满足我们的需求;确定是使用什么结构来存储,接下来我们要考虑以什么类型进行存储,因为不同的业务场景使用的数据类型不同,为了通用,在java中我们可以使用泛型,Go语言中暂时没有泛型,我们可以使用interface类型来代替,把解析数据交给程序员自己来进行断言,增强了可扩展性,同时也增加一些风险。
总结:
数据结构:哈希表; key:string类型;value:interface类型;
并发安全
本地缓存的应用肯定会面对并发读写的场景,这是就要考虑并发安全的问题。因为我们选择的是哈希结构,Go语言中主要提供了两种哈希,一种是非线程安全的map,一种是线程安全的sync.map,为了方便我们可以直接选择sync.map,也可以考虑使用map+sync.RWMutex组合方式自己实现保证线程安全,网上有人对这两种方式进行比较,在读操作远多于写操作的时候,使用sync.map的性能是远高于map+sync.RWMutex的组合的。在本地缓存中读操作是远高于写操作的,但是我们本地缓存不仅支持进行数据存储的时候要使用锁,进行过期清除等操作时也需要加锁,所以使用map+sync.RWMutex的方式更灵活,所以这里我们选择这种方式保证并发安全。
高性能并发访问
加锁可以保证数据的读写安全性,但是会增加锁竞争,本地缓存本来就是为了提升性能而设计出来,不能让其成为性能瓶颈,所以我们要对锁竞争进行优化。针对本地缓存的应用场景,我们可以根据key进行分桶处理,减少锁竞争。
我们的key都是string类型,所以我们可以使用djb2哈希算法把key打散进行分桶,然后在对每一个桶进行加锁,也就是锁细化,减少竞争。
对象上限
因为本地缓存是在内存中存储的,内存都是有限制的,我们不可能无限存储,所以我们可以指定缓存对象的数量,根据我们具体的应用场景去预估这个上限值,默认我们选择缓存的数量为1024。
淘汰策略
因为我们会设置缓存对象的数量,当触发上限值时,可以使用淘汰策略淘汰掉,常见的缓存淘汰算法有:
LFU
LFU(Least Frequently Used)即最近不常用算法,根据数据的历史访问频率来淘汰数据,这种算法核心思想认为最近使用频率低的数据,很大概率不会再使用,把使用频率最小的数据置换出去。
存在的问题:
某些数据在短时间内被高频访问,在之后的很长一段时间不再被访问,因为之前的访问频率急剧增加,那么在之后不会在短时间内被淘汰,占据着队列前头的位置,会导致更频繁使用的块更容易被清除掉,刚进入的缓存新数据也可能会很快的被删除。
LRU
LRU(Least Recently User)即最近最少使用算法,根据数据的历史访问记录来淘汰数据,这种算法核心思想认为最近使用的数据很大概率会再次使用,最近一段时间没有使用的数据,很大概率不会再次使用,把最长时间未被访问的数据置换出去
存在问题:
当某个客户端访问了大量的历史数据时,可能会使缓存中的数据被历史数据替换,降低缓存命中率。
FIFO
FIFO(First in First out)即先进先出算法,这种算法的核心思想是最近刚访问的,将来访问的可能性比较大,先进入缓存的数据最先被淘汰掉。
存在的问题:
这种算法采用绝对公平的方式进行数据置换,很容易发生缺页中断问题。
Two Queues
Two Queues是FIFO + LRU的结合,其核心思想是当数据第一次访问时,将数据缓存在FIFO队列中,当数据第二次被访问时将数据从FIFO队列移到LRU队列里面,这两个队列按照自己的方法淘汰数据。
存在问题:
这种算法和LRU-2一致,适应性差,存在LRU中的数据需要大量的访问才会将历史记录清除掉。
ARU
ARU(Adaptive Replacement Cache)即自适应缓存替换算法,是LFU和LRU算法的结合使用,其核心思想是根据被淘汰数据的访问情况,而增加对应 LRU 还是 LFU链表的大小,ARU主要包含了四个链表,LRU 和 LRU Ghost ,LFU 和LFU Ghost, Ghost 链表为对应淘汰的数据记录链表,不记录数据,只记录 ID 等信息。

当数据被访问时加入LRU队列,如果该数据再次被访问,则同时被放到 LFU 链表中;如果该数据在LRU队列中淘汰了,那么该数据进入LRU Ghost队列,如果之后该数据在之后被再次访问了,就增加LRU队列的大小,同时缩减LFU队列的大小。
存在问题:
因为要维护四个队列,会占用更多的内存空间。
选择
每一种算法都有自己特色,结合我们本地缓存使用的场景,选择ARU算法来做缓存缓存淘汰策略是一个不错的选择,可以动态调整 LRU 和 LFU 的大小,以适应当前最佳的缓存命中。
过期清除
除了使用缓存淘汰策略清除数据外,还可以添加一个过期时间做双重保证,避免不经常访问的数据一直占用内存。可以有两种做法:
数据过期了直接删除 数据过期了不删除,异步更新数据
两种做法各有利弊,异步更新数据需要具体业务场景选择,为了迎合大多数业务,我们采用数据过期了直接删除这种方法更友好,这里我们采用懒加载的方式,在获取数据的时候判断数据是否过期,同时设置一个定时任务,每天定时删除过期的数据。
缓存监控
很多人对于缓存的监控也比较忽略,基本写完后不报错就默认他已经生效了,这就无法感知这个缓存是否起作用了,所以对于缓存各种指标的监控,也比较重要,通过其不同的指标数据,我们可以对缓存的参数进行优化,从而让缓存达到最优化。如果是企业应用,我们可以使用Prometheus进行监控上报,我们自测可以简单写一个小组件,定时打印缓存数、缓存命中率等指标。
GC调优
对于大量使用本地缓存的应用,由于涉及到缓存淘汰,那么GC问题必定是常事。如果出现GC较多,STW时间较长,那么必定会影响服务可用性;对于这个事项一般是具体case具体分析,本地缓存上线后记得经常查看GC监控。
缓存穿透
使用缓存就要考虑缓存穿透的问题,不过这个一般不在本地缓存中实现,基本交给使用者来实现,当在缓存中找不到元素时,它设置对缓存键的锁定;这样其他线程将等待此元素被填充,而不是命中数据库(外部使用singleflight封装一下)。
参考文章
https://zhuanlan.zhihu.com/p/352910565 https://cloud.tencent.com/developer/article/1676115 https://tech.meituan.com/2017/03/17/cache-about.html https://www.cnblogs.com/vancasola/p/9951686.html
总结
真正想设计一个高性能的本地缓存还是挺不容易的,由于我也才疏学浅,本文的设计思想也是个人实践想法,欢迎大家提出宝贵意见,我们一起做出来一个真正的高性能本地缓存。
下篇文章我将分享自己的写的一个本地缓存,尽请期待!!!
好啦,本文到这里就结束了,我是asong,我们下期见。创建了读者交流群,欢迎各位大佬们踊跃入群,一起学习交流。入群方式:关注公众号获取。更多学习资料请到公众号领取。