
MySQL之InnoDB存储引擎:执行计划之Explain命令
在MySQL中,查询优化器会对用户提交的SQL语句进行调整优化并最终生成执行计划。具体地,可通过Explain命令来进行查看

基本使用
关于Explain命令的使用方法,在前面已经多次出现了。直接在我们的SQL语句前添加explain,即可查看该SQL语句的执行计划。下面即是一个查看select语句执行计划的示例。事实上,Explain命令亦可用于delete、insert、update等其它类型的SQL语句上,只不过日常我们更关心查询语句的执行计划
字段释义
上面,我们知道了如何查看执行计划。现在我们来了解下查询语句的执行计划中各字段的含义
id字段
对于查询语句而言,在执行计划中其会对每一个select关键字分配一个唯一的id值
单表查询
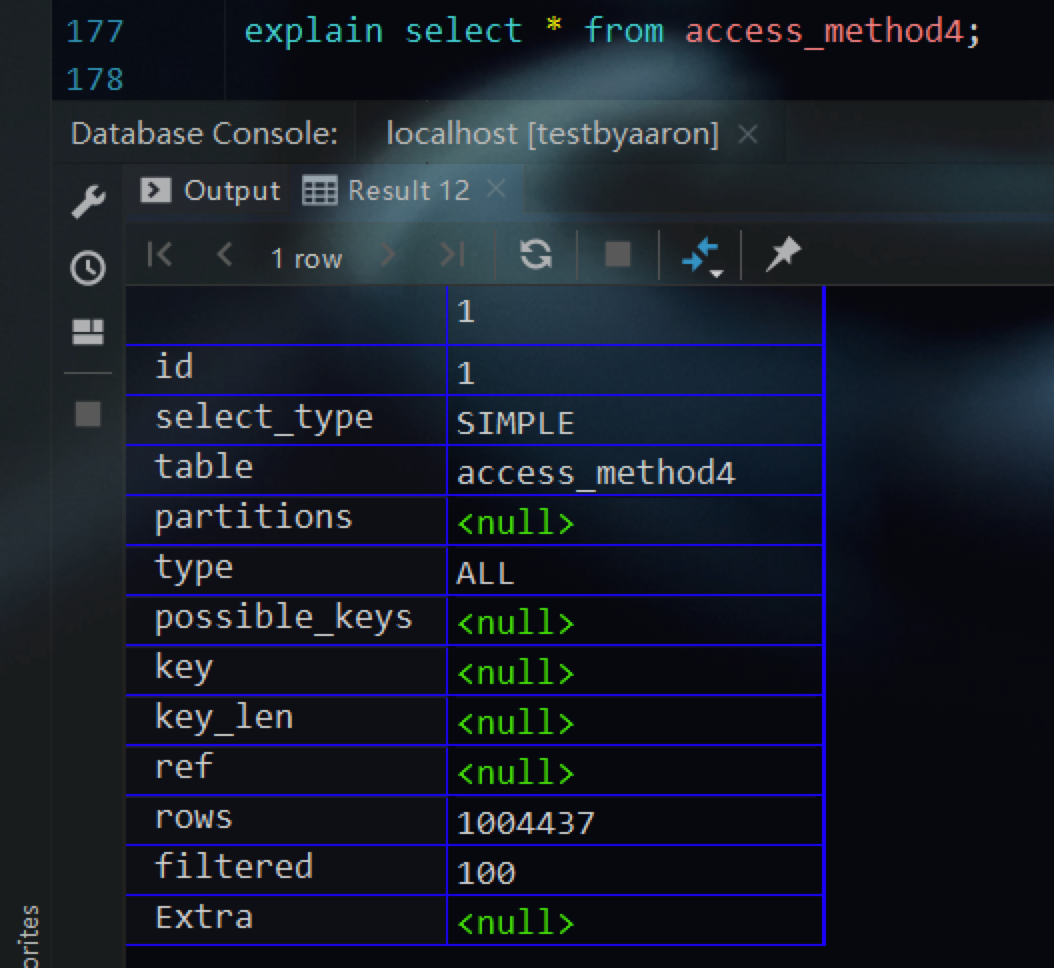
例如下面是一个单表查询的select语句
explain select * from access_method4;
由于是对单表的查询,所以执行计划中只有一条记录,符合预期
连接查询
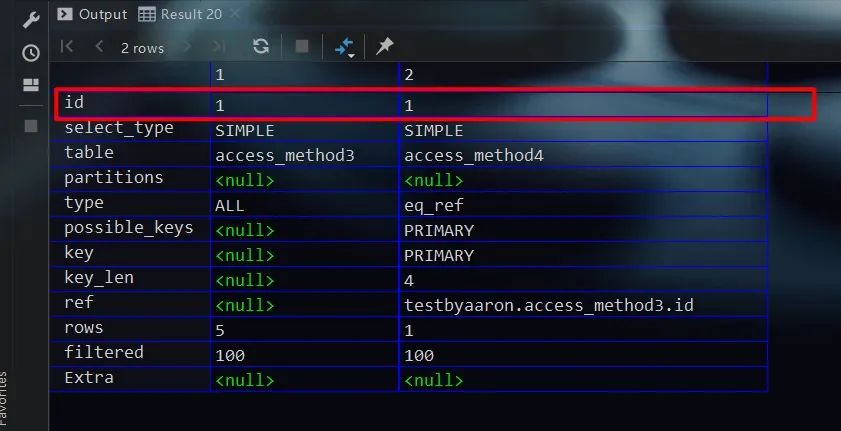
对于下面的连接查询而言,其涉及到对两张表的查询
explain
select * from access_method3 left join testbyaaron.access_method4
on access_method3.id = access_method4.id;
从执行计划的结果中可以看出,虽然有两条记录。但是由于只含一个select关键字,故两条记录均使用同一个id值
Note
对于连接查询的执行计划而言,前面的记录用于表示驱动表,后面的记录用于表示被驱动表
子查询
对于一个SQL查询语句而言,其可能会有不止一个select关键字。典型地,有所谓的子查询
explain
select * from access_method3
where id = (
select access_method4.id from access_method4
where access_method3.name = access_method4.name );
从下图的执行计划中可以看出,由于存在两个select关键字,故两条记录的id值不一样
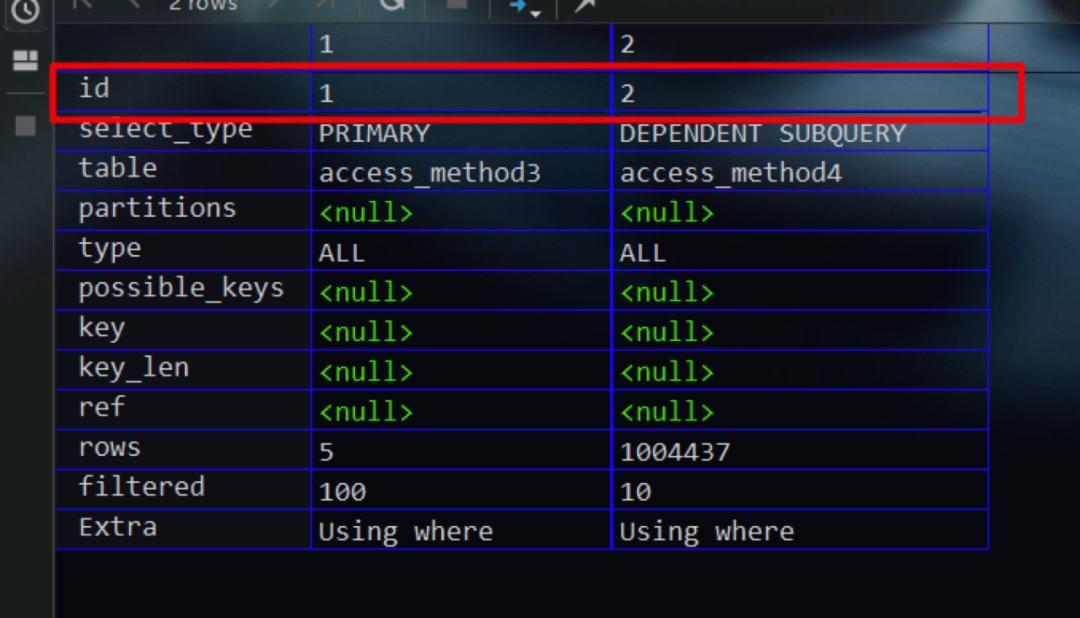
值得一提的是对于子查询而言,查询优化器有时候会将其优化为连接查询(准确地说,是semi-join半连接)。这样我们在查看它的执行计划时即会发现各记录的id值是一样的
Union联合查询
在Union联合查询中,其也会存在多个select关键字。例如下面的SQL语句
explain
select * from access_method3 where id = 2
union all
select * from access_method3 where id = 3;
结果符合预期,两条记录的id值不一样
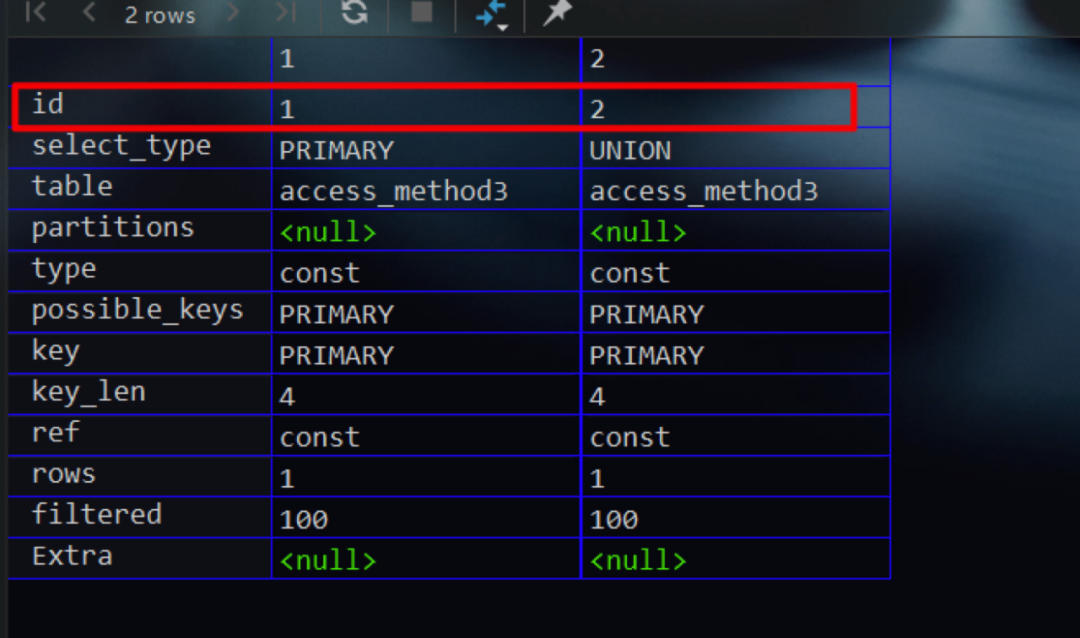
