
GAN的入门与实践
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

引言
生成对抗网络(Generative Adversarial Nets,GAN)是由open ai研究员Good fellow在2014年提出的一种生成式模型,自从提出后在深度学习领域收到了广泛的关注和研究。目前,深度学习领域的图像生成,风格迁移,图像变换,图像描述,无监督学习,甚至强化学习领域都能看到GAN 的身影。GAN主要针对的是一种生成类问题。目前深度学习领域可以分为两大类,其中一个是检测识别,比如图像分类,目标识别等等,此类模型主要是VGG, GoogLenet,residual net等等,目前几乎所有的网络都是基于识别的;另一种是图像生成,即解决如何从一些数据里生成出图像的问题,生成类模型主要有深度信念网(DBN),变分自编码器(VAE)。而某种程度上,在生成能力上,GAN远远超过DBN、VAE。经过改进后的GAN足以生成以假乱真的图像。本文将首先介绍一些GAN 的原理和公式推导,另外会详细给出GAN生成图像的Tensorflow的实现,基于python语言。
GAN主要解决的是生成类问题,即如何从一段任意的随机数中生成图像。假设给定一段100维的向量X{x1, x2,…, x100 }作为网络的输入,其中x是产生的随机数,一般按照高斯分布或者均匀分布产生,GAN通过对抗训练的方式,可以生成清晰的图像,这个过程是通过GAN不断模拟训练集中图像的像素分布来实现的。看完下文GAN的原理后或许你会对这个过程有一个清晰的认识。
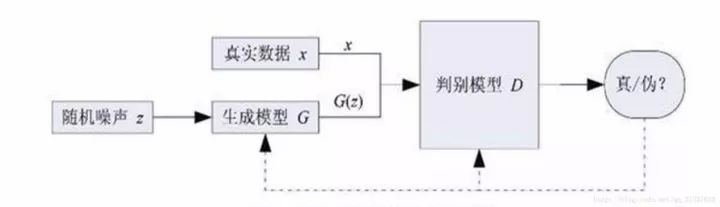
图1
首先,附上一张GAN的网络流程图,如图1所示。不同于以往的判别网络模型,GAN包括两个网络模型,一个生成模型G(generator)和一个判别模型D(discriminator),其中D就是识别检测类模型中经常使用的网络。GAN的大概流程是,G以随机噪声作为输入,生成出一张图像G(z),暂且不管生成质量多好,然后D以G(z)和真实图像x作为输入,对G(z)和x做一个二分类,检测谁是真实图像谁是生成的假图像。