
宅男福利!我50行Python代码让小姐姐给你读Pdf
最近小编忙着给项目做文档,需要阅读大量的文献资料,长时间的阅读让本就不喜欢看书的我是又困又乏,所以想着,要是能有小姐姐在旁边读给我听该有多好。
说干就干,小编整理了一下思路,晚上熬夜花了几个小时就完成了整个小程序,一起来跟小编学习一下吧。
代码的构思
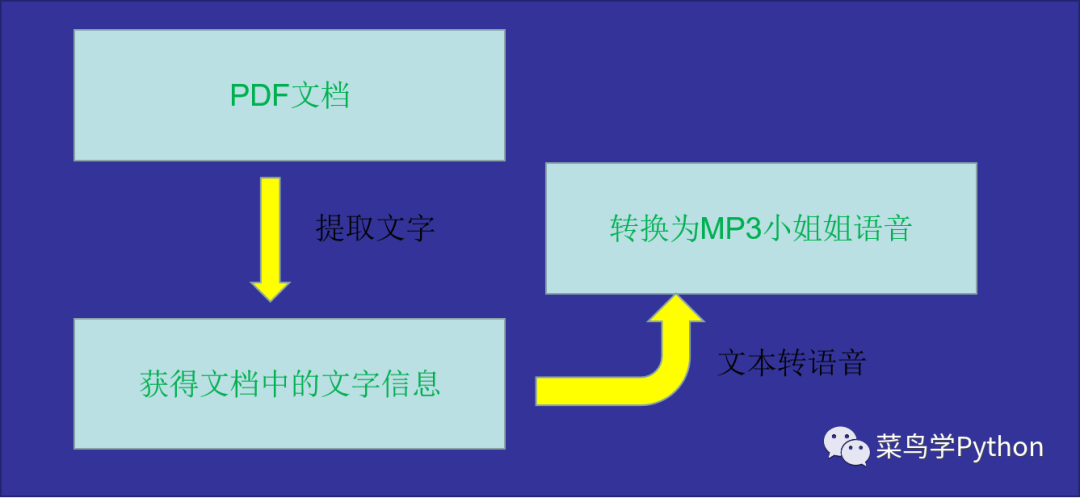
上图中,我们首先需要实现的是将PDF文章中,我们想要提取的文字提取出来,然后再将提取的文本内容,通过小姐姐文本朗读转化为MP3文件,保存到本地当中。明确思路之后,接下来我们就来看一下程序是如何实现的吧。
文字提取
但是需要注意版本的使用,这里我们使用的python3.5环境下的版本号为0.5.25的pdfplumber。对于文本的提取,其程序如下所示:
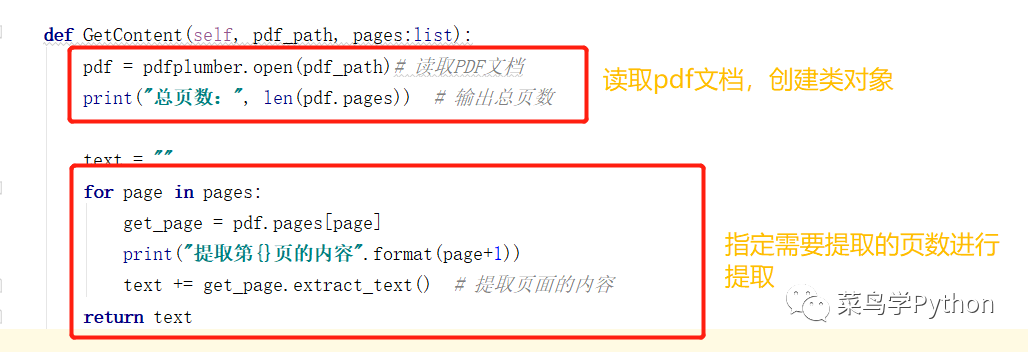
上述的程序中,我们首先打开pdf文件,并返回一个pdf的类对象,然后根据指定的pages数据,来提取指定页码的文本信息。我们来运行一下程序,看一下提取的结果如何吧。

上述的红框中,左侧的是程序提取的结果,而右侧是PDF的文本,通过提取的结果来看,pdfplumber能够准确的提取出PDF中的文本信息。
文本转语音
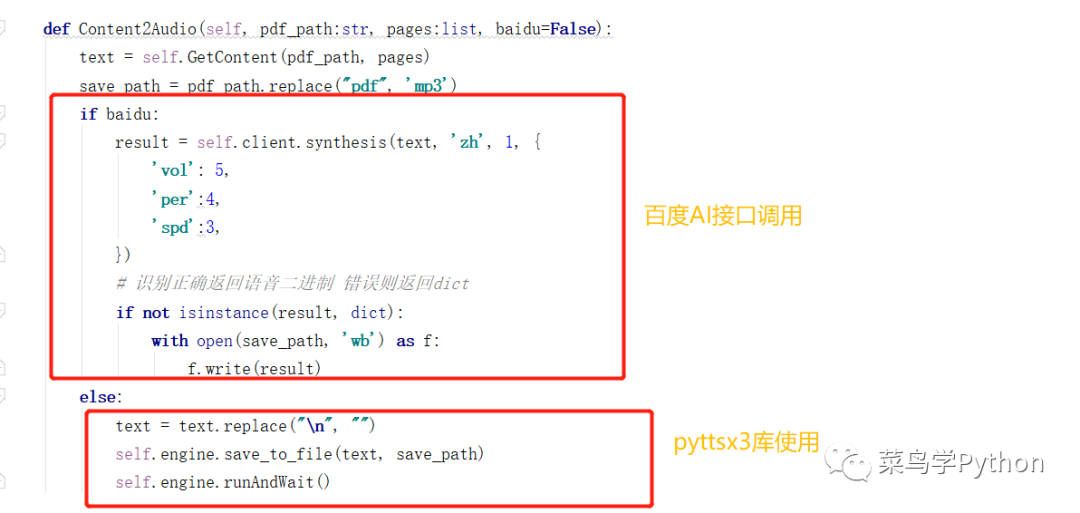
