
如何利用AI识别口罩下的人脸?

今天的大街上戴口罩的人越来越多,你可能会想:他们摘了口罩都长什么样呢?至少我们 STRV 机器学习(ML)团队就有这样的疑问。作为一个机器学习团队,我们很快意识到问题比想象中更容易解决。
想知道我们是如何设计出一种可以从人脸图像上移除口罩的 ML 工具的吗?
本文将指导你完成构建深度学习 ML 模型的整个过程——从初始设置、数据收集和选择适当的模型,到训练和微调。
在深入研究之前,我们先来定义任务的性质。我们试图解决的问题可以看作是 图像修复,也就是恢复受损图像或填充缺失部分的过程。下面就是图像修复的例子:输入的图像有一些白色缺失,经过处理这些缺失被补足了。

使用部分卷积进行图像修复的示例
解决完定义的问题后我们再提一点:除了本文之外,我们还准备了一个 GitHub 帐户,其中包含你需要的所有内容实现,以及 Jupyter Notebook“mask2face.ipynb”,你可以在其中运行本文提到的所有内容。只需单击几下,即可训练你自己的神经网络。
接下来,让我们正式开始吧。
如果你想在计算机上执行本文所述的所有步骤,可以从我们的 GitHub(https://github.com/strvcom/strv-ml-mask2face) 克隆此项目。
首先,我们来为 Python 项目准备虚拟环境。你可以使用你喜欢的任何虚拟环境,只要确保从 environment.yml 和 requirements.txt 安装所有必需的依赖项即可。不熟悉虚拟环境或 Conda 的话可以参考这篇文章 (https://towardsdatascience.com/a-guide-to-conda-environments-bc6180fc533)。如果你熟悉 Conda,还可以在克隆的 GitHub 项目目录中运行以下命令来初始化 Conda 环境:
conda env create -f environment.yml
conda activate mask2face
现在,你已经有了一个带有所有必需依赖项的环境,接下来我们来定义目标和目的。对于这个项目,我们想要创建一个 ML 模型,该模型可以向我们展示戴口罩的人摘下口罩的样子。我们的模型有一个输入——戴口罩的人的图像;一个输出——摘下口罩的人的图像。
下图很好地展示了整个项目的高层管道。
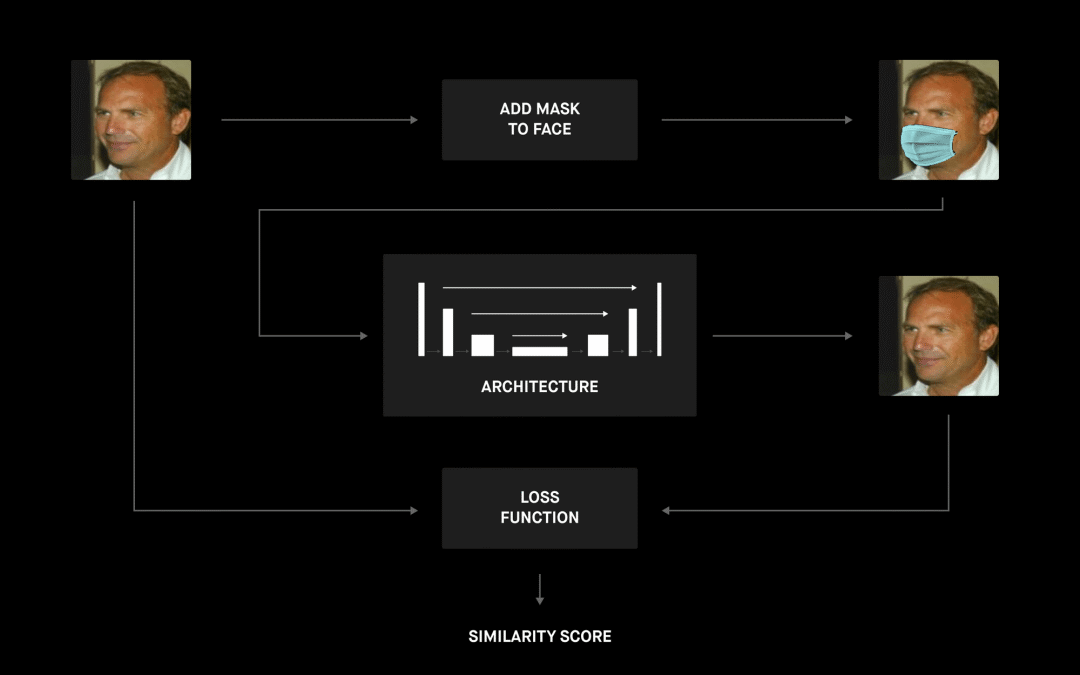
我们从一个带有预先计算的面部界标的面部数据集开始,该数据集是通过口罩生成器处理的,它使用这些界标将口罩放在脸上。现在我们有了带有成对图像(戴和不戴口罩)的数据集,我们就可以继续定义 ML 模型的架构了。管道的最后一部分是找到最佳损失函数和组成各个部分的所有必要脚本,以便我们可以训练和评估模型。
要想训练这个深度学习模型,我们需要采用大量数据,也就是大量输入和输出的图像对。当然,要收集每个人戴口罩 / 不戴口罩的输入和输出图像是不切实际的。
当前,市面上有很多人脸图像数据集,主要用于训练人脸检测算法。我们可以采用这样的数据集,在人脸上绘制口罩——于是我们就有了图像对。