D的输出是一个概率值,比如G(z)作为输入时D输出0.15,那么代表D认为G(z)有15%的概率是真图像。然后G和D会根据D输出的情况不断改进自己,G提高G(z)和x的相似度,尽可能的欺骗D,而D则会通过学习尽可能的不被G欺骗。二者相当于是做一个极大极小的博弈过程,称为零和博弈。可以用一个简单的例子描述他们之间的过程,我们把G想象成制造假币的团伙,视D为警察,G不断产生假币,而D任务就是从真钱币中分辨出G的假币,刚开始时,G没有经验,制造的假币太假,D很容易就能分辨出来,所以G不断改进自己的技术,产生的假币越来越真实,D可能就没有那么容易判别出真假了,所以D也根据自己的情况不断改进自己,经过很多次这样的循环之后,G产生的假币足以以假乱真了,D很难分出真假。对应到图像生成上,此时G足以生成出一般的分类神经网络分辨不出真假的图像了,G从而获得了生成图像的能力。
与传统神经网络训练不一样的且有趣的地方,就是训练生成器的方法不同,生成器参数的更新来自于D的反传梯度。生成器一心想要“骗过”判别器。使用博弈理论分析技术,可以证明这里面存在一种纳什均衡。
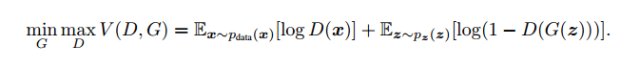
这里就是他们的损失函数定义,实际上是一个交叉熵,判别器的目的是尽可能的令D(x)接近1,令D(G(z))接近0,所以D主要是最大化上面的损失函数,G恰恰相反,他主要是最小化上述损失函数。
训练过程:

(图2)
图2展示了GAN训练的伪代码,首先在迭代次数范围内,首先对z和x采样一个批次,获得他们的数据分布,然后通过随机梯度下降的方法先对D做k次更新,之后对G做一次更新,这样做的主要目的是保证D一直有足够的能力去分辨真假。实际在代码中我们可能会多更新几次G只更新一次D,不然D学习的太好,会导致训练前期发生梯度消失的问题。
在求平衡点之前,我们先做一个数学假设,即G固定情况下D的最优形式,然后根据D的最优形式再去观察G最小化损失函数的问题。
假设在G固定的条件下,并将损失函数化为如下简单形式:
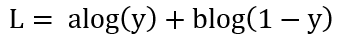
