
Pandas最详细教程来了!
机器学习算法与Python实战
共 9733字,需浏览 20分钟
·
2021-04-23 22:55
导读:在Python中,进行数据分析的一个主要工具就是Pandas。Pandas是Wes McKinney在大型对冲基金AQR公司工作时开发的,后来该工具开源了,主要由社区进行维护和更新。
import pandas as pd
data={'A':['x','y','z'],'B':[1000,2000,3000],'C':[10,20,30]}
df=pd.DataFrame(data,index=['a','b','c'])
df
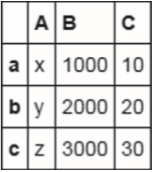
数据,位于表格正中间的9个数据就是DataFrame的数据部分。 索引,最左边的a、b、c是索引,代表每一行数据的标识。这里的索引是显式指定的。如果没有指定,会自动生成从0开始的数字索引。 列标签,表头的A、B、C就是标签部分,代表了每一列的名称。
data:ndarray/字典/类似列表 | DataFrame数据;数据类型可以是ndarray、嵌套列表、字典等 index:索引/类似列表 | 使用的索引;默认值为range(n) columns:索引/类似列表 | 使用的列标签;默认值为range(n) dtype:dtype | 使用(强制)的数据类型;否则通过推导得出;默认值为None copy:布尔值 | 从输入复制数据;默认值为False
二维ndarray:可以自行指定索引和列标签 嵌套列表或者元组:类似于二维ndarray 数据、列表或元组组成的字典:每个序列变成一列。所有序列长度必须相同 由Series组成的字典:每个Series会成为一列。如果没有指定索引,各Series的索引会被合并 另一个DataFrame:该DataFrame的索引将会被沿用
df.values
array([['x', 1000, 10],
['y', 2000, 20],
['z', 3000, 30]], dtype=object)
df.index
Index(['a', 'b', 'c'], dtype='object')
df.columns
Index(['A', 'B', 'C'], dtype='object')
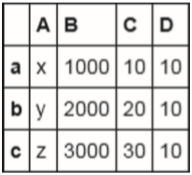
df=pd.DataFrame(data,columns=['C','B','A'],index=['a','b','c'])
df

df['D']=10
df
del df['D']
df

new_df=pd.DataFrame({'A':'new','B':4000,'C':40},index=['d'])
df=df.append(new_df)
df

df.loc['e']=['new2',5000,50]
df

df2=pd.DataFrame([1,2,3,4,5],index=['a','b','c','d','z'],columns=['E'])
df2

df.join(df2)

df.join(df2,how='outer')