我们尝试了两个数据集。其中一个数据库是马萨诸塞大学[1] 的现实世界人脸标记数据集 (http://vis-www.cs.umass.edu/lfw/)。这里是它的 104MB gzip 压缩 tar 文件 (http://vis-www.cs.umass.edu/lfw/lfw-deepfunneled.tgz),其中包含整个数据集,超过 5,000 张图片。这个数据集非常适合我们的情况,因为它包含的图像主要都是人脸。但对于最终结果,我们使用了 CelebA 数据集 (http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html),它更大(200,000 个样本),并且包含更高质量的图像。
接下来,我们需要定位面部界标,以便将口罩放置在正确的位置。为此,我们使用了一个预训练的 dlib 面部界标检测器。你可以使用其他任何类似的数据集,只要确保你可以找到预计算的面部界标点(可参考这个 GitHub 存储库 (https://github.com/LynnHo/Facial-Landmarks-of-Face-Datasets))或自己计算界标。
一开始,我们做了一个口罩生成器的简单实现,将一个多边形放置在脸上,使多边形顶点与面部界标的距离随机化。这样我们就可以快速生成一个简单的数据集,并测试项目背后的想法是否可行。一旦确定它确实有效,我们就开始寻找一种更强大的解决方案,以更好地反映现实场景。
GitHub 上有一个很棒的项目 Mask The Face(https://github.com/aqeelanwar/MaskTheFace),已经解决了口罩生成问题。它从脸部界标点估计口罩位置,估计脸部倾斜角度以从数据库中选择最合适的口罩,最后将口罩放置在脸上。可用的口罩数据库包括了手术口罩、有各种颜色和纹理的布口罩、几种呼吸器,甚至是防毒面罩。
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from utils.data_generator import DataGenerator
from utils.configuration import Configuration
# You can update configuration.json to change behavior of the generator
configuration = Configuration()
dg = DataGenerator(configuration)
# Generate images
dg.generate_images()
# Plot a few examples of image pairs
n_examples = 5
inputs, outputs = dg.get_dataset_examples(n_examples)
f, axarr = plt.subplots(2, n_examples, figsize=(20,10))