现在我们再来看另外一个联合查询。与上面SQL不同的是,由于其没有使用all关键字,故该联合查询需要对重复的记录进行去重
explain
select * from access_method3 where id = 2
union
select * from access_method3 where id = 3;
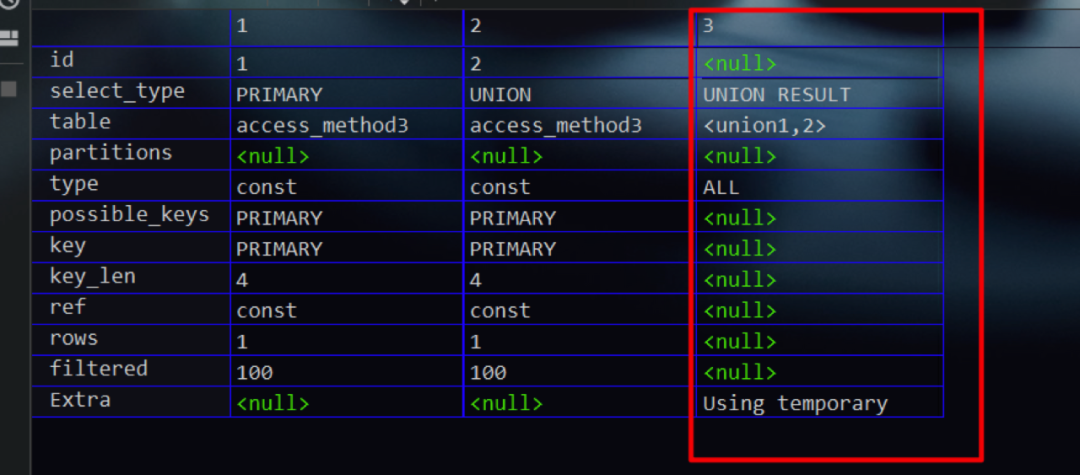
现在,我们来看看该联合查询的执行计划。可以看出,其多了一条记录且id值为NULL。原因在于MySQL为了对两条select命令的结果进行去重合并,需要建立一个名为 <union1, 2>的临时表。所以这第三条记录的id值为NULL
select_type字段
从上面的测试结果可以看到,执行计划中会生成各数据表相应的记录。而select_type字段即表示对数据表进行select操作的类型。下面介绍几种常见的类型
SIMPLE
简单select,即未使用UNION或子查询。比如对于单表查询、连接查询,其就是SIMPLE类型
PRIMARY
对于含联合查询或子查询的SQL语句而言,其会有多个select关键字。则SQL语句中第一个(即最左边)的select类型就是PRIMARY
UNION
对于联合查询而言,除了SQL语句中第一个select类型为PRIMARY,SQL语句中的其余select类型即为UNION
UNION RESULT
对于联合查询而言,如果需要对联合查询的结果集进行去重,则其对临时表的select类型即为UNION RESULT
SUBQUERY
对于子查询而言,如果查询优化器无法将其优化为semi-join半连接查询,且该子查询为不相关子查询。则该子查询中第一个select的类型即为SUBQUERY
DEPENDENT SUBQUERY
对于子查询而言,如果查询优化器无法将其优化为semi-join半连接查询,且该子查询为相关子查询。则该子查询中第一个select类型即为DEPENDENT SUBQUERY
DEPENDENT UNION
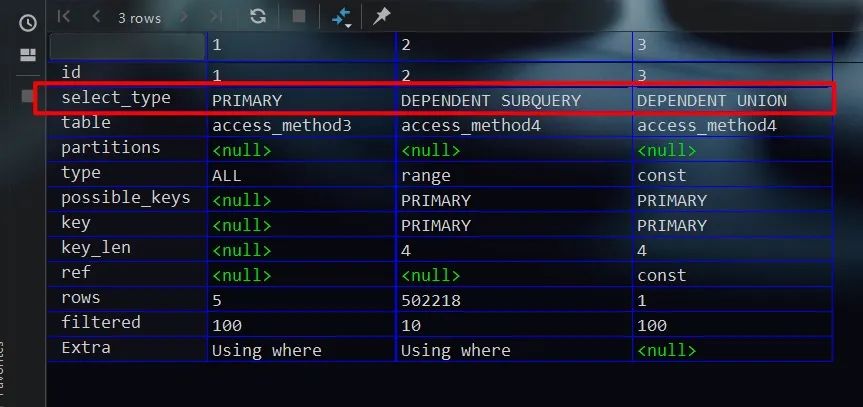
对于一个通过union连接、内部含有多个select的子查询而言,且子查询内部各select语句均与外层查询相关时,则该子查询除了第一个select类型为DEPENDENT SUBQUERY,其余select类型均为DEPENDENT UNION。SQL语句示例如下所示
explain
select * from access_method3
where id = (
-- 该子查询内部通过union连接2个select关键字
select access_method4.id from access_method4
where access_method3.name = access_method4.name and access_method4.id>3
union all
select access_method4.id from access_method4
