
那个男人竟然不会Flink的CheckPoint机制
共 12478字,需浏览 25分钟
·
2020-12-15 08:54
三歪第403篇原创文章
作者:三歪
本文已收录至我的GitHub
没错,就是你,鸡蛋?(没事就把认识的都黑一遍,反正鸡蛋去字节了也打不了我)
这里已经是Flink的第三篇原创啦。第一篇《Flink入门教程》讲解了Flink的基础和相关概念,第二篇《背压原理》讲解了什么是背压,在Flink背压大概的流程是怎么样的。
这篇来讲Flink另一个比较重要的知识,就是它的容错机制checkpoint原理。
所谓的CheckPoint其实就是Flink会在指定的时间段上保存状态的信息,如果Flink挂了可以将上一次状态信息再捞出来,重放还没保存的数据来执行计算,最终可以实现exactly once。
状态只持久化一次到最终的存储介质中(本地数据库/HDFS),在Flink下就叫做exactly once(计算的数据可能会重复(无法避免),但状态在存储介质上只会存储一次)。
前排提醒,本文基于Flink 1.7
《浅入浅出学习Flink的checkpoint知识》
开胃菜(复习)
作为用户,我们写好Flink的程序,上管理平台提交,Flink就跑起来了(只要程序代码没有问题),细节对用户都是屏蔽的。
实际上大致的流程是这样的:
Flink会根据我们所写代码,会生成一个StreamGraph的图出来,来代表我们所写程序的拓扑结构。然后在提交的之前会将 StreamGraph这个图优化一把(可以合并的任务进行合并),变成JobGraph将 JobGraph提交给JobManagerJobManager收到之后JobGraph之后会根据JobGraph生成ExecutionGraph(ExecutionGraph是JobGraph的并行化版本)TaskManager接收到任务之后会将ExecutionGraph生成为真正的物理执行图
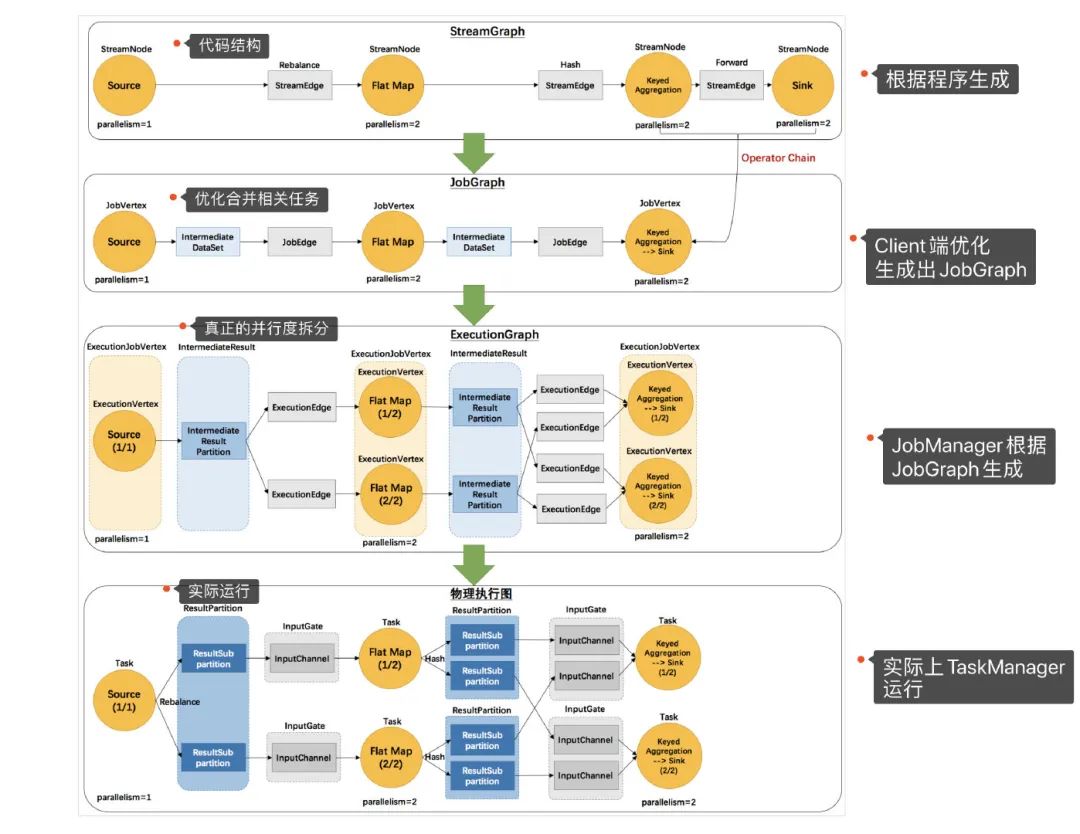
可以看到物理执行图真正运行在TaskManager上Transform和Sink之间都会有ResultPartition和InputGate这俩个组件,ResultPartition用来发送数据,而InputGate用来接收数据。

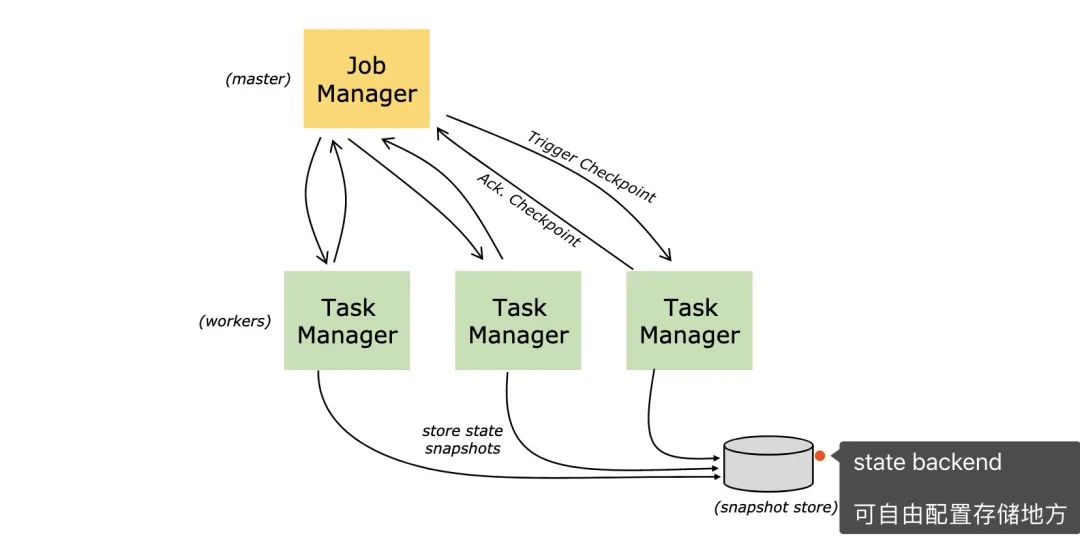
屏蔽掉这些Graph,可以发现Flink的架构是:Client->JobManager->TaskManager
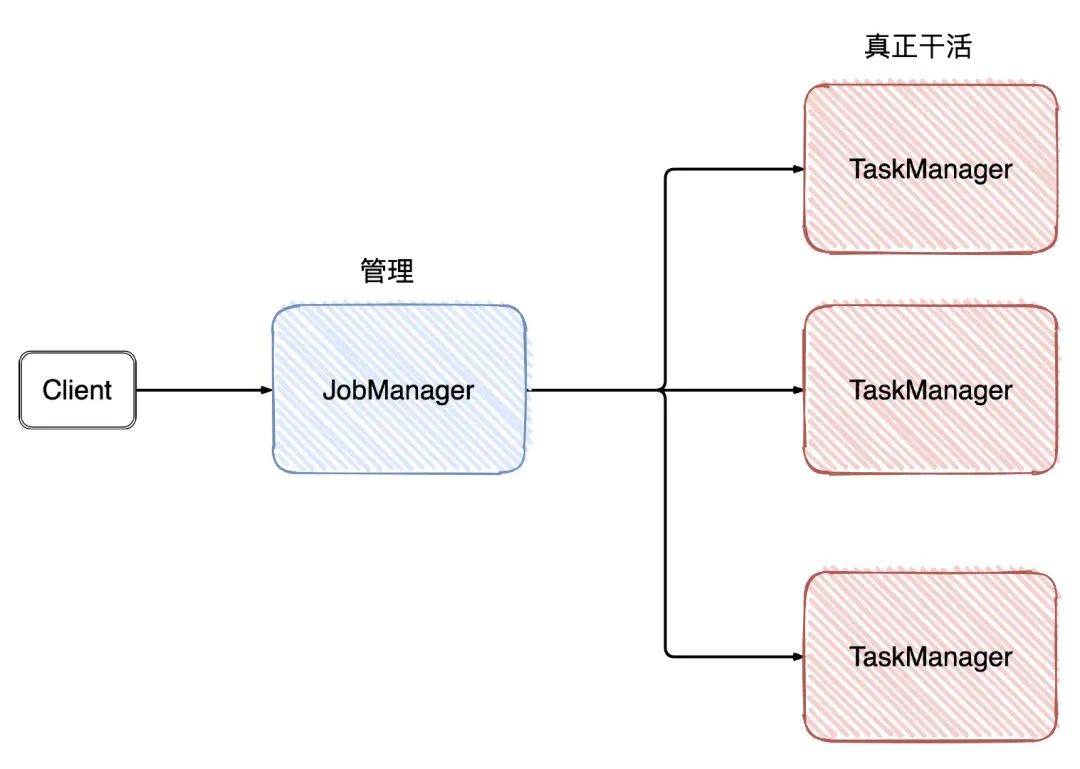
从名字就可以看出,JobManager是干「管理」,而TaskManager是真正干活的。回到我们今天的主题,checkpoint就是由JobManager发出。
Flink本身就是有状态的,Flink可以让你选择执行过程中的数据保存在哪里,目前有三个地方,在Flink的角度称作State Backends:
MemoryStateBackend(内存) FsStateBackend(文件系统,一般是HSFS) RocksDBStateBackend(RocksDB数据库)
同样地,checkpoint信息就是保存在State Backends上
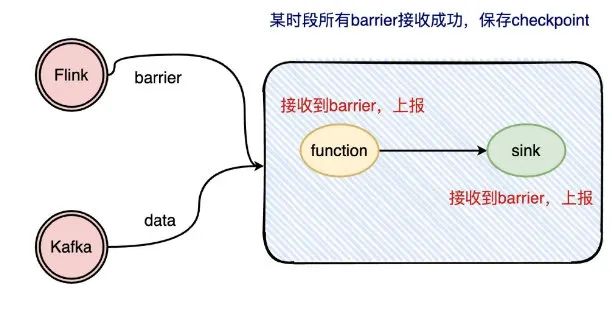
先来简单描述一下checkpoint的实现流程:
checkpoint的实现大致就是插入barrier,每个operator收到barrier就上报给JobManager,等到所有的operator都上报了barrier,那JobManager 就去完成一次checkpointi
因为checkpoint机制是Flink实现容错机制的关键,我们在实际使用中,往往都要配置checkpoint相关的配置,例如有以下的配置:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(60000);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
简单铺垫过后,我们就来撸源码了咯?