for i in range(len(inputs)):
axarr[1, i].imshow(mpimg.imread(inputs[i]))
axarr[0, i].imshow(mpimg.imread(outputs[i]
现在我们已经准备好了数据集,是时候搭建深度神经网络模型架构了。在这项工作中,绝对没有人可以声称有一个客观的“最佳”选项。
选择合适架构的过程总是取决于许多因素,例如时间要求(你要实时处理视频还是要离线预处理一批图像?)、硬件需求(模型应在搭载高性能 GPU 的群集上运行,还是要在低功耗移动设备上运行?)等等。每次你都要寻找正确的参数,并针对你的具体情况进行设置。
如果你想进一步了解这个问题,可以参考这个 KDnuggets 帖子 (https://www.kdnuggets.com/2019/09/no-free-lunch-data-science.html) 或这篇学术文章 (http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.390.9412&rep=rep1&type=pdf)。
卷积神经网络(CNN)是一种利用卷积核过滤器的神经网络架构。它适用于各种问题,例如时间序列分析、自然语言处理和推荐系统,但主要用于各种图像相关的用途,例如对象分类、图像分割、图像分析和图像修复。
CNN 的核心是能够检测输入图像视觉特征的卷积层。当我们一层层堆叠多个卷积层时,它们倾向于检测不同的特征。第一层通常会提取更复杂的特征,例如边角或边缘。当你深入 CNN 时,卷积层将开始检测更高级的特征,例如对象、面部等。
有关 CNN 的详细说明,请参阅这篇 TechTalks 文章 (https://bdtechtalks.com/2020/01/06/convolutional-neural-networks-cnn-convnets/) 或这些斯坦福笔记 (https://cs231n.github.io/convolutional-networks/)。
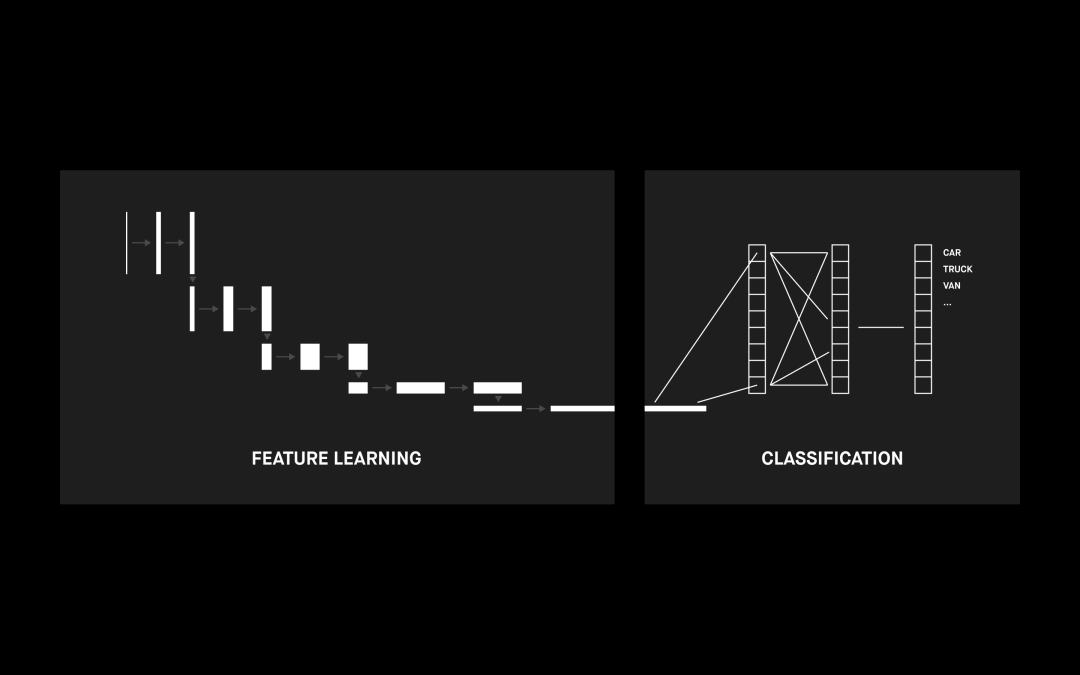
CNN 架构示例
上图显示了用于图像检测的 CNN 示例。这并不是我们要解决的问题,但 CNN 架构是任何修复架构的必要组成部分。
在讨论修复架构之前,我们先来谈谈起作用的构建块,它们称为 ResNet 块或残差块。在传统的神经网络或 CNN 中,每一层都连接到下一层。在具有残差块的网络中,每一层也会连接到下一层,但还会再连接两层或更多层。我们引入了 ResNet 块以进一步提高性能,后文会具体介绍。
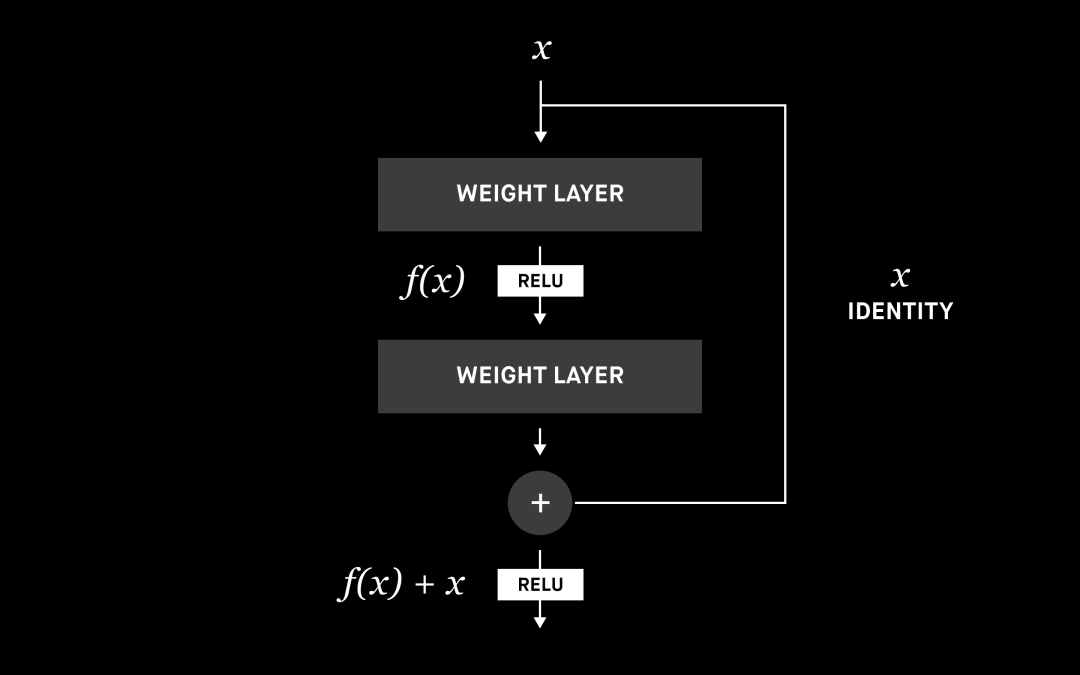
ResNet 构建块 [7]
神经网络能够估计任何函数,我们可以认为增加层数可以提高估计的准确性。但由于诸如梯度消失或维数诅咒之类的问题,层数增加到一定程度就不会继续提升性能了,甚至会让性能倒退。这就是为什么有很多研究致力于解决这些问题,而性能最好的解决方案之一就是残差块。