dates=pd.date_range('20160101',periods=8)
dates
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06', '2016-01-07', '2016-01-08'],dtype='da
tetime64[ns]', freq='D')
start:字符串/日期时间 | 开始日期;默认为None end:字符串/日期时间 | 结束日期;默认为None periods:整数/None | 如果start或者end空缺,就必须指定;从start开始,生成periods日期数据;默认为None freq:dtype | 周期;默认是D,即周期为一天。也可以写成类似5H的形式,即5小时。其他的频率参数见下文 tz:字符串/None | 本地化索引的时区名称 normalize:布尔值 | 将start和end规范化为午夜;默认为False name:字符串 | 生成的索引名称
B:交易日 C:自定义交易日(试验中) D:日历日 W:每周 M:每月底 SM:半个月频率(15号和月底) BM:每个月份最后一个交易日 CBM:自定义每个交易月 MS:日历月初 SMS:月初开始的半月频率(1号,15号) BMS:交易月初 CBMS:自定义交易月初 Q:季度末 BQ:交易季度末 QS:季度初 BQS:交易季度初 A:年末 BA:交易年度末 AS:年初 BAS:交易年度初 BH:交易小时 H:小时 T,min:分钟 S:秒 L,ms:毫秒 U,us:微秒 N:纳秒
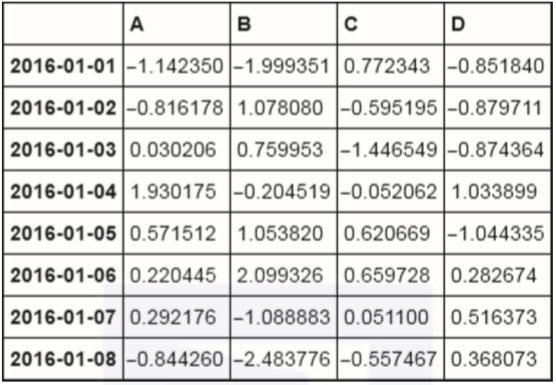
df=pd.DataFrame(np.random.randn(8,4),index=dates,columns=list('ABCD'))
df
df.sum()A 0.241727
B -0.785350
C -0.547433
D -1.449231
dtype: float64
df.mean()A 0.030216
B -0.098169
C -0.068429
D -0.181154
dtype: float64
df.cumsum()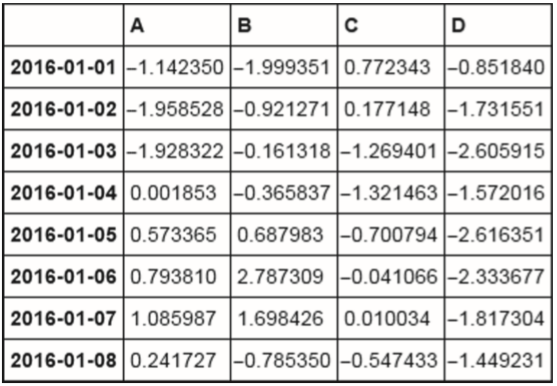
df.describe()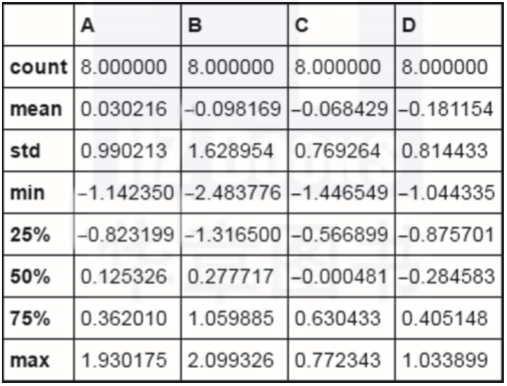
df.sort_values('A')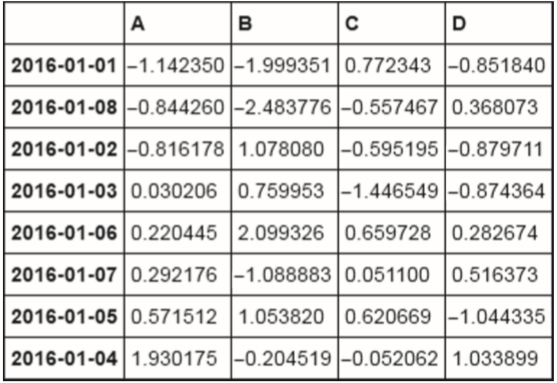
df.sort_index(ascending=False)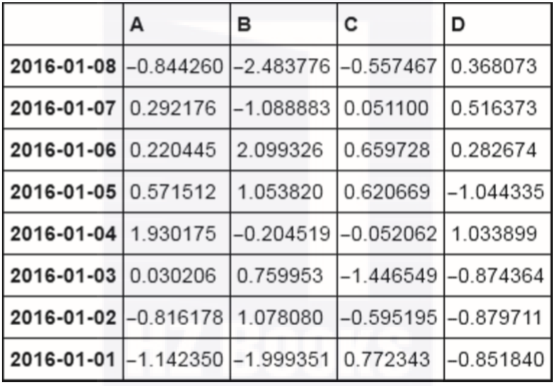
df['A']
2016-01-01 -1.142350
2016-01-02 -0.816178
2016-01-03 0.030206
2016-01-04 1.930175
2016-01-05 0.571512
2016-01-06 0.220445
2016-01-07 0.292176
2016-01-08 -0.844260
Freq: D, Name: A, dtype: float64
df[0:5]

df.loc[dates[0]]
A -1.142350
B -1.999351
C 0.772343
D -0.851840
Name: 2016-01-01 00:00:00, dtype: float64
df.loc[:,['A','C']]

df.loc['20160102':'20160106',['A','C']]