程序首先采用判断的方式,如果形参baidu == True,则采用百度AI,否则就采用pyttsx3库。
对于百度AI的调用,想必大家都非常的熟悉,大家需要到百度的AI开发者平台,进行接口的申请,然后通过申请的信息来进行百度AI接口的调用。
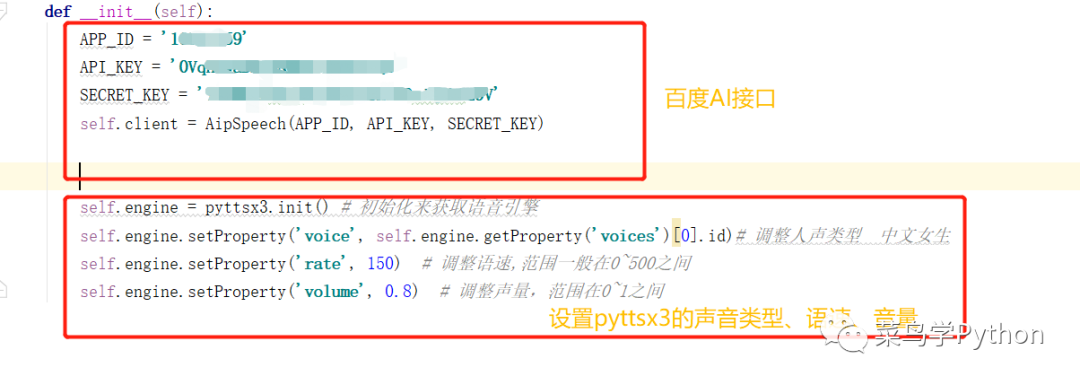
对于pyttsx3库,首先需要初始化语音引擎,然后设置语音的声音类型、语速和音量的信息。就可以进行引擎的调用。
结果展示
以上就是对于程序部分的讲解,下面小编通过视频展示的方式来看一下程序的运行效果。
最后来听一下小姐姐阅读pdf,是什么感觉!有点酥麻!
以上的内容就是小编今天为大家带来的分享,通过这样的处理,小编可以解放双眼,直接”听文档“,大家也赶快下载程序,一起学习起来吧!
需要本篇的源码,后台输入:pdf 也可以添加小助手微信小助手获得技术支持,暗号:pdf
菜鸟小助手
推荐阅读:
这个GitHub 1400星的Git魔法书火了,斯坦福校友出品丨有中文版 贼 TM 好用的 Java 工具类库 超全Python IDE武器库大总结,优缺点一目了然! 秋招来袭!GitHub28.5颗星!这个汇聚阿里,腾讯,百度,美团,头条的面试题库必须安利! 收获10400颗星!这个Python库有点黑科技,竟然可以伪造很多'假'的数据! 牛掰了!这个Python库有点逆天了,竟然能把图片,视频无损清晰放大!
点这里,获取一大波福利