残差块允许使用跳过连接或标识函数,将信息从初始层传递到下一层。通过赋予神经网络使用标识函数的能力,相比单纯地增加层数,我们可以构建性能更好的网络。你可以在参考资料中阅读有关 ResNet 及其变体的更多信息。[8]
编码器 - 解码器架构由两个单独的神经网络组成:编码器提取输入(嵌入)的一个固定长度表示,而解码器从该表示生成输出。

用于图像分割的编码器 - 解码器网络 [6]
你会注意到,编码器部分与上一节中描述的 CNN 非常相似。经过验证的分类 CNN 通常用作编码器的基础,甚至直接用作编码器,只是没有最后一个(分类)层。这个架构可以用来生成新图像,这正是我们所需要的。但它的性能却不是那么好,因此我们来看一下更好的东西。
U-net 最初是为图像分割而开发的卷积神经网络架构[2],但它在其他许多任务(例如图像修复或图像着色)中也展示了自己的能力。

原始文章中的 U-net 架构 [2]
我们前面之所以提到 ResNet 块有一个重要原因。事实上,将 ResNet 块与 U-net 架构结合使用对整体性能的影响最大。你可以在下图中看到添加 ResNet 块的架构。

U-net 中使用的 Upscale ResNet 块(顶部)和 downscale resNet 块(底部)
当你将上面的 U-net 架构与上一节中的编码器 - 解码器架构进行比较时,它们看起来非常相似,但有一个关键的区别:U-net 实现了一种称为“跳过连接”的功能,该功能将 identity 从反卷积块传播到另一侧对应的上采样块(上图中的灰色箭头)。这是对编码器 - 解码器架构的两处显著改进。
首先,已知跳过连接可以加快学习过程并帮助解决梯度消失问题[5];其次,它们可以将信息从编码器直接传递到解码器,从而有助于减少下采样期间的信息丢失。我们可以认为它们能传播我们希望保持不变的口罩外部图像的所有部分,同时还有助于生成口罩下面的脸部图像。
这正是我们所需要的!跳过连接将有助于保留我们要传播到输出的部分输入,而 U-net 的编码器 - 解码器部分将检测到口罩并将其替换为下面的嘴部图像。
如何选择损失函数是你需要解决的最重要的问题之一,使用正确的损失函数可能会得到性能出色的模型,反之就会得到令人失望的模型。这就是我们花很多时间选择最佳模型的原因所在。下面,我们来讨论几种选项。
MSE 和 MAE 都是损失函数,都基于我们模型生成的图像将口罩应用到面部之前。这似乎正是我们所需要的,但我们并不打算训练可以像素级完美重现口罩下隐藏内容的模型。
我们希望我们的模型理解口罩下面是嘴巴和鼻子,甚至可能要理解来自那些未被隐藏的事物(例如眼睛)所包含的情感,从而生成悲伤的、快乐的或可能是惊讶的面孔。这意味着,即使不能完美地捕获每个像素,实际上也可以产生一个很好的结果;更重要的是,它可以学习如何在任何脸部上泛化,而不仅仅是对训练数据集中的面孔进行泛化。
SSIM 是用于度量两个图像之间相似度的度量标准,由 Wang 等人在 2004 年提出[3]。它专注于解决 MSE/MAE 所存在的问题。它提供了一个数值表达式,用来展示两张图像之间的相似度。它通过对比图像之间的三个测量值来做到这一点:亮度、对比度和结构。最终得分是所有三个测量值的加权组合,分数从 0 到 1,1 表示图像完全相同。