D的目标就是最大化L,我们可以通过对L求导,并令导数为0,计算出L取最大值时y的取值如下:
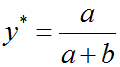
所以,换为原来的式子D的最优解形式为:
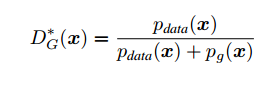
到这里我们得出了结论,当G固定时,D的最优形式是上面形式。
接下来我们求一下D最优时,G最小化损失函数到什么形式才能达到二者相互博弈的平衡点。
带入到损失函数里面后,损失函数可以写为如下形式:
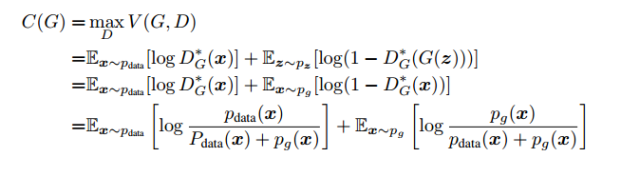
这时观察到,上面式子仍然是一个交叉熵也称KL散度的形式,KL散度通常用来衡量分布之间的距离,它是非对称的。同样还有另一个衡量数据分布距离的散度--JS散度,他们之间有如下关系。
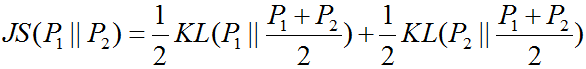
不过JS散度有一个很重要的性质就是总是大于等于0的,当且仅当 P1=P2上面的式子取得最小值0,
所以我们可以将C(G)写成JS散度的形式:
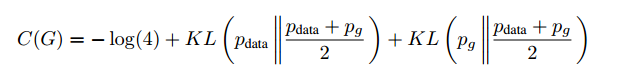
也即是当且仅当Pg=Pdata时,C(G)取得最小值-log(4),也即是D最优时,G能将损失函数最小化到-log(4),最小点处Pg=Pdata。即真实数据的分布和生成数据的分布相等。
分析到这里,直观上也很好理解了,Pg=Pdata意味着此时D恰好等于0.5,就是D有一半的概率认为D(G(z))是真的数据,有一半概率认为是假的数据,这不就和猜硬币正反面一样嘛。也说明了此时G生成的数据足以以假乱真。
到这里,GAN的原理和数学推导就介绍完了,理论上说明了GAN只要循规蹈矩的训练,G就可以完美的模拟数据分布并生成真实的图像,但是我们做数学推导的时候为了证明方便做了一些假设,实际上并不是这样,GAN存在训练困难、梯度消失、模式崩溃的问题,这些问题在这里不做重点介绍。
首先,建立一个train.py文件,在文件里建立一个名为Train的类,在类的初始化函数里进行一些初始化:
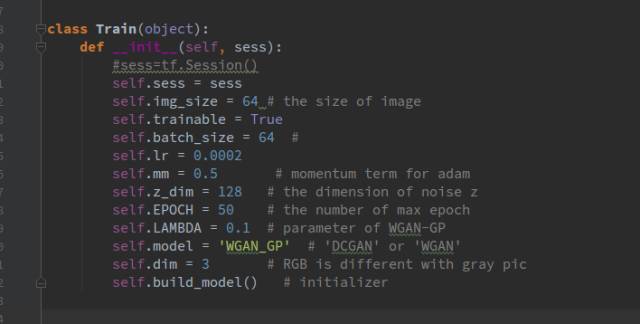
Self.build_model()函数用来存放构建流图部分的代码,下面会介绍,其他初始化的都是一些简单的参数。
下面先介绍生成器和判别器的网络:
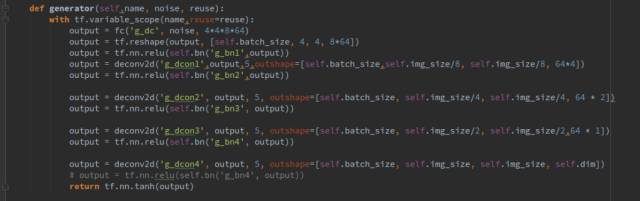
生成器传进去三个参数,分别是名字,输入数据,和一个bool型状态变量reuse,用来表示生成器是否复用,reuse=True代表网络复用,False代表不复用。
生成器一共包括1个全连接层和4个转置卷积层,每一层后面都跟一个batchnorm层,激活函数都选择relu。其中fc(),deconv2d()函数和bn()函数都是我们封装好的函数,代表全链接层,转制卷积层,和归一化层,其形式如下:
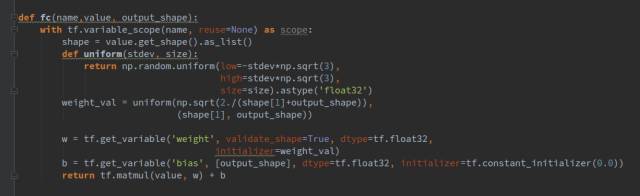
全连接层fc的输入参数value指输入向量,output_shape指经过全连接层后输出的向量维度,比如我们生成器这里噪声向量维度是128,我们输出的是4*4*8*64维。
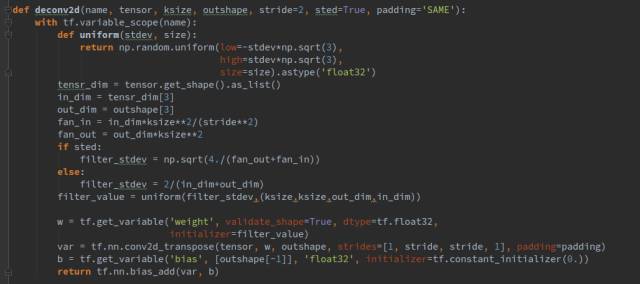
其中Ksize指卷积核的大小,outshape指输出的张量的shape,sted是一个bool类型的参数,表示用不同的方式初始化参数
bn()函数我是直接放在了train的类里面,其形式如下:
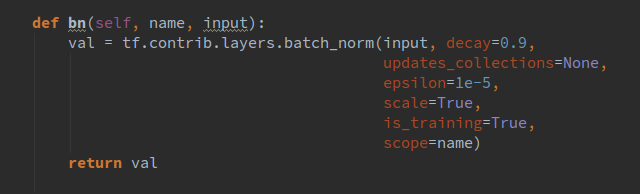
我们都希望权重都能初始化到一个比较好的数,所以这里我没有直接用固定方差的高斯分布去初始化权重,而是根据每一层的输入输出通道数量的不同计算出一个合适的方差去做初始化。同理,我们还封装了卷积操作,其形式如下:
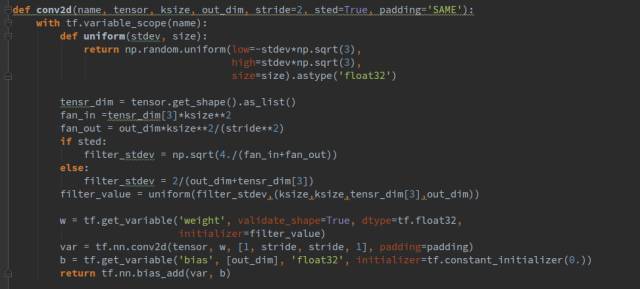
好了,目前已经介绍了生成器的结构和一些基本函数,下面来介绍一下判别网络,其代码如下所示:
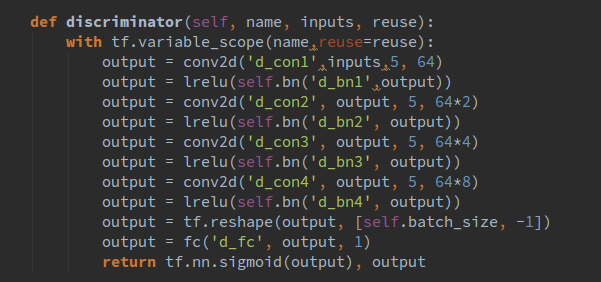