Checkpoint(原理)
JobManager发送checkpoint
从上面的图我们可以发现 checkpoint是由JobManager发出的,并且JobManager收到的是JobGraph,会将JobGraph转换成ExecutionGraph。
这块在JobMaster的构造器就能体现出来:
public JobMaster(...) throws Exception {
// 创建ExecutionGraph
this.executionGraph = createAndRestoreExecutionGraph(jobManagerJobMetricGroup);
}
我们点击进去createAndRestoreExecutionGraph看下:
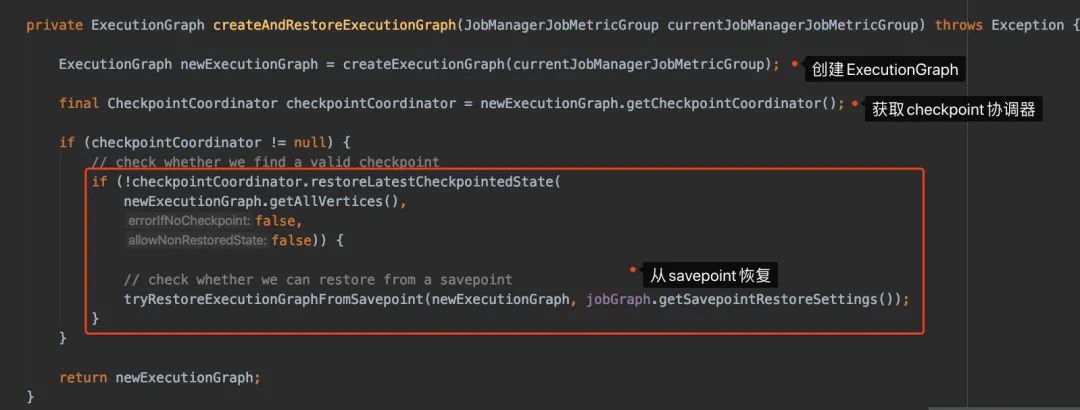
看CheckpointCoordinator这个名字,就觉得他很重要,有木有?它从ExecutionGraph来,我们就进去createExecutionGraph里边看看呗。
点了两层buildGraph()方法,可以看到在方法的末尾处有checkpoint相关的信息:
executionGraph.enableCheckpointing(
chkConfig.getCheckpointInterval(),
chkConfig.getCheckpointTimeout(),
chkConfig.getMinPauseBetweenCheckpoints(),
chkConfig.getMaxConcurrentCheckpoints(),
chkConfig.getCheckpointRetentionPolicy(),
triggerVertices,
ackVertices,
confirmVertices,
hooks,
checkpointIdCounter,
completedCheckpoints,
rootBackend,
checkpointStatsTracker);
前面的几个参数就是我们在配置checkpoint参数的时候指定的,而triggerVertices/confirmVertices/ackVertices我们溯源看了一下,在源码中注释也写得清清楚楚的。
// collect the vertices that receive "trigger checkpoint" messages.
// currently, these are all the sources
List triggerVertices = new ArrayList<>();
// collect the vertices that need to acknowledge the checkpoint
// currently, these are all vertices
List ackVertices = new ArrayList<>(jobVertices.size());
// collect the vertices that receive "commit checkpoint" messages
// currently, these are all vertices
List commitVertices = new ArrayList<>(jobVertices.size());
下面还是进去enableCheckpointing()看看大致做了些什么吧:
// 将上面的入参分别封装成ExecutionVertex数组
ExecutionVertex[] tasksToTrigger = collectExecutionVertices(verticesToTrigger);