下图说明了 MSE 存在的问题:左上图是未经修改的原始图像;其他图像均有不同形式的失真。原始图像与其他图像之间的均方误差大致相同(大约 480),而 SSIM 的变化很大。例如,模糊图像和分割后的图像与原始图像的相似度绝对不如其他图像,但 MSE 几乎相同——尽管面部特征和细节丢失了。另一方面,偏色图像和对比度拉伸的图像与人眼中的原始图像非常相似(SSID 指标也是一样),但 MSE 表示不同意这个结论。

我们使用 ADAM 优化器和 SSIM 损失函数,通过 U-net 架构对模型进行训练,将数据集分为测试部分(1,000 张图像)、训练部分(其余 80%的数据集)和验证部分(其余 80%的数据集)。我们的第一个实验为几张测试图像生成了不错但不太清晰的输出图像。是时候尝试使用架构和损失函数来提高性能了,下面是我们尝试的一些更改:卷积过滤器的层数和大小。
更多的卷积过滤器和更深的网络意味着更多的参数(大小为[8、8、256] 的 2D 卷积层具有 59 万个参数,大小为[4、4、512] 的层具有 230 万个参数)和更多的训练时间。由于每层中过滤器的深度和数量是我们模型架构的构造器的输入参数,因此使用不同的值进行实验非常容易。
尝试一段时间后,我们发现对我们而言,以下设置可以达到性能和模型大小之间的最佳平衡:
# Train model with different number of layers and filter sizes
from utils.architectures import UNet
from utils.model import Mask2FaceModel
# Feel free to experiment with the number of filters and their sizes
filters = (64, 128, 128, 256, 256, 512)
kernels = ( 7, 7, 7, 3, 3, 3)
input_image_size=(256, 256, 3)
architecture = UNet.RESNET
training_epochs = 20
batch_size = 12
model = Mask2FaceModel.build_model(architecture=architecture, input_size=input_image_size, filters=filters, kernels=kernels)
model.summary()
model.train(epochs=training_epochs, batch_size=batch_size, loss_function='ssim_l1_loss'
我们做了一些实验,上面代码块中的设置对我们来说是最好的。
现在,我们已经通过上述调整对模型进行了训练和调整,下面我们来看一些结果!