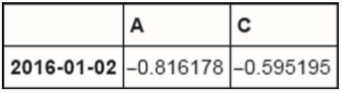
df.loc['20160102',['A','C']]
A -0.816178
C -0.595195
Name: 2016-01-02 00:00:00, dtype: float64
df.loc['20160102':'20160102',['A','C']]
df.iloc[2]
A 0.030206
B 0.759953
C -1.446549
D -0.874364
Name: 2016-01-03 00:00:00, dtype: float64
df.iloc[3:6,1:3]
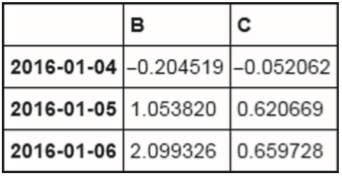
df.A>0
2016-01-01 False
2016-01-02 False
2016-01-03 True
2016-01-04 True
2016-01-05 True
2016-01-06 True
2016-01-07 True
2016-01-08 False
Freq: D, Name: A, dtype: bool
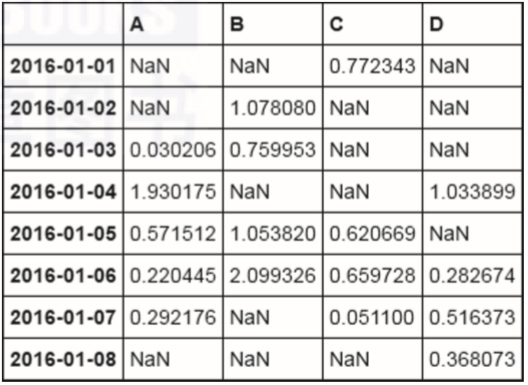
df[df.A>0]