ExecutionVertex[] tasksToWaitFor = collectExecutionVertices(verticesToWaitFor);
ExecutionVertex[] tasksToCommitTo = collectExecutionVertices(verticesToCommitTo);
// 创建触发器
checkpointStatsTracker = checkNotNull(statsTracker, "CheckpointStatsTracker");
// 创建checkpoint协调器
checkpointCoordinator = new CheckpointCoordinator(
jobInformation.getJobId(),
interval,
checkpointTimeout,
minPauseBetweenCheckpoints,
maxConcurrentCheckpoints,
retentionPolicy,
tasksToTrigger,
tasksToWaitFor,
tasksToCommitTo,
checkpointIDCounter,
checkpointStore,
checkpointStateBackend,
ioExecutor,
SharedStateRegistry.DEFAULT_FACTORY);
// 设置触发器
checkpointCoordinator.setCheckpointStatsTracker(checkpointStatsTracker);
// 状态变更监听器
// job status changes (running -> on, all other states -> off)
if (interval != Long.MAX_VALUE) {
registerJobStatusListener(checkpointCoordinator.createActivatorDeactivator());
}
值得一提的是,点进去CheckpointCoordinator()构造方法可以发现有状态后端StateBackend的身影(因为checkpoint就是保存在所配置的状态后端)
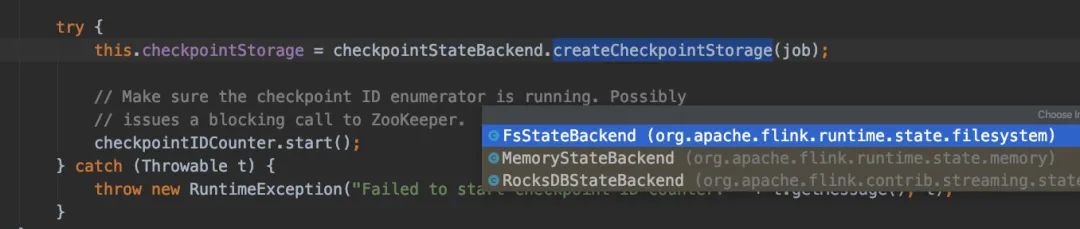
如果Job的状态变更了,CheckpointCoordinatorDeActivator是能监听到的。
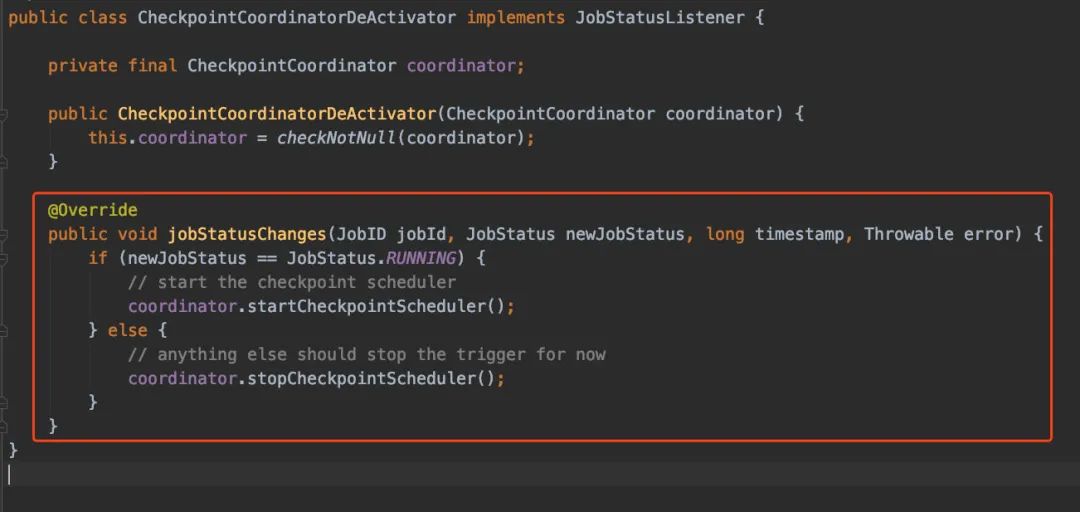
当我们的Job启动的时候,又简单看看startCheckpointScheduler()里边究竟做了些什么操作:
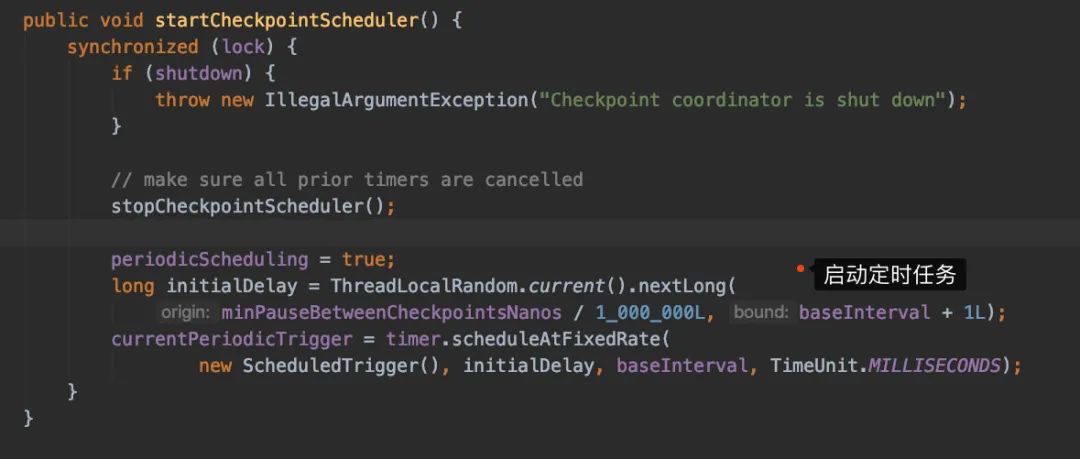
它会启动一个定时任务,我们具体看看定时任务具体做了些什么ScheduledTrigger,然后看到比较重要的方法:triggerCheckpoint()
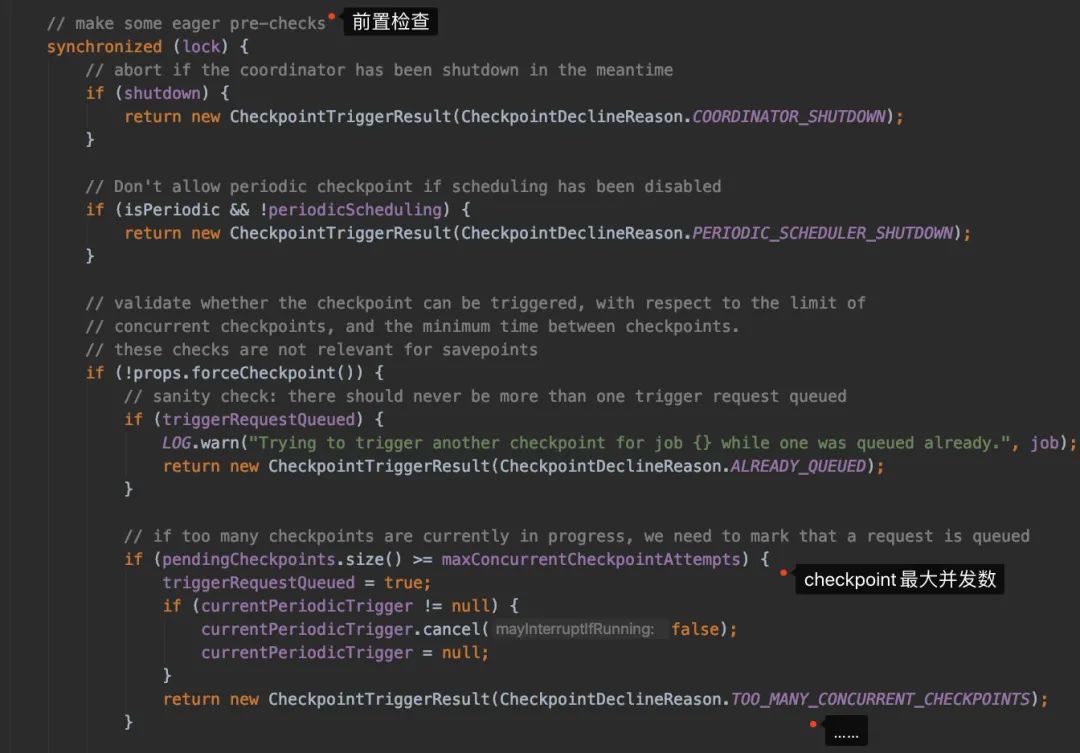
这块代码的逻辑有点多,我们简单来总结一下
前置检查(是否可以触发 checkpoint,距离上一次checkpoint的间隔时间是否符合...)检查是否所有的需要做 checkpoint的Task都处于running状态生成 checkpointId,然后生成PendingCheckpoint对象来代表待处理的检查点注册一个定时任务,如果 checkpoint超时后取消checkpoint
注:检查task的任务状态时,只会把source的task封装给进Execution[]数组