左:我们模型的输入;中:没有口罩的输入图像(预期输出);右:我们模型的输出
如你所见,给定的网络在我们的测试数据上生成了很好的结果。这个网络具有泛化能力,并且似乎 可以很好地识别情绪,从而生成微笑或悲伤的面孔。另一方面,这里当然也有改进的空间。
虽说使用 ResNet 块的 U-net 网络效果很好,但我们也可以看到生成的摘口罩图像不是很清晰。一种解决方法是用一个提炼网络扩展我们的网络,如[4] 中和下图中所述。此外还可以进行其他一些改进。
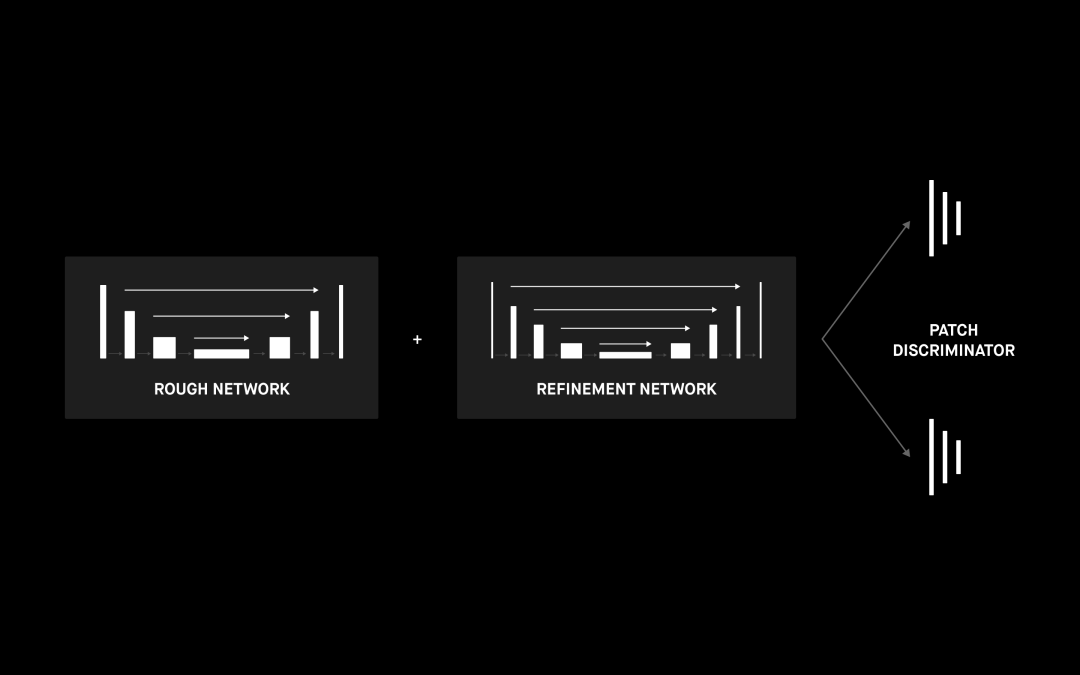
根据我们实验中获取的经验。数据集的选择可以对结果产生重大影响。下一步,我们将合并不同的数据集以使样本具有更大的多样性,从而更好地模拟现实世界的数据。另一项可行改进是调整将口罩与面部组合的方式,使它们看起来更自然。[12] 是很好的灵感来源。
我们已经提到了编码器 - 解码器架构,其中编码器部分将输入图像映射到嵌入中。我们可以将嵌入视为多维潜在空间中的单点。在许多方面,变分自动编码器与编码器 - 解码器是很像的;主要的区别可能是变分自动编码器的映射是围绕潜在空间的一点完成的多元正态分布。这意味着编码在设计上是连续的,可以实现更好的随机采样和内插。这可能会极大地改善网络输出生成图像的平滑度。
GAN 能够生成与真实照片无法区分的结果,这主要归功于完全不同的学习方法。我们当前的模型试图将训练过程中的损失降到最低,而 GAN 还是由两个独立的神经网络组成:生成器和鉴别器。生成器生成输出图像,而鉴别器尝试确定图像是真实图像还是由生成器生成。
在学习过程中,两个网络都会动态更新,让表现越来越好,直到最后鉴别器无法确定所生成的图像是否真实,生成器所生成的图像就与真实图像无法区分了。

从源 A 和源 B 创建混合面孔的示例 [9]
GAN 的结果很好,但在训练过程中通常会出现收敛问题,而且训练时间很长。由于参数众多,GAN 模型通常也要复杂得多,因此不太适合导出到手机上。
在许多方面,U-net 的瓶颈层都可以用作特征提取嵌入。[10]、[11] 等文章建议,将不同网络的嵌入并置可以提高整体性能。
我们尝试将嵌入(瓶颈层)与 ImageNet 和 FaceNet 的两种不同嵌入结合在一起。我们期望这可以添加有关人脸及其特征的更多信息,以帮助 U-net 的上采样部分进行人脸修复。这无疑提高了性能,但另一方面,它使整个模型更加复杂,并且与“训练”部分中提到的其他改进相比,其性能提升要小得多。