where access_method3.name = access_method4.name and access_method4.id=1 );
执行计划如下所示,符合预期
DERIVED
对于采用物化的方式执行的包含派生表的查询,该派生表对应的子查询的select类型即为DERIVED。示例SQL如下所示
explain
select *
from (select count(*) as count from access_method3) as t1
where count>996;
执行计划如下所示,符合预期

table字段
该字段即是执行查询时所作用的数据表的表名
type字段
关于type字段,其表示的就是进行查询时所使用的访问方法。之前我们已经介绍MySQL进行单表查询时一些常用的Access Method访问方法了。这里我们再对其他常见的访问方法进行补充说明
system
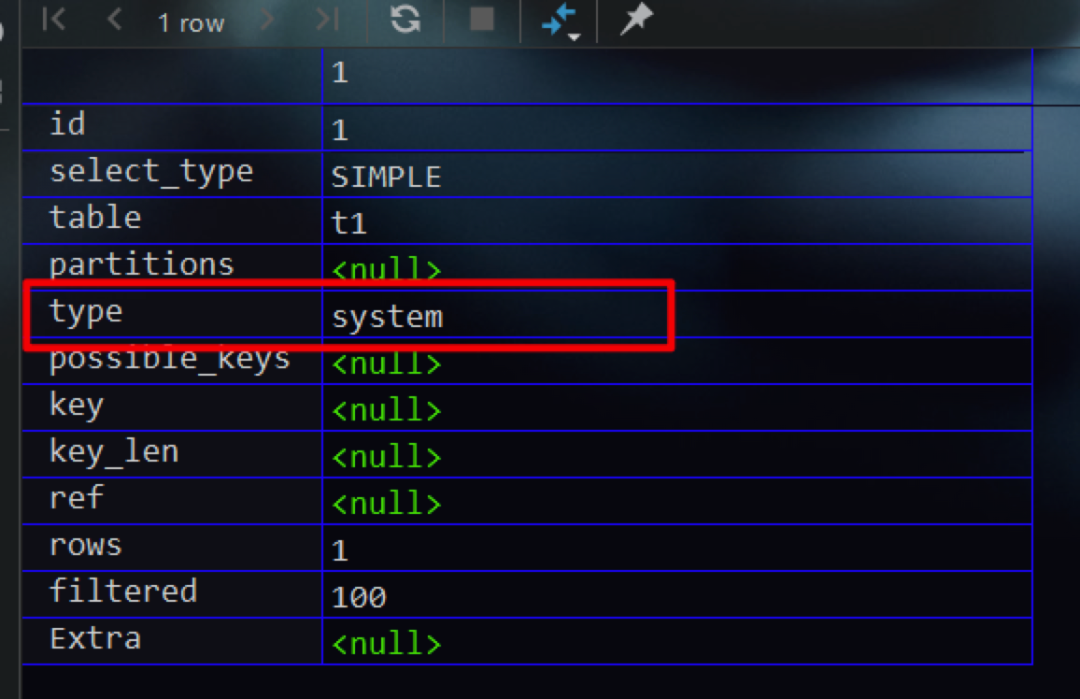
前面我们提到MySQL会对表中的记录数进行统计。在表中只有一条记录的情况下,此时查询的访问方法即为system。需要注意其有一个前提条件,即要求存储引擎对表中记录数的统计必须是准确值,而不能是估计值。换言之,该访问方法对InnoDB存储引擎不适用,适用于MyISAM、Memory等存储引擎。下面的SQL语句,即建立了一个基于MyISAM的数据表并向其中插入一条记录
-- 创建基于MyISAM的数据表
create table t1 (
name varchar(255),
age int,
primary key (name)
) Engine=MyISAM;
-- 插入一条记录
insert into t1(name, age) values ('Aaron', 25);
-- 查看查询SQL的执行计划
explain select * from t1;
结果如下,符合预期
fulltext
使用全文索引
unique_subquery
有时候查询优化器会对in子查询进行优化进而转换为exists子查询,例如下面的SQL使用了in子查询,其中access_method3的主键为id字段
explain
select * from access_method4
where access_method4.name in (
select access_method3.id from access_method3
where access_method3.iphone_number=110
)
or access_method4.type='staff';
现在我们将其转换为exists子查询,可以看到现在对于exists子查询而言,可以利用access_method3表的主键(聚簇索引)进行等值查询。这也是为啥查询优化器要进行如此优化的原因所在
explain
select * from access_method4
where exists(
select 1 from access_method3
where access_method3.iphone_number=110
