
无需多个模型也能实现知识整合?港中文MMLab提出「烘焙」算法,全面提升ImageNet性能
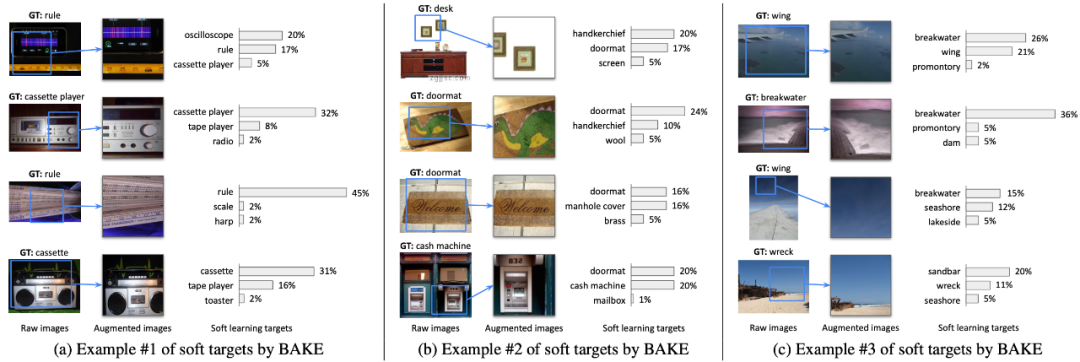
来自港中文 MMLab 的研究者提出一种烘焙(BAKE)算法,为知识蒸馏中的知识整合提供了一个全新的思路,打破了固有的多模型整合的样式,创新地提出并尝试了样本间的知识整合。

论文链接:https://arxiv.org/pdf/2104.13298.pdf
项目主页:https://geyixiao.com/projects/bake
代码链接:https://github.com/yxgeee/BAKE


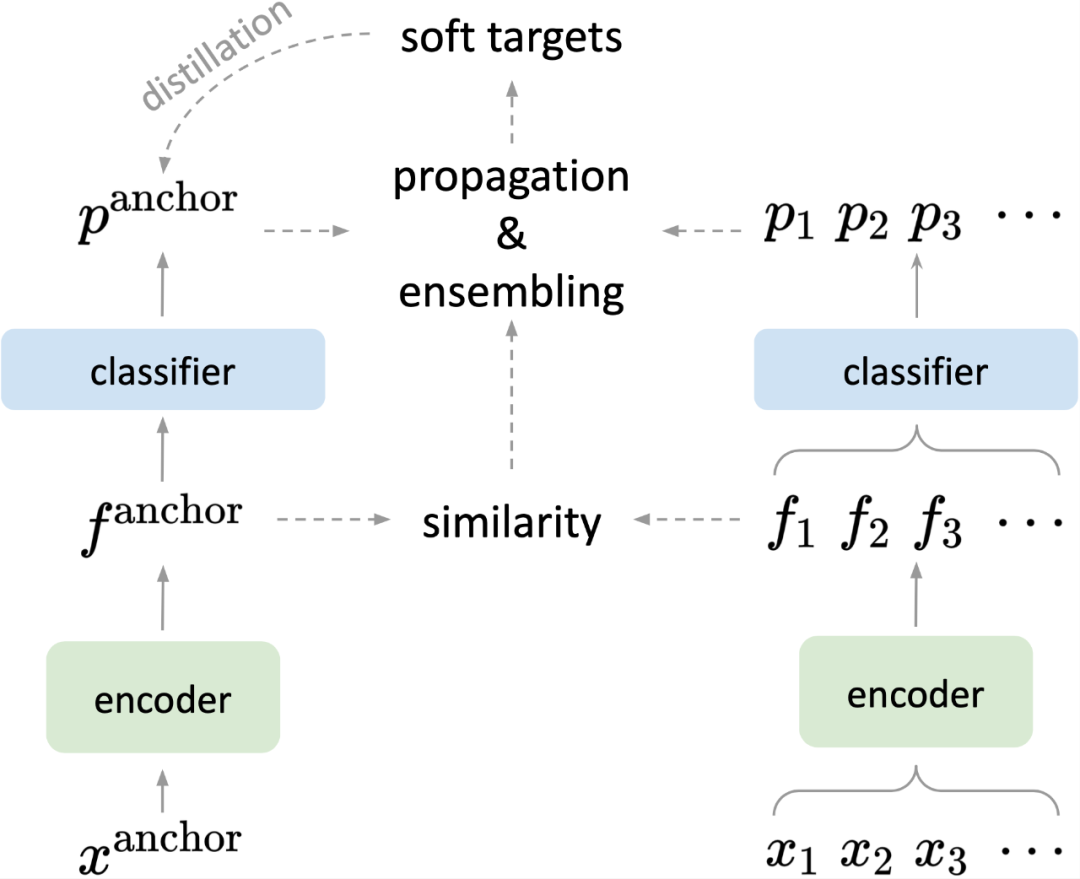
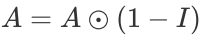 ,也就是同一样本的相似度,并在每行进行 softmax 归一化,使得每一行的和为 1,即
,也就是同一样本的相似度,并在每行进行 softmax 归一化,使得每一行的和为 1,即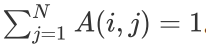 。基于亲和度矩阵 A,可以对除锚样本之外的其他样本的预测进行加权传播,
。基于亲和度矩阵 A,可以对除锚样本之外的其他样本的预测进行加权传播,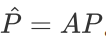 。并与锚样本本身的预测概率进行加权和,从而获得软标签作为蒸馏目标
。并与锚样本本身的预测概率进行加权和,从而获得软标签作为蒸馏目标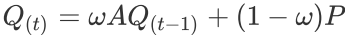 。研究者利用近似预测对传播无限次后的软标签进行了估计,
。研究者利用近似预测对传播无限次后的软标签进行了估计,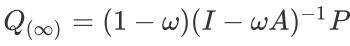 。
。



© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论