与生成器不同的是,我们使用leakrelu作为激活函数,
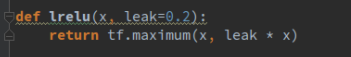
这些函数的定义都是放在了layer.py文件里,
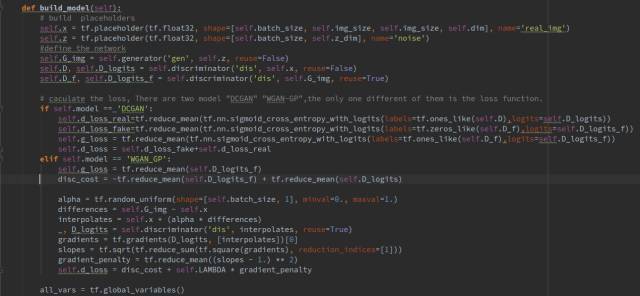
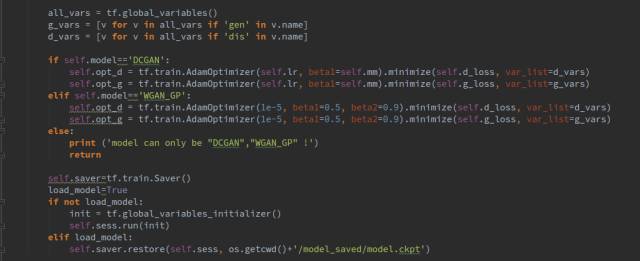
这里有两个GAN可供选择,DCGAN 和WGAN-GP,他们唯一不同的地方是损失函数的计算不同,网络结构都是一样的,二者都是GAN的改进版,WGAN-GP效果好更好一些,这里我们使用WGAN-GP。DCGAN训练的时候容易遇到训练不稳定的问题。
到这里我们已经介绍完了所有的初始化过程,接下来就是训练数据的提取和网络的训练部分了,训练数据我们使用cele名人数据集,一共20万张图像左右,数据集里的图像size并不是很一致,我们可以使用一小段代码把图像的人脸截取下来,并resize到64*64大小。
代码如下:
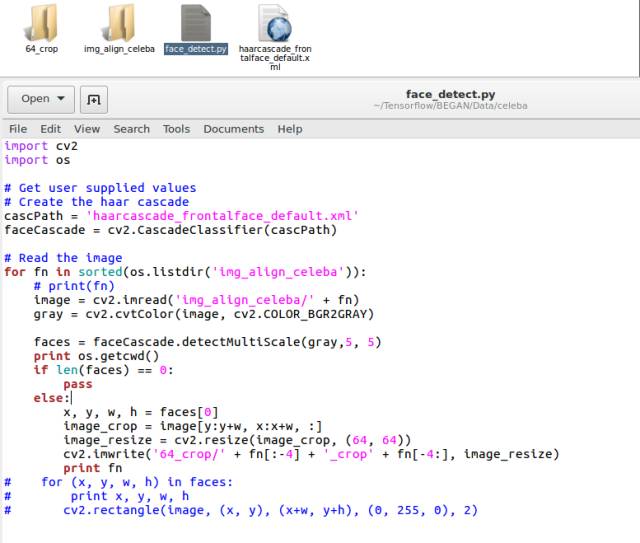
把数据集下载下来后解压到img_align_celeba文件夹里面,然后运行face_detec.py就可以了,截取下来的图像会放到64_crop文件夹里,本来有20万张图像的,截取过后就剩15万张了。
下面就是训练部分了,首先是读取数据,load_data()函数每次会读取一个batch_size的数据作为网络的输入,在训练过程中,我们选择训练一次D训练两次G,而不是训练多次D之后训练一次G,不然容易发生训练不稳定的问题,因为D总是学的太好,很容易就判别出真假,所以导致G不论怎么改进都没有用,有些太打击G的造假积极性了。
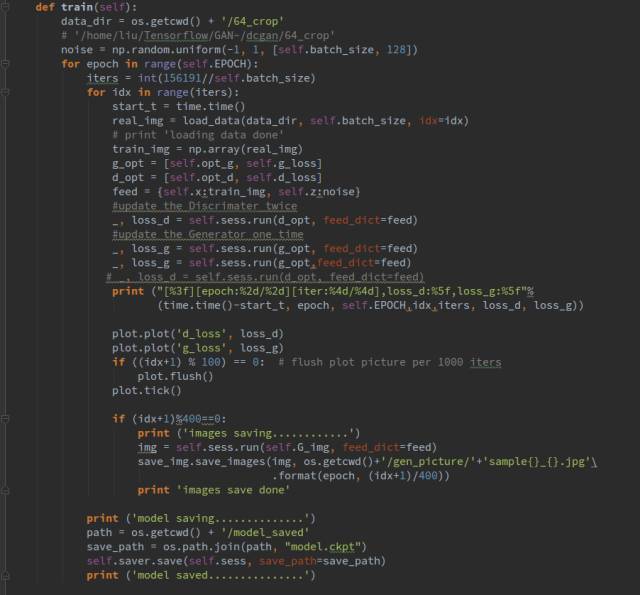
Plot()函数会每训练100步后绘出网络loss的变化图像,是另外封装的函数
同时我们选择每训练400步生成一张图像,看一下生成器的效果。
load_data()函数我们并没有使用队列或者转化为record文件读取,这样的方式肯定会快一些,读取图像我们使用scipy.misc 来读取,