and access_method3.id = access_method4.name )
or access_method4.type='staff';
故当将查询优化器将in子查询优化为exists子查询时,如果子查询可以利用主键索引进行等值查询,则该子查询的访问方法即为unique_subquery。现在我们查看上文in子查询的执行计划
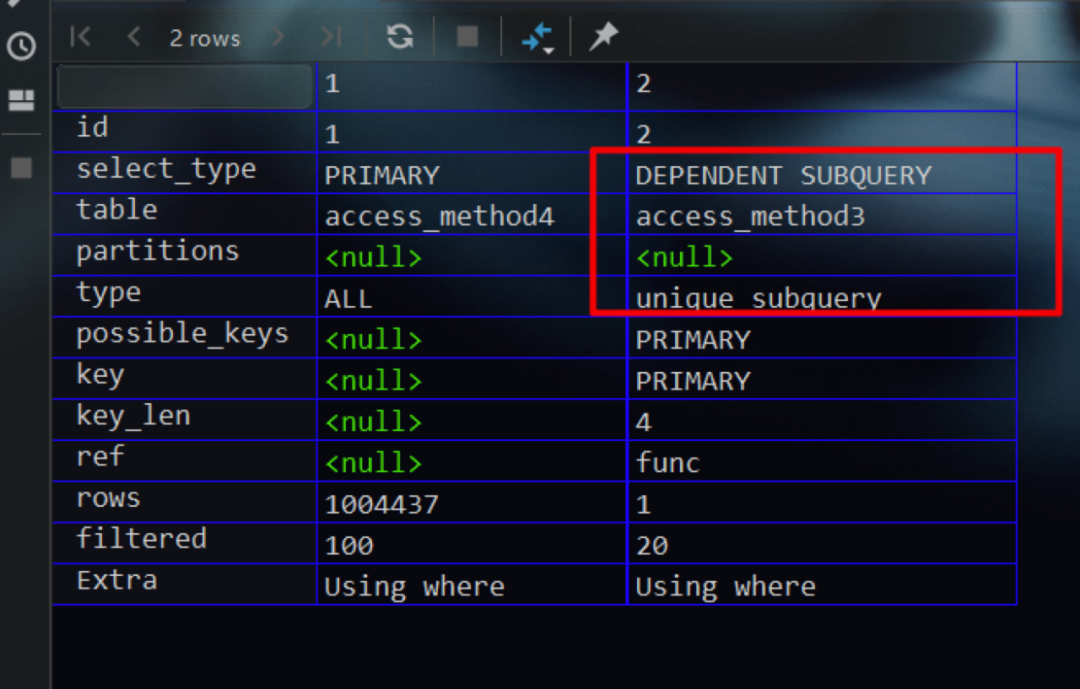
index_subquery
其与unique_subquery类似,只不过其是在查询优化器将in子查询优化为exists子查询的条件下,子查询可以利用二级索引进行等值查询时的访问方法。例如下面的SQL语句,其中对access_method3表的name字段建立了一个二级索引
explain
select * from access_method4
where access_method4.name in (
select access_method3.name from access_method3
where access_method4.type = access_method3.country
)
or access_method4.type='staff';
执行结果如下,符合预期
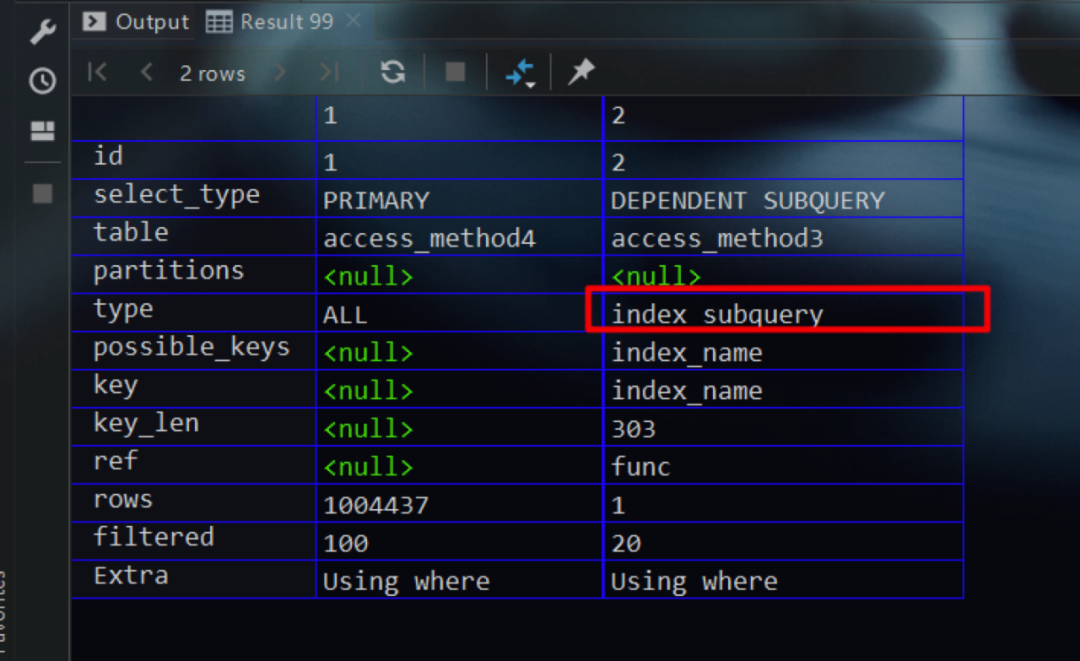
possible_keys字段
故名思义,该字段只是列出该查询可以利用的索引。需要注意的是该字段所列出的索引越多,则查询优化器在计算、比较各查询方案成本时所需的时间也就越多
key字段
前面我们提了possible_keys字段只是给出在查询过程可以利用的索引,而实际真正地使用哪些索引进行查询则体现在key字段中
key_len字段
该字段意为当使用索引进行查询时,该索引的最大长度字节数。具体地:
对于固定长度类型的索引字段而言,则其占用的最大长度就是该固定值 对于指定字符集的变长类型的索引字段而言,例如对utf8字符集下的varchar(10)而言,则其所占用的最大长度为3*10=30个字节 对于变长类型的索引字段而言,其还需占用2个字节用于存储变长类型的实际长度 若该索引字段允许NULL值,则其key_len值比不允许NULL值时多1个字节
说了这么多,那这个字段到底有什么用呢?为此,我们先来建立一张表并插入一些数据。其中该数据表使用utf8字符集
create table user_info(
id int auto_increment,
name varchar(10) null,
sex varchar(10) null,
age int null,
primary key (id),
index index1(name, sex, age)
);
好了,现在我们查看下面的SQL查询语句的执行计划
explain
select name from user_info
where name='aaron';
执行计划中的key_len值为33,为什么呢?其实也很好理解。首先对于上面的SQL语句而言,如果使用index1索引,最多也只会用到name索引字段,则此时该索引记录的最大长度即为10*3 + 2(变长类型) + 1(允许为NULL) = 33