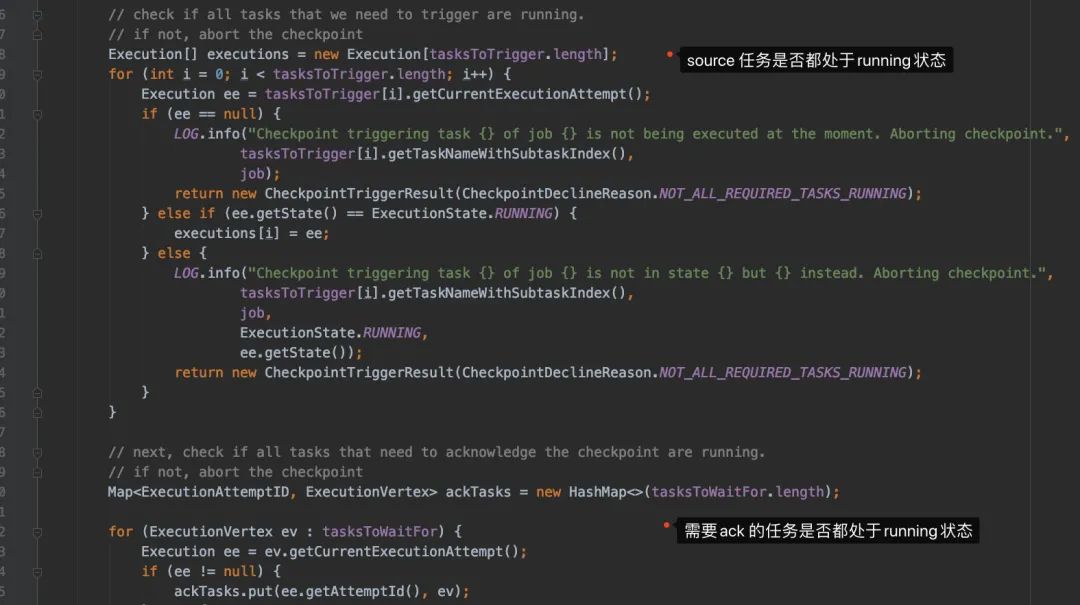

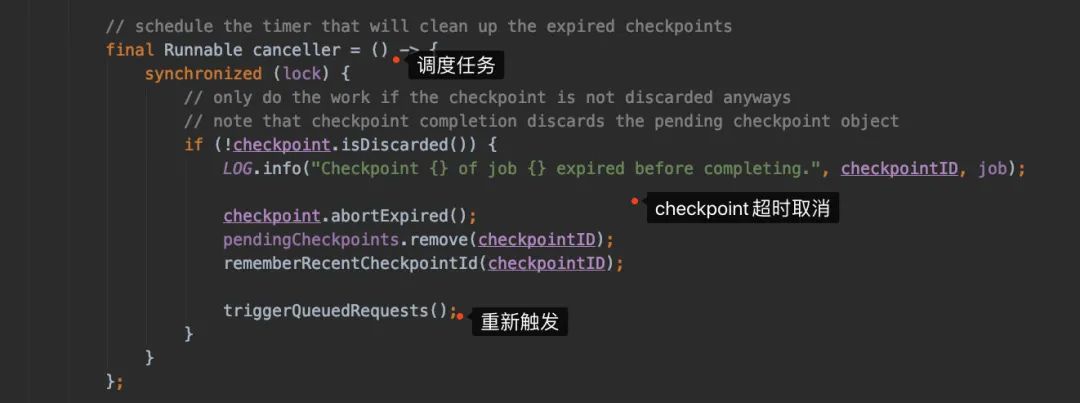

JobManager侧只会发给source的task发送checkpoint
JobManager发送总结
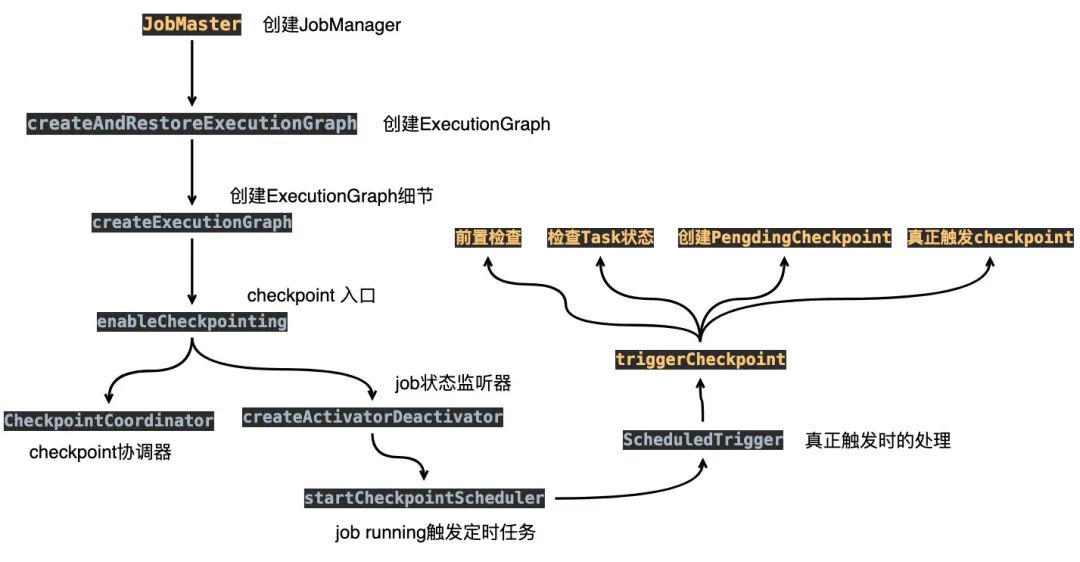
贴的图有点多,最后再来简单总结一波,顺便画个流程图,你就会发现还是比较清晰的。
JobManager收到client提交的JobGraphJobManger需要通过JobGraph生成ExecutionGraph在生成 ExcutionGraph的过程中实际上就会触发checkpoint的逻辑定时任务会前置检查(其实就是你实际上配置的各种参数是否符合) 判断 checkpoint相关的task是否都是running状态,将source的任务封装到Execution数组中创建 checkpointID/checkpointStorageLocation(checkpoint保存的地方)/PendingCheckpoint(待处理的checkpoint)创建定时任务(如果当 checkpoint超时,会将相关状态清除,重新触发)真正触发 checkPoint给TaskManager(只会发给source的task)找出所有 source和需要ack的Task创建 checkpointCoordinator协调器创建 CheckpointCoordinatorDeActivator监听器,监听Job状态的变更当 Job启动时,会触发ScheduledTrigger定时任务

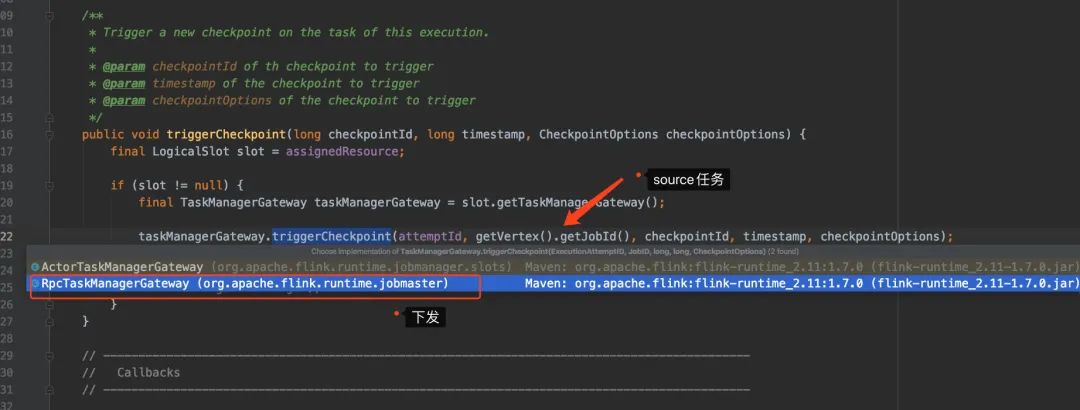
TaskManager(source Task接收)
前面提到了,JobManager 在生成ExcutionGraph时,会给所有的source 任务发送checkpoint,那么source收到barrier又是怎么处理的呢?会到TaskExecutor这里进行处理。
TaskExecutor有个triggerCheckpoint()方法对接收到的checkpoint进行处理:
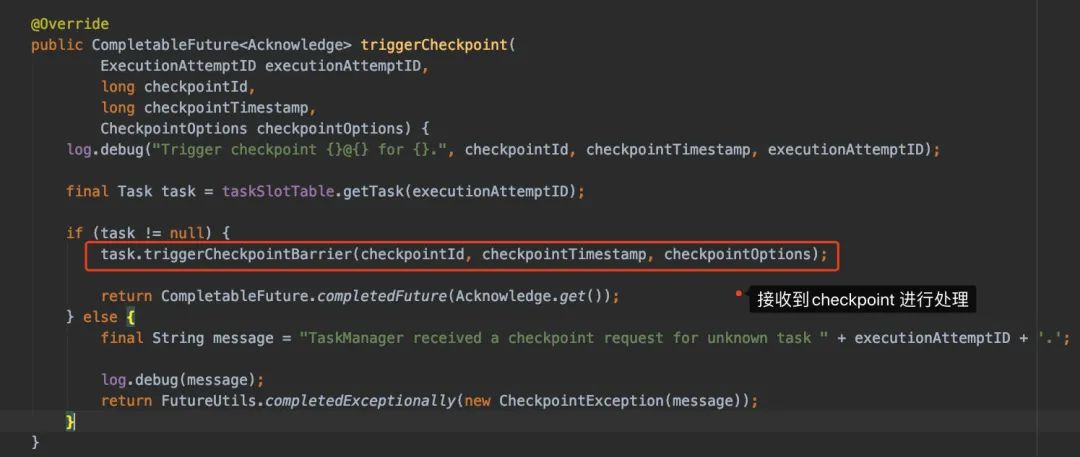
进入triggerCheckpointBarrier()看看:
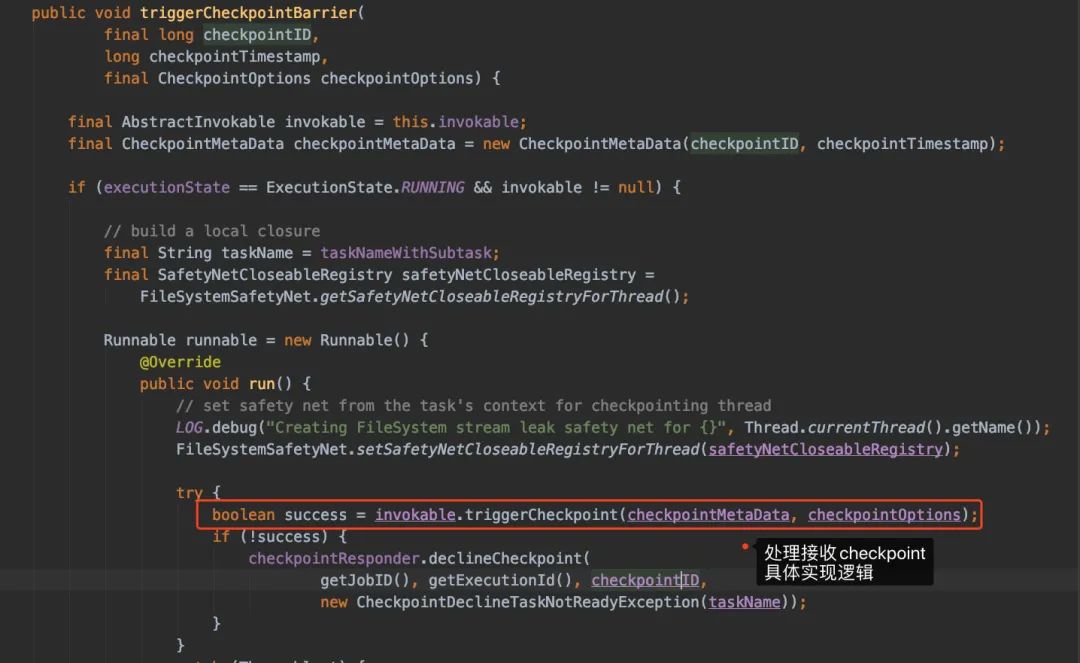
再想点进去triggerCheckpoint()看实现时,我们会发现走到performCheckpoint()这个方法上:
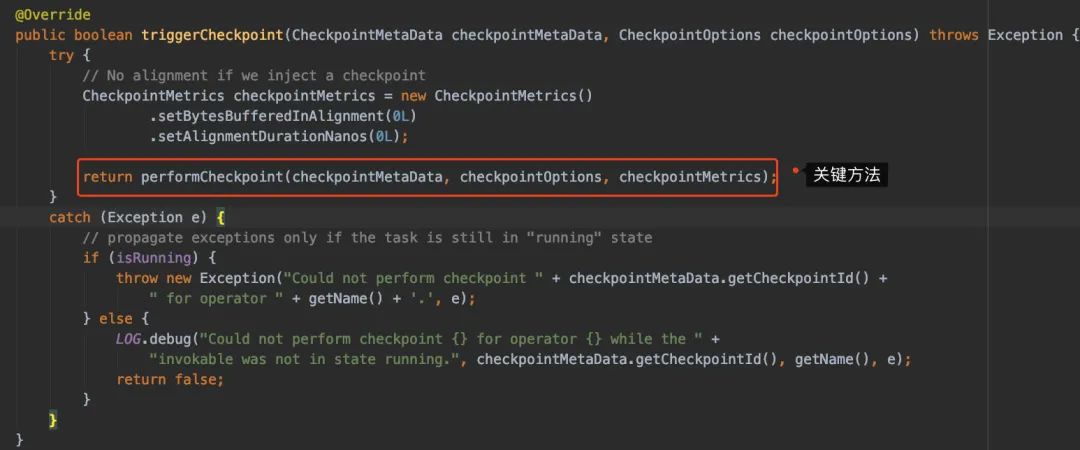
从实现的注释我们可以很方便看出方法大概做了什么:
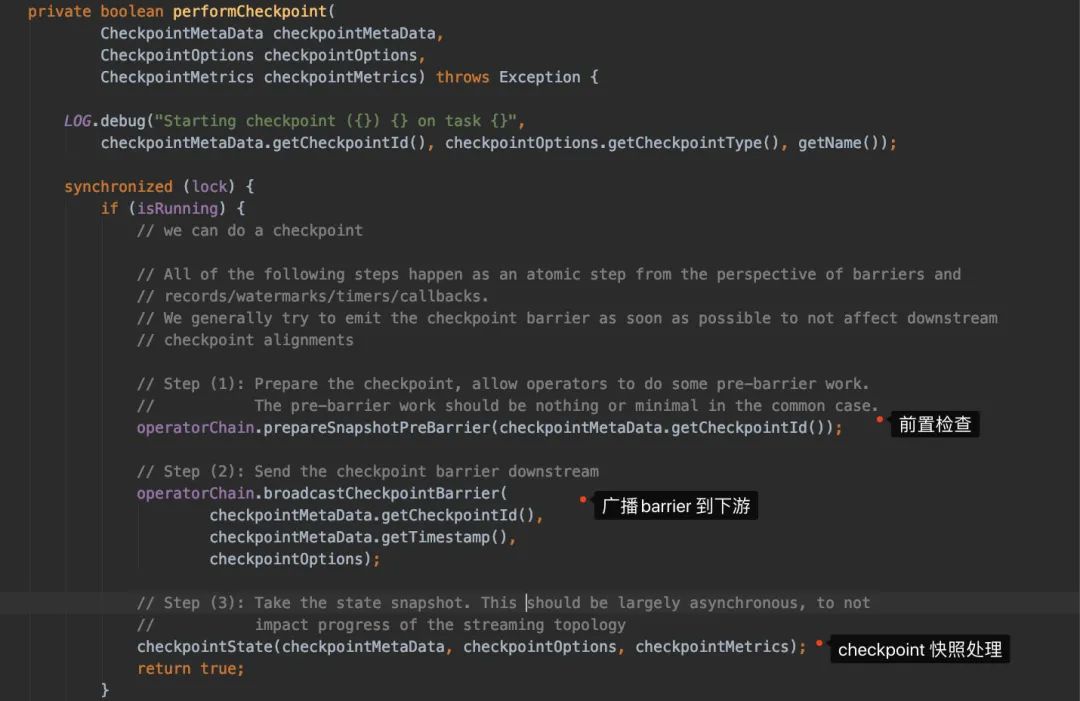
这块我们先在这里放着,知道Source的任务接收到Checkpoint会广播到下游,然后会做快照处理就好。
下面看看非Source 的任务接收到checkpoint是怎么处理的。
TaskManager(非source Task接收)
在上一篇《背压原理》又或是这篇的基础铺垫上,其实我们可以看到在Flink接收数据用的是InputGate,所以我们还是回到org.apache.flink.streaming.runtime.io.StreamInputProcessor#processInput这个方法上
随后定位到处理数据的逻辑:
final BufferOrEvent bufferOrEvent = barrierHandler.getNextNonBlocked();