具体是import scipy.misc as scm
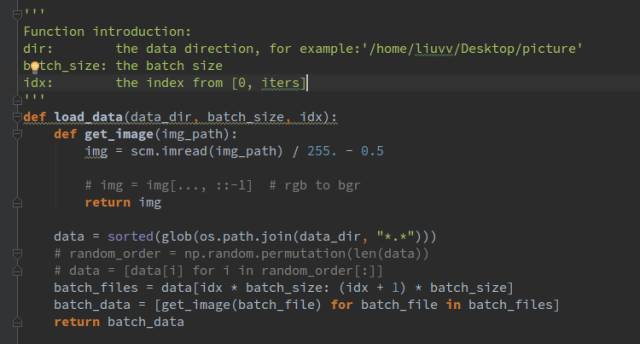
可以看到,我们首先对所有的图像做一个排序,返回一个列表,列表里存放的是每个图像的位置索引,这样做就是每次将一个batch_size的数据读到了内存里,读取的数据做了一个归一化操作,我们选择归一化到[-0.5,+0.5]。
接下来就是展示结果的时候了,其中训练过程loss的变化如下所示:
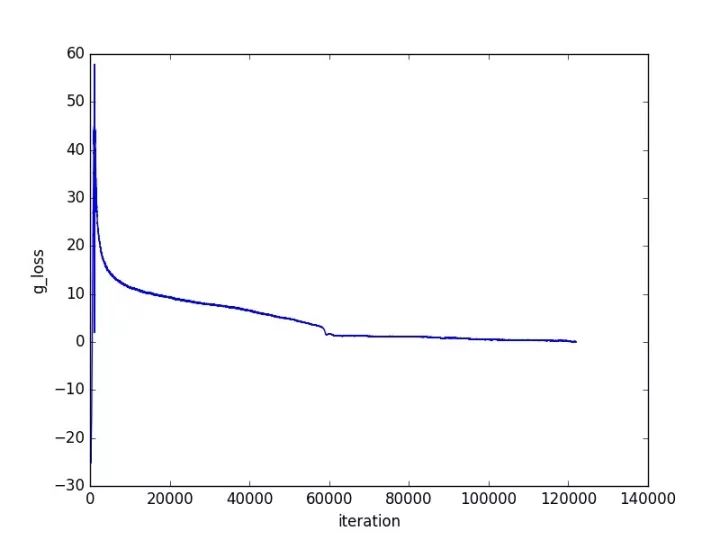
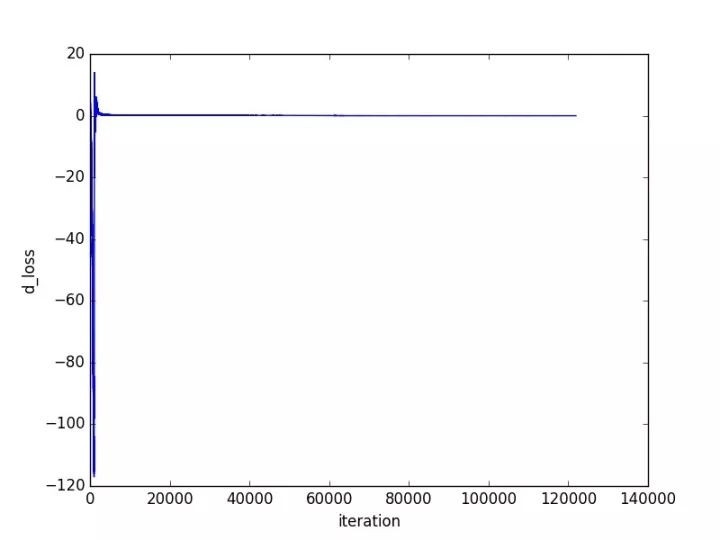
由图可见,经过一次比较大的震荡之后,网络就收敛的比较好了。
接下来是展示生成结果了:
我测试的时候设置了bach_size是16:
训练1epoch的时候是这样子的:

训练一段时间后:

再往后训练效果看上去反而差了一些,而且明显没有学习到眼镜的特征(最后一行第二个)估计是数据集里眼镜比较少,GAN学习不到足够的特征,眼睛鼻子嘴巴学习的还是很好的。

训练失败的结果:

下面谈一谈我训练GAN的感受,GAN是在是太难训练了,即使是使用WGAN,WGAN-GP,还是遇到了训练困难的问题,以上这些结果都是我做了好几次实验得出来的结果,有些实验中间得到的生成结果其实是惨不忍睹的,就像是下面这样,我总结了一部分原因,一个原因是网络结构太简单,我本次使用的网络是几年前流行的DCGAN的网络结构,有很大的改进空间,现在基本上用的不多了,我也试了BEGAN,不得不说BEGAN是真好训练,只要写好代码就让他自己跑去吧,基本上不会出问题,而且效果还很好;另一个原因是优化器的选择和学习率等超参数的设置。设置好的超参数对GAN的训练是很有帮助的,至于优化器,尽量不要选择SGD,因为GAN的平衡点是一个鞍点,鞍点附近梯度几乎为0,使用梯度的优化方法很难收敛到最优点,另外就是SGD训练震荡,很容易引起训练不稳定。理论上是这样,实际的问题比这复杂的多。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~