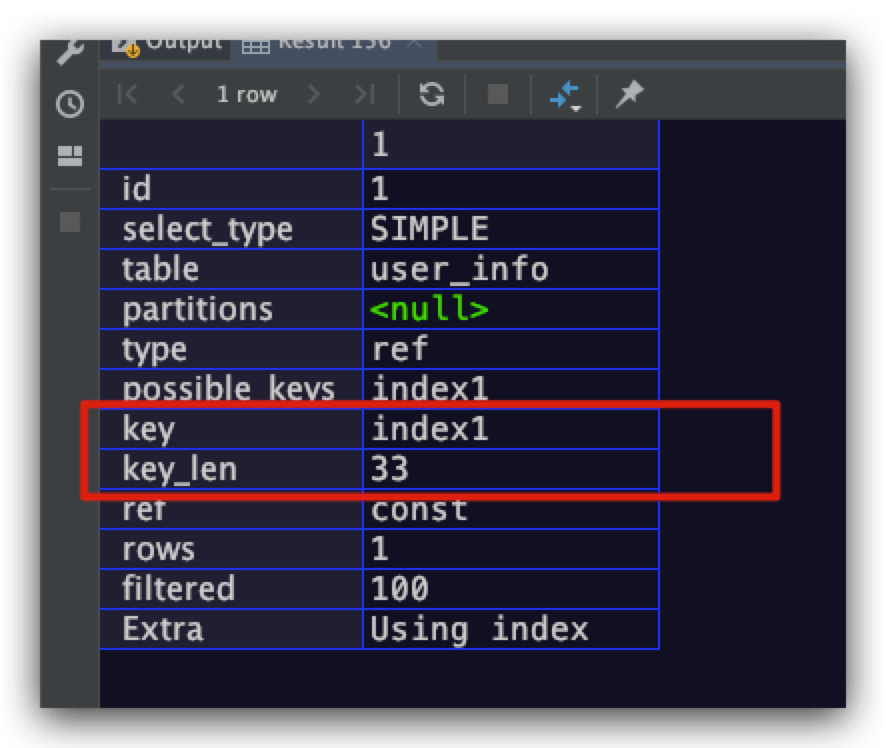
如果我们同时使用index1索引中的name、sex索引字段是什么效果呢
explain
select name from user_info
where name='aaron' and sex='man';
可以看到此时该key_len值变为66了。由于name字段与sex字段的类型在数据表的定义中完全一致,故此处就不再具体解释这个66是怎么计算出来的,可以参照上文对name字段的计算过程
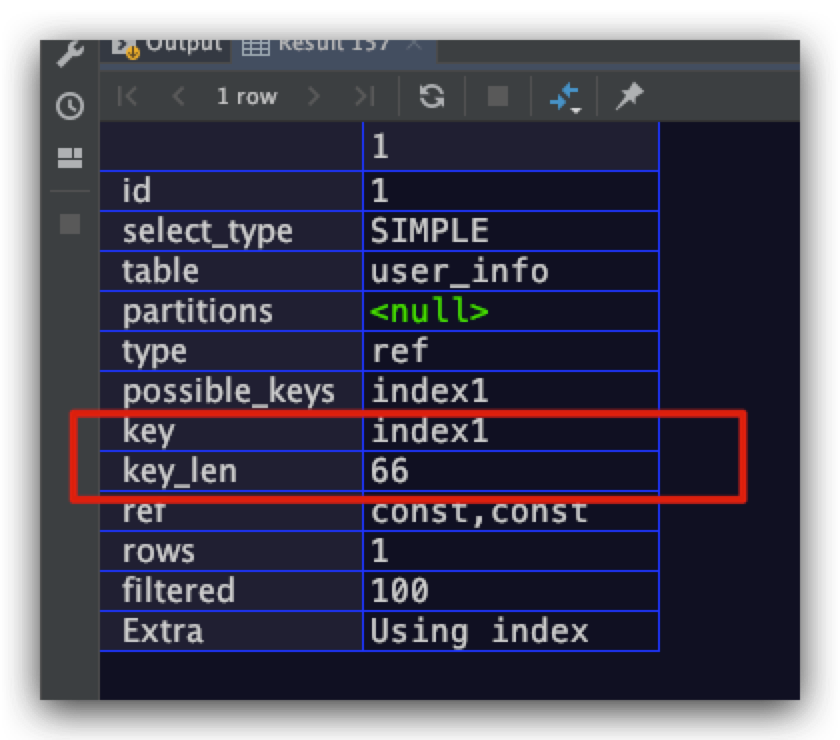
至此,相信大家应该知道key_len字段的用处了。通过该字段即可让用户知道,在通过索引查询时到底使用了联合索引的几个索引字段
ref字段
该字段表示索引字段进行等值查询过程中"值"的类型。例如对于下面的SQL查询语句而言
explain
select name from user_info
where name='aaron';
这里对索引index1的name索引字段进行了等值查询,其中值为'aaron'。即是一个常数。从执行计划中我们可以看到其ref字段为const,即常数
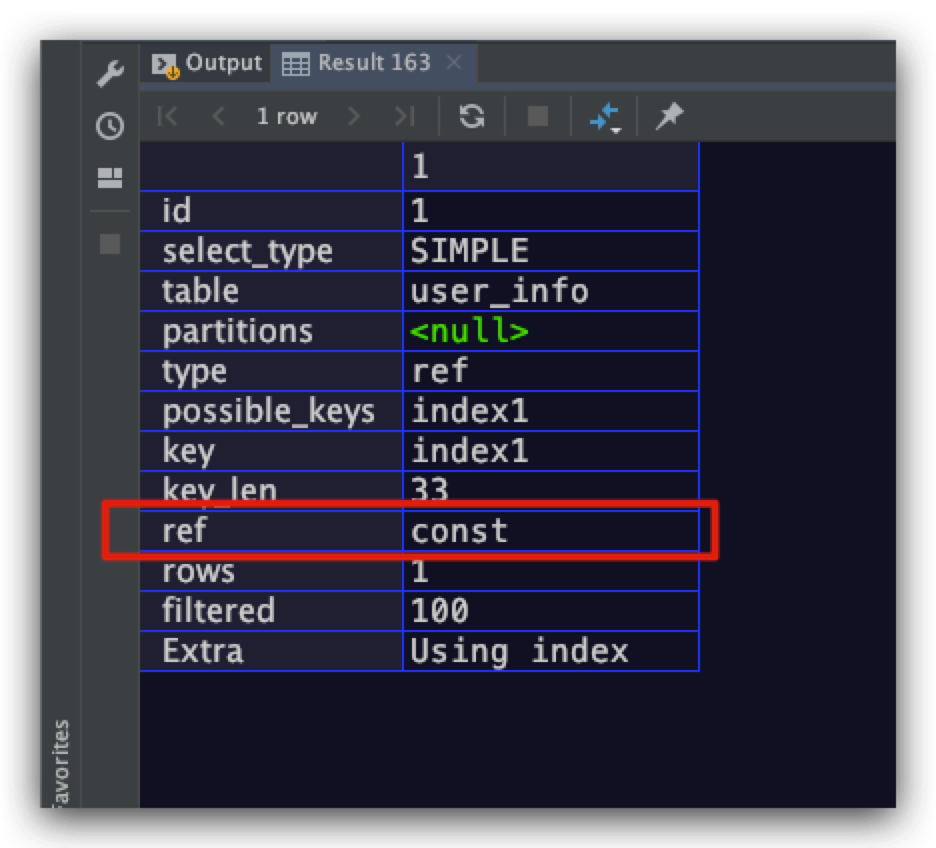
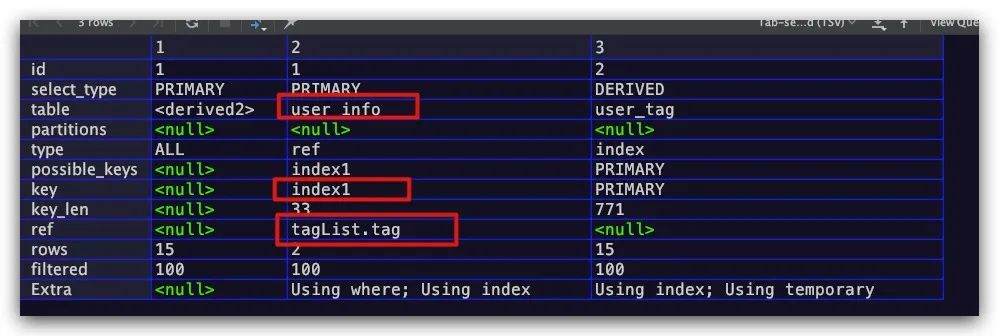
此外该字段还可以是某个列的列名。例如对于下面的SQL语句而言,在对被驱动表user_info进行单表查询时,是以tagList表中记录的tag字段作为等值查询时的值
explain
select * from tagList left join user_info
on user_info.name=tagList.tag;
则从执行计划中我们可以看到,结果符合预期
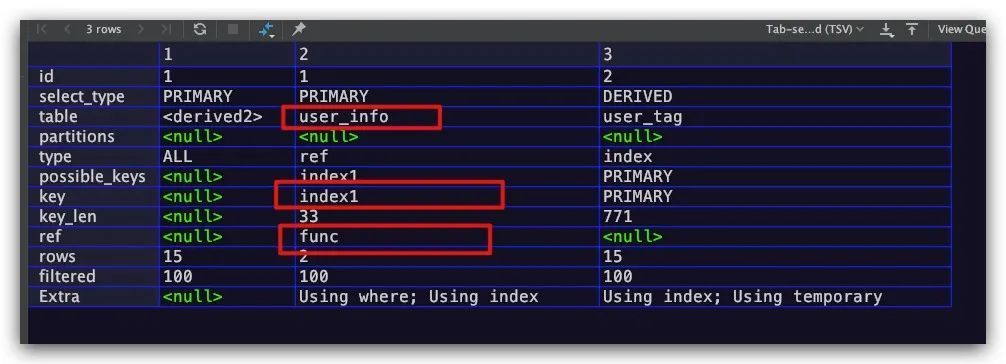
此外该字段的值还可以是func,即等值匹配的类型是一个函数。SQL实例如下所示
explain
select * from tagList left join user_info
on user_info.name = lower( tagList.tag );
执行计划结果如下,符合预期
rows字段
该字段表示预计查询需要扫描的记录数(行数)。具体地,当采用全表扫描的方式进行查询时,其指的就是数据记录的行数;当通过索引进行查询时,其指的是索引记录的行数
filtered字段
该字段是一个以百分比%为单位的估计值,其表示的是 通过查询条件过滤后符合要求的记录数 占 预计扫描的记录数(即row字段值) 的百分比。换言之,预计结果记录数量为 filtered值 / 100 * rows值
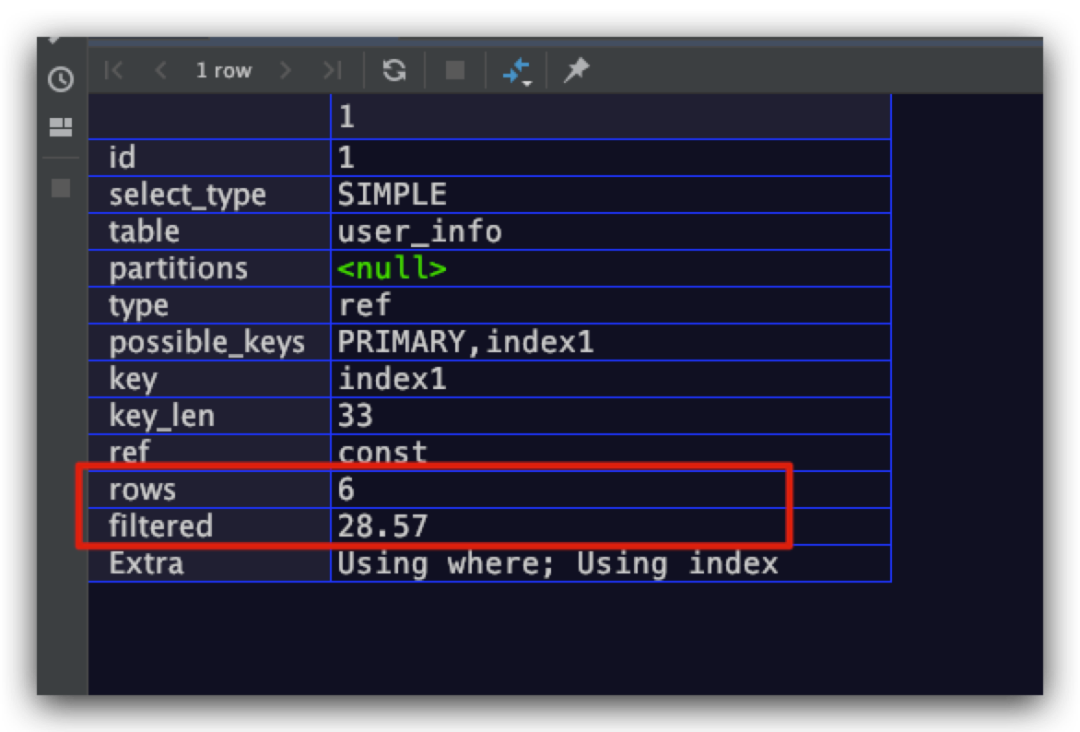
这里向user_info数据表插入一些数据,具体结果如下。其中name字段上建立了一个二级索引index1
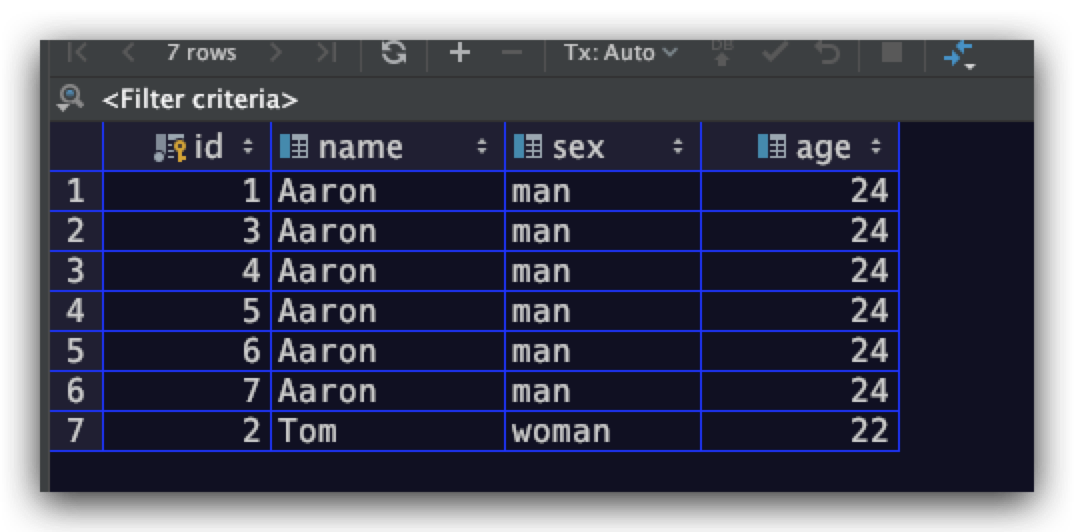