想点击进去,发现有两个实现类:
BarrierBufferBarrierTracker

这两个实现类其实就是对应着AT_LEAST_ONCE 和EXACTLY_ONCE这两种模式。
/**
* The BarrierTracker keeps track of what checkpoint barriers have been received from
* which input channels. Once it has observed all checkpoint barriers for a checkpoint ID,
* it notifies its listener of a completed checkpoint.
*
* Unlike the {@link BarrierBuffer}, the BarrierTracker does not block the input
* channels that have sent barriers, so it cannot be used to gain "exactly-once" processing
* guarantees. It can, however, be used to gain "at least once" processing guarantees.
*
*
NOTE: This implementation strictly assumes that newer checkpoints have higher checkpoint IDs.
*/
/**
* The barrier buffer is {@link CheckpointBarrierHandler} that blocks inputs with barriers until
* all inputs have received the barrier for a given checkpoint.
*
* To avoid back-pressuring the input streams (which may cause distributed deadlocks), the
* BarrierBuffer continues receiving buffers from the blocked channels and stores them internally until
* the blocks are released.
*/
简单翻译下就是:
BarrierTracker是at least once模式,只要inputChannel接收到barrier,就直接通知完成处理checkpointBarrierBuffer是exactly-once模式,当所有的inputChannel接收到barrier才通知完成处理checkpoint,如果有的inputChannel还没接收到barrier,那已接收到barrier的inputChannel会读数据到缓存中,直到所有的inputChannel都接收到barrier,这有可能会造成反压。
说白了,就是BarrierBuffer会有对齐barrier的处理。
这里又提到exactly-once和at least once了。在文章开头也说过Flink是可以实现exactly-once的,含义就是:状态只持久化一次到最终的存储介质中(本地数据库/HDFS)。
在这里我还是画个图和举个例子配合BarrierBuffer/BarrierTracker来解释一下。