df>0
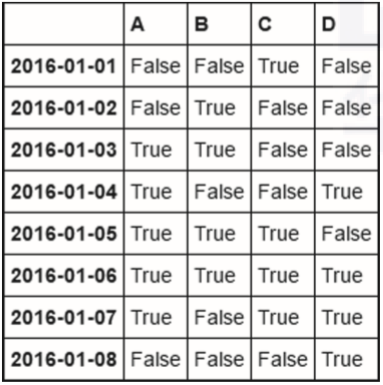
df[df>0]
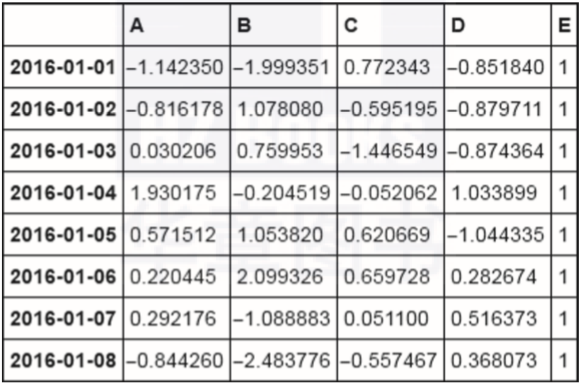
df['E']=0
df
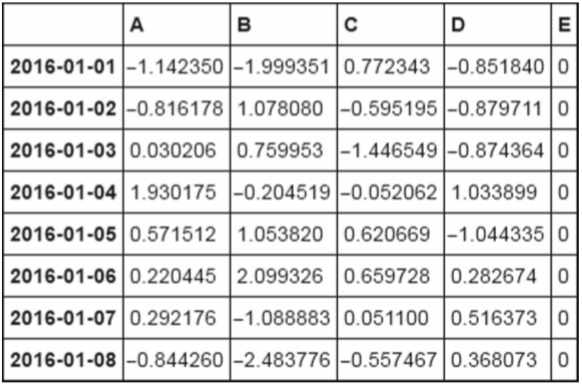
df.loc[:,'E']=1
df
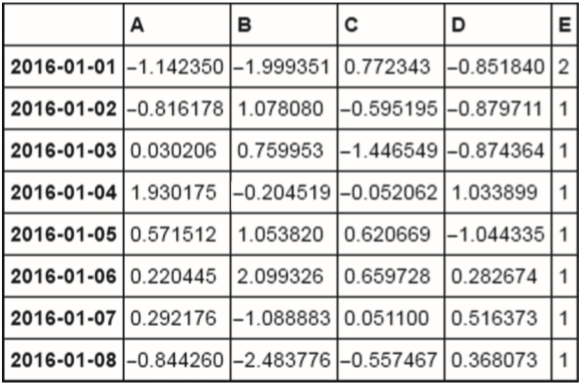
df.loc['2016-01-01','E'] = 2
df
df.loc[:,'D'] = np.array([2] * len(df))
df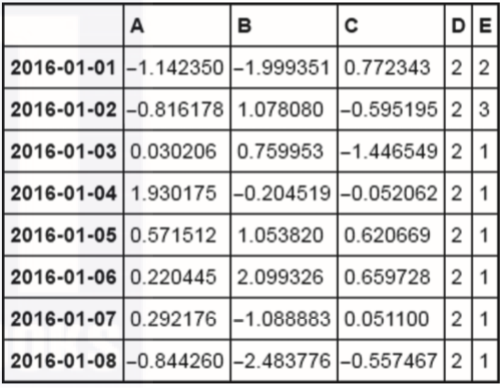
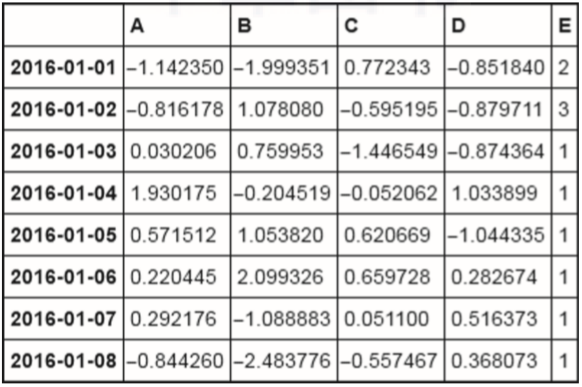
df.ix[1,'E'] = 3
df
假如索引本身就是整数类型,那么ix只会使用标签索引,而不会使用位置索引,即使没能在索引中找到相应的值(这个时候会报错)。 如果索引既有整数类型,也有其他类型(比如字符串),那么ix对于整数会直接使用位置索引,但对于其他类型(比如字符串)则会使用标签索引。
import pandas as pd
s=pd.Series([1,4,6,2,3])
s
0 1
1 4
2 6
3 2
4 3
s.values
array([1, 4, 6, 2, 3], dtype=int64)s.index
Int64Index([0, 1, 2, 3, 4], dtype='int64')
s=pd.Series([1,2,3,4],index=['a','b','c','d'])
s
a 1
b 2
c 3
d 4
s['a']
1s[['b','c']]
b 2
c 3
s[s>1]
b 2
c 3
d 4s*3
a 3
b 6
c 9
d 12
s1=pd.Series([1,2,3],index=['a','b','c'])
s2=pd.Series([4,5,6],index=['b','c','d'])
s1+s2
a NaN
b 6
c 8
d NaN
s.index
Index([u'a', u'b', u'c', u'd'], dtype='object')s.index=['w','x','y','z']
s.index
Index([u'w', u'x', u'y', u'z'], dtype='object')
s
w 1
x 2
y 3
z 4

推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论