示例SQL语句如下
explain
select name from user_info
where name='aaron' and id>5;
从执行计划中我们可以看出,符合上述查询要求的记录数的估计值为 6 * 28.57% = 1.7142,通过观察我们可以看到真正满足查询要求的记录数是2条。这也进一步执行计划中的结果只是一个估计值,而非精确值
Extra字段
该字段是对执行计划信息的补充和完善,这里就一些常见的补充信息进行说明
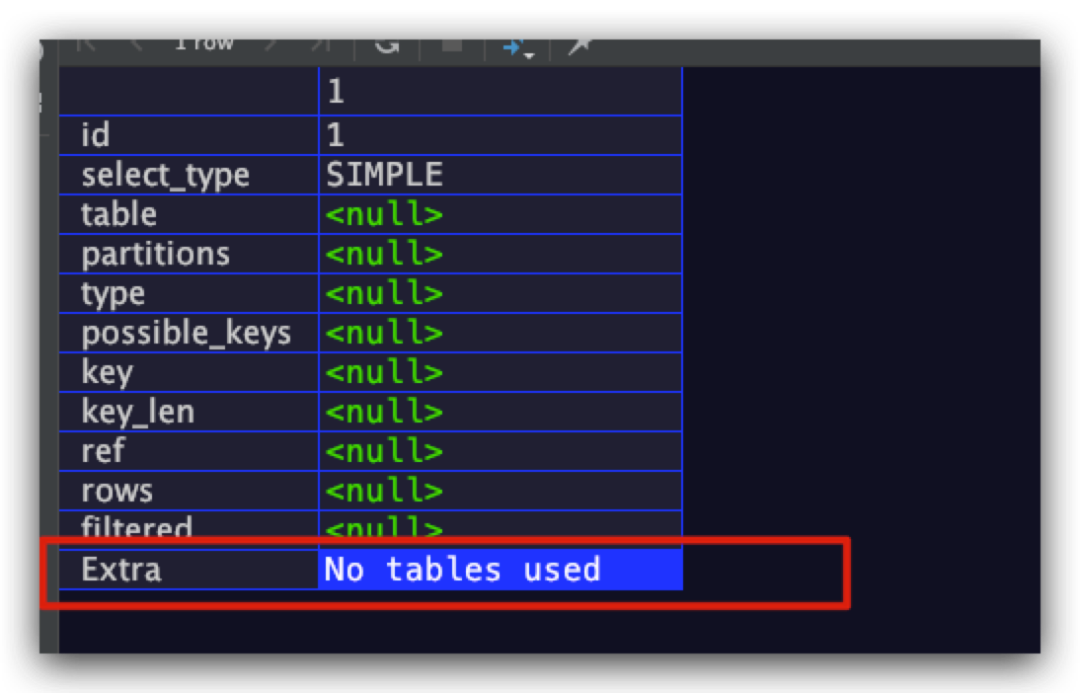
No tables used
没有数据表,即未使用from子句。示例SQL如下所示
explain select 1;
结果如下,符合预期
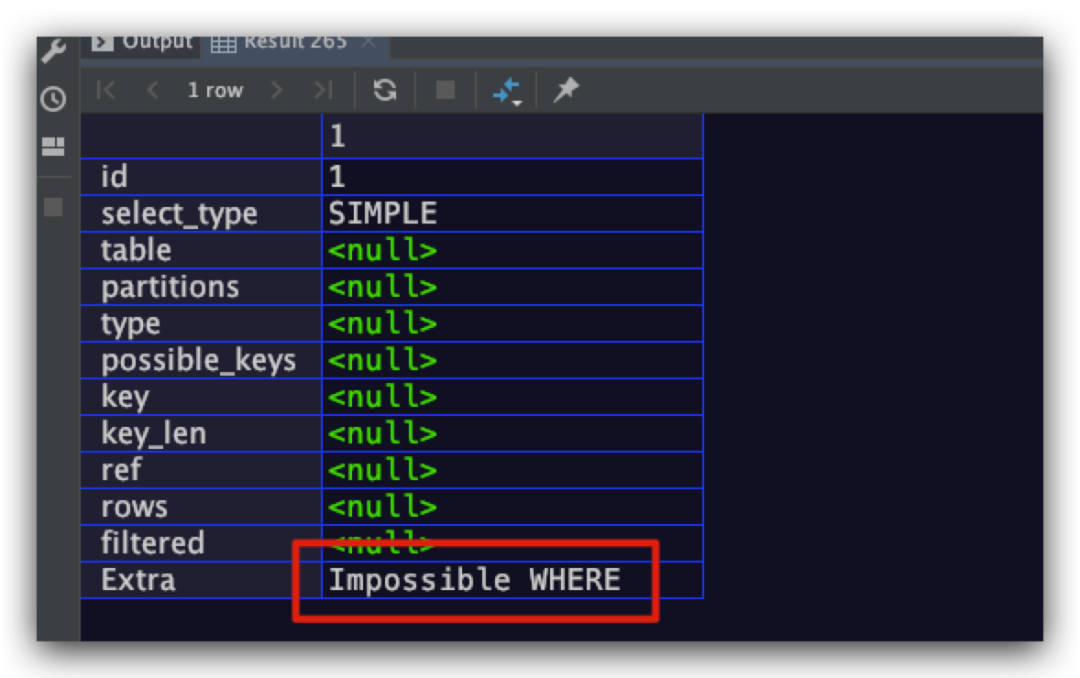
Impossible WHERE
where子句中条件恒为false。示例SQL如下所示
explain
select * from user_info
where 1=3;
结果如下,符合预期
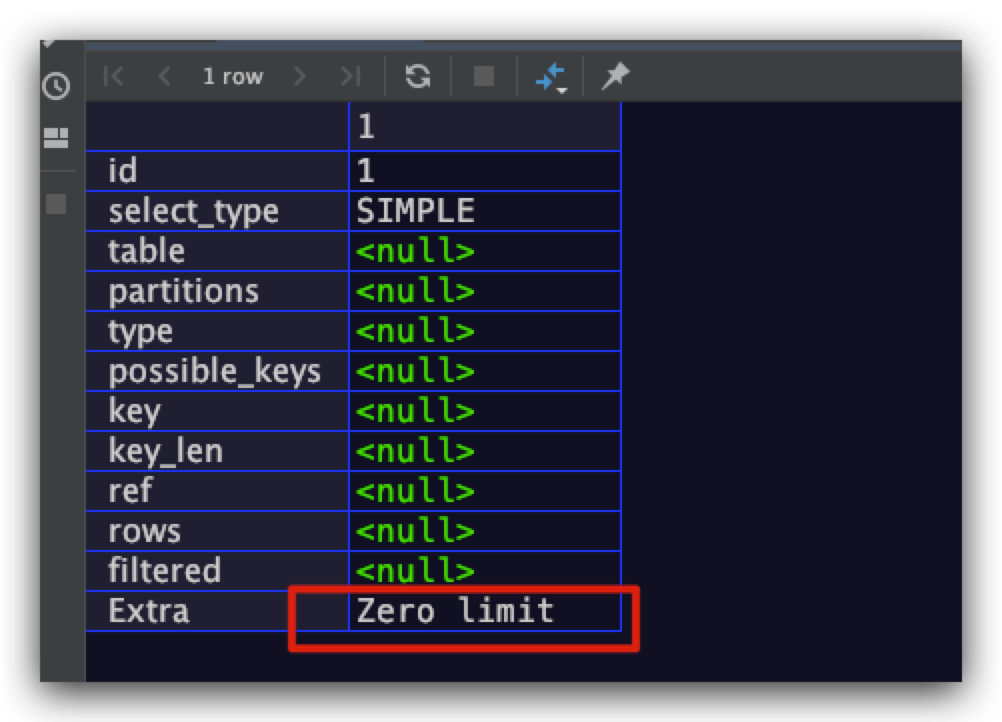
Zero limit
limit子句的参数为0,即查询语句返回的记录数为0条。示例SQL如下所示
explain select * from user_info limit 0;
结果如下,符合预期
Using index
出现索引覆盖,即不需要进行回表操作。为了方便演示,这里先建立一张表,并在name、age字段上建立了一个联合索引index1
create table staff(
id int auto_increment,
name varchar(10) null,
age int null,
salary double null,
primary key (id),
index index1(name, age)
);
现在我们就来写一个发生索引覆盖情况的SQL,示例如下
explain
select age from staff
where name = 'aaron';
执行计划如下所示,符合预期
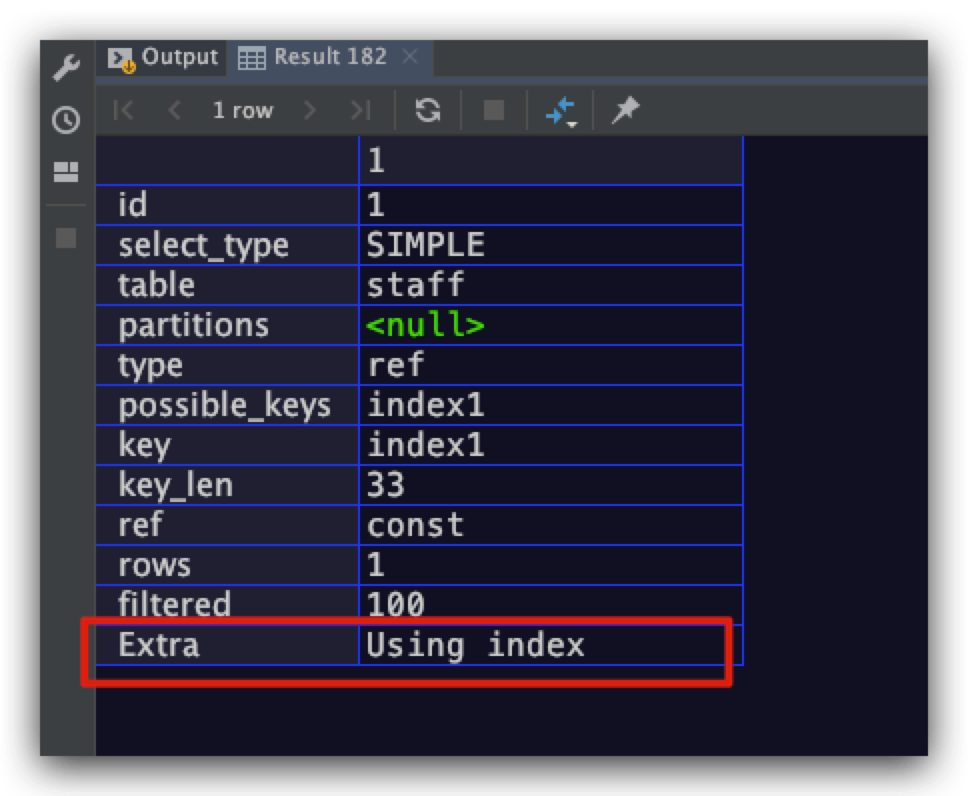
相应的,如果我们的索引index1不是一个覆盖索引时,既不会存在该补充信息,示例SQL如下
explain
select salary from staff
where name = 'aaron';
从下面的执行计划可以看到Extra为NULL,符合预期
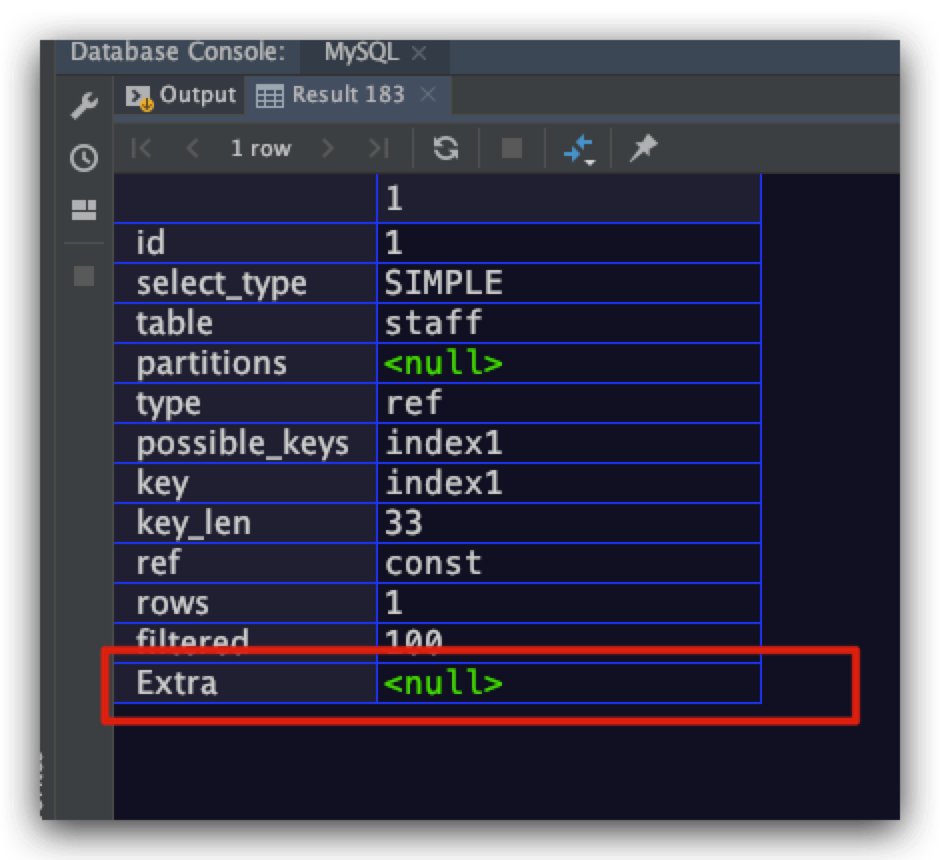
Using index condition