现在我有一个Topic,假定这个Topic有两个分区partition(又或者你可以理解我设置消费的并行度是2)。现在要拉取Kafka这两个分区的数据,由算子Map进行消费转换,期间在转化的时候可能会存储些信息到State(Flink给我们提供的存储,你就当做是会存到HDFS上就好了),最终输出到Sink。
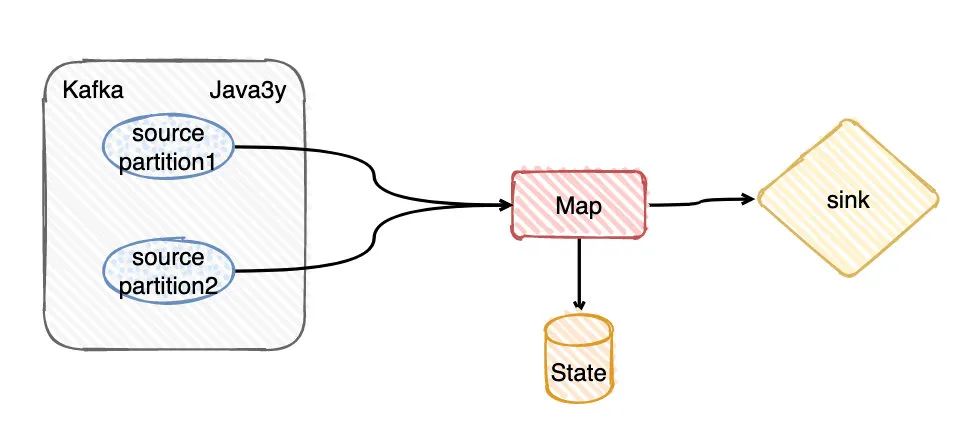
从上面的知识点我们应该可以知道, 在Flink做checkpoint的时候JobManager往每个Source任务(简单对应图上的两个paritiion) 发送checkpointId,然后做快照存储。
显然,source任务存储最主要的内容就是消费分区的offset嘛。比如现在source 1的offerset是100,而source2的offset是105。
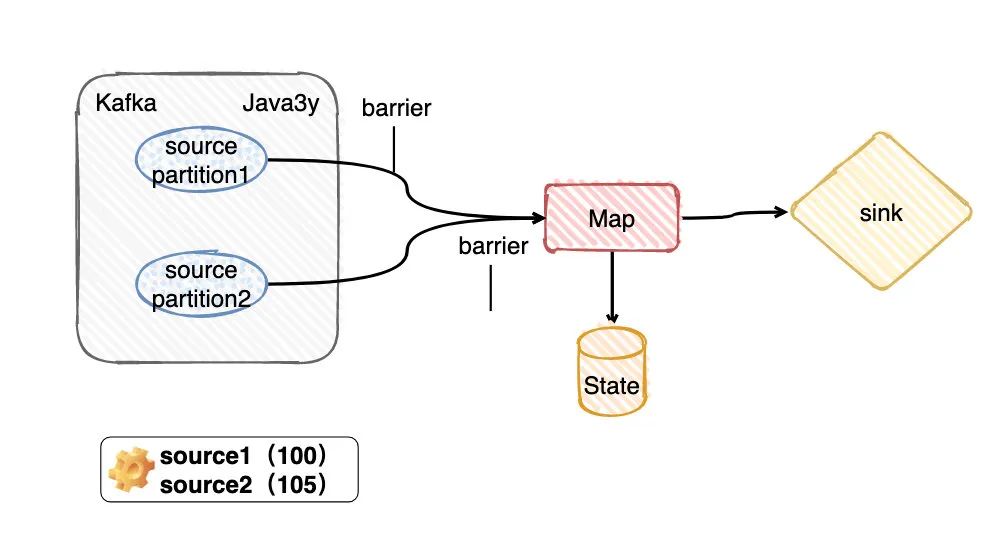
目前看来source2的数据会比source1的数据先到达Map
假定我们用的是BarrierBuffer exactly-once模式,那么source2的barrier到达Map算子的后,source2之后的数据只能停下来,放到buffer上,不做处理。等source1 的barrier来了以后,再真正处理source2放在buffer的数据。
这就是所谓的barrier对齐
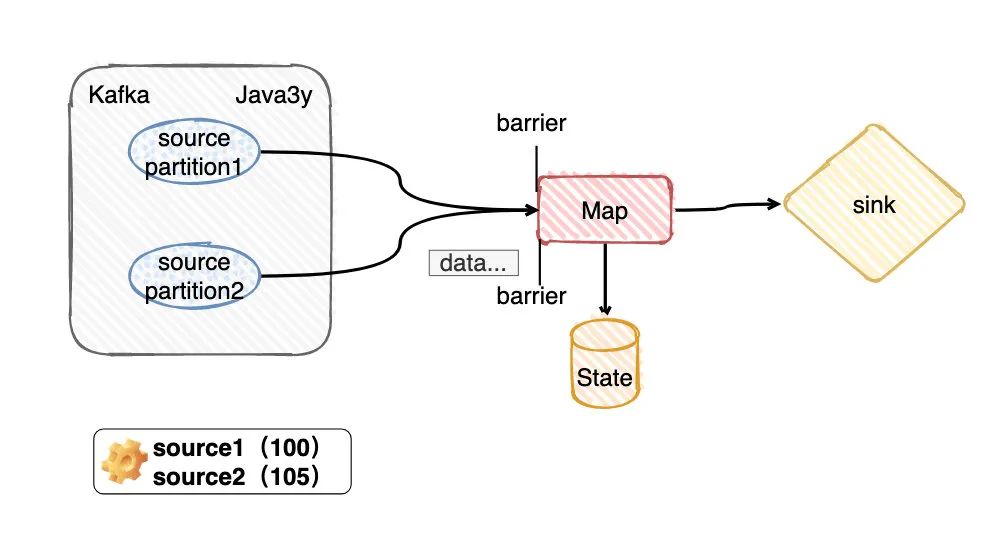
假定我们用的是BarrierTracker at least once模式,那么source2的barrier到达Map算子的后,source2之后的数据不会停下来等待source1,后面的数据会继续处理。
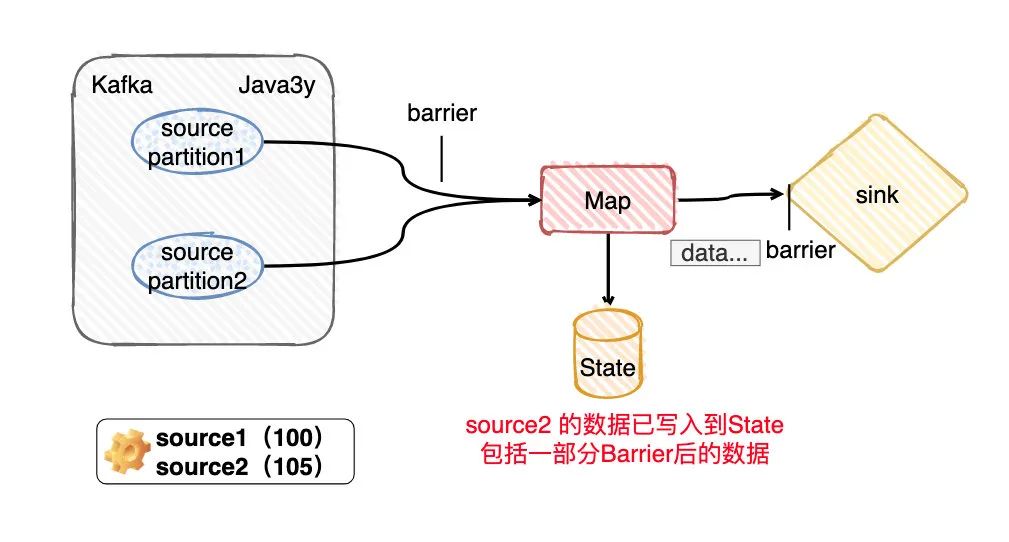
现在问题就来了,那对不对齐的区别是什么呢?
依照上面图的的运行状态(无论是BarrierTracker at least once模式还是BarrierBuffer exactly-once模式),现在我们的checkpoint都没做,因为source1的barrier还没到sink端呢。现在Flink挂了,那显然会重新拉取source 1的offerset是小于100,而source2的offset是小于105的数据,State的最终信息也不会保存。
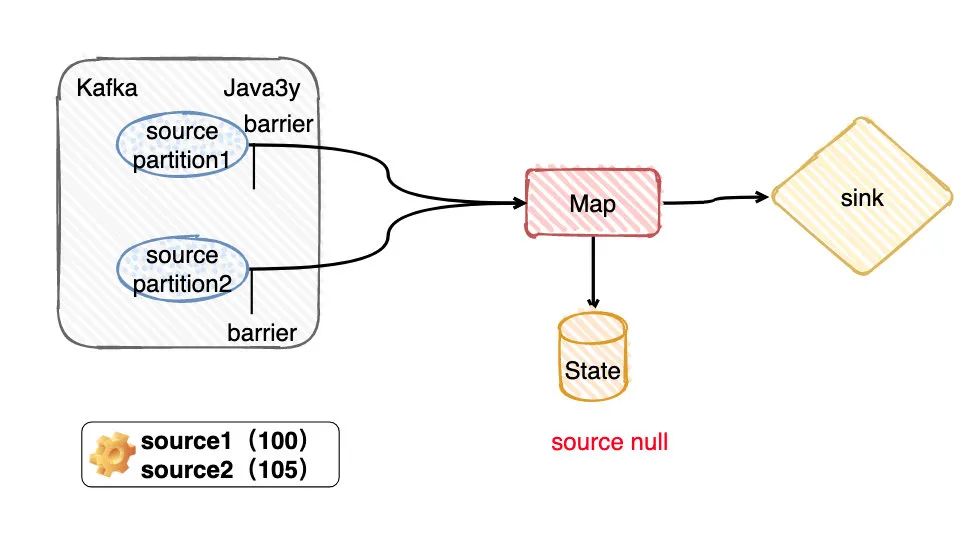
checkpoint从没做过的时候,对数据不会产生任何的影响(所以这里在Flink的内部是没啥区别的)
而假设我们现在是BarrierTracker at least once模式,没有任何问题,程序继续执行。现在source1的barrier也走到了slink,最后完成了一次checkpoint。
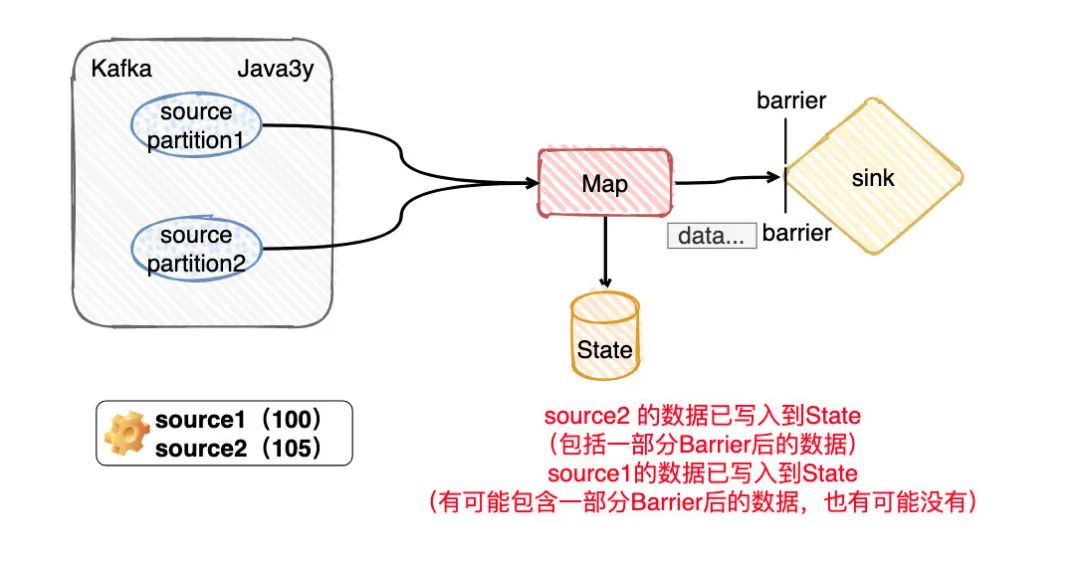
由于source2的barrier比source1的barrier要快,那么source1所处理的State的数据实际是包括offset>105的数据的,自然Flink保存的时候也会把这部分保存进去。
程序继续运行,刚好保存完checkpoint后,此时系统出了问题,挂了。因为checkpoint已经做完了,所以Flink会从source 1的offerset是100,而source2的offset是105重新消费。
但是,由于我们是BarrierTracker at least once模式,所以State里边的保存状态实际上有过source2的offset 大于105 的记录了。那source2重新从offset是105开始消费,那就是会重复消费!