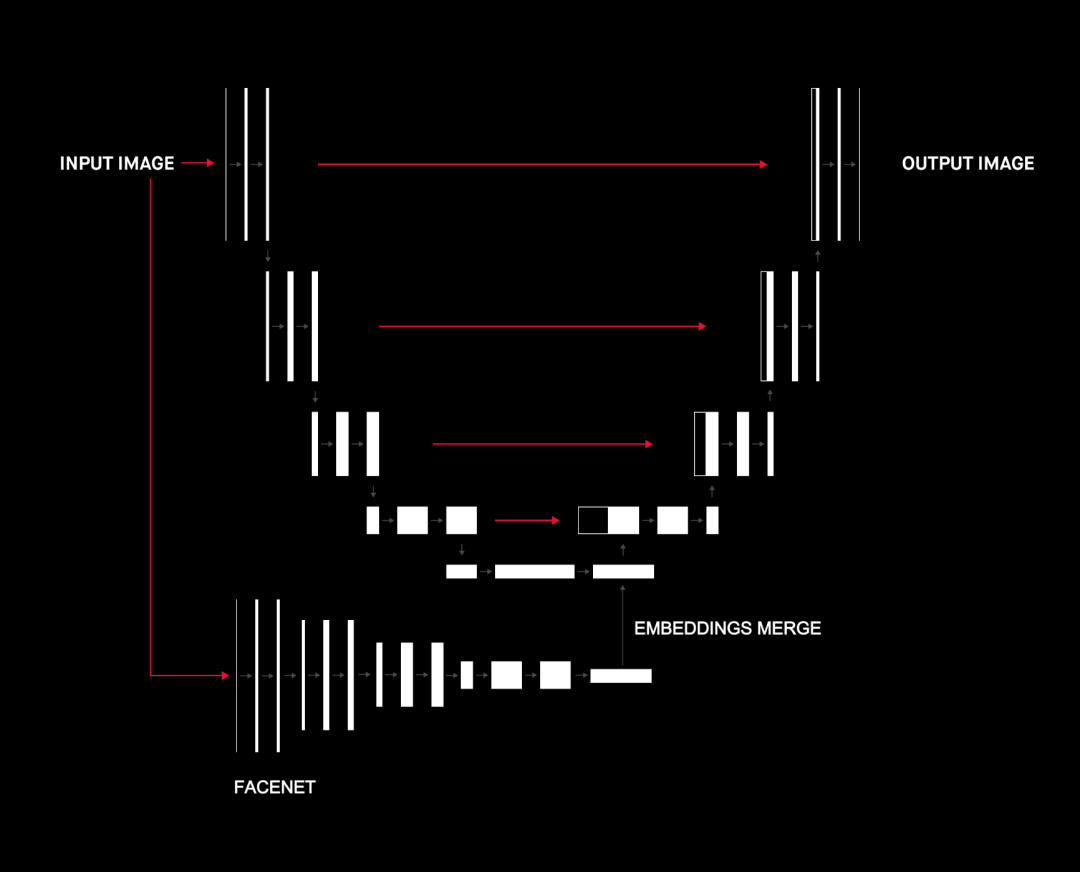
这种人脸重建面临许多挑战。我们发现,要想获得最佳结果,就需要一种创新的方法来融合各种数据集和技术。我们必须适当地解决诸如遮挡、照明和姿势多样性等具体问题。问题无法解决的话,在传统的手工解决方案和深度神经网络中都会有显著的精度下降,方案最后可能只能处理一类照片。
但正是这些挑战让我们发现这个项目非常具有吸引力。
我们着手创建 Mask2Face 的原因是要为我们的 ML 部门打造一个典型示例。我们观察世界上正在发生的事情(口罩检测),并寻找不怎么常见的路径(摘下口罩)。任务越难,学到的经验越多。ML 的核心目标是解决看似不可能的问题,我们希望一直遵循这一理念。
[1]http://vis-www.cs.umass.edu/lfw/
[2] https://arxiv.org/abs/1505.04597
[3] Wang, Zhou; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. (2004-04-01). "Image quality assessment: from error visibility to structural similarity". IEEE Transactions on Image Processing
[4] Elharrouss, O., Almaadeed, N., Al-Maadeed, S. et al. “Image Inpainting: A Review”. Neural Process Lett 51, 2007–2028 (2020). https://doi.org/10.1007/s11063-019-10163-0
[5] Adaloglou, Nikolas. "Intuitive Explanation of Skip Connections in Deep Learning". (2020) https://theaisummer.com/skip-connections/
[6] Hyeonwoo Noh, Seunghoon Hong and Bohyung Han. “Learning Deconvolution Network for Semantic Segmentation”. (2015) https://arxiv.org/abs/1505.04366
[7]. K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,2015.
[8] https://towardsdatascience.com/an-overview-of-resnet-and-its-variants-5281e2f56035
[9] T. Karras, S. Laine and T. Aila. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv preprint arXiv:1812.04948,2019
[10] Danny Francis, Phuong Anh Nguyen, Benoit Huet and Chong-Wah Ngo. Fusion of Multimodal Embeddings for Ad-Hoc Video Search. ICCV 2019
[11] Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Zhenhua Chai, Xiaolin Wei and Ran He. Free-Form Image Inpainting via Contrastive Attention Network. arXiv preprint arXiv:2010.15643, 2020
[12] https://medium.com/neuromation-blog/neuronuggets-cut-and-paste-in-deep-learning-a296d3e7e876
原文链接:
https://www.strv.com/blog/mask2face-how-we-built-ai-that-shows-face-beneath-mask-engineering
—版权声明—
来源:AI前线
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!