对于利用二级索引进行查询的过程我们已经很熟悉了,基本是先利用 索引字段的查询条件 获取 二级索引记录,然后再通过回表操作获取完整记录。那问题来了,对于存在一些无法使用索引的索引字段的查询条件。该何时使用呢?具体地,即是在获得二级索引的记录后使用该查询条件进行过滤,还是在回表操作后获取到完整的记录时使用该查询条件进行过滤呢?在MySQL 5.6之前,对于该查询条件的使用时机是在回表后获取到完整记录的时候。而在MySQL 5.6中引入了 Index Condition Pushdown(ICP, 索引条件下推) 特性,该优化将 索引字段的查询条件 的使用时机放在获取到二级索引的记录时,此举大大减少了不必要的回表操作。故如果某个查询语句使用了ICP特性,这即会出现补充信息Using index condition
这么说可能有点抽象,下面通过具体的实例作进一步的解释。其中,name字段上存在一个二级索引index1。可以看到对于查询条件 name>'aa' 而言,是可以利用到索引index1。但对于查询条件 name like '%ron',由于是前缀匹配,故该索引字段的查询条件无法使用索引。但MySQL可以先利用查询条件name > 'aa'在索引index1的B+树中获取符合条件的记录,然后再对这些二级索引的记录进一步使用 name like '%ron' 条件进行过滤,最后再利用二级索引记录中主键进行回表获取完整的用户记录
explain
select * from staff
where name > 'aa' and name like '%ron';
执行计划结果如下所示,符合预期
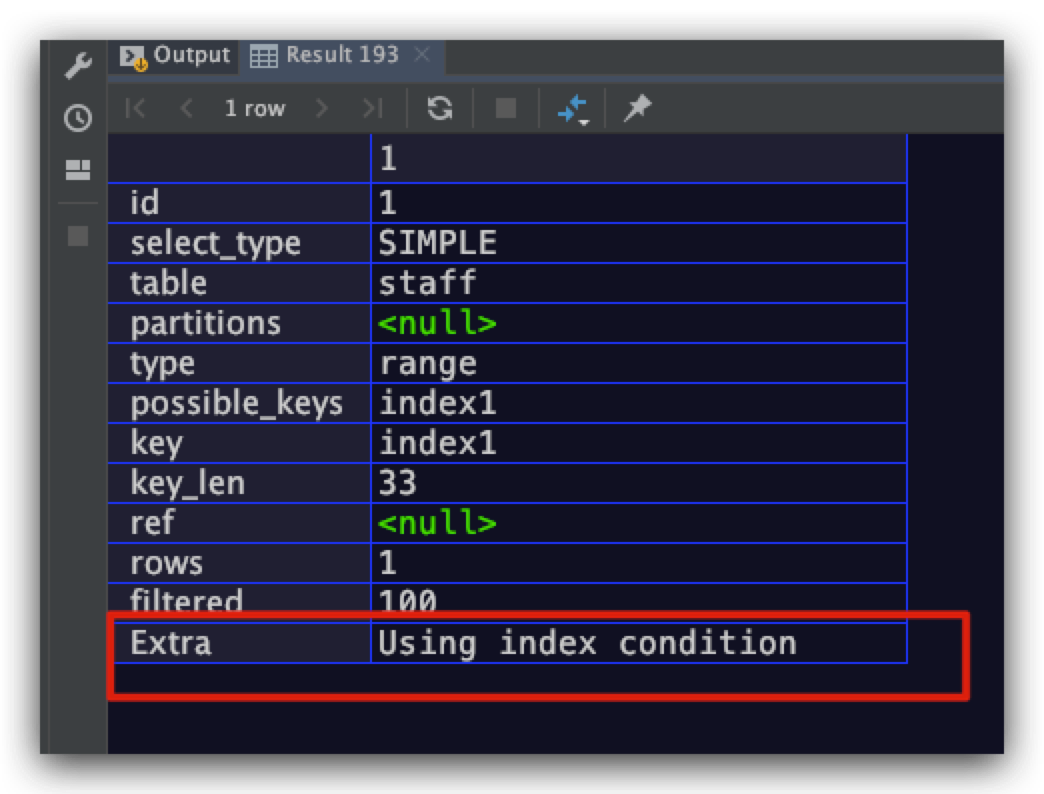
Using where
在全表扫描时或二级索引回表后,使用where子句中的查询条件进行过滤。SQL示例如下所示,其中name字段上建有二级索引index1
explain
select * from staff
where name='bob' and salary>123;
执行计划的结果如下,符合预期
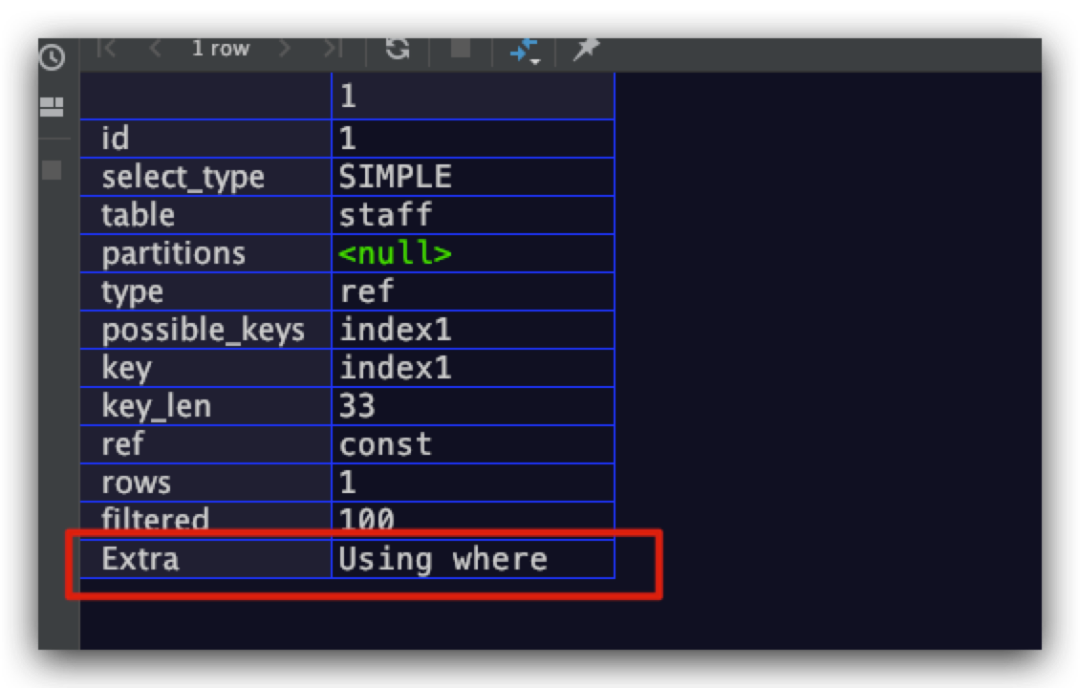
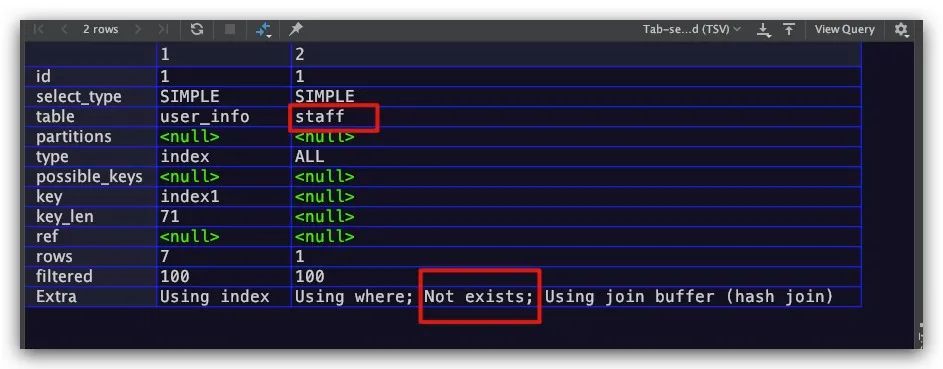
Not exists
对于外连接查询而言,如果在where子句要求被驱动表中某个不允许为NULL字段的值为NULL。则会在被驱动表执行计划的Extra字段中出现Not exists信息。因为在此种场景下,驱动表中的记录只有在被驱动表中无法匹配到记录时,才会被加入到最终的结果集。换言之,对于驱动表中的某条记录A1来说,如果其通过on子句在被驱动表中找到一条匹配的记录后,即可提前停止对A1记录的匹配。因为A1记录肯定不会被加入到最终的结果集中。显然通过提前停止匹配的操作,大大减少不必要的性能浪费
对于下面的左外连接查询SQL语句而言,除staff表的id字段不允许为NULL外,其余字段均可为NULL
explain
select * from user_info left join staff
on user_info.age = staff.age
where staff.id is null;
执行计划的结果如下,符合预期
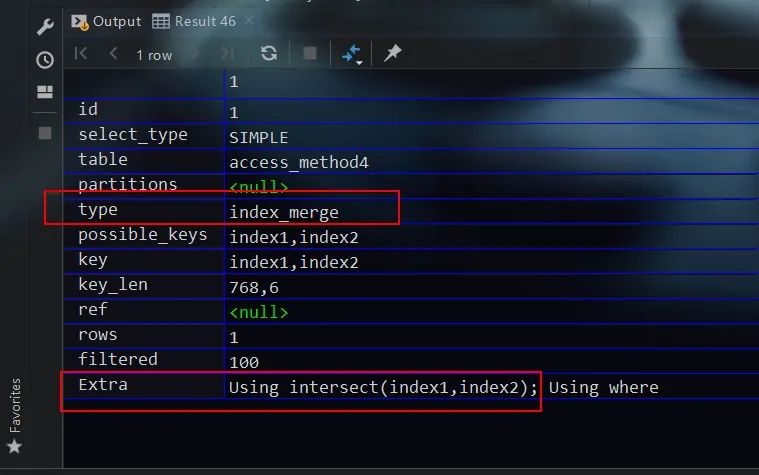
Using intersect、Using union、Using sort_union