理解了上面所讲的话,那再看BarrierBuffer exactly-once模式应该就不难理解了(各位大哥大嫂你也要经过这个operator处理保存吗?我们一起吧?有问题,我们一起重来,没问题我们一起保存)

无论是BarrierTracker还是BarrierBuffer也好,在处理checkpoint的时候都需要调用notifyCheckpoint() 方法,而notifyCheckpoint()方法最终调用的是triggerCheckpointOnBarrier
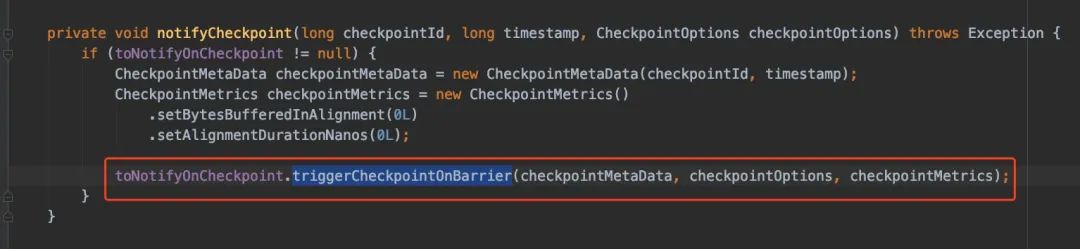
triggerCheckpointOnBarrier()最终还是会调用performCheckpoint()方法,所以无论是source接收到checkpoint还是operator接收到checkpoint,最终还是会调用performCheckpoint()方法。
大家有兴趣可以进去checkpointState()方法里边详细看看,里边会对State状态信息进行写入,完成后上报给TaskManager

TaskManager总结
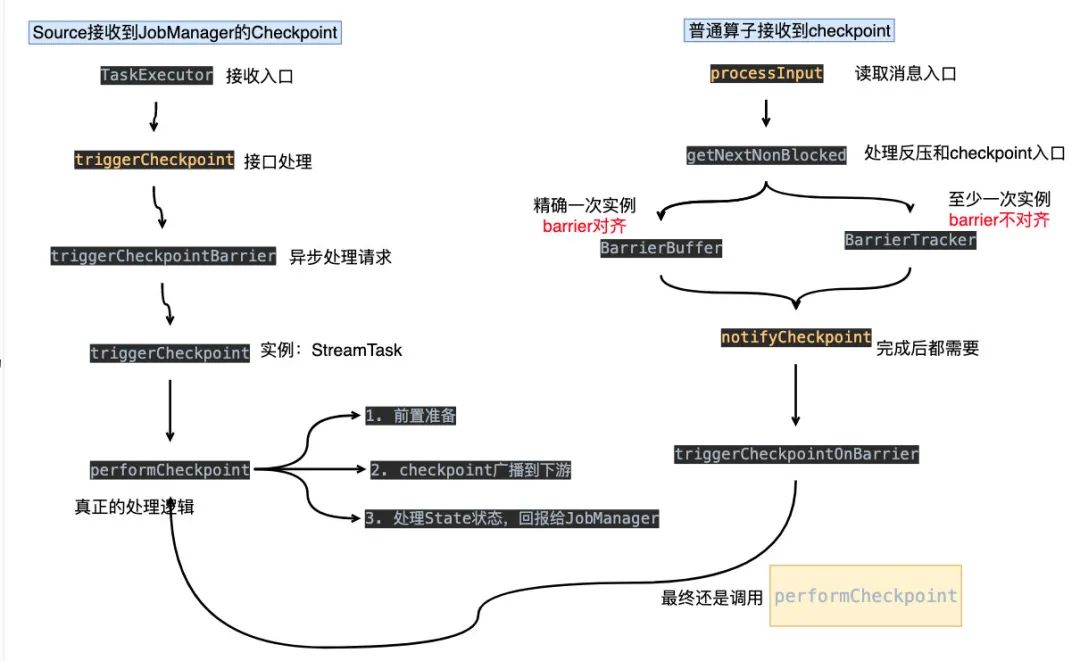
TaskExecutor接收到JobManager下发的checkpoint,由triggerCheckpoint方法进行处理triggerCheckpoint方法最终会调用org.apache.flink.streaming.runtime.tasks.StreamTask#triggerCheckpoint,而最主要的就是performCheckpoint方法performCheckpoint方法会对checkpoint做前置处理,barrier广播到下游,处理State状态做快照,最后回到成功消息给JobManager普通算子由 org.apache.flink.streaming.runtime.io.StreamInputProcessor#processInput这个方法读取数据,具体处理逻辑在getNextNonBlocked方法上。该方法有两个实例,分别是 BarrierBuffer和BarrierTracker,这两个实例对应着checkpoint不同的模式(至少一次和精确一次)。精确一次需要对barrier对齐,有可能导致反压的情况最后处理完,会调用 notifyCheckpoint方法,实际上还是会调performCheckpoint方法
所以说,最终处理checkpoint的逻辑是一致的,只是会source会直接通过TaskExecutor处理,而普通算子会根据不同的配置在接收到后有不同的实例处理:BarrierTracker/BarrierBuffer。
JobManager接收回应
前面提到了,无论是source还是普通算子,都会调用performCheckpoint方法进行处理。
performCheckpoint方法里边处理完State快照的逻辑,会调用reportCompletedSnapshotStates告诉JobManager快照已经处理完了。
reportCompletedSnapshotStates方法里边又会调用acknowledgeCheckpoint方法通过RPC去通知JobManager

兜兜转转,最后还是会回到checkpointCoordinator上,调用receiveAcknowledgeMessage进行处理
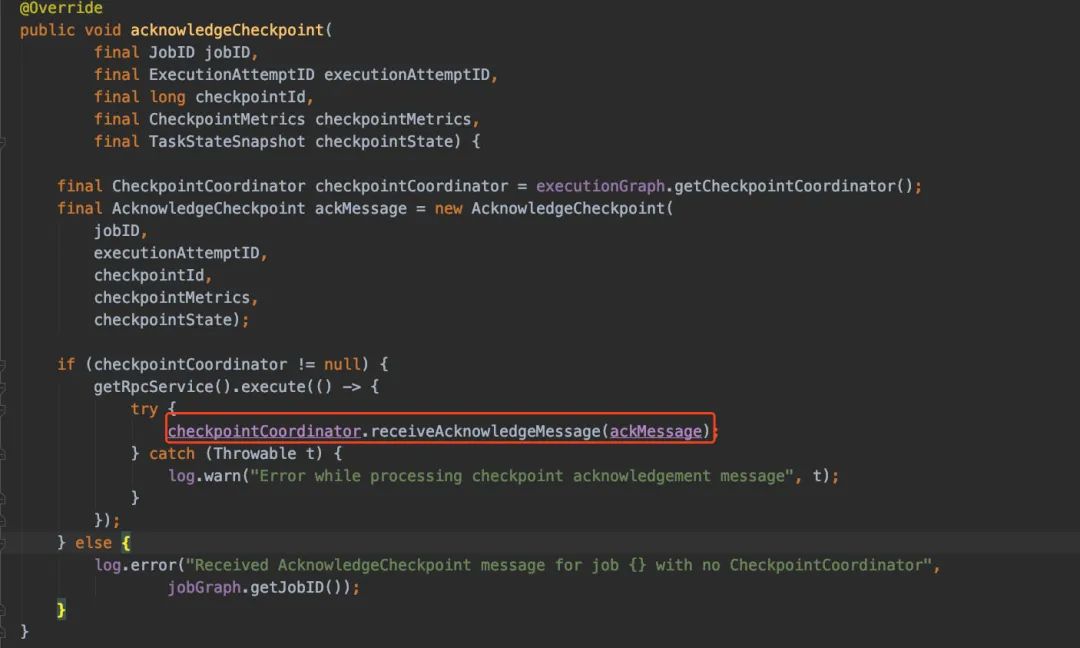
进入到receiveAcknowledgeMessage上,主要就是下面图的逻辑:处理完返回不同的状态,根据不同的状态进行处理
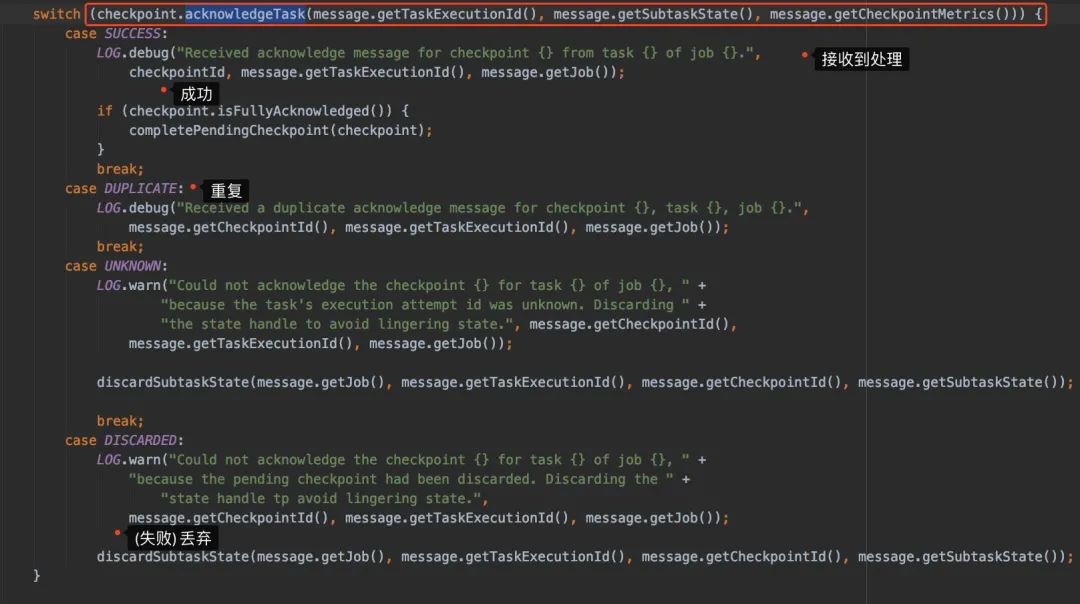
主要我们看的其实就是acknowledgeTask方法里边做了些什么。
在 PendingCheckpoint维护了两个Map:
// 已经接收到 Ack 的算子的状态句柄
private final Map operatorStates;
// 需要 Ack 但还没有接收到的 Task