我们在介绍单表查询的Access Method访问方法时,介绍过一种同时使用多个索引的访问方法——index merge。在该访问方法下,具体有Intersection、Union、Sort-Union等算法。故当执行计划的type字段值为index merge时,Extra字段即会给出具体算法的补充信息。对应于上面提到三种不同算法,分别为Using intersect、Using union、Using sort_union。并在后面的括号中会给出涉及到的索引名称
这里以Using intersect为例进行介绍,首先建立如下的数据表并插入一些数据
create table access_method4 (
id int auto_increment,
recv_time datetime null,
create_time varchar(255) null,
name varchar(255) null,
PRIMARY KEY (id),
index index1(create_time),
index index2(recv_time)
);
则SQL查询的示例如下所示
explain
select * from access_method4
where create_time='2019-03-26 23:59:35.492' -- 对index1索引中所有字段进行等值查询
and recv_time='2019-03-26 23:59:32'; -- 对index2索引中所有字段等进行值查询
则执行计划的结果如下所示
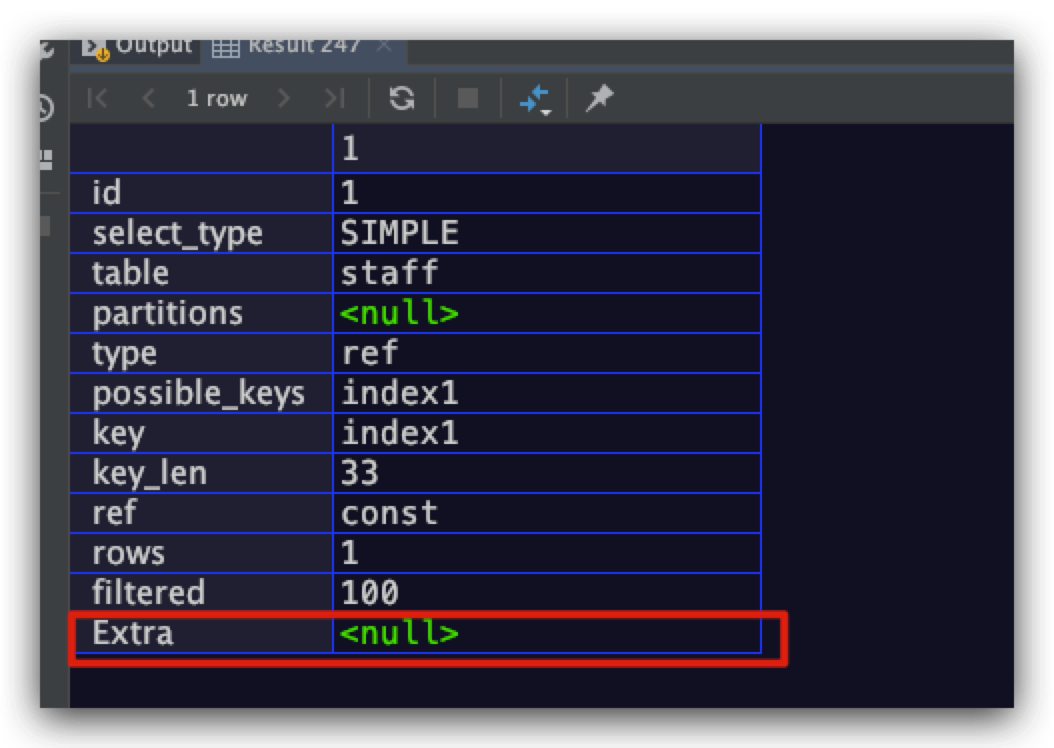
Using filesort
众所周知,可以利用索引直接实现某些排序需求。例如对于下面的SQL而言,其在name、age字段上建立了一个联合索引
explain
select * from staff
where name = 'a'
order by age;
则其执行计划如下所示,Extra字段值空空如也
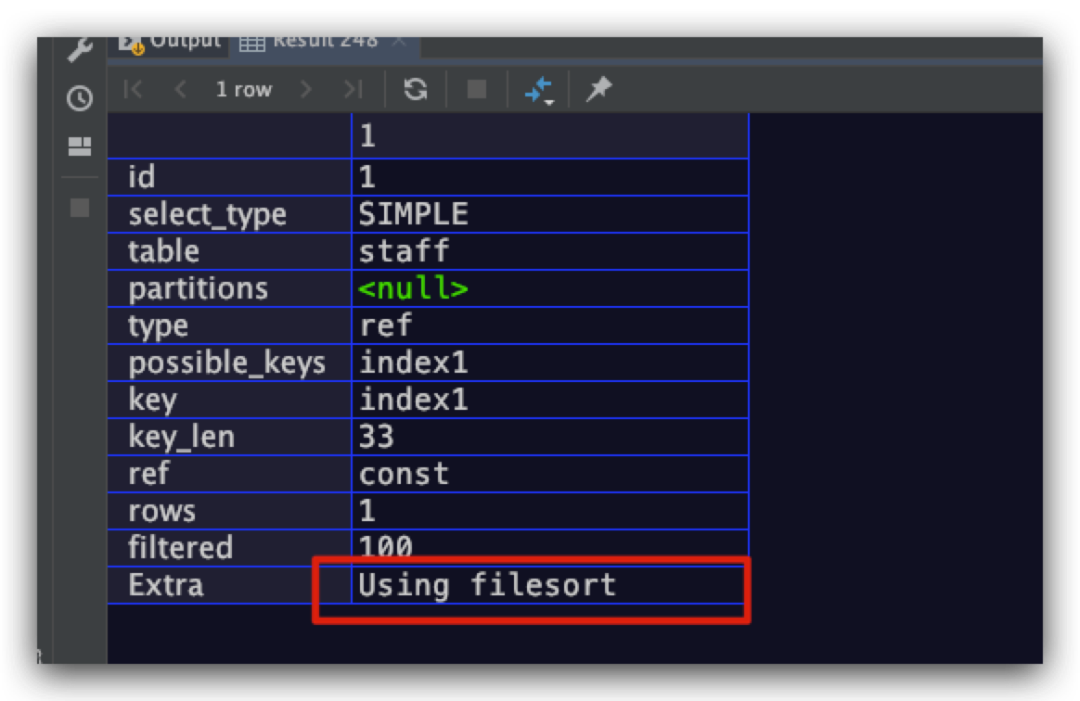
但大多数时候我们无法利用索引直接实现有序,而只能在内存或磁盘中进行排序。前者内存中适用于记录较少时,后者磁盘中适用于记录较多时。不论是在内存中还是在硬盘中实现排序,在MySQL下均被称作file sort文件排序。例如对于下面的SQL语句而言,即无法通过索引直接实现排序,而只能通过file sort排序实现
explain
select * from staff
where name = 'a'
order by salary;
执行计划结果如下,符合预期
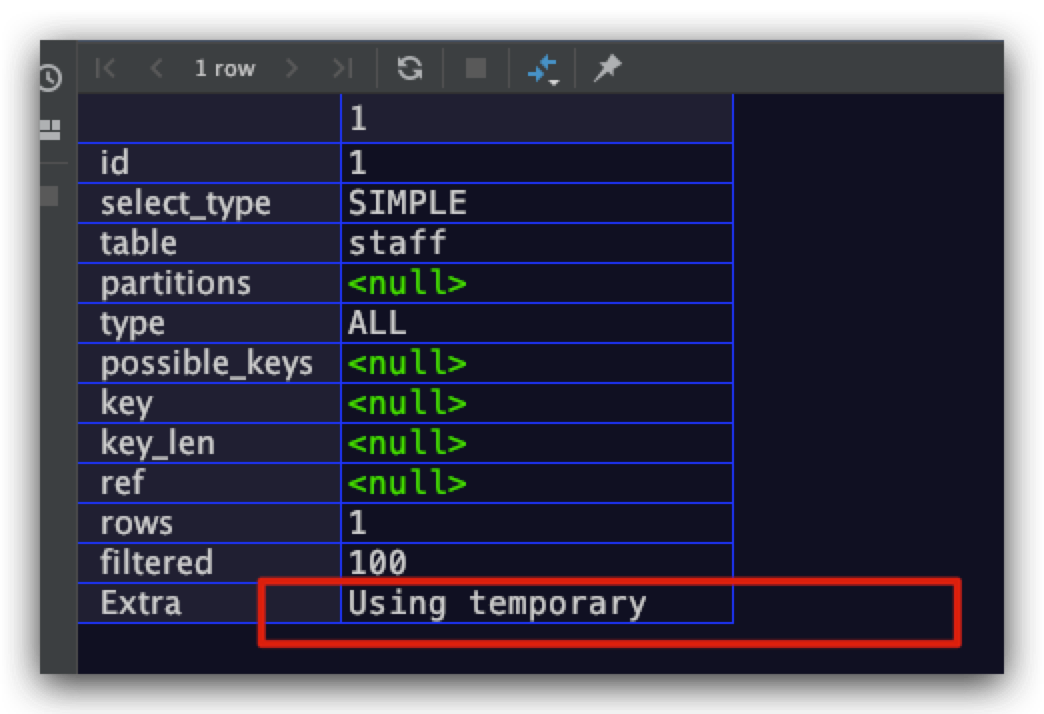
Using temporary
当MySQL进行去重、排序、分组等操作时,可能需要在内部建立临时表来完成。值得一提的是,由于建立、维护临时表的成本并不低,必要时可以通过索引来避免MySQL使用临时表。示例SQL如下所示
explain select distinct salary from staff;
执行计划结果如下所示
参考文献
MySQL是怎样运行的