private final Map notYetAcknowledgedTasks;
然后我们进去acknowledgeTask简单了解一下可以发现就是在处理operatorStates和notYetAcknowledgedTasks
synchronized (lock) {
if (discarded) {
return TaskAcknowledgeResult.DISCARDED;
}
// 接收到Task了,从notYetAcknowledgedTasks移除
final ExecutionVertex vertex = notYetAcknowledgedTasks.remove(executionAttemptId);
if (vertex == null) {
if (acknowledgedTasks.contains(executionAttemptId)) {
return TaskAcknowledgeResult.DUPLICATE;
} else {
return TaskAcknowledgeResult.UNKNOWN;
}
} else {
acknowledgedTasks.add(executionAttemptId);
}
// ...
if (operatorSubtaskStates != null) {
for (OperatorID operatorID : operatorIDs) {
// ...
OperatorState operatorState = operatorStates.get(operatorID);
// 新来的operatorID,添加到operatorStates
if (operatorState == null) {
operatorState = new OperatorState(
operatorID,
vertex.getTotalNumberOfParallelSubtasks(),
vertex.getMaxParallelism());
operatorStates.put(operatorID, operatorState);
}
//....
}
}
等到所有的Task都到齐以后,就会调用isFullyAcknowledged进行处理。

最后调用completedCheckpoint = pendingCheckpoint.finalizeCheckpoint();来实现最终的存储,所有完毕以后会通知所有的Task 现在checkpoint已经完成了。
最后
总的来说,这篇文章带着大家走马观花撸了下Checkpoint,很多细节我也没去深入,但我认为这篇文章可以让你大概了解到Checkpoint的实现过程。
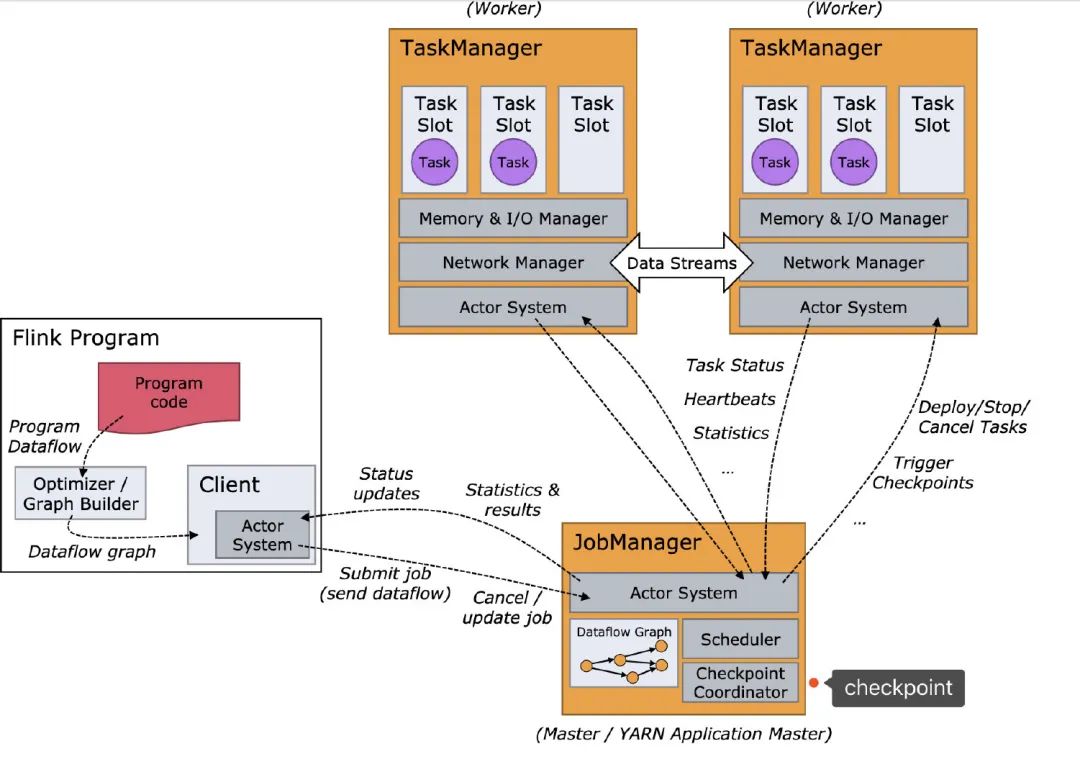
最后再来看看官网的图,看完应该大概就能看得懂啦:
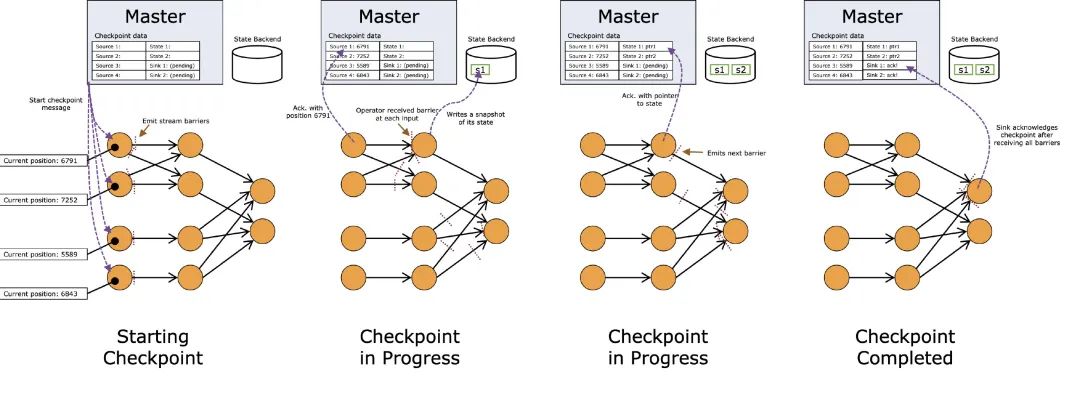
相信我,或许你现在还没用到Flink,但等你真正去用Flink的时候,checkpoint是肯定得搞搞的(:现在可能有的同学还没看懂,没关系,先点个赞?,收藏起来,后面就用得上了。
参考资料:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/concepts/stateful-stream-processing.html https://blog.csdn.net/weixin_40809627/category_9631155.html https://www.jianshu.com/p/4d31d6cddc99 https://www.jianshu.com/p/d2fb32ba2c9b

原创电子书
原创思维导图
已经有8756个初学者都下载了!
?三歪把【大厂面试知识点】、【简历模板】、【原创文章】
全部整理成电子书,共有1263页!扫码或微信搜 Java3y
回复「888」领取


 |
|


47块半年购买服务器。最近如果要买服务器的同学可以重点关注,错过了就要等一年!别在活动结束后再问我能不能